通义甩出王炸!首个全开源DeepResearch诞生,性能硬刚OpenAI!
通义DeepDeepResearch:开启开源 AI 研究智能体的新纪元。
通义DeepDeepResearch:开启开源 AI 研究智能体的新纪元
- GitHub:https://github.com/Alibaba-NLP/DeepResearch
- HuggingFace:https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
- ModelScope:https://modelscope.cn/models/iic/Tongyi-DeepResearch-30B-A3B
- Demo:https://tongyi-agent.github.io/showcase/
- Blog:https://tongyi-agent.github.io/zh/blog/introducing-tongyi-deep-research/
从聊天机器人到自主智能体
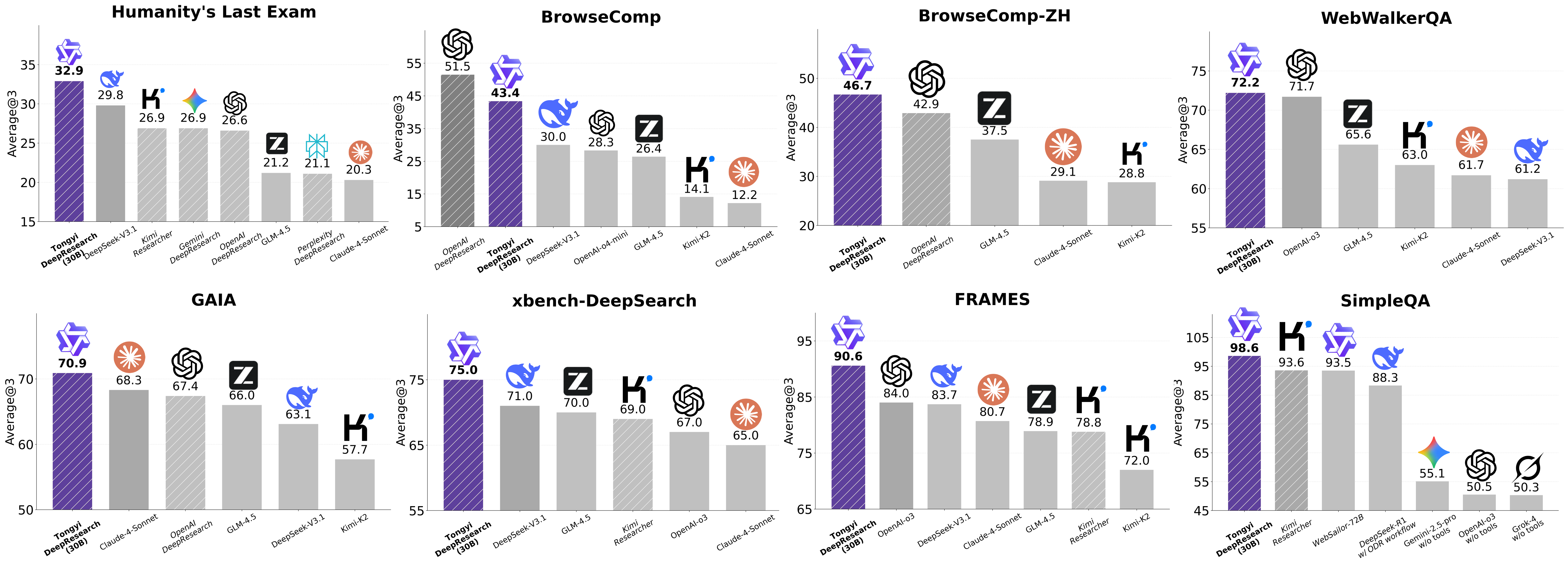
最近,阿里团队推出了 通义深度研究 (Tongyi DeepResearch),这是首个完全开源的网络智能体 (Web Agent),在一系列基准测试中,它的表现足以和 OpenAI 的同类研究智能体相媲美。
通义深度研究展现了当前最顶尖的水平,具体来看:
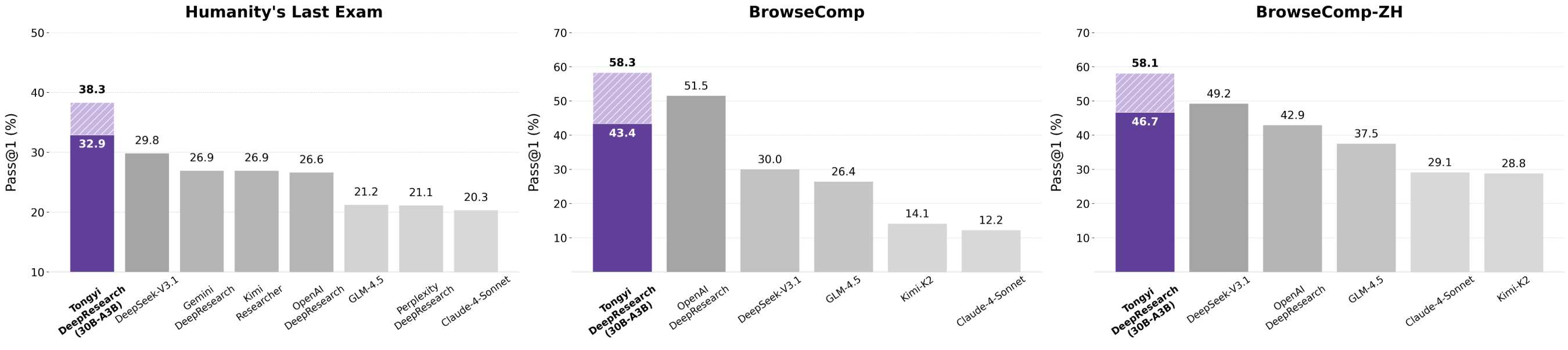
- 在学术推理任务 HLE (Humanity’s Last Exam) 中得分 32.9
- 在极其复杂的信息检索任务 BrowseComp 中得分 43.4
- 在中文信息检索任务 BrowseComp-ZH 中得分 46.7
- 在以用户为中心的 xbench-DeepSearch 基准测试中得分 75
