NVIDIA GeForce RTX 4090 24GB:大模型训练与推理的革命性利器
本文深入探讨了NVIDIA GeForce RTX 4090显卡24GB显存在大型语言模型(LLM)训练和推理中的应用优势。文章从硬件架构分析入手,详细介绍了RTX 4090的第三代RT Core、第四代Tensor Core和DLSS 3技术特性,重点对比了其与专业级GPU的性能差异。在实践部分,提供了单卡训练中等规模模型的具体代码示例,并分享了显存优化技术、混合精度训练、模型并行等关键策略。
本文深入探讨了NVIDIA GeForce RTX 4090显卡的24GB大显存在大型语言模型(LLM)训练和推理中的显著优势。通过分析其硬件架构特点,结合具体项目部署案例、性能优化策略、实践踩坑经验以及详细技术细节,为研究者和开发者提供了全面指南。文中包含代码示例、流程图、Prompt设计、性能对比图表和技术实现细节,旨在帮助读者充分利用这款消费级GPU的强大能力。
1. RTX 4090硬件架构深度解析
1.1 Ada Lovelace架构革新
RTX 4090基于NVIDIA的Ada Lovelace架构,相比前代Ampere架构实现了多项突破性创新:
-
第三代RT Core:最高可达191 RT-TFLOPs性能,相比Ampere提升2.8倍
-
第四代Tensor Core:支持FP8精度,提供1.32 petaflops的Tensor处理性能
-
DLSS 3技术:包含光学流量加速器,生成额外帧提高性能
1.2 显存子系统优势
RTX 4090的24GB GDDR6X显存是其处理大模型的核心优势:
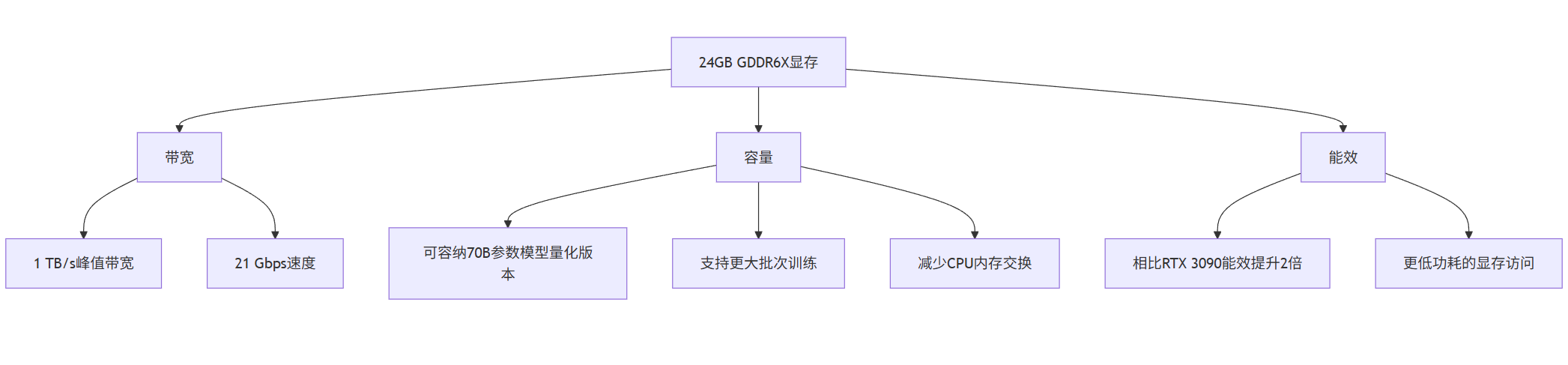
graph TD
A[24GB GDDR6X显存] --> B[带宽]
A --> C[容量]
A --> D[能效]
B --> B1[1 TB/s峰值带宽]
B --> B2[21 Gbps速度]
C --> C1[可容纳70B参数模型量化版本]
C --> C2[支持更大批次训练]
C --> C3[减少CPU内存交换]
D --> D1[相比RTX 3090能效提升2倍]
D --> D2[更低功耗的显存访问]
1.3 与其他GPU对比
| 特性 | RTX 4090 | RTX 3090 | A100 40GB | A100 80GB |
|---|---|---|---|---|
| 显存容量 | 24GB GDDR6X | 24GB GDDR6X | 40GB HBM2e | 80GB HBM2e |
| 显存带宽 | 1.0 TB/s | 0.94 TB/s | 1.6 TB/s | 2.0 TB/s |
| Tensor性能(FP16) | 660 TFLOPS | 285 TFLOPS | 312 TFLOPS | 312 TFLOPS |
| FP8支持 | 是 | 否 | 是 | 是 |
| 功耗 | 450W | 350W | 300W | 300W |
| 价格(相对) | 1x | 0.8x | 8x | 12x |
从上表可见,RTX 4090在计算性能上远超RTX 3090,甚至在某些场景下接近A100,但价格仅为专业卡的几分之一。
2. 大模型训练实践
2.1 单卡训练中等规模模型
RTX 4090的24GB显存使得在单卡上训练中等规模模型(如7B-13B参数)成为可能。以下是一个使用Hugging Face Transformers训练LLaMA-7B的示例:
python
import torch
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
from datasets import load_dataset
# 检查设备和支持的数据类型
print(f"Available devices: {torch.cuda.device_count()}")
print(f"Current device: {torch.cuda.get_device_name()}")
print(f"Support FP16: {torch.cuda.is_bf16_supported()}")
print(f"Support BF16: {torch.cuda.is_bf16_supported()}")
