强化学习飞行器智能决策python——中段突防
本文介绍了基于强化学习的多智能体对抗训练系统,主要包括三个核心模块:1) 常规训练模块(train)实现"经验收集-网络更新-结果记录"的循环训练流程;2) 元学习模块(train_meta)在预训练模型基础上进行快速场景适应优化;3) 可视化模块(display)用于策略性能评估和轨迹展示。系统采用TD3/MASAC等算法,支持静态/动态威胁环境下的协同对抗训练,通过配置类集
1.依赖导入
首先导入项目所需的第三方库和自定义模块,涵盖数值计算、深度学习、日志记录、可视化等功能。
import torch
import numpy as np
from tensorboardX import SummaryWriter
import matplotlib.pyplot as plt
import time
import random
import sys,os
curr_path = os.path.dirname(__file__)
parent_path = os.path.dirname(curr_path)
sys.path.append(parent_path)
from python_enviroment.pyenv_area import TF_threat_area2.配置类 Config
Config 类是整个项目的 “参数中心”,集中管理场景设置、网络参数、训练参数等所有可配置项,避免参数散落在代码中,便于统一修改和调试。
场景设置:
class Config:
num_agents = 3 # 智能体数量
num_adversaries =2 # 敌方数量
good_policy = "TD3" # 我方策略方法 choices=["TD3","MASAC"]
adv_policy = "PN" # 敌方策略方法 choices=[ "ddpg", "PN"]网络参数设置:
StartLearnStep = 120000 #开始学习步数
steps_per_update=50 # 网络更新步数
Batchsize = 128 # 批次样本数
#----td3-----
init_noise_scale=0.8
final_noise_scale=0.03
#----sac-----
gamma_sac=0.99 #SAC折扣因子(权衡当前 / 未来奖励)
reward_scale=1
repeat_times=2 ** 0
target_step=2 ** 10
max_memo=2 ** 17
soft_update_tau=2 ** -8
batch_size_sac=256
net_dim=2 ** 8预测参数设置:
pred_trajectory=False # 是否预测
trajectory_pred_size=2 # 预测样本间隔
his_time_step=10 # 历史轨迹拍数(用于预测输入)
pre_traj_step=1 # 预测拍数
batch_size_predict=64 # 预测网络批次样本数meta参数设置:
meta =True # False # # 是否在线优化
MetaLearnStep =1024 # 开始更新步数--最好大于MATD3中的 Q_batchsize值
update_step = 3 # 更新步数打印输出设置:
save_dir="./policy/" # 保存网络的地址
load_dir='' # "directory in which training state and model are loaded")
log_dir="./log/" # 保存日志的地址
save_rate=100 # 保存的间隔训练设置:
Episodes = 450 # 训练回合
EpisodeLength = 5000 # 回合max步数
display = True # False #是否进入测试 / 可视化模式(True为测试,False为训练)
Save_origin=True # 保存原始数据
State_Noise=False # 引入噪声
threat_area=True # 是否是静态障碍
max_mark=4 # meta多任务训练
use_env=False # 是否联合unity
seed=0 # 随机种子
use_RND=False
Err_U = True # 故障约束
adv_restore=True
good_restore=True
display_adv_policy=True3.工具函数
固定随机种子,确保实验结果的可重复性(避免因随机因素导致结果波动):
def setup_seed(seed=0):
torch.manual_seed(seed) # PyTorch CPU随机种子
torch.cuda.manual_seed_all(seed) # PyTorch GPU随机种子(多卡)
np.random.seed(seed) # NumPy随机种子
random.seed(seed) # Python原生随机种子
torch.backends.cudnn.deterministic = True # 禁用CuDNN自动优化(确保确定性)
torch.backends.cudnn.benchmark = False # 禁用CuDNN基准测试(避免随机性)4.核心逻辑(训练 / 元学习 / 可视化)核心逻辑(训练 / 元学习 / 可视化)
(1) train(常规训练)
train 函数实现多智能体强化学习的常规训练流程,核心是 “经验收集→网络更新→结果记录” 的循环,适用于固定场景下的策略学习。
def train(config):
setup_seed()1) 初始化操作
日志与路径初始化:用当前时间戳创建日志目录(SummaryWriter)和模型保存目录,避免文件覆盖。
nowt = time.strftime("%Y-%m-%d", time.localtime()) # 对时间进行格式化
train_log_dir = config.log_dir + '/' + nowt + '_train_logs'
# if not os.path.isdir(train_log_dir):
# os.makedirs(str(train_log_dir))
train_logger = SummaryWriter(str(train_log_dir)+'_yl') # 建立一个log训练结果保存:
file = './policy/policy' + str(nowt)
isExists = os.path.exists(file)
if not isExists:
os.makedirs(file)
print(file + ' 创建成功')
else:
print(file + ' 目录已存在') # 如果目录存在则不创建,并提示目录已存在
filename = file + '/' + str(config.Episodes)用unity environment#T0D0:未引入包
if config.use_env:
env = Unity_env()
env_info = env.get_env_info()
#print(env_info)环境与动作 / 状态空间定义:python Environment设置
加载自定义环境 TF_threat_area(含威胁区域的场景);
