突破OCR hallucination难题:DianJin-OCR-R1框架的创新与实践
阿里云团队提出DianJin-OCR-R1框架,创新性融合大视觉语言模型推理能力与专家OCR模型精准性,突破OCR领域"幻觉"和技术适配难题。该框架通过"初步识别-工具调用-复盘输出"三阶段闭环,实现复杂文档的精准解析。实验表明其在印章、表格、公式识别任务上全面超越主流模型,准确率最高提升37%。研究采用SFT+RFT双阶段训练,构建高质量推理数据集,验证了
突破OCR hallucination难题:DianJin-OCR-R1框架的创新与实践
在文档图像解析领域,光学字符识别(OCR)是核心技术之一,但当前主流模型普遍存在“幻觉”(生成图像中不存在的内容)和任务适配性不足的问题。阿里云计算Qwen DianJin团队提出的DianJin-OCR-R1框架,通过“推理+工具交互”的创新范式,成功融合了大视觉语言模型(LVLMs)的推理能力与专家OCR模型的精准性,为复杂OCR任务提供了新解法。本文将按原文章章节结构,提炼核心内容,带大家全面了解这一框架。
一、研究背景:OCR领域的“两难困境”
当前OCR技术主要分为两类方案,但均存在明显短板:
- 大视觉语言模型(LVLMs):如Qwen2.5-VL、GPT-4V等,能以端到端范式处理文本、表格、公式等多种文档元素,流程简洁统一。但这类模型易产生“幻觉”——因学习的是语言模式而非图像实际内容,常输出不存在的字符或结构,且细粒度感知能力弱于专业模型。
- 专家OCR模型:如PP-StructureV3(处理表格)、PP-FormulaNet(处理公式)等,针对单一任务设计,几乎无“幻觉”问题,细粒度识别能力强。但需为不同任务切换模型,流程复杂,且无法跨任务复用。
以印章识别为例(见表1),Qwen2.5-VL-7B-Instruct将“永安县工农村第九村民小组”误识别为“永安分社”,PP-StructureV3则错把“羌族”写为“芜族”,均体现了现有模型的局限性。
二、核心方案:DianJin-OCR-R1的“推理+工具”双引擎
为解决上述困境,DianJin-OCR-R1提出“推理与工具交互”的核心框架,整体流程分三步,形成闭环验证:
- 初步识别:基于模型自身OCR能力,对输入图像的内容(如印章文字、表格结构、公式符号)进行初步识别,获取基础结果。
- 工具调用与参考:调用1-2个适配当前任务的专家OCR模型(如表格识别用MonkeyOCR-3B、公式识别用PP-FormulaNet),将其输出作为参考依据,弥补自身细粒度识别短板。
- 二次复盘与输出:“重新审视”图像,对比自身初步结果与专家模型结果,分析差异点(如字符错误、结构遗漏),通过推理修正偏差,最终输出精准结果。
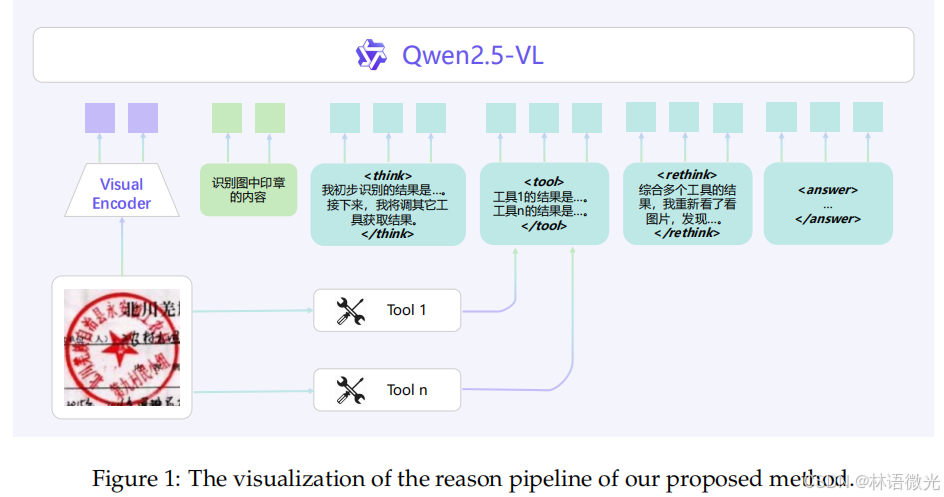
该框架的关键优势在于:无需对庞大的LVLMs进行重新训练,仅需迭代小型专家模型,即可低成本提升整体性能;同时,“推理链”的加入让识别过程更透明、可验证,减少“幻觉”产生。