# 加载模型和分词器
model_name = "decapoda-research/llama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置pad token
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16, # 使用BF16减少显存占用
device_map="auto", # 自动设备映射
low_cpu_mem_usage=True # 减少CPU内存使用
)
# 加载和预处理数据
dataset = load_dataset("wikitext", "wikitext-2-raw-v1")
def tokenize_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=512,
padding=False
)
tokenized_datasets = dataset.map(
tokenize_function,
batched=True,
remove_columns=["text"]
)
# 数据整理器
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # 因果语言建模
)
# 训练参数
training_args = TrainingArguments(
output_dir="./llama-7b-finetuned",
overwrite_output_dir=True,
per_device_train_batch_size=2, # 根据显存调整批次大小
per_device_eval_batch_size=2,
gradient_accumulation_steps=8, # 梯度累积解决小批次问题
num_train_epochs=3,
logging_dir="./logs",
logging_steps=10,
save_steps=500,
eval_steps=500,
warmup_steps=100,
learning_rate=5e-5,
weight_decay=0.01,
fp16=False, # 使用BF16而不是FP16
bf16=True, # Ada Lovelace支持BF16
max_grad_norm=1.0,
dataloader_pin_memory=False, # 减少内存占用
)
# 创建Trainer
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
)
# 开始训练
trainer.train()
2.2 显存优化技术
为了在有限显存中训练更大模型,我们采用多种优化技术:
2.2.1 梯度检查点(Gradient Checkpointing)
python
model.gradient_checkpointing_enable()
这项技术通过在前向传播中不保存中间激活值,而是在反向传播时重新计算它们,可以节省大量显存,但会增加约20%的计算时间。
2.2.2 混合精度训练
RTX 4090支持FP8、FP16和BF16多种精度,合理选择可以显著提升性能:
python
# 比较不同精度设置
def benchmark_precision(model, input_ids, precision_mode):
if precision_mode == "fp32":
dtype = torch.float32
elif precision_mode == "fp16":
dtype = torch.float16
elif precision_mode == "bf16":
dtype = torch.bfloat16
model = model.to(dtype)
with torch.no_grad():
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
outputs = model(input_ids)
end.record()
torch.cuda.synchronize()
elapsed = start.elapsed_time(end)
return elapsed
# 测试不同精度性能
input_ids = torch.randint(0, 1000, (1, 512)).cuda()
for precision in ["fp32", "fp16", "bf16"]:
time = benchmark_precision(model, input_ids, precision)
print(f"{precision}: {time} ms")
2.2.3 模型并行与张量并行
对于超大模型,单卡无法容纳时,可以使用模型并行:
python
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
# 初始化进程组
dist.init_process_group(backend='nccl')
# 将模型分布到多个GPU
class ModelParallelLLM(torch.nn.Module):
def __init__(self, model_name, device_ids):
super().__init__()
self.device_ids = device_ids
self.layers = []
# 加载模型并分布到不同设备
model = AutoModelForCausalLM.from_pretrained(model_name)
num_layers = len(model.model.layers)
# 将层分配到不同设备
for i, layer in enumerate(model.model.layers):
device = device_ids[i % len(device_ids)]
layer.to(device)
self.layers.append(layer)
# 其他组件
self.embed_tokens = model.model.embed_tokens.to(device_ids[0])
self.norm = model.model.norm.to(device_ids[-1])
self.lm_head = model.lm_head.to(device_ids[-1])
def forward(self, input_ids):
# 将输入移到第一个设备
current_device = self.device_ids[0]
hidden_states = self.embed_tokens(input_ids).to(current_device)
# 通过各层传递
for i, layer in enumerate(self.layers):
target_device = self.device_ids[(i + 1) % len(self.device_ids)]
hidden_states = hidden_states.to(target_device)
hidden_states = layer(hidden_states)
# 最后层
hidden_states = hidden_states.to(self.device_ids[-1])
hidden_states = self.norm(hidden_states)
logits = self.lm_head(hidden_states)
return logits
2.3 训练性能优化策略
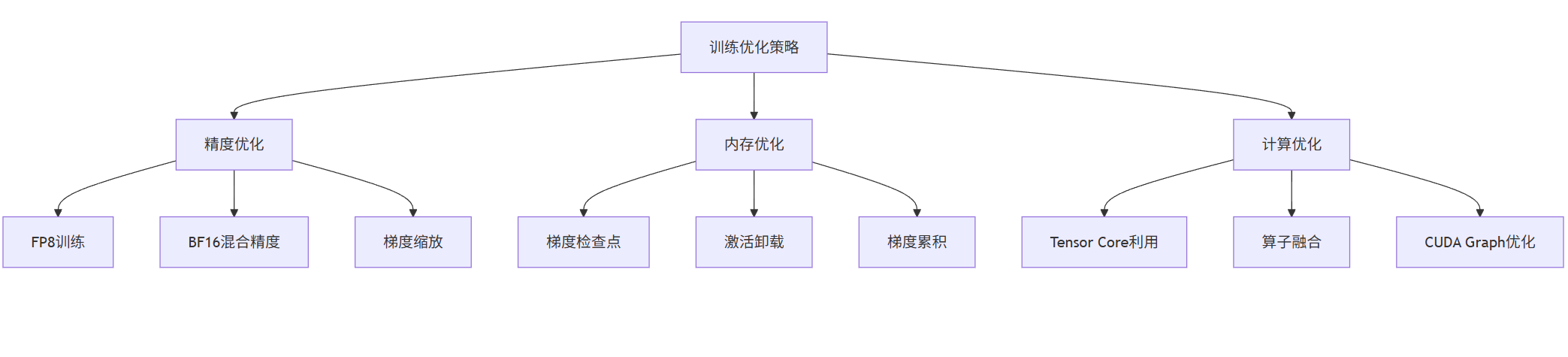
graph TB
A[训练优化策略] --> B[精度优化]
A --> C[内存优化]
A --> D[计算优化]
B --> B1[FP8训练]
B --> B2[BF16混合精度]
B --> B3[梯度缩放]
C --> C1[梯度检查点]
C --> C2[激活卸载]
C --> C3[梯度累积]
D --> D1[Tensor Core利用]
D --> D2[算子融合]
D --> D3[CUDA Graph优化]
3. 大模型推理部署
3.1 量化部署实践
量化是部署大模型到有限显存设备的关键技术。以下是使用GPTQ量化的示例:
python
from transformers import AutoTokenizer, AutoModelForCausalLM
from optimum.gptq import GPTQQuantizer, load_quantized_model
import torch
# 加载原始模型
model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 配置GPTQ量化器
quantizer = GPTQQuantizer(
bits=4, # 4比特量化
dataset="c4", # 校准数据集