定义动作空间 action_n(我方 3 维:攻角 / 倾侧 / 力;敌方 2 维:横向 / 纵向过载);
定义状态空间 obs_shape_n(我方 24 维:自身状态 6 维 + 敌方 1 状态 6 维 + 威胁半径 1 维 + 敌方 2 状态 6 维 + 威胁半径 1 维 + 目标点 3 维 + 故障信息 1 维;敌方 12 维:自身状态 6 维 + 我方状态 6 维)。
if config.threat_area:
action_n = [[0,0,0], [0, 0], [0, 0]] #动作空间我3:攻角,倾侧,力,adv2:横向过载、纵向过载,adv 2
act_shape_n = [3, 2, 2]
obs_shape_n = [23, 12, 12] #状态空间:23=我6+adv6+半径+adv6+半径+目标点3 adv12:我6+adv6
if config.Err_U:
obs_shape_n = [24, 12, 12] #状态空间:24=我6+adv6+半径+adv6+半径+目标点3+u adv12:我6+adv6智能体网络构建:
我方智能体:根据 good_policy 加载 TD3/MASAC 网络(从 trainers 目录导入预定义的算法类);
敌方智能体:根据 adv_policy 加载 PN/DDPG 网络(PN 为传统控制,无需训练;DDPG 为强化学习,需训练)。
trainers = []
for i in range(config.num_agents - config.num_adversaries):
if config.good_policy == 'TD3':
if config.use_RND:
from trainers.MATD3.MATD3 import MATD3RND
trainers.append(MATD3RND(state_dim=obs_shape_n[i], action_dim=act_shape_n[i],agent_index=i,
num_agents=config.num_agents - config.num_adversaries,
arglist=config))
else:
from trainers.MATD3.MATD3 import MATD3
trainers.append(MATD3(state_dim=obs_shape_n[i], action_dim=act_shape_n[i],agent_index=i,
num_agents=config.num_agents - config.num_adversaries,
arglist=config))
for i in range(config.num_agents - config.num_adversaries, config.num_agents):
if config.adv_policy == "ddpg":
from trainers.DDPG.ddpg import ddpg_agent
trainers.append(ddpg_agent(obs_shape_n[1], act_shape_n[1], arglist=config, Parallel=Parallel))
##TODO:
if config.adv_policy == 'PN':#比例导引
from trainers.PN.PNN import PNN
trainers.append(PNN())计算参数:
step_total = 0 # 所有的步数,用于开始学习
done_episodes_50 = 0 # 计算成功率
collect_data = {"tf_reward": [], "done": [],"done_rate": [], "episode_steps": []} # 收集信息
ori_data =np.zeros((1,obs_shape_n[0])) # 保存原始数据
mark = 0 # 定场景
his_traj_n = None
his_done_rate = 0
# print("StartLearnStep: ",config.StartLearnStep)2)训练主循环
遍历 Episodes 个回合,每个回合的流程如下:
环境重置:调用 py_env.reset(mark=mark) 初始化场景(mark 用于区分不同任务场景),获取初始状态 obs_n。
步数与数据初始化:重置当前回合步数 step_episode、奖励列表 reward_coll、原始数据 ori_data(用于保存状态轨迹)。
for episode in range(config.Episodes): # 回合遍历
py_env = TF_threat_area(num_agents=config.num_agents, random_num=config.num_adversaries,threat_area=config.threat_area,Err_U=config.Err_U)
step_episode = 0 # 每回合的步数,用于reward
reward_coll = []
# print("episode: {}".format(episode))
obs_n = py_env.reset(mark=mark) # 初始化环境(1,25)
if config.use_env:#TODO:未引入包-------------------
env.reset() # ndarray[1,:]
unity_obs = obs_n
a= env.step(unity_obs)
if config.Save_origin:
ori_data = np.append(ori_data,obs_n,axis=0) # 初始化原始数据(1,25)
if config.State_Noise:
obs_n = py_env.noise(obs_n) # 加噪声-->[1.18]
obs_std, reward_std = py_env.max_min_standard(obs_n,0) # 最大最小规范化
while True:
step_total += 1
step_episode += 13)步数级循环(每步交互)
每个回合内遍历 EpisodeLength 步,核心是 “智能体决策→环境交互→经验存储→网络更新”:
智能体决策:
若总步数 step_total ≤ StartLearnStep:我方智能体随机探索(均匀分布采样动作);
若总步数超过阈值:我方智能体通过训练好的网络输出动作(并裁剪到 [-1,1] 范围,避免动作过大);
敌方智能体:若为静态威胁区域,动作固定为 [0,0](不移动);若为动态区域,通过 PN/DDPG 输出动作。
for i in range(config.num_agents - config.num_adversaries):
if step_total <= config.StartLearnStep:
a = np.random.uniform(-1, 1, size=(act_shape_n[i],))
else:
# a = trainers[i].select_action(obs_std) + np.random.normal(size=(3,))
# a,debug= trainers[i].act(obs_std)
a = trainers[i].select_action(obs_std)