三、技术细节:从数据构建到模型训练
DianJin-OCR-R1的落地依赖两大核心技术环节——高质量推理数据构建与分阶段模型训练,确保框架能稳定学习“推理+工具交互”逻辑。
3.1 推理数据集:为“思考”量身定制
团队针对印章、表格、公式三大典型OCR任务,构建了专属推理数据集(RsrR_{sr}Rsr/ RtrR_{tr}Rtr/ RfrR_{fr}Rfr),每个数据集的样本格式为「图像+指令+推理链+正确输出」,构建逻辑如下:
- 数据来源:印章数据取自ReST(ICDAR 2023竞赛数据集)、表格数据取自TabRecSet(双语表格数据集)、公式数据取自UniMER-1M(百万级公式数据集),确保数据真实性与多样性。
- 推理链生成:利用Qwen-VL-Max等强LVLMs,通过多轮提示生成“初步识别(标签)+工具结果(标签)+复盘分析(标签)”的完整推理链。
- 样本筛选:通过严格指标筛选有效样本,如印章识别要求“输出与标准答案完全匹配”,表格识别要求“Tree-Edit-Distance相似度(TEDS)>0.98”,公式识别要求“1-归一化编辑距离(1-NED)<0.015”。
最终构建的三个数据集各含1024个样本,为后续训练提供高质量监督信号。
3.2 模型训练:SFT+RFT双阶段优化
框架基于Qwen2.5-VL-7B-Instruct进行训练,分两个阶段递进优化,训练环境为单节点8张NVIDIA A100 GPU:
- 有监督微调(SFT):以“图像+指令”为输入,“推理链+正确输出”为目标,让模型学习“如何生成符合格式的推理过程并输出正确结果”。训练参数为:学习率1.0×10⁻⁵、序列长度16K、bf16精度、2个epoch,通过4步梯度累积模拟大批次训练。
- 强化学习微调(RFT):采用Group Relative Policy Optimization(GRPO)算法,引入两大奖励信号,进一步提升模型稳定性与准确性:
- 格式奖励:推理链需严格包含、、标签,无多余内容则得1.0分,否则0分,确保输出结构化。
- 精度奖励:印章识别以“完全匹配”为1.0分,表格识别以TEDS为分数,公式识别以字符检测匹配度(CDM)为分数(CDM=1.0时额外加0.5分),引导模型优先输出正确结果。
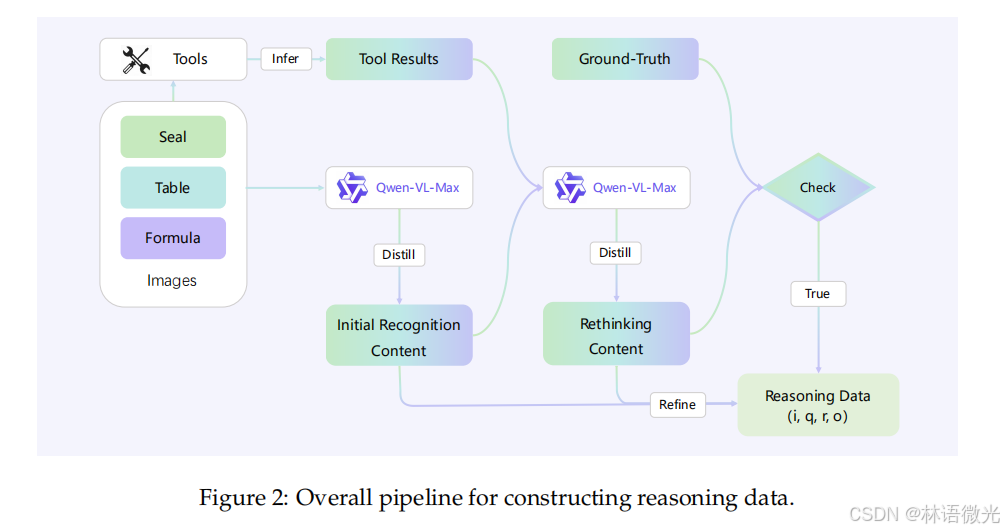
该流程图展示了构建推理数据的整体流程,可分为以下几个关键步骤:
- 工具推理:首先,“Tools”(工具)通过“ Infer”(推理)得到“Tool Results”(工具结果)。同时,包含“Seal”(印章)、“Table”(表格)、“Formula”(公式)等元素的“Images”(图像)输入到“Qwen - VL - Max”模型中。
- 初次识别内容提取:“Qwen - VL - Max”模型对输入的图像进行处理,通过“Distill”(提取、提炼)得到“Initial Recognition Content”(初次识别内容)。