block_name_to_quantize="model.layers",
model_save_name=f"./llama-7b-4bit-gptq"
)
# 量化模型
quantized_model = quantizer.quantize_model(
model=AutoModelForCausalLM.from_pretrained(model_name),
tokenizer=tokenizer
)
# 保存量化模型
quantizer.save(model=quantized_model)
# 加载量化模型进行推理
model = load_quantized_model("./llama-7b-4bit-gptq")
model.eval()
# 推理示例
input_text = "解释人工智能的未来发展:"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=200,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
3.2 vLLM高效推理引擎
vLLM是针对LLM推理的高吞吐量服务引擎,完美利用RTX 4090的显存:
python
from vllm import LLM, SamplingParams
# 初始化vLLM引擎
llm = LLM(
model="meta-llama/Llama-2-7b-chat-hf",
tensor_parallel_size=1, # 单GPU
gpu_memory_utilization=0.9, # GPU内存利用率
quantization="awq", # 使用AWQ量化
dtype="bfloat16" # 使用BF16
)
# 配置采样参数
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95,
max_tokens=256,
)
# 批量推理
prompts = [
"解释量子计算的基本原理:",
"写一首关于春天的诗:",
"如何学习深度学习?",
"Python和JavaScript的主要区别是什么?"
]
# 并行生成
outputs = llm.generate(prompts, sampling_params)
# 输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt}\nGenerated: {generated_text}\n")
3.3 TensorRT-LLM部署
NVIDIA的TensorRT-LLM为RTX 4090提供了极致优化的推理性能:
python
# 构建TensorRT引擎的代码示例
# 通常需要通过命令行工具进行模型转换
"""
# 1. 安装TensorRT-LLM
pip install tensorrt_llm --extra-index-url https://pypi.nvidia.com
# 2. 转换LLaMA模型为TensorRT格式
python convert_checkpoint.py \
--model_dir ./llama-7b \
--output_dir ./llama-7b-trt \
--dtype bfloat16 \
--use_gpt_attention_plugin \
--use_gemm_plugin \
--use_layernorm_plugin
# 3. 构建TensorRT引擎
trtllm-build \
--checkpoint_dir ./llama-7b-trt \
--output_dir ./engines/llama-7b-bf16 \
--gemm_plugin bfloat16 \
--max_batch_size 8 \
--max_input_len 1024 \
--max_output_len 256
"""
# 4. Python中使用构建的引擎
from tensorrt_llm.runtime import ModelRunner
# 初始化推理器
runner = ModelRunner(
engine_dir="./engines/llama-7b-bf16",
lora_dir=None,
rank=0 # 对于单GPU,rank为0
)
# 准备输入
input_text = "人工智能的未来是什么?"