a = a.clip(-1, 1)
action_n[i] = a.reshape(-1)
for i in range(config.num_agents -config.num_adversaries, config.num_agents):
if config.threat_area: #静态障碍
action_n[i] = [0, 0]
else: #动态障碍
if i == 1:
if arglist.adv_policy == 'PN':
action_n[i] = trainers[i].choose_action(obs_n[:, :12])
#TODO:ddpg
else:
if arglist.adv_policy == 'PN':
action_n[i] = trainers[i].choose_action(np.hstack((obs_n[:, :6], obs_n[:, 14:20])))
# TODO:ddpg环境交互:调用 py_env.step(action_n, step_episode) 执行动作,获取下一状态 obs_n_、即时奖励 reward、结束标志 done、最小距离(dis_2D_min1 为我方与敌方 1 的距离,dis_2D_p 为我方与目标点的距离)。
obs_n_, reward, done, dis_2D_min1, dis_2D_min2,dis_2D_p = py_env.step(action_n,step_episode) #状态转移
if config.use_env:#TODO:未引入包-------------------
a = env.step(obs_n_)
if config.Save_origin:
ori_data = np.append(ori_data,obs_n_,axis=0) #记录状态
reward_coll.append(reward) #记录reward
if config.State_Noise:
obs_n_ = py_env.noise(obs_n_) # 加噪声
if done:
obs_n_ = obs_n
train_logger.add_scalar('reward_end', reward, episode)
reward_mean = sum(reward_coll)/step_episode
train_logger.add_scalar('reward_coll', reward_mean, episode)
train_logger.add_scalar('dis_2D_min1', dis_2D_min1, episode)
train_logger.add_scalar('dis_2D_min2', dis_2D_min2, episode)
train_logger.add_scalar('dis_p', dis_2D_p, episode)
collect_data["tf_reward"].append(reward_mean)
# collect_data["adv_reward"].append(reward)
collect_data["episode_steps"].append(step_episode)数据预处理:
状态规范化:调用 py_env.max_min_standard 对状态和奖励做 “最大最小归一化”,避免数值范围差异影响网络训练;
obs_std_,reward_std_ = py_env.max_min_standard(obs_n_,reward) # 规范化原始数据保存:若 Save_origin=True,将下一状态 obs_n_ 追加到 ori_data,用于后续分析。
经验存储:
将 “当前状态→动作→奖励→下一状态→结束标志” 存入我方智能体的经验回放池(add_experience),供后续采样训练。
for i, agent in enumerate(trainers):
done_ = 0 if done == 0 else 1 # 此处改一下合理点
if i in range(config.num_agents - config.num_adversaries):
if config.good_policy in ["maddpg", "TD3", "MASAC"]:
agent.add_experience(obs_std, action_n[0], reward_std_, obs_std_, done_,mark,step_episode)
elif i in range(config.num_agents - config.num_adversaries, config.num_agents):
if config.threat_area:
continue网络更新:
若总步数 step_total > StartLearnStep:我方智能体调用 updata 函数,从经验池采样批次数据更新 TD3/MASAC 网络;
loss_n = []
if step_total == config.StartLearnStep:
print('startlearn')
if step_total >config.StartLearnStep:
loss = trainers[0].updata(episode, 0, trainers[0:config.num_agents - config.num_adversaries],
logger=train_logger)
loss_n.append(loss)若敌方策略为 DDPG:调用 trainers[1].learn(done) 更新敌方网络,并记录损失到日志。
if config.adv_policy == "ddpg":
trainers[1].learn(done)
trainers[2].learn(done)
train_logger.add_scalar('M1actor_loss', trainers[1].a_loss, step_total)
train_logger.add_scalar('M1critic_loss',trainers[1].q_loss, step_total)
train_logger.add_scalar('M2actor_loss',trainers[2].a_loss, step_total)
train_logger.add_scalar('M2critic_loss', trainers[2].q_loss, step_total)
4)回合结束处理
模型保存:每 50 个回合保存一次训练数据(np.save),若当前成功率高于历史最高,保存我方智能体的网络参数(trainers[0].save)。
if done:
# print("step_episode: {}".format(step_episode), reward, done)
if done==1:
# print("step_episode: {}".format(step_episode), reward, done)
done_episodes_50 += 1
if episode % 50 == 0:
train_logger.add_scalar('done_rate', done_episodes_50/50, episode / 50)