这些成绩全面超越了市面上所有现有的闭源和开源同类研究智能体。
除了模型本身,该项目还分享了一套完整且经过实战检验的方法论,揭示了如何打造这样一个先进的智能体。其核心贡献在于一套新颖的数据合成方案,这套方案贯穿了整个训练流程——从用于冷启动的智能体持续预训练 (Agentic CPT) 和监督微调 (SFT),一直到最后的强化学习 (RL) 阶段。
特别是在强化学习方面,团队提供了一套全栈解决方案,涵盖了算法创新、自动化数据整理和强大的基础设施。而在推理层面,通用的 ReAct 框架展示了模型无需任何提示工程就具备的强大内在能力;而先进的“重度模式” (Heavy Mode) 则进一步挖掘了其复杂推理和规划能力的上限。
全合成数据驱动:从持续预训练到后训练
持续预训练数据
为了给后续的训练流程打下一个坚实的智能体基础模型,团队首次将智能体持续预训练 (Agentic CPT) 的概念引入研究型智能体的训练中。为此,他们提出了 AgentFounder,一个系统化、可扩展的大规模数据合成方案,它通过整个后训练流程的数据,创造了一个数据飞轮。
1. 数据重组与问题构建
这个方案会持续从各种来源收集数据,包括文档、公开网页数据、知识图谱,以及历史轨迹和工具调用记录(比如带链接的搜索结果)。如下图所示,这些五花八门的数据源被重构成以实体为核心的开放世界知识记忆库。然后,基于随机采样的实体及其相关知识,生成各种风格的(问题,答案)对。
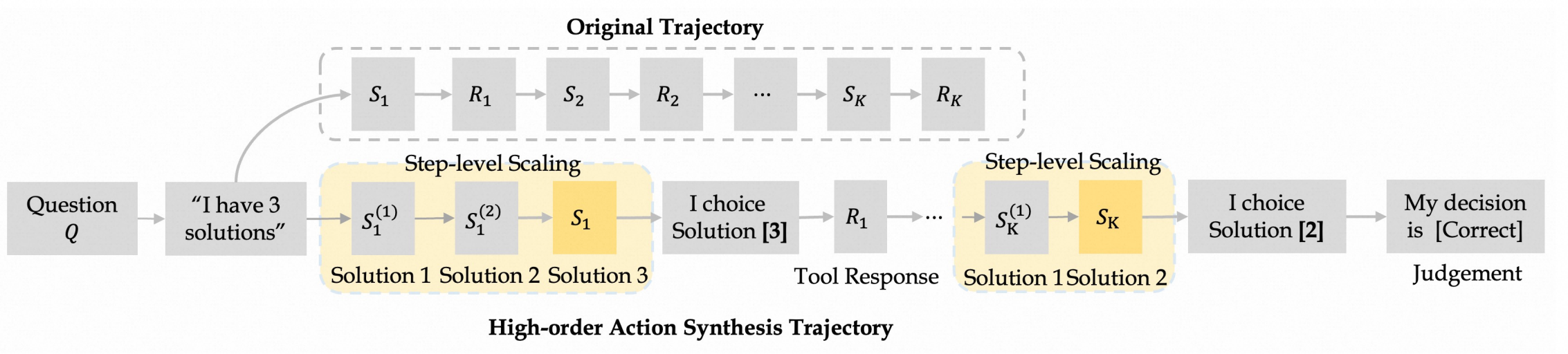
2. 动作合成
基于多样化的问题和历史轨迹,团队构建了两种动作合成数据:一阶动作和高阶动作。这种方法能够在离线环境中大规模、全面地探索潜在的推理-行动空间,从而避免了对商业工具 API 的额外调用。特别是在高阶动作合成中,轨迹被重塑为多步决策过程,以此来增强模型的决策能力。
后训练数据
高质量的合成问答对