- 反思内容生成:接着,“Initial Recognition Content”与“Tool Results”以及“Ground - Truth”(真实情况)一起再次输入到“Qwen - VL - Max”模型,经过“Distill”得到“Rethinking Content”(反思内容)。
- 内容优化与检查:“Initial Recognition Content”和“Rethinking Content”经过“Refine”(优化)后,与“Ground - Truth”一同进入“Check”(检查)环节。若检查结果为“True”(符合要求),最终生成“Reasoning Data (i, q, r, o)”(推理数据,其中i、q、r、o为相关参数)。
四、实验验证:性能全面超越主流模型
团队在ReST(印章)、OmniDocBench(表格/公式)三大 benchmark 上开展实验,对比了通用LVLMs、专家LVLMs、专家OCR模型三类基线,结果证明DianJin-OCR-R1的优越性。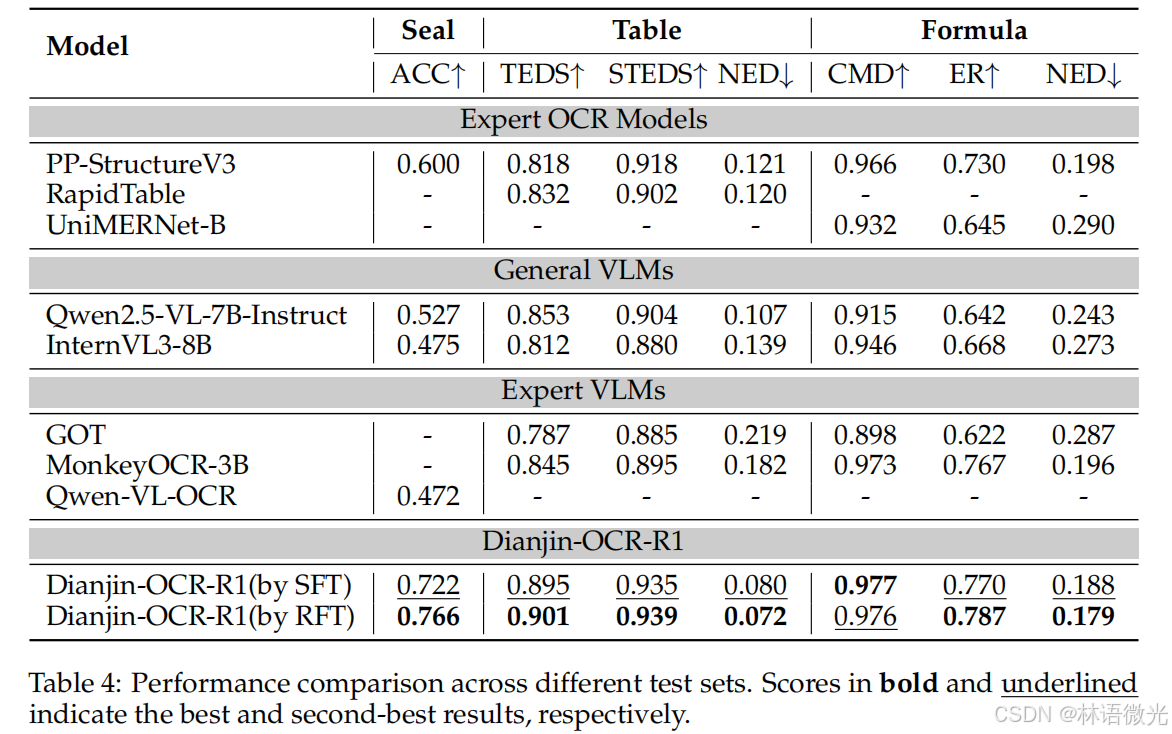
这些指标通常用于评估表格识别相关模型的性能,以下是对各指标的解释:
- Seal - ACC
- 解释:“Seal”可能是特定任务(比如印章相关识别等,结合表格识别场景推测)下的准确率(Accuracy)指标。“ACC↑”表示该指标越高越好,用于衡量模型在“Seal”任务上预测结果与真实结果的匹配程度。
- Table - TEDS
- 解释:TEDS(Table Entity Detection and Structure Recognition)是用于评估表格实体检测与结构识别的指标。“TEDS↑”表示该指标越高越好,它综合衡量模型对表格中单元格、行列结构等实体的检测以及表格整体结构的识别能力。
- Table - STEDS
- 解释:STEDS(Semantic Table Entity Detection and Structure Recognition)可理解为语义层面的表格实体检测与结构识别指标。“STEDS↑”表示该指标越高越好,相比TEDS,它更注重从语义角度(比如单元格内容的语义关联等)对表格实体和结构进行评估。
- Table - NED
- 解释:NED(Normalized Edit Distance)是归一化编辑距离。“NED↓”表示该指标越低越好,编辑距离用于衡量两个序列(比如表格结构的序列表示等)的差异程度,归一化后能在不同规模的“比较对象”间更公平地评估差异,NED低说明模型生成的表格结构与真实结构差异小。
- Formula - CMD
- 解释:CMD(Cell Matching Degree)是单元格匹配度。“CMD↑”表示该指标越高越好,用于衡量模型对表格中单元格(尤其是涉及公式等场景下的单元格)的匹配能力,匹配度高说明模型能较好地识别和对应相关单元格。
- Formula - ER