collect_data["done_rate"].append(done_episodes_50 / 50)
# print(done_episodes_50 / 50)
if done_episodes_50 / 50> his_done_rate:
trainers[0].save(filename)
his_done_rate =done_episodes_50 / 50
done_episodes_50= 0
break
obs_n = obs_n_
obs_std = obs_std_
if episode % 50 == 0: #每50回合保存数据
np.save(filename + "_collect_data", collect_data)结果记录:若 done=True(回合结束,如到达目标点或碰撞),计算当前回合的平均奖励,将奖励、步数、成功率存入 collect_data,并通过 SummaryWriter 记录到 TensorBoard。
trainers[0].save(filename+"_final_")
# print('game over')
if config.Save_origin:
np.save(filename + "ori_data.npy", ori_data) # 保存原始数据
train_logger.export_scalars_to_json('./log/_train_logs/summary.json')
train_logger.close()(2) 元学习训练函数 train_meta
train_meta 是在常规训练基础上的在线优化模块,核心是 “加载预训练模型→适应新场景→快速更新策略”,适用于场景动态变化的情况(如威胁区域位置改变)。
与 train 的核心差异的在于:
模型初始化:加载常规训练好的模型(trainers[0].load(filename),filename 为预训练模型路径),而非从头训练;
网络更新触发条件:总步数 step_total > MetaLearnStep 且每 10 步更新一次,且仅更新 T=7 次(快速适应新场景,避免过拟合);
更新函数:调用 updata_meta 而非 updata(元学习专用更新逻辑,通常采用 “快速梯度下降”,用少量数据快速调整参数);
回合数:仅训练 1 个回合(元学习注重 “单场景快速适应”,而非多回合积累)。
def train_meta(config):
print('-------------meta_begin------------')
setup_seed(0)
time_all = [] # 计算样本数据利用周期
time_start = time.time()
# -------------------设训练日志-------------------
nowt = time.strftime("%Y-%m-%d", time.localtime()) # 对时间进行格式化
train_log_dir = config.log_dir + '/' + nowt + '_train_logs'
train_logger = SummaryWriter(str(train_log_dir)) # 建立一个log
# -------------------测试网络参数选择-------------------
filename = './policy/policy2024-01-18/450'
# -------------------用Unity Environment#TODO:未引入包-------------------
if config.use_env:
env = Unity_env()
env_info = env.get_env_info()
# print(env_info)
# --------------------python Environment设置-----------
if config.threat_area:
action_n = [[0, 0, 0], [0, 0], [0, 0]] # 动作空间我3:攻角,倾侧,力,adv2:横向过载、纵向过载,adv 2
act_shape_n = [3, 2, 2]
obs_shape_n = [23, 12, 12] # 状态空间:25=我6+adv6+半径+adv6+半径+目标点3 adv12:我6+adv6
if config.Err_U:
obs_shape_n = [24, 12, 12]
# -------------------构建网络---------------------------
trainers = []
for i in range(config.num_agents - config.num_adversaries):
if config.good_policy == 'TD3':
if config.use_RND:
from trainers.MATD3.MATD3 import MATD3RND
trainers.append(MATD3RND(state_dim=obs_shape_n[i], action_dim=act_shape_n[i], agent_index=i,
num_agents=config.num_agents - config.num_adversaries,
arglist=config))
else:
from trainers.MATD3.MATD3 import MATD3
trainers.append(MATD3(state_dim=obs_shape_n[i], action_dim=act_shape_n[i], agent_index=i,
num_agents=config.num_agents - config.num_adversaries,
arglist=config))
if config.good_policy == 'TD3_pred':
from trainers.TD3.TD3 import TD3
trainers.append(TD3(obs_shape_n[0], act_shape_n[0], arglist=config))
if config.good_policy == "MASAC":
from trainers.MASAC.MASAC import AgentModSAC
trainers.append(AgentModSAC(net_dim=config.net_dim, state_dim=obs_shape_n[i], agent_index=i,
num_agents=config.num_agents - config.num_adversaries,
action_dim=act_shape_n[i],
arglist=config))
trainers[0].load(filename) # 放入参数
for i in range(config.num_agents - config.num_adversaries, config.num_agents):
if config.adv_policy == 'PN':
from trainers.PN.PNN import PNN
trainers.append(PNN())