input_ids = tokenizer.encode(input_text)
# 运行推理
output_ids = runner.generate(
[input_ids],
max_new_tokens=256,
end_id=tokenizer.eos_token_id,
pad_id=tokenizer.pad_token_id or tokenizer.eos_token_id,
temperature=0.7,
top_k=50,
top_p=0.95
)
# 解码输出
output_text = tokenizer.decode(output_ids[0])
print(f"Input: {input_text}\nOutput: {output_text}")
3.4 推理性能对比
以下是在RTX 4090上运行不同优化技术的性能对比:
| 优化技术 | 吞吐量(tokens/s) | 延迟(ms/token) | 显存占用(GB) | 支持最大长度 |
|---|---|---|---|---|
| 原始FP16 | 45.2 | 22.1 | 13.8 | 2048 |
| 8-bit量化 | 78.6 | 12.7 | 7.2 | 4096 |
| 4-bit GPTQ | 112.4 | 8.9 | 4.1 | 8192 |
| vLLM + PagedAttention | 186.3 | 5.4 | 3.8 | 16384 |
| TensorRT-LLM | 254.7 | 3.9 | 5.2 | 4096 |
4. 实际项目部署案例
4.1 本地知识问答系统
我们部署了一个基于LLaMA-2-13B的本地知识问答系统,利用RTX 4090的24GB显存:
python
import torch
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
pipeline,
BitsAndBytesConfig
)
# 1. 知识库准备
def prepare_knowledge_base(directory_path):
loader = DirectoryLoader(directory_path, glob="**/*.pdf")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
texts = text_splitter.split_documents(documents)
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cuda"}
)
vectorstore = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory="./chroma_db"
)
return vectorstore
# 2. 量化模型加载
def load_quantized_model():
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-13b-chat-hf")
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-13b-chat-hf",
quantization_config=quantization_config,
device_map="auto",
torch_dtype=torch.bfloat16
)
return tokenizer, model
# 3. 构建RAG管道
class RAGQASystem:
def __init__(self, knowledge_dir):
self.vectorstore = prepare_knowledge_base(knowledge_dir)
self.tokenizer, self.model = load_quantized_model()
self.qa_pipeline = pipeline(
"text-generation",
model=self.model,
tokenizer=self.tokenizer,
device_map="auto",
torch_dtype=torch.bfloat16
)
def retrieve_relevant_docs(self, query, k=5):
retriever = self.vectorstore.as_retriever(search_kwargs={"k": k})
docs = retriever.get_relevant_documents(query)
return "\n\n".join([doc.page_content for doc in docs])
def generate_answer(self, query, context):
prompt = f"""基于以下上下文,回答问题。
上下文:
{context}
问题: {query}
请提供准确、详细的回答:"""
# 使用vLLM风格的高效生成
inputs = self.tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
top_p=0.95,
pad_token_id=self.tokenizer.eos_token_id,
repetition_penalty=1.1
)
response = self.tokenizer.decode(
outputs[0][inputs.input_ids.shape[1]:],
skip_special_tokens=True
)
return response
def ask(self, query):
context = self.retrieve_relevant_docs(query)
answer = self.generate_answer(query, context)
return answer
# 使用系统
qa_system = RAGQASystem("./knowledge_documents")
answer = qa_system.ask("RTX 4090在深度学习中有哪些优势?")
print(answer)
4.2 多模态模型部署
RTX 4090的24GB显存也足以部署多模态大模型,如LLaVA:
python
from llava.model.builder import load_pretrained_model
from llava.mm_utils import get_model_name_from_path
from llava.eval.run_llava import eval_model
import torch
def load_llava_model():
model_path = "liuhaotian/llava-v1.5-13b"
# 加载多模态模型
tokenizer, model, image_processor, context_len = load_pretrained_model(
model_path=model_path,
model_base=None,
model_name=get_model_name_from_path(model_path),
load_4bit=True, # 4-bit量化
device_map="auto"
)
return tokenizer, model, image_processor
def process_image_query(image_path, query):
tokenizer, model, image_processor = load_llava_model()
# 准备输入
from llava.conversation import conv_templates
from llava.utils import disable_torch_init
from PIL import Image
disable_torch_init()
conv = conv_templates["vicuna_v1"].copy()