- 解释:ER(Error Rate)是错误率。“ER↑”这里可能是指标定义特殊(通常错误率是越低越好,结合表格需看具体场景),一般错误率是衡量模型在任务中出错的比例,若“ER↑”是合理的,可能是该“错误率”定义为与“正确识别”正相关的指标(需结合具体研究背景),整体是评估模型在公式相关表格任务中的错误情况。
- Formula - NED
- 解释:同“Table - NED”,是归一化编辑距离,“NED↓”表示该指标越低越好,用于衡量涉及公式的表格结构等与真实情况的差异程度,越低说明差异越小。
4.1 核心指标表现
从表4(性能对比表)可提取关键结论:
- 碾压基础模型:SFT训练后的DianJin-OCR-R1,印章识别准确率从Qwen2.5-VL-7B-Instruct的0.527提升至0.722,表格识别TEDS从0.853提升至0.895,公式识别CDM从0.915提升至0.977,全面突破基础模型瓶颈。
- 超越专家模型:在印章识别上,准确率(0.766,RFT版)高于PP-StructureV3的0.600;表格识别TEDS(0.901,RFT版)高于RapidTable的0.832;公式识别CDM(0.976,RFT版)高于UniMERNet-B的0.932,实现“跨任务优于单任务专家”。
- RFT优于SFT:相同任务下,RFT训练的模型性能普遍高于SFT,如印章识别准确率RFT(0.766)比SFT(0.722)高0.044,证明强化学习能有效提升模型鲁棒性。
4.2 消融实验:关键组件的必要性
为验证“工具调用”和“推理链”的价值,团队开展消融实验(表5),得出三大结论:
- 工具调用是基础:仅给基础模型添加专家工具结果作为参考,印章识别准确率就从0.527提升至0.560,证明专家模型的结果能有效辅助LVLMs。
- 推理链是核心:对比“仅用答案训练”和“用推理链+答案训练”,后者性能显著更高(如SFT+工具的印章准确率0.722,远高于仅SFT的0.643),说明“思考过程”的学习对提升精度至关重要。
- 工具质量影响性能:替换公式识别的工具(用GOT+PP-FormulaNet plus-S替代MonkeyOCR-3B+PP-FormulaNet plus-M),CDM从0.977降至0.969,证明优化小型专家工具能低成本提升整体性能,符合框架设计初衷。
五、总结与展望
DianJin-OCR-R1的核心贡献在于:
- 范式创新:首次将“推理链”与“工具交互”结合,解决了LVLMs的“幻觉”问题与专家模型的“任务单一”问题,实现“1+1>2”的效果。
- 资源高效:无需迭代庞大的LVLMs,仅需优化小型专家模型,降低了技术落地的计算成本与时间成本。
- 性能领先:在多语言、多任务的OCR benchmark上全面超越主流模型,为复杂文档解析(如金融票据、科研论文)提供了实用方案。
未来,该框架可进一步扩展至更多OCR场景(如手写体识别、多语言混合文档),并探索更高效的工具选择策略,让“推理+工具”的范式在更多视觉语言任务中落地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)