为了突破 AI 智能体的性能极限,团队开发了一套端到端的全自动化数据合成解决方案。这个过程无需任何人工干预,就能构建出超高质量的数据集。这套方法经过了长期的探索和迭代——从早期通过逆向工程从点击流生成问答对(WebWalker),到更系统的基于图谱的合成方法(WebSailor),再到形式化的任务建模(WebShaper),最终确保了卓越的数据质量和大规模的可扩展性。
为了解决那些复杂且不确定性高的问题,团队通过一个新颖的流程来合成基于网络的问答数据。
- 首先,通过随机游走和同构表构建,从真实网站数据中建立高度互联的知识图谱,确保了信息的真实结构。
- 然后,对子图和子表进行采样,生成初始的问题和答案。
- 最关键的一步,是通过巧妙地模糊或混淆问题中的信息来刻意增加难度。这种方法背后有完整的理论框架支撑,将问答难度形式化建模为实体关系上的一系列可控“原子操作”(例如,合并属性相似的实体),从而能够系统地提升问题的复杂度。
此外,为了进一步减少结构化信息与问答推理结构之间的差异,实现更可控的难度扩展,团队基于集合论对信息检索问题进行了形式化建模。通过这种形式化,开发出的智能体能够以受控的方式扩展问题,最大限度地减少推理捷径和结构冗余,进一步提高了问答质量。同时,这种形式化建模也让问答正确性的验证变得高效,解决了后训练中合成数据验证的难题。
不仅如此,团队还开发了一个自动化数据引擎,用于生成博士级别的研究问题。这个引擎首先建立一个多学科知识库,生成需要跨来源推理的“种子”问答对。然后,每个种子都会进入一个自引导的“迭代式复杂性提升”循环。在这个循环中,一个问题构建智能体配备了网络搜索、学术检索和 Python 执行环境等强大工具。在每次迭代中,智能体不断扩展知识边界、深化概念抽象,甚至构建计算任务,形成一个良性循环:上一轮的输出成为下一轮更复杂的输入,确保了任务难度可控且系统性地升级。
通过 SFT 冷启动提升智能体能力
为了提升模型的初始能力,团队基于 ReAct 和新提出的 IterResearch 框架(下文会详述),通过拒绝采样构建了一批 SFT 轨迹数据。