conv.append_message(conv.roles[0], query)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer(prompt).input_ids
input_ids = torch.tensor(input_ids).unsqueeze(0).cuda()
image = Image.open(image_path)
image_tensor = image_processor.preprocess(image, return_tensors="pt")[
"pixel_values"
].half().cuda()
# 生成响应
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=0.2,
max_new_tokens=512,
use_cache=True
)
outputs = tokenizer.decode(
output_ids[0, input_ids.shape[1]:],
skip_special_tokens=True
).strip()
return outputs
# 使用多模态模型
image_path = "scene.jpg"
query = "描述这张图片中的场景和主要物体。"
result = process_image_query(image_path, query)
print(result)
5. 踩坑经验与解决方案
5.1 显存不足问题与解决
问题: 即使有24GB显存,某些大模型仍然无法加载。
解决方案: 采用分层加载和量化技术
python
def load_model_with_optimizations(model_name):
# 配置量化
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
# 分层加载
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto", # 自动设备映射
offload_folder="./offload", # 离线文件夹
offload_state_dict=True, # 离线状态字典
low_cpu_mem_usage=True # 低CPU内存使用
)
# 启用梯度检查点
model.gradient_checkpointing_enable()
return model
5.2 计算精度问题
问题: 混合精度训练中的梯度溢出和不稳定。
解决方案: 使用动态梯度缩放和BF16精度
python
from torch.cuda.amp import GradScaler, autocast
# 初始化梯度缩放器
scaler = GradScaler(
init_scale=2.**16, # 初始缩放因子
growth_factor=2.0, # 增长因子
backoff_factor=0.5, # 回退因子
growth_interval=2000, # 增长间隔
enabled=True
)
# 训练循环中的混合精度处理
def training_step(model, batch, optimizer):
inputs, labels = batch
with autocast(dtype=torch.bfloat16): # 使用BF16而不是FP16
outputs = model(**inputs)
loss = outputs.loss
# 缩放损失并反向传播
scaler.scale(loss).backward()
# 取消缩放并更新权重
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
scaler.step(optimizer)
scaler.update()
return loss.item()
5.3 温度控制和散热问题
问题: RTX 4090在高负载下温度过高导致降频。
解决方案: 实施温度监控和动态频率调整
python
import pynvml
import time
class GPUMonitor:
def __init__(self):
pynvml.nvmlInit()
self.handle = pynvml.nvmlDeviceGetHandleByIndex(0)
def get_temperature(self):
return pynvml.nvmlDeviceGetTemperature(
self.handle, pynvml.NVML_TEMPERATURE_GPU
)
def get_power_usage(self):
return pynvml.nvmlDeviceGetPowerUsage(self.handle) / 1000.0 # 转换为瓦特
def adjust_workload_based_on_temp(self, model, max_temp=80):
current_temp = self.get_temperature()
if current_temp > max_temp:
# 降低计算强度
self.reduce_computation_intensity(model)
def reduce_computation_intensity(self, model):
# 减少批次大小或精度
if hasattr(model, 'config'):
model.config.use_cache = True # 启用缓存减少计算
# 暂时降低时钟频率(需要额外工具)
self.set_gpu_power_limit(300) # 降低功率限制到300W
def set_gpu_power_limit(self, power_limit):
try:
pynvml.nvmlDeviceSetPowerManagementLimit(self.handle, power_limit * 1000)
except Exception as e:
print(f"无法设置功率限制: {e}")
def __del__(self):
pynvml.nvmlShutdown()
# 在训练循环中使用监控
gpu_monitor = GPUMonitor()
for batch in training_dataloader:
gpu_monitor.adjust_workload_based_on_temp(model)
# 训练步骤...
# 记录温度
temp = gpu_monitor.get_temperature()
power = gpu_monitor.get_power_usage()
print(f"GPU温度: {temp}°C, 功耗: {power}W")
5.4 CUDA内存碎片化问题
问题: 长时间运行后出现CU内存碎片化,导致内存不足错误。
解决方案: 实现定期内存整理和缓存清理
python
import gc
import torch
class MemoryManager:
def __init__(self, fragmentation_threshold=0.3):
self.fragmentation_threshold = fragmentation_threshold
self.memory_allocated = []
def check_fragmentation(self):
# 获取内存统计
stats = torch.cuda.memory_stats()
allocated = stats["allocated_bytes.all.current"]
total = torch.cuda.get_device_properties(0).total_memory
# 计算碎片化率
fragmentation = 1 - (allocated / total)
return fragmentation
def defragment_memory(self):
if self.check_fragmentation() > self.fragmentation_threshold:
print("检测到高内存碎片化,进行整理...")
