大模型技术演变-3注意力机制诞生Neural Machine Translation by Jointly Learning to Align and Translate读后笔记
这篇ICLR 2015论文开创性地提出注意力机制,突破传统Seq2Seq模型的信息瓶颈问题。作者通过双向RNN编码和动态注意力权重计算,使解码器能自适应聚焦源语句的关键部分,显著提升长句翻译质量。实验显示模型能自主学习词对齐关系,且性能不受句子长度限制。该工作不仅奠定神经机器翻译基础,其Query-Key-Value思想更为Transformer架构埋下伏笔,最终推动整个NLP领域进入注意力时代。
这篇由 Dzmitry Bahdanau 等人在 ICLR 2015 上发表的论文《Neural Machine Translation by Jointly Learning to Align and Translate》,是神经机器翻译(NMT)和注意力机制发展史上的一座里程碑。它巧妙地解决了传统序列到序列(Seq2Seq)模型的核心痛点,并为后续 Transformer 乃至大模型时代的技术爆发奠定了基石。
以下是对该论文的专业解读和读后笔记。
📌 1. 论文基本信息
-
标题: Neural Machine Translation by Jointly Learning to Align and Translate
-
作者: Dzmitry Bahdanau, KyungHyun Cho, Yoshua Bengio
-
会议: International Conference on Learning Representations (ICLR) 2015
-
原文链接: arXiv:1409.0473
⚙️ 2. 核心问题与创新动机
论文的出发点是解决传统编码器-解码器(Encoder-Decoder)架构在神经机器翻译中的根本性缺陷。
-
信息瓶颈(Information Bottleneck): 传统模型需将整个源语句压缩为一个固定长度的上下文向量(Context Vector),这导致源句信息被高度浓缩,细节不可避免地被丢失。当处理长句子时,这个问题尤为突出,模型性能显著下降。
-
长序列建模困难: 尽管编码器(如LSTM/GRU)具有一定记忆能力,但仍难以完美捕获长距离依赖关系。
该论文的创新性在于,它不再试图将整个句子压缩成一个固定向量,而是让模型在翻译(解码)的每一个时间步,自动地、动态地去“瞥一眼”源语句中与之最相关的部分。这个过程被称为联合学习对齐与翻译(Jointly Learning to Align and Translate)。
🧠 3. 核心思想:注意力机制(Attention Mechanism)
论文的核心贡献是引入了注意力机制,其核心思想可概括为:
在解码器生成目标语言每个词时,动态计算一组权重(注意力权重),表示此时应关注源语言序列中各个词的程度。解码器 then 根据这些权重对编码器的隐藏状态进行加权平均,得到一个动态的上下文向量,该向量聚焦于与当前翻译词最相关的源语言信息。
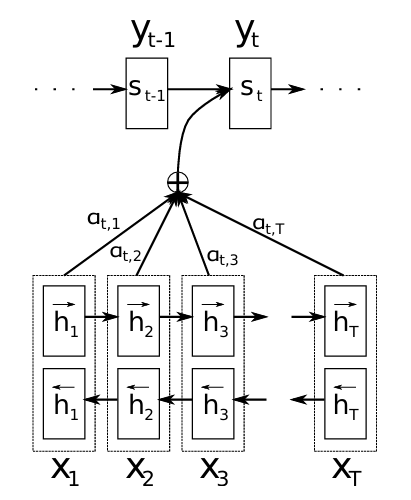
3.1 模型架构 (RNNsearch)
论文提出了名为 RNNsearch 的模型:
-
编码器: 采用双向RNN。这使得每个词的隐藏状态(annotation)都包含了其前后文信息,为后续计算更精准的注意力提供了丰富基础。
-
解码器: 在预测每个目标词
y_i时,会计算一个专属的上下文向量c_i(而非一个固定的向量)。
3.2 注意力计算步骤 (Bahdanau Attention)
动态上下文向量 c_i的计算是论文的精髓,具体步骤如下:
-
计算注意力得分(Energy): 对编码器第
j个位置的隐藏状态h_j和解码器上一时刻的隐藏状态s_{i-1},通过一个前馈神经网络(对齐模型)a()计算得分e_{ij},衡量二者的相关性。论文中
a()的具体形式为加性注意力(Additive Attention):其中
-
计算注意力权重(Alpha): 对所有
应用 Softmax 归一化,得到权重
i个目标词时,对源语句第j个词的关注程度。 -
计算动态上下文向量(Context Vector): 将编码器所有隐藏状态的加权和作为当前时间步的上下文向量
