AI模型压缩-详解
🍋🍋AI学习🍋🍋🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞模型压缩的四种主流技术:Pruning 剪枝:Quantization 量化:Knowledge distillation 知识蒸馏:Low-rank factorization 低秩因式分解:实际部署的时候需要一些模型加速的方法,每种框架
🍋🍋AI学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
模型压缩的四种主流技术:
Pruning 剪枝:
剪枝是一种减少深度神经网络参数数量的强大技术。在 深度神经网络中,许多参数是冗余的,因为它们在训练期间贡献不大。因此,在训练之后,可以从网络中删除这些参数,而对准确性的影响很小。
Quantization 量化:
在 深度神经网络模型 中,权重存储为 32 位浮点数,即fp32。量化通过减少每个权重所需的位数来压缩原始网络。例如,权重可以量化为 fp16 位、int8 位甚至 int4 位。通过减少使用的位数,可以显著减小 DNN 的大小,且加速推理速度。
Knowledge distillation 知识蒸馏:
在知识蒸馏中,在大型数据集上训练大型复杂模型。当这个大模型可以泛化并进行推理时,使其知识转移到较小的网络。较大的模型称为教师模型,较小的网络称为学生网络。
Low-rank factorization 低秩因式分解:
低秩因式分解通过采用矩阵分解来识别深度神经网络的冗余参数。当需要减小模型大小时,低秩因式分解技术通过将大型矩阵分解为较小的矩阵来提供帮助。
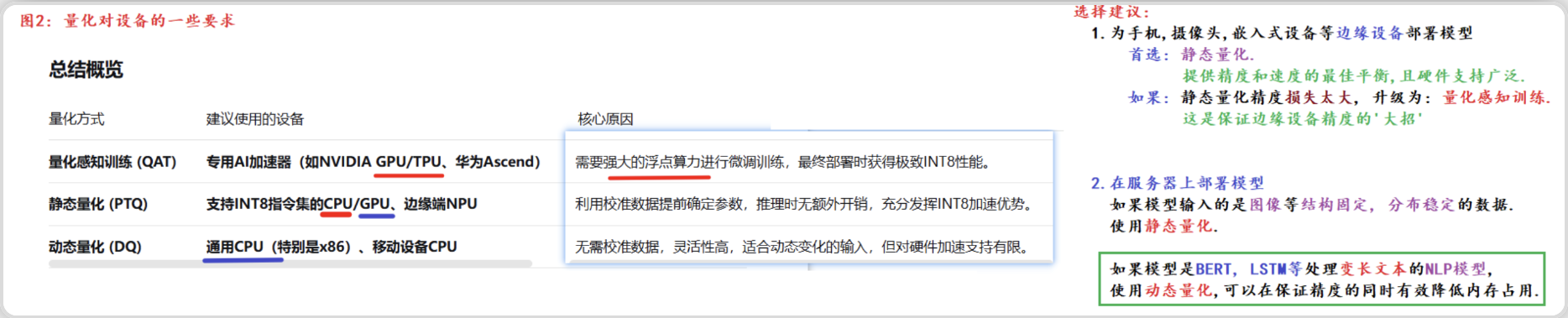
一、量化
实际部署的时候需要一些模型加速的方法,每种框架除了fp32精度外,都支持了int8的精度,而量化到int8常常可以使我们的模型更小更快,所以在部署端很受欢迎。常用的模型量化方式有动态量化、训练中量化,QAT,和训练后量化,PTQ。
-
通俗的理解, 就是将模型的参数精度进行降低操作, 用更少的比特位(torch.qint8)代替较多的比特位(torch.float32), 从而缩减模型, 并加速推断速度.