# -------------------计数参数-------------------
step_total = 0 # 所有的步数,用于开始学习
done_episodes_50 = 0 # 计算成功率
collect_data = {"tf_reward": [], "done": [], "done_rate": [], "episode_steps": []} # 收集信息
ori_data = np.zeros((1, 24)) # 保存原始数据
mark = 1 # 定场景
std_state = np.zeros((1, 25))
std_a = np.zeros((1, 3))
dis1 = np.array([0])
dis2 = np.array([0])
disp = np.array([0])
q_coll = []
T=7(3) 测试与可视化函数 display
display 是训练结果的验证与可视化模块,核心是 “加载训练好的模型→多回合测试→轨迹与区域可视化”,用于直观评估策略性能。
与 train 的核心差异在于:
模型加载:加载元学习优化后的模型(trainers[0].load(filename+"2024-03-22meta")),仅用于推理,不更新网络;
测试回合数:共测试 51 个回合(足够统计成功率);
可视化逻辑:
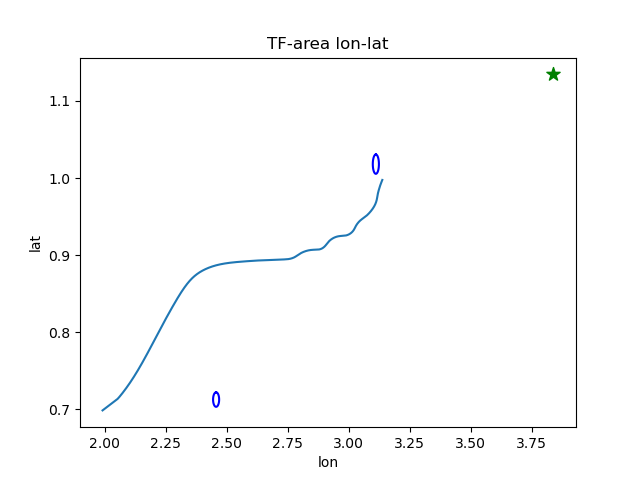
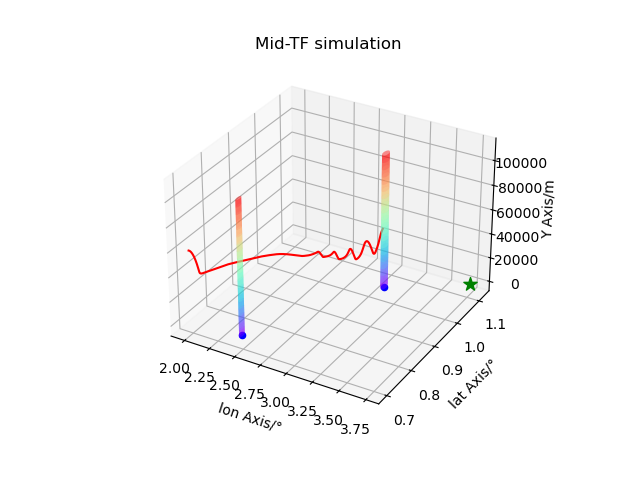
3D 轨迹图:绘制我方智能体的飞行轨迹(红色)、敌方位置(蓝色球体)、目标点(绿色星标)、威胁区域(彩色曲面),直观展示避障效果;
2D 经纬度图:绘制我方轨迹(折线)、目标点(绿色星标)、初始威胁区域(蓝色圆),评估导航路径是否合理;
成功率统计:每 50 个回合计算一次成功率(done_episodes_50 / 50),并打印结果,量化策略性能。
for episode in range(1): # 回合遍历
py_env = TF_threat_area(num_agents=config.num_agents, random_num=config.num_adversaries,
threat_area=config.threat_area)
step_episode = 0 # 每回合的步数,用于reward
reward_coll = []
obs_n = py_env.reset(mark=mark) # 初始化环境(1,25)
if config.use_env: # TODO:未引入包-------------------
env.reset() # ndarray[1,:]
unity_obs = obs_n
a = env.step(unity_obs)
if config.Save_origin:
ori_data = np.append(ori_data, obs_n, axis=0) # 初始化原始数据(1,25)
if config.State_Noise:
obs_n = py_env.noise(obs_n) # 加噪声-->[1.18]
obs_std, reward_std = py_env.max_min_standard(obs_n, 0) # 最大最小规范化
t = 0
while True:
step_total += 1
step_episode += 1
for i in range(config.num_agents - config.num_adversaries):
a = trainers[i].select_action(obs_std)
action_n[i] = a.reshape(-1)
for i in range(config.num_agents - config.num_adversaries, config.num_agents):
if config.threat_area: # 静态障碍
action_n[i] = [0, 0]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
q_act = trainers[0].q_critic(torch.FloatTensor(obs_std).to(device),
torch.FloatTensor(action_n[0].reshape(1, -1)).to(device))
q_coll.append(q_act)
obs_n_, reward, done, dis_2D_min1, dis_2D_min2, dis_2D_p = py_env.step(action_n, step_episode) # 状态转移
if config.use_env: # TODO:未引入包-------------------
a = env.step(obs_n_)
if config.Save_origin:
ori_data = np.append(ori_data, obs_n_, axis=0) # 记录状态
reward_coll.append(reward) # 记录reward
train_logger.add_scalar('reward', reward, step_total)
train_logger.add_scalar('action_u1', action_n[0][0], step_total)
train_logger.add_scalar('action_u2', action_n[0][1], step_total)
if config.State_Noise:
obs_n_ = py_env.noise(obs_n_) # 加噪声
if done:
print("step_episode: {}".format(step_episode), reward, done)
obs_n_ = obs_n
dis1 = np.append(dis1, dis_2D_min1)
dis2 = np.append(dis2, dis_2D_min2)
disp = np.append(disp, dis_2D_p)
train_logger.add_scalar('reward_end', reward, episode)
reward_mean = sum(reward_coll) / step_episode
train_logger.add_scalar('reward_coll', reward_mean, episode)
train_logger.add_scalar('dis_2D_min1', dis_2D_min1, episode)
train_logger.add_scalar('dis_2D_min2', dis_2D_min2, episode)
train_logger.add_scalar('dis_p', dis_2D_p, episode)
collect_data["tf_reward"].append(reward_mean)
# collect_data["adv_reward"].append(reward)
collect_data["episode_steps"].append(step_episode)
obs_std_, reward_std_ = py_env.max_min_standard(obs_n_, reward) # 规范化