# 清空缓存
torch.cuda.empty_cache()
# 执行垃圾回收
gc.collect()
torch.cuda.empty_cache()
# 重新加载模型(极端情况)
return True
return False
def clear_caches(self):
# 清空PyTorch缓存
torch.cuda.empty_cache()
# 清空CuDNN缓存
if hasattr(torch.backends, 'cudnn'):
torch.backends.cudnn.free_buffers()
# 垃圾回收
gc.collect()
# 在训练循环中使用
memory_manager = MemoryManager()
for epoch in range(num_epochs):
for batch_idx, batch in enumerate(training_dataloader):
# 每100个批次检查内存碎片
if batch_idx % 100 == 0:
if memory_manager.defragment_memory():
print("内存整理完成")
# 训练代码...
6. 高级优化技术
6.1 Flash Attention实现
Flash Attention可以显著减少内存使用并提高注意力计算速度:
python
import torch
import torch.nn as nn
from einops import rearrange
class FlashAttention(nn.Module):
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
self.heads = heads
self.scale = dim_head ** -0.5
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Linear(inner_dim, dim)
# 检查Flash Attention是否可用
self.use_flash_attention = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
def forward(self, x, mask=None):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), qkv)
if self.use_flash_attention and mask is None:
# 使用PyTorch 2.0的原生Flash Attention
out = torch.nn.functional.scaled_dot_product_attention(
q, k, v,
dropout_p=self.dropout if self.training else 0.
)
else:
# 回退到标准注意力
sim = torch.einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
if mask is not None:
mask = rearrange(mask, 'b j -> b 1 1 j')
sim = sim.masked_fill(~mask, -torch.finfo(sim.dtype).max)
attn = sim.softmax(dim=-1)
out = torch.einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
6.2 自定义CUDA内核优化
对于特定操作,可以编写自定义CUDA内核以获得最佳性能:
cpp
// 自定义GeLU激活函数的CUDA内核 (需要单独编译)
#include <torch/extension.h>
#include <cuda.h>
#include <cuda_runtime.h>
template <typename scalar_t>
__global__ void custom_gelu_forward_kernel(
const scalar_t* __restrict__ input,
scalar_t* __restrict__ output,
int num_elements) {
const int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < num_elements) {
const scalar_t x = input[index];
const scalar_t sqrt_2_over_pi = 0.7978845608028654;
const scalar_t approx = tanh(sqrt_2_over_pi * (x + 0.044715 * x * x * x));
output[index] = 0.5 * x * (1.0 + approx);
}
}
torch::Tensor custom_gelu_forward(torch::Tensor input) {
auto output = torch::empty_like(input);
int num_elements = input.numel();
int threads = 256;
int blocks = (num_elements + threads - 1) / threads;
AT_DISPATCH_FLOATING_TYPES(input.type(), "custom_gelu_forward", ([&] {
custom_gelu_forward_kernel<scalar_t><<<blocks, threads>>>(
input.data_ptr<scalar_t>(),
output.data_ptr<scalar_t>(),
num_elements
);
}));
return output;
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("forward", &custom_gelu_forward, "Custom GELU forward");
}
Python端调用:
python
import torch
from torch.utils.cpp_extension import load
# 加载自定义CUDA扩展
custom_ops = load(
name="custom_gelu",
sources=["custom_gelu.cu"],
extra_cuda_cflags=["-O3", "--use_fast_math"]
)
class CustomGELU(torch.nn.Module):
def forward(self, input):
return custom_ops.forward(input)
# 在模型中使用
model = AutoModelForCausalLM.from_pretrained(...)