二、蒸馏
按“知识”类型分类(最常见分类)
这是最主流的分类方式,根据从教师模型中提取什么类型的知识来划分。
-
输出层蒸馏(Response-based Distillation)
-
知识来源:教师模型的输出层概率分布(软标签)。
-
方法:
-
使用高温 softmax 生成平滑的概率分布。
-
学生模型学习模仿这个分布。
-
-
损失函数:KL 散度 + 真实标签交叉熵。
-
优点:简单、通用、易于实现。
-
代表工作:Hinton et al. (2015) 《Distilling the Knowledge in a Neural Network》
适用场景:图像分类、文本分类等。
-
特征层蒸馏(Feature-based Distillation / Representation Distillation)
-
知识来源:教师模型中间层的特征表示(如隐藏层输出、注意力矩阵)。
-
方法:
-
让学生模型的中间层输出逼近教师模型对应层的输出。
-
常用 L2 损失或注意力迁移(Attention Transfer)。
-
-
损失函数:MSE 或相似性度量(如余弦相似度)。
-
优点:传递更丰富的结构化知识,适合复杂任务。
-
代表工作:
-
FitNet:让学生网络“模仿”教师的中间层激活。
-
TinyBERT:蒸馏 Transformer 的注意力矩阵和隐藏状态。
-
适用场景:BERT 蒸馏、目标检测、语义分割。
-
关系型蒸馏(Relation-based Distillation)
-
知识来源:样本之间的关系结构(如样本对之间的相似性、排序关系)。
-
方法:
-
构建样本间的关系图(如距离、相似度)。
-
学生模型学习保持相同的样本间关系。
-
-
代表工作:
-
RKD(Relational Knowledge Distillation):蒸馏样本间的距离和角度关系。
-
PKD(Probabilistic Knowledge Distillation):蒸馏样本对的排序关系。
-
适用场景:度量学习、小样本学习。
按训练策略分类
-
离线蒸馏(Offline Distillation)
-
流程:
-
先训练好教师模型。
-
固定教师参数,用它生成软标签或特征。
-
训练学生模型。
-
-
优点:简单、稳定。
-
缺点:需要先训练大模型,耗资源。
-
最常见方式。
-
在线蒸馏(Online Distillation)
-
流程:教师和学生同时训练,互相学习。
-
特点:
-
教师不一定是预训练大模型,可能是多个学生模型的集成(Self-Ensemble)。
-
可以是同构(相同结构)或异构(不同结构)。
-
-
代表工作:
-
Deep Mutual Learning:两个学生模型互相当老师。
-
Born-Again Networks:一个模型训练完后,用它蒸馏自己(自蒸馏)。
-
优点:无需预先训练教师,适合资源有限场景。
-
自蒸馏(Self-Distillation)
-
定义:同一个模型,用深层的知识指导浅层的学习。
-
方式:
-
用模型深层的输出或特征,作为监督信号训练浅层。
-
或:先训练一个模型,再用它的输出蒸馏一个结构相同但更小的学生模型。
-
-
优点:无需额外教师模型,提升模型自身性能。
-