-
解码与预测: 将上下文向量
c_i与解码器当前隐藏状态结合,来预测下一个词y_i。
下面是注意力机制在机器翻译中的工作流程示意图:
flowchart TD
A[源序列: The cat is on the mat] --> B["编码器 (双向RNN)<br>生成隐藏状态序列 h_j"]
B -- 隐藏状态序列 --> C[注意力机制]
G[目标序列: Le chat est sur le tapis] --> H["解码器<br>当前隐藏状态 s_i-1"]
H -- 查询 Query --> C
C -- 计算对齐权重 α_ij --> D[上下文向量 c_i]
D --> H
subgraph C [注意力计算过程]
C1[计算注意力得分<br>e_ij = a(s_i-1, h_j)]
C2[计算注意力权重<br>α_ij = softmax(e_ij)]
C3[计算上下文向量<br>c_i = ∑ α_ij h_j]
C1 --> C2 --> C3
end
H --> I[预测下一个目标词]4. 实验结果与意义
论文在 WMT'14 英法翻译任务上进行了实验,结果表明:
3. 计算效率分析
-
性能显著提升: RNNsearch 在翻译质量上显著优于传统的固定上下文向量模型(RNNencdec),尤其是在处理长句子时优势巨大。
-
解决信息瓶颈: 实验证明,RNNsearch 的性能不会随着句子长度的增加而急剧下降,有效解决了信息瓶颈问题。
-
自动学习对齐: 注意力权重矩阵的可视化显示,模型在没有显式监督的情况下,自动学习到了源语言和目标语言之间合理的软对齐关系(例如,将"chat"与"cat"对齐),这不仅提升了性能,还增强了模型的可解释性。
-
4.2. 注意力权重的可解释性
-
可视化显示:生成目标词“chat”时,权重峰值位于源词“cat”,符合词对齐直觉(如下图)。
源序列: The cat is on the mat 权重分布: [0.02, 0.85, 0.03, 0.05, 0.03, 0.02] -
无需对齐监督:模型自主学习软对齐,突破IBM模型需强制对齐的限制。
-
时间复杂度:O(Tx×Ty),其中 Tx、Ty为序列长度,成为长序列处理的瓶颈。
-
参数量:加性注意力引入额外参数 Wa,Ua,va,但实验表明其收益远高于成本。
💡 5. 深远影响与启示
这篇论文的影响远远超出了其当时的实验任务:
-
注意力机制的奠基: 它首次将注意力机制成功引入NMT,并展示了其巨大威力,直接启发了后续一系列注意力变体的研究,如 Luong 的点积注意力(Dot-Product Attention) 和 全局/局部注意力。
-
通向Transformer之路: 本文提出的 Query-Key-Value 思想雏形(
s_{i-1}作为 Query,h_j作为 Key 和 Value)以及加权求和的计算方式,是自注意力(Self-Attention)机制最直接的前身。可以说,没有这篇论文,可能就没有2017年的《Attention is All You Need》和Transformer架构。 -
现代大模型的基石: 注意力机制,特别是其高级形态自注意力,已成为所有大型预训练模型(如BERT、GPT等)不可或缺的核心组件。这篇论文为整个NLP领域的技术演进奠定了第一块基石。
-
范式转变: 它推动机器翻译从统计方法(SMT)全面转向神经机器翻译(NMT),并确立了端到端学习的绝对主导地位。
💎 6. 总结与思考
《Neural Machine Translation by Jointly Learning to Align and Translate》是一篇见解深刻、影响深远的经典论文。它从一个具体问题(固定长度上下文向量)出发,提出了一个通用、强大且优雅的解决方案(注意力机制)。
其最核心的启示在于:让模型动态地、有选择地关注信息,远比试图静态地、完整地压缩信息更为有效。这种思想不仅改变了机器翻译,更重塑了整个人工智能领域处理序列数据的方式。
阅读这篇论文,不仅是理解一项技术,更是回顾一个时代的开端。它完美地展示了如何通过一个关键性的创新,撬动整个领域的发展方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)