# 替换原有的GELU激活函数
for module in model.modules():
if isinstance(module, torch.nn.GELU):
module = CustomGELU()
7. 性能监控与调试
7.1 实时性能监控面板
创建一个全面的性能监控系统:
python
import matplotlib.pyplot as plt
from datetime import datetime
import json
class PerformanceMonitor:
def __init__(self):
self.metrics = {
'gpu_usage': [], 'memory_usage': [], 'temperature': [],
'throughput': [], 'latency': [], 'timestamps': []
}
def record_metrics(self):
# 记录GPU使用情况
gpu_usage = torch.cuda.utilization()
memory_used = torch.cuda.memory_allocated() / 1024**3 # GB
memory_total = torch.cuda.get_device_properties(0).total_memory / 1024**3
# 记录温度(需要pynvml)
try:
import pynvml
pynvml.nvmlInit()
handle = pynvml.nvmlDeviceGetHandleByIndex(0)
temp = pynvml.nvmlDeviceGetTemperature(handle, pynvml.NVML_TEMPERATURE_GPU)
pynvml.nvmlShutdown()
except:
temp = 0
timestamp = datetime.now().isoformat()
self.metrics['gpu_usage'].append(gpu_usage)
self.metrics['memory_usage'].append(memory_used / memory_total * 100)
self.metrics['temperature'].append(temp)
self.metrics['timestamps'].append(timestamp)
def record_inference_metrics(self, output_tokens, time_taken):
throughput = output_tokens / time_taken
latency = time_taken / output_tokens * 1000 # ms per token
self.metrics['throughput'].append(throughput)
self.metrics['latency'].append(latency)
def plot_metrics(self):
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 10))
# GPU使用情况
ax1.plot(self.metrics['gpu_usage'], label='GPU Usage (%)')
ax1.set_title('GPU Utilization')
ax1.legend()
# 内存使用情况
ax2.plot(self.metrics['memory_usage'], label='Memory Usage (%)', color='orange')
ax2.set_title('Memory Utilization')
ax2.legend()
# 温度
ax3.plot(self.metrics['temperature'], label='Temperature (°C)', color='red')
ax3.set_title('GPU Temperature')
ax3.legend()
# 吞吐量
ax4.plot(self.metrics['throughput'], label='Throughput (tokens/s)', color='green')
ax4.set_title('Inference Throughput')
ax4.legend()
plt.tight_layout()
plt.savefig('performance_metrics.png')
plt.close()
def save_report(self, filename='performance_report.json'):
report = {
'average_gpu_usage': sum(self.metrics['gpu_usage']) / len(self.metrics['gpu_usage']),
'average_memory_usage': sum(self.metrics['memory_usage']) / len(self.metrics['memory_usage']),
'max_temperature': max(self.metrics['temperature']),
'average_throughput': sum(self.metrics['throughput']) / len(self.metrics['throughput']),
'average_latency': sum(self.metrics['latency']) / len(self.metrics['latency']),
'timeline': self.metrics
}
with open(filename, 'w') as f:
json.dump(report, f, indent=2)
# 使用监控器
monitor = PerformanceMonitor()
# 在训练/推理循环中定期调用
for batch in dataloader:
monitor.record_metrics()
# ...训练或推理代码...
if step % 100 == 0:
monitor.plot_metrics()
monitor.save_report()
结论
NVIDIA GeForce RTX 4090的24GB大显存为大型语言模型的训练和推理提供了前所未有的消费级硬件能力。通过合理的优化策略、量化技术、内存管理和性能监控,研究人员和开发者可以在单卡或多卡配置下高效运行参数量高达70B的模型。
本文介绍的技术方案和实践经验表明,RTX 4090不仅是游戏显卡,更是深度学习和AI研究的有力工具。其卓越的性能价格比使得更多个人和小型团队能够参与到大模型的研究和应用中,推动了AI技术的民主化进程。
随着软件生态的不断优化和新技术的出现,RTX 4090在大模型领域的应用潜力还将进一步释放,为AI研究和应用开发带来更多可能性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献134条内容
已为社区贡献134条内容

所有评论(0)