代表工作:Noisy Student Training(Google)、Teaacher-Student with same architecture.
| 分类维度 | 主要方式 | 关键特点 |
|---|---|---|
| 知识类型 | 输出层蒸馏 | 学习软标签 |
| 特征层蒸馏 | 学习中间表示 | |
| 关系型蒸馏 | 学习样本间关系 | |
| 训练策略 | 离线蒸馏 | 教师先训练好 |
| 在线蒸馏 | 教师与学生共训练 | |
| 自蒸馏 |
自己教自己 |
三、剪枝
模型剪枝的核心思想是:识别并移除神经网络中的冗余部分(如权重、神经元、通道等),从而得到一个更小、更快、更高效的模型,同时尽量保持其原始精度。
它的灵感来自于人脑的发育过程——婴儿期会产生大量神经元连接,但之后不常用的连接会被修剪掉,使得大脑网络更高效。
深度学习模型虽然强大,但存在明显的缺陷:
-
计算量大:参数量动辄数百万甚至数十亿,推理速度慢,难以部署在手机、嵌入式设备等资源受限的边缘设备上。
-
内存占用高:巨大的模型需要大量的存储空间和内存,导致部署成本高昂。
-
能耗高:大规模的计算意味着高能耗,对于移动设备和IoT设备来说是致命的。
-
过度参数化:研究发现,神经网络中存在大量冗余。很多权重对最终的输出贡献极小,移除它们对精度影响不大。
-
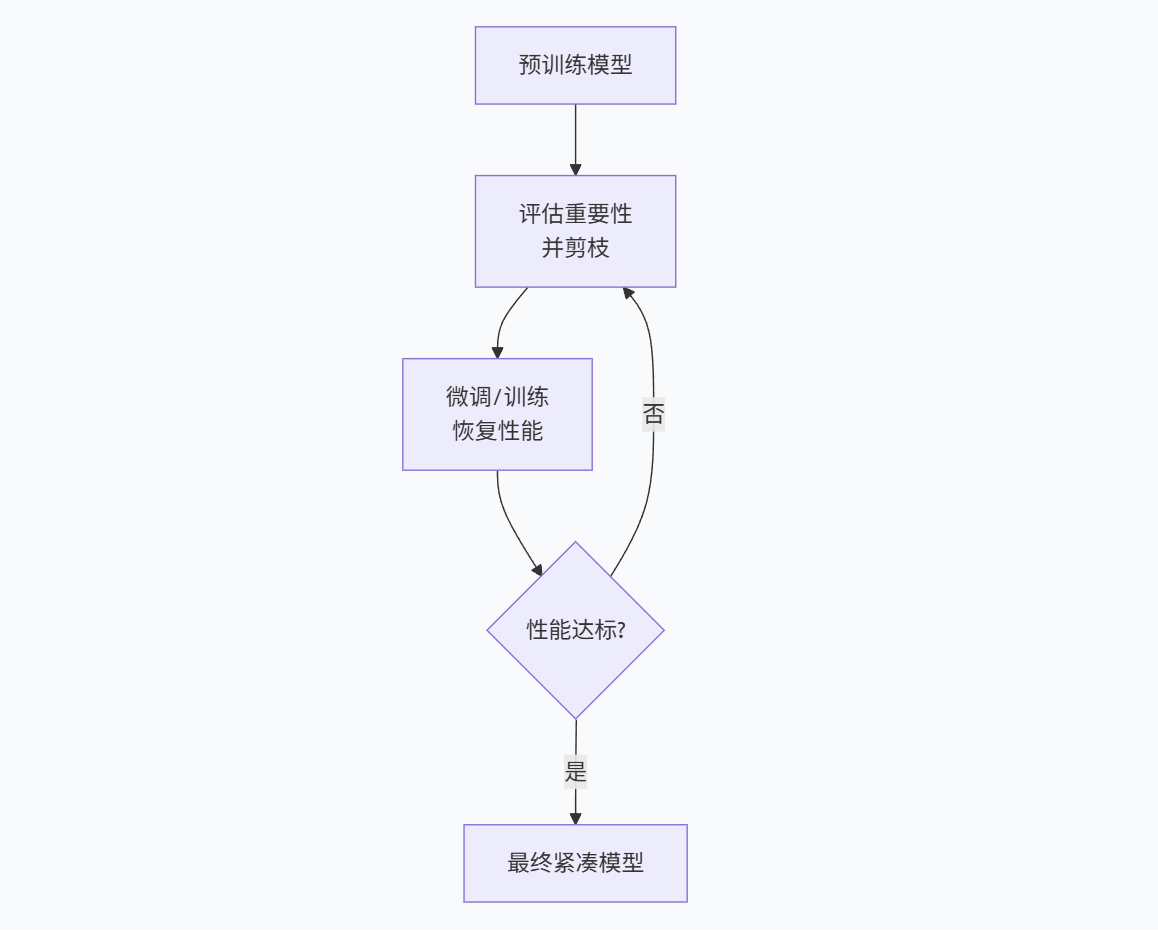
预训练:首先,你需要一个训练好的、性能良好的原始模型。剪枝通常不会从一个随机初始化的模型开始。
-
评估重要性并剪枝:这是最关键的一步。你需要制定一个重要性准则,来判断哪些参数是“不重要”的、可以移除的。
-
常用准则:
-
幅度剪枝:最简单常用的方法。认为绝对值越小的权重越不重要,因为它对激活值的贡献很小。
-
基于梯度的准则:考虑权重在训练中的梯度,梯度小的可能不重要。
-
基于Hessian的准则:更高级的方法,考虑损失函数对权重的二阶导数,能更准确地评估重要性,但计算成本高。
-
-
-
微调/训练:剪枝后,模型性能必然会下降。需要通过微调让模型恢复性能。微调的过程本质上是对剩余的重要权重进行重新训练,让它们来补偿被移除的权重所承担的功能。
-
迭代:步骤2和3通常需要重复多次,逐步地剪枝,而不是一步到位地剪掉大部分参数。这样能保证模型性能不会崩溃。
***根据剪除的粒度大小,剪枝可以分为不同级别:
| 剪枝类型 | 操作对象 | 优点 | 缺点 |
|---|---|---|---|
| 细粒度剪枝 | 单个权重 | 压缩率最高 | 生成不规则稀疏模式,需要特殊硬件/库才能加速 |
| 向量/核剪枝 | 一组权重(如卷积核的一行) | 结构化程度更高 | 压缩率低于细粒度 |
| 粗粒度剪枝 | 整个通道(通道剪枝)或整个神经元 | 硬件友好,容易加速 | 压缩率相对较低 |
| 随机剪枝 | 随机选择权重进行剪枝 | 实现简单 | 效果通常不如结构化剪枝 |
| 结构化剪枝 | 按结构(如通道)剪枝 | 硬件友好,容易加速 | 需要精心设计重要性准则 |
其中,通道剪枝是目前最流行的方法之一,因为它直接减少了卷积层的通道数,从而显著降低了计算量(FLOPs)和模型大小,并且可以被常规硬件高效执行。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)