# -------------------存新数据-----------------------
done_ = 0 if done == 0 else 1 # 此处改一下合理点
if config.good_policy in ["maddpg", "TD3", "MASAC"]:
trainers[0].add_experience(obs_std, action_n[0], reward_std_, obs_std_, done_, 0, step_episode)
# ------------------更新参数------------------------
loss_n = []
if step_total > config.MetaLearnStep and step_total%10==0 and t<T:
loss = trainers[0].updata_meta(episode, 0, trainers[0:config.num_agents - config.num_adversaries],
logger=train_logger)
loss_n.append(loss)
t+=1
# ---------------------------记成功率---------------
if done:
time_end = time.time()
time_all.append(time_end - time_start)
print('样本数据利用周期:',time_all)
if done == 1:
done_episodes_50 += 1
if episode % 50 == 0:
train_logger.add_scalar('done_rate', done_episodes_50 / 50, episode / 50)
collect_data["done_rate"].append(done_episodes_50 / 50)
# print(done_episodes_50 / 50)
done_episodes_50 = 0
break
obs_n = obs_n_
obs_std = obs_std_
if episode % 50 == 0: # 每50回合保存数据,第0个回合也保存
np.save(filename + nowt + 'meta' + "_collect_data", collect_data)
# -------------------训练结束-------------------
trainers[0].save(filename + nowt + 'meta') # 保存网络参数
# print('game over')
np.save(filename + nowt + 'meta' + "dis1.npy", dis1)
np.save(filename + nowt + 'meta' + "dis2.npy", dis2)
np.save(filename + nowt + 'meta' + "disp.npy", disp)
if config.Save_origin:
np.save(filename + nowt + 'meta' + "ori_data.npy", ori_data) # 保存原始数据
np.save(filename + nowt + 'meta' + "std_state_data.npy", std_state)
np.save(filename + nowt + 'meta' + "std_a_data.npy", std_a)
train_logger.export_scalars_to_json(train_log_dir + 'summary.json')
train_logger.close()
print('-------------meta_end-------------')
def display(config):
print('-------------diaplay_begin-------------')
setup_seed()
# -------------------设训练日志-------------------
nowt = time.strftime("%Y-%m-%d", time.localtime()) # 对时间进行格式化
train_log_dir = config.log_dir + '/' + nowt + '_train_logs'
train_logger = SummaryWriter(str(train_log_dir)) # 建立一个log
# -------------------测试网络参数选择-------------------
filename = './policy/policy2024-01-18/450'
# -------------------用Unity Environment#TODO:未引入包-------------------
if config.use_env:
env = Unity_env()
env_info = env.get_env_info()
# print(env_info)
# --------------------python Environment设置-----------
if config.threat_area:
action_n = [[0, 0, 0], [0, 0], [0, 0]] # 动作空间我3:攻角,倾侧,力,adv2:横向过载、纵向过载,adv 2
act_shape_n = [3, 2, 2]
obs_shape_n = [23, 12, 12] # 状态空间:25=我6+adv6+半径+adv6+半径+目标点3 adv12:我6+adv6
if config.Err_U:
obs_shape_n = [24, 12, 12]
# -------------------构建网络---------------------------
trainers = []
for i in range(config.num_agents - config.num_adversaries):
if config.good_policy == 'TD3':
if config.use_RND:
from trainers.MATD3.MATD3 import MATD3RND
trainers.append(MATD3RND(state_dim=obs_shape_n[i], action_dim=act_shape_n[i], agent_index=i,
num_agents=config.num_agents - config.num_adversaries,
arglist=config))
else:
from trainers.MATD3.MATD3 import MATD3
trainers.append(MATD3(state_dim=obs_shape_n[i], action_dim=act_shape_n[i], agent_index=i,
num_agents=config.num_agents - config.num_adversaries,
arglist=config))
if config.good_policy == 'TD3_pred':
