使用AutoDL平台训练自己的YOLO模型,以YOLO11为例
使用自己的电脑配置较低,训练慢。选择云算力是性价比高的选择,现在市面上有很多算力平台,我这里就以AtuoDL为例(无广)。来实现训练自己的YOLO11模型,如果需要训练其他一些版本的YOLO模型也同理都用ultralytics即可,使用自己的数据集无非就是自己写一下简单的配置。下面将会详细介绍该过程。
一.准备操作
1.租用算力服务器
首先需要来到算力市场创建一个满足自己要求的算力实例,我这里采用按量计费租L20一张显卡。
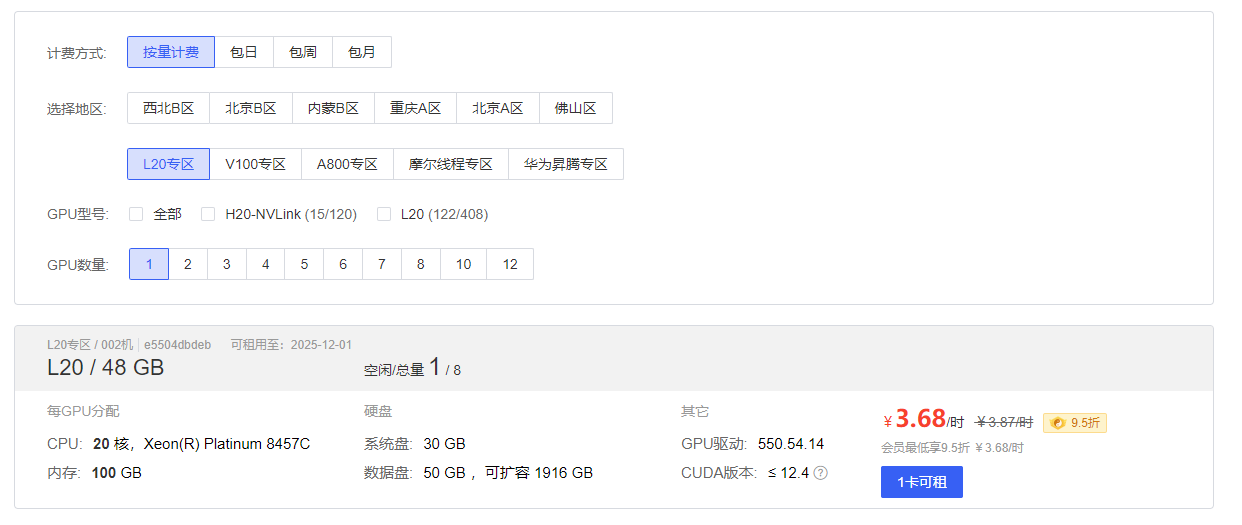
2.配置镜像
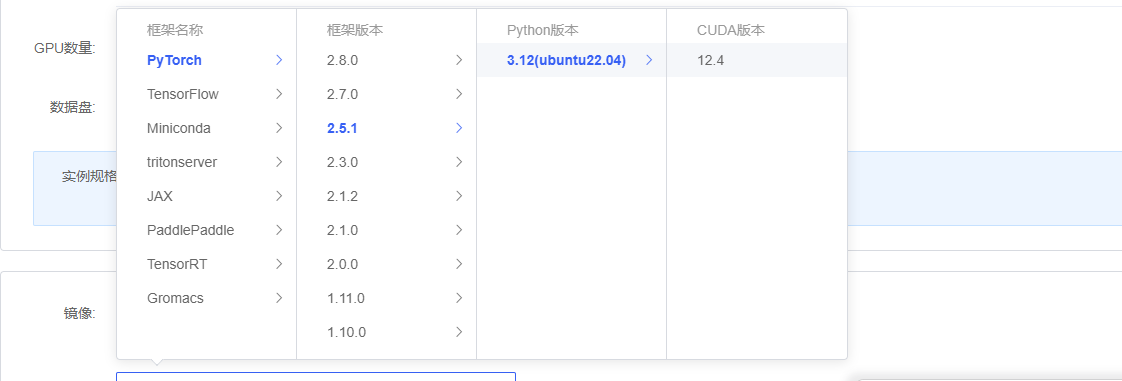
接着选择镜像同时选择基础配置,我这里选择适用PyTorch2.51,Python3.12,CUDA选择12.4。配置后点击开机即可。
3.无卡模式开机
随后进入控制台即可看见刚才创建的容器实例,先关机后选择无卡模式开机,进行基础配置。

4.登录方式选择
可以选择自己喜欢的方式登录SSH或者使用Jupyter,我这里使用XTerminal。
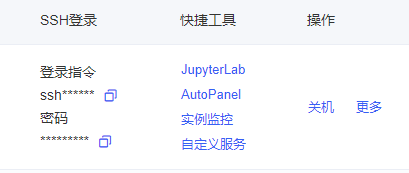
在复制登录指令后获取地址,用户与端口信息。

二.配置环境
1.conda
在默认环境中已经配置了miniconda,直接使用即可。

首先需要创建一个conda环境:
conda create -n yolo python==3.10等待完成后激活环境:
conda activate yolo如果出现:

就先执行:
conda init后重启后再激活环境
2.ultralytics
pip install ultralytics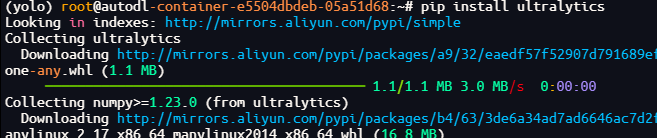
等待完成。
三.准备数据集与三个文件
1.数据集
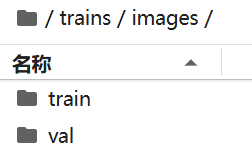
在数据集的准备上,也就是下图的images与labels,两个文件夹中均包含train与val,分别用于存储对应的图片与标签文件。

2.data.yaml
在这里使用的是YOLO11模型,所以需要准备预训练模型yolo11n.pt。接着编辑data.yaml用于配置数据集信息:
train: ./images/train
val: ./images/val
nc: 1
names:
- person
如上代码所示:
train 指定的是训练集的图片所在目录
val 指定的是验证集的图片所在目录
nc: 类别数量,如仅有person一个类别就为1,具体数量需要自己确定
names: 每个类别标签
3.train.py
在上述文件准备好后,创建文件train.py,注意参数需要按照实际情况修改,编辑训练:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'yolo11n.pt') # 预训练模型
model.train(
data=r'data.yaml', # 数据集配置文件
imgsz=640, # 图像输入大小默认640*640
epochs=50, # 训练轮数
batch=32, # 批次
workers=8, # CPU线程数
device='0', # 指定显卡
single_cls=true, # 是否单类别,因为上边的数据集中只有person
)
python train.py四.查看与下载训练结果
训练完成后可以在train.py的同级目录下打开run/detect/train 包含训练结果信息,其中的weights中的best.pt为训练好的模型。
附:
如果训练时间较长,同时网络不稳定建议在训练之前使用screen工具确保可以保持训练。
使用方式很简单。在激活conda环境前使用:
screen -S screen_name进入单独的screen再进行环境激活开启训练,此时可以断开ssh链接,如果再次登录需要进入训练查看的screen可以直接执行:
screen -r screen_name
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)