- 一方面,ReAct 作为经典的多轮推理格式,为模型注入了丰富的推理行为,并强化了其遵循结构化格式的能力。
- 另一方面,团队引入了 IterResearch,这是一种创新的智能体范式。它通过在每一轮动态重建一个精简的工作空间,来释放模型的全部推理潜力,确保每个决策都经过深思熟虑。利用 IterResearch,团队构建了一批融合了推理、规划和工具使用的轨迹,从而增强了模型在面对复杂任务时持续规划的能力。
推理模式
在研究智能体的推理范式上,团队进行了广泛的探索。最终的模型支持多种推理格式,包括原生的 ReAct 模式和带上下文管理的“重度模式”。
原生 ReAct 模式
这个模型在原生的 ReAct 推理模式下,无需任何提示工程(Prompt Engineering)就能展现出卓越的性能。它严格遵循“思考-行动-观察”的循环,通过多次迭代来解决问题。得益于 128K 的模型上下文长度,它可以处理大量的交互轮次,充分发挥与环境扩展交互的潜力。ReAct 的简洁和通用性,最清晰地证明了模型内在的能力和训练流程的有效性。
选择 ReAct 在很大程度上是受到了 AI 领域的“惨痛教训” (The Bitter Lesson) 理论的启发,该理论认为,利用可扩展计算的通用方法,最终将超越那些依赖复杂、人为设计的知识和精巧设计的方法。
重度模式 (Heavy Mode)
除了原生的 ReAct 模式,团队还开发了专为复杂、多步研究任务设计的“重度模式” (Heavy Mode)。该模式基于新的 IterResearch 范式构建,旨在将智能体的能力推向极限。
IterResearch 范式的提出是为了解决一个痛点:当智能体把所有信息都堆积在一个不断膨胀的上下文中时,容易出现“认知窒息”和“噪音污染”。而 IterResearch 则将任务分解为一系列的“研究回合”。