from trainers.TD3.TD3 import TD3
trainers.append(TD3(obs_shape_n[0], act_shape_n[0], arglist=config))
if config.good_policy == "MASAC":
from trainers.MASAC.MASAC import AgentModSAC
trainers.append(AgentModSAC(net_dim=config.net_dim, state_dim=obs_shape_n[i], agent_index=i,
num_agents=config.num_agents - config.num_adversaries,
action_dim=act_shape_n[i],
arglist=config))
trainers[0].load(filename+"2024-03-22meta") #放入参数
# trainers[0].load(filename) # 放入参数
for i in range(config.num_agents - config.num_adversaries, config.num_agents):
if config.adv_policy == "ddpg":
from trainers.DDPG.ddpg import ddpg_agent
trainers.append(ddpg_agent(obs_shape_n[1], act_shape_n[1], arglist=config, Parallel=Parallel))
##TODO:
if config.adv_policy == 'PN':
from trainers.PN.PNN import PNN
trainers.append(PNN())
# -------------------计数参数-------------------
step_total = 0 # 所有的步数,用于开始学习
done_episodes_50 = 0 # 计算成功率
collect_data = {"tf_reward": [], "done": [], "done_rate": [], "episode_steps": []} # 收集信息
ori_data = np.zeros((1, 24)) # 保存原始数据
mark = 1 # 定场景
std_state = np.zeros((1, 25))
std_a = np.zeros((1, 3))
dis1 = np.array([0])
dis2 = np.array([0])
disp = np.array([0])
q_coll = []
# -------------------测试开始-------------------
for episode in range(51): # 回合遍历
action_collect = np.zeros((1, 3))
py_env = TF_threat_area(num_agents=config.num_agents, random_num=config.num_adversaries,
threat_area=config.threat_area)
step_episode = 0 # 每回合的步数,用于reward
reward_coll = []
obs_n = py_env.reset(mark=mark) # 初始化环境(1,25)
if config.use_env: # TODO:未引入包-------------------
env.reset() # ndarray[1,:]
unity_obs = obs_n
a = env.step(unity_obs)
if config.Save_origin:
ori_data = np.append(ori_data, obs_n, axis=0) # 初始化原始数据(1,25)
if config.State_Noise:
obs_n = py_env.noise(obs_n) # 加噪声-->[1.18]
obs_std, reward_std = py_env.max_min_standard(obs_n, 0) # 最大最小规范化
while True:
step_total += 1
step_episode += 1
for i in range(config.num_agents - config.num_adversaries):
a = trainers[i].select_action(obs_std)
action_collect= np.append(action_collect, a, axis=0)
action_n[i] = a.reshape(-1)
for i in range(config.num_agents - config.num_adversaries, config.num_agents):
if config.threat_area: # 静态障碍
action_n[i] = [0, 0]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
q_act = trainers[0].q_critic(torch.FloatTensor(obs_std).to(device),
torch.FloatTensor(action_n[0].reshape(1, -1)).to(device))
q_coll.append(q_act)
obs_n_, reward, done, dis_2D_min1, dis_2D_min2, dis_2D_p = py_env.step(action_n, step_episode) # 状态转移
if config.Save_origin:
ori_data = np.append(ori_data, obs_n_, axis=0) # 记录状态
reward_coll.append(reward) # 记录reward
train_logger.add_scalar('reward', reward, step_total)
train_logger.add_scalar('action_u1', action_n[0][0], step_total)
train_logger.add_scalar('action_u2', action_n[0][1], step_total)
if config.State_Noise:
obs_n_ = py_env.noise(obs_n_) # 加噪声
if done:
obs_n_ = obs_n
dis1 = np.append(dis1, dis_2D_min1)
dis2 = np.append(dis2, dis_2D_min2)
disp = np.append(disp, dis_2D_p)
train_logger.add_scalar('reward_end', reward, episode)
reward_mean = sum(reward_coll) / step_episode
train_logger.add_scalar('reward_coll', reward_mean, episode)
train_logger.add_scalar('dis_2D_min1', dis_2D_min1, episode)
train_logger.add_scalar('dis_2D_min2', dis_2D_min2, episode)
train_logger.add_scalar('dis_p', dis_2D_p, episode)
collect_data["tf_reward"].append(reward_mean)
# collect_data["adv_reward"].append(reward)
collect_data["episode_steps"].append(step_episode)
obs_std_, reward_std_ = py_env.max_min_standard(obs_n_, reward) # 规范化
if done:
print("step_episode: {}".format(step_episode), reward, done)
fig = plt.figure(episode)
ax = fig.add_subplot(projection='3d')
ax.plot(ori_data[-step_episode:-1, 1], ori_data[-step_episode:-1, 2], ori_data[-step_episode:-1, 0] - py_env.Re, color="r")
ax.scatter(ori_data[-1, 7], ori_data[-1, 8], ori_data[-1, 6] - py_env.Re, color="b")
ax.scatter(ori_data[-1, 14], ori_data[-1, 15], ori_data[-1, 13] - py_env.Re, color="b")
ax.scatter(py_env.target[1], py_env.target[2], py_env.target[0] - py_env.Re, color="g", marker="*",
s=100)
u = np.linspace(0, 2 * np.pi, 50) # 把圆分按角度为50等分
h1 = np.linspace(0, 110e3, 20) # 把高度1均分为20份
x1 = np.outer(ori_data[-1, 7] + 60e3/ py_env.Re / np.cos(ori_data[-1, 8]) * np.sin(u), np.ones(len(h1))) # x值重复20次
z1 = np.outer(ori_data[-1, 8] + 60e3/ py_env.Re * np.cos(u), np.ones(len(h1))) # y值重复20次
y1 = np.outer(np.ones(len(u)), h1) # x,y 对应的高度
h2 = np.linspace(0, 110e3, 20) # 把高度1均分为20份
x2 = np.outer(ori_data[-1, 14] + 80e3/ py_env.Re / np.cos(ori_data[-1, 15]) * np.sin(u), np.ones(len(h2))) # x值重复20次
z2 = np.outer(ori_data[-1, 15] + 80e3/ py_env.Re * np.cos(u), np.ones(len(h2))) # y值重复20次
y2 = np.outer(np.ones(len(u)), h2) # x,y 对应的高度
ax.plot_surface(x1,z1 ,y1 , cmap=plt.get_cmap('rainbow'), alpha=0.5)
ax.plot_surface(x2,z2,y2, cmap=plt.get_cmap('rainbow'), alpha=0.5)
ax.set_xlabel("lon Axis/°")
ax.set_ylabel("lat Axis/°")
ax.set_zlabel("Y Axis/m")
ax.set_title("Mid-TF simulation")
plt.show()
u = np.linspace(0, 2 * np.pi, 50) # 把圆分按角度为50等分
a1 = ori_data[-step_episode, 12] / py_env.Re / np.cos(ori_data[-step_episode, 8])
b1 = ori_data[-step_episode, 12] / py_env.Re
a2 = ori_data[-step_episode, 19] / py_env.Re / np.cos(ori_data[-step_episode, 16])
b2 = ori_data[-step_episode, 19] / py_env.Re
x1 = ori_data[-step_episode, 7] + a1 * np.sin(u) # x值重复20次
z1 = ori_data[-step_episode, 8] + b1 * np.cos(u) # y值重复20次
x2 = ori_data[-step_episode, 14] + a2 * np.sin(u) # x值重复20次
z2 = ori_data[-step_episode, 15] + b2 * np.cos(u) # y值重复20次
plt.plot(ori_data[-step_episode:-1, 1], ori_data[-step_episode:-1, 2]) # 经纬度
plt.scatter(220 * np.pi / 180, 65 * np.pi / 180, color="g", marker="*", s=100)
plt.plot(x1, z1, color="b")
plt.plot(x2, z2, color="b")
plt.ylabel('lat')
plt.xlabel('lon')
plt.title("TF-area lon-lat")
plt.show()
if done == 1:
done_episodes_50 += 1
if episode % 50 == 0:
train_logger.add_scalar('done_rate', done_episodes_50 / 50, episode / 50)
collect_data["done_rate"].append(done_episodes_50 / 50)
print('进行50次TF试验,成功率为:',done_episodes_50 / 50)
done_episodes_50 = 0
break
obs_n = obs_n_
obs_std = obs_std_
if episode % 50 == 0: # 每50回合保存数据
np.save(filename + "_collect_data", collect_data)
# -------------------训练结束-------------------
np.save(filename + "dis1.npy", dis1)
np.save(filename + "dis2.npy", dis2)
np.save(filename + "disp.npy", disp)