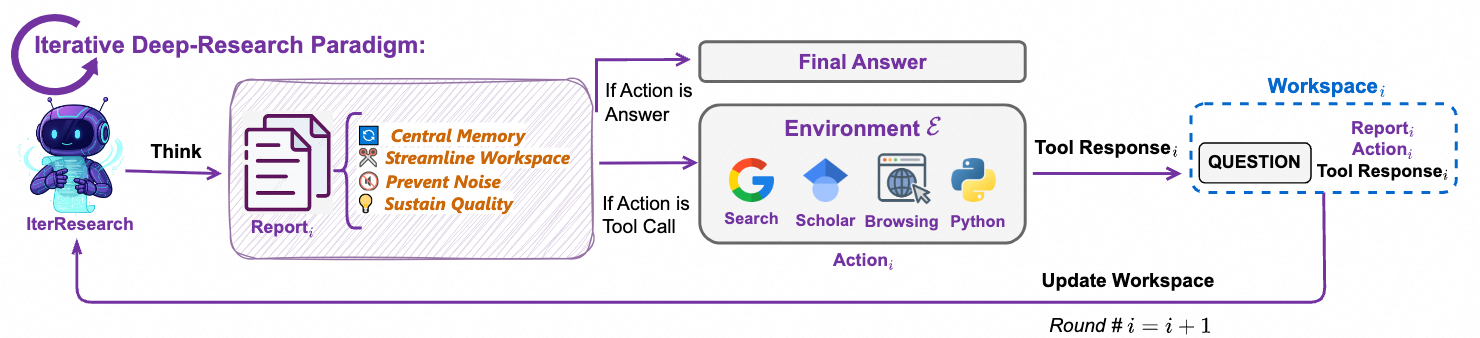
在每个回合中,智能体只利用上一回合最核心的结果来重建一个精简的工作空间。在这个专注的工作空间里,智能体分析问题,将关键发现整合到一份持续更新的中心报告中,然后决定下一步行动——是收集更多信息,还是给出最终答案。这种“合成与重建”的迭代过程,让智能体在漫长的任务中也能保持清晰的“认知焦点”和高质量的推理。
在此基础上,团队还提出了“研究-合成”框架。在该模型中,多个研究智能体利用 IterResearch 过程并行探索问题。最后,一个合成智能体负责整合它们提炼出的报告和结论,从而产生一个更全面的最终答案。这种并行结构让模型能在有限的上下文窗口内探索更广泛的研究路径,将其性能推向极限。
端到端的智能体训练流程

为了训练出这样的智能体模型,整个模型训练流程都需要被重新思考,从预训练、微调到强化学习。团队为智能体模型训练建立了一种新范式,将 智能体 CPT → 智能体 SFT → 智能体 RL 连接起来,为 AI 智能体创建了一个无缝的端到端训练闭环。下面重点介绍最后阶段——强化学习是如何实现的,这对校准智能体的行为至关重要。
在线智能体强化学习 (RL)
用强化学习来构建高质量的智能体,是一项复杂的系统工程挑战。如果把整个开发过程看作一个“强化学习”循环,那么任何一个环节的不稳定或不健壮,都可能导致错误的“奖励”信号。以下是团队在强化学习方面的实践经验,涵盖算法和基础设施两个方面。
在强化学习算法方面,团队取得了多项突破,采用了一种定制的在线 (on-policy) 组相对策略优化 (Group Relative Policy Optimization, GRPO) 算法。
- 首先,采用严格的在线训练方案,确保学习信号始终与模型当前的能力相关。
- 其次,为了进一步减少优势估计的方差,采用了留一法 (leave-one-out) 策略。
- 此外,对负样本采取保守策略,因为未经筛选的负样本轨迹会显著降低训练稳定性,甚至在长时间训练后导致“格式崩溃”。为此,团队会选择性地将某些负样本排除在损失计算之外(例如,那些因超长而未能产生最终答案的样本)。
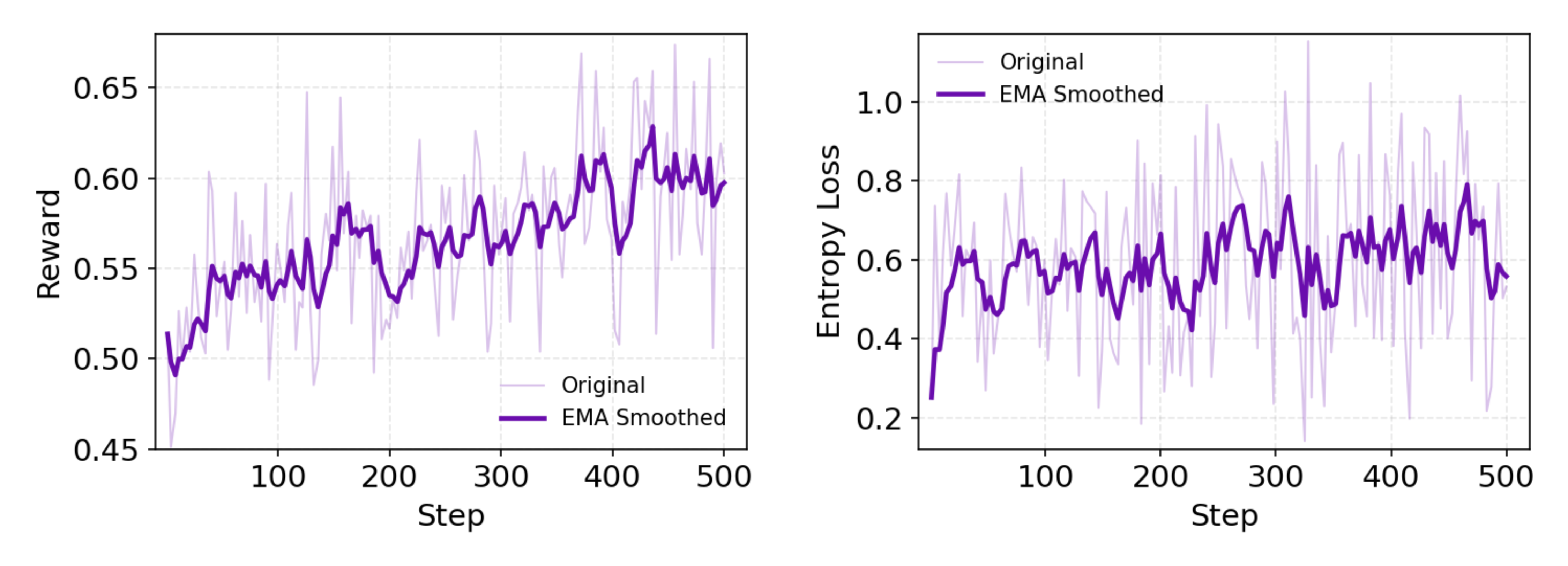
从训练动态来看,学习是有效的,奖励呈现持续上升趋势。同时,策略熵保持在较高水平,表明模型在持续探索,避免了过早收敛。
一个有趣的发现是,算法虽然重要,但可能不是智能体强化学习成功的唯一决定因素。数据和训练环境的稳定性,可能才是决定强化学习成败的关键。团队曾尝试直接在 BrowseComp 测试集上训练模型,但效果远不如使用合成数据。推测原因在于,合成数据提供了一个更一致的分布,让模型能更有效地学习和泛化。相比之下,人工标注的数据(如 BrowseComp)本身就更嘈杂,且规模有限,难以形成一个可学习的潜在分布。
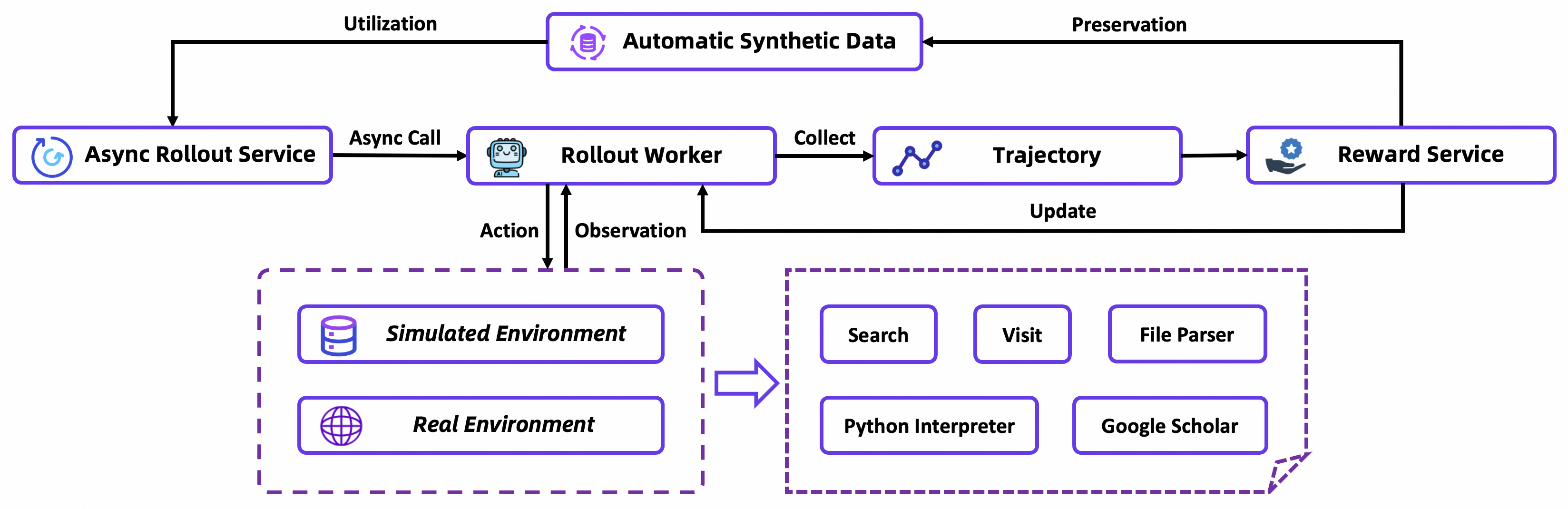
在基础设施方面,训练一个带工具的智能体需要一个高度稳定和高效的环境:
- 模拟训练环境: 依赖实时网络 API 进行开发成本高、速度慢且不稳定。团队通过创建一个使用离线维基百科数据库和定制工具套件的模拟训练环境来解决这个问题。这个平台经济高效、快速可控,极大地加速了研究和迭代。
- 稳定高效的工具沙箱: 为了确保工具使用的可靠性,团队开发了一个统一的沙箱。该沙箱通过缓存结果、重试失败调用以及使用备用 API 等方式来优雅地处理并发和故障,为智能体提供了快速和确定性的体验。
- 自动化数据整理: 数据是模型能力提升的核心驱动力。为了应对这一挑战,团队通过训练的动态过程来实时优化数据。一个完全自动化的数据合成和过滤管道会动态调整训练集,通过打通数据生成与模型训练的闭环,不仅确保了训练稳定性,也带来了显著的性能提升。
- 在线异步框架: 基于 rLLM,团队实现了一个定制的步级异步强化学习训练循环。多个智能体实例并行地与环境交互,每个实例都生成轨迹。
通过这些措施,整个智能体训练流程形成了一个“闭环”。从一个原始模型开始,通过 CPT 预训练初始化工具使用技能,然后用专家级数据进行 SFT 冷启动,最后进行在线强化学习,让模型自我演进。这种全栈方法为训练能够在动态环境中稳健解决复杂任务的 AI 智能体,提出了一种新的范式。
实际应用与影响
通义深度研究不仅仅是一个技术展示,它已经在阿里内外的实际应用中发挥价值:
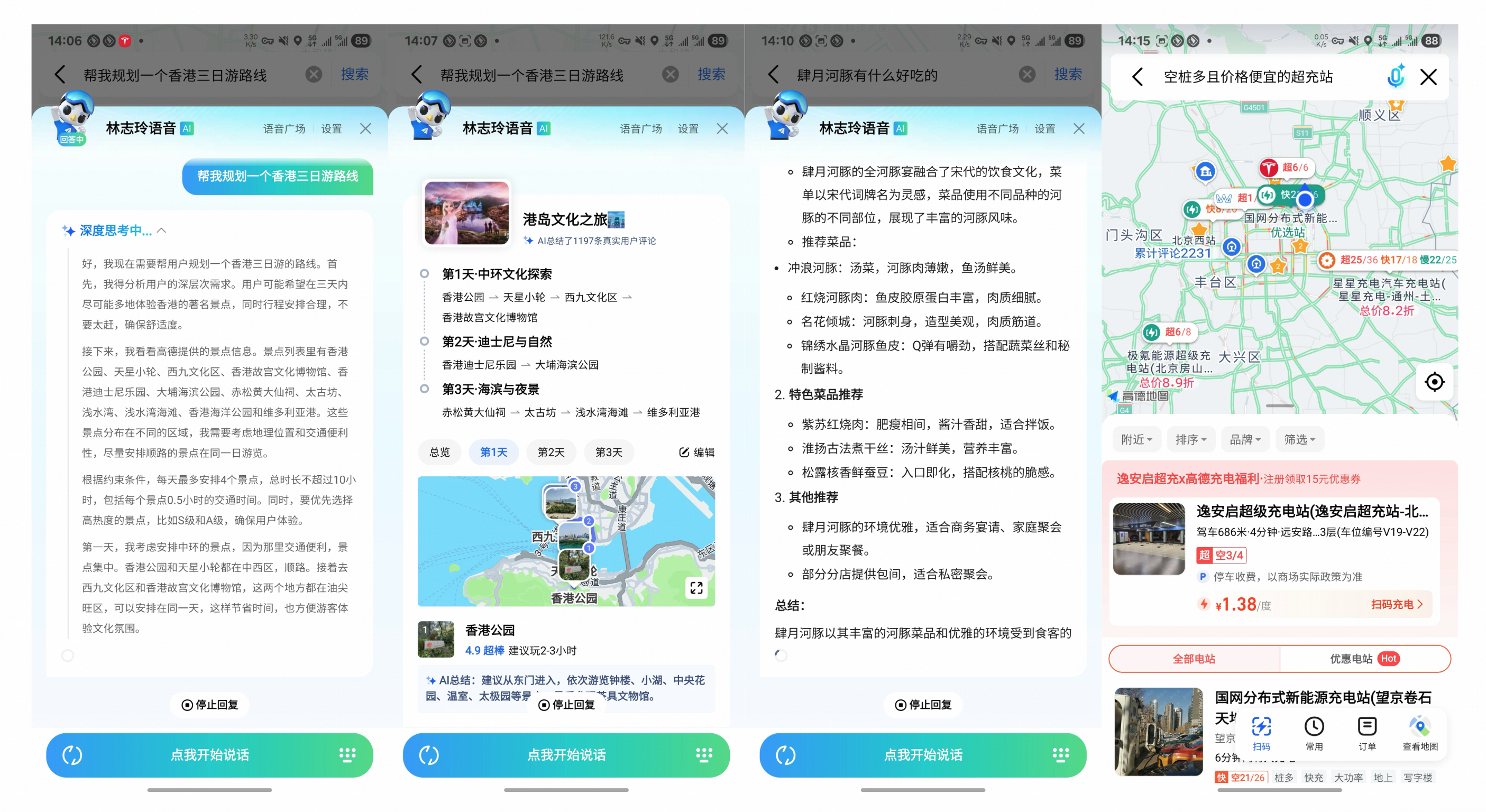
- 高德地图伴侣(小高): 团队与高德合作,共同开发了 AI 副驾“小高”。它能利用高德应用的丰富工具集,执行复杂的旅行规划指令,比如创建一个包含特定景点和宠物友好酒店的多日自驾游路线。通过多步推理,小高能自主研究并整合信息,生成详细的个性化行程。
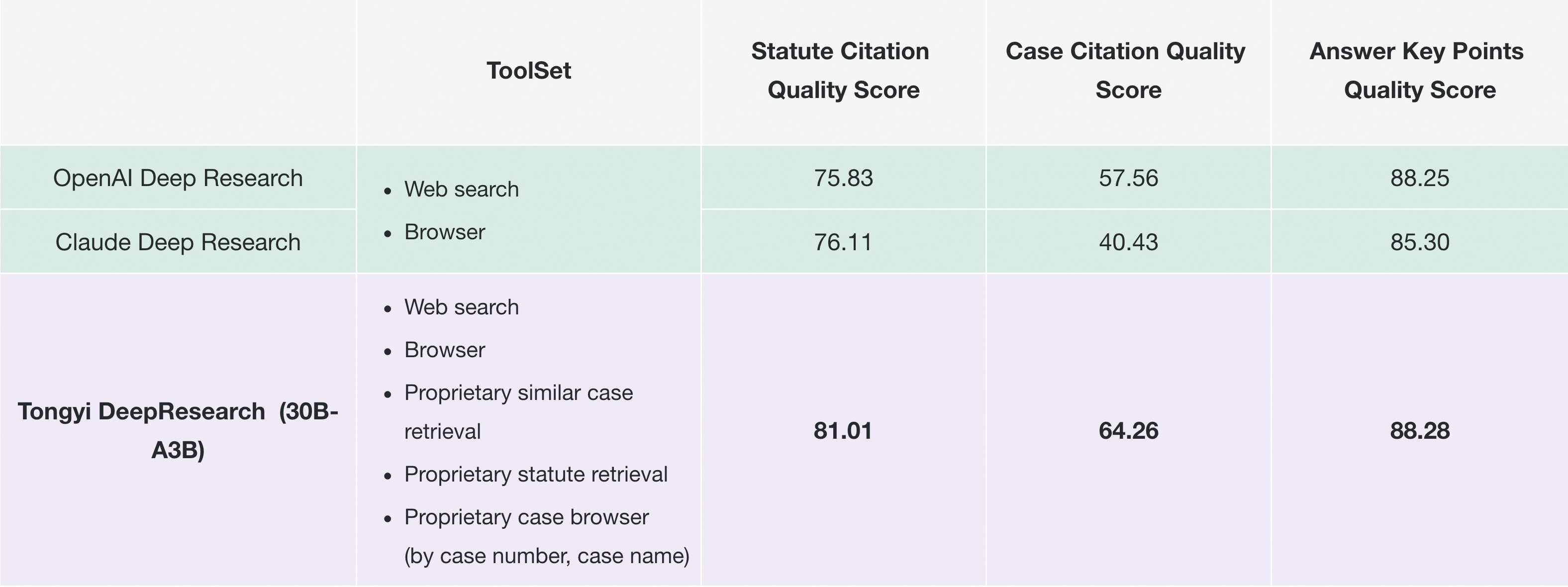
- 通义法睿(法律研究智能体): 在深度研究架构的赋能下,法睿成为了一个真正的法律智能体。它能自主执行复杂的多步研究任务,模拟初级法律助理的工作流程——系统性地检索判例法、交叉引用法规并综合分析。更重要的是,所有结论都基于可验证的司法来源,并附有精确的判例和法规引用,确保了专业级的准确性和可信度。
局限性
未来的工作将主要解决三个关键局限性:
- 上下文长度: 当前 128K 的上下文长度对于最复杂的长程任务仍然不够,需要探索扩展上下文窗口和更复杂的信息管理技术。
- 模型规模: 当前的训练流程在远超 30B 规模的 MoE 基础模型上的可扩展性尚未得到验证。
- RL 效率: 计划通过研究部分推演等技术来提高强化学习框架的效率,这将需要解决离线策略训练带来的分布偏移等挑战。
系列研究工作
通义深度研究背后是一个庞大的研究智能体家族。可以在以下论文中找到更多信息:
- WebWalker: Benchmarking Language Models on the Web
- WebDancer: Towards Autonomous Information-Seeking Agents
- WebSailor: Steering Super-human Reasoning for Web Agents
- WebShaper: Agent Data Synthesis via Information-Seeking Formalism
- WebWatcher: A New Frontier for Vision-Language Deep-Research Agents
- WebResearch: Unleashing Reasoning in Long-Horizon Agents
- ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
- WebWeaver: Constructing Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
- WebSailor-V2: Bridging the Gap to Proprietary Agents via Synthetic Data and Scalable RL
- Agent Scaling via Continual Pre-training
- Towards Universal Agentic Intelligence via Environment Scaling
该团队长期致力于深度研究智能体的研发。在过去六个月里,他们保持着每月发布一篇技术报告的节奏。而这一次,他们一次性发布了六份新报告,并与社区分享了通义深度研究 30B A3B 模型。
敬请期待下一代智能体模型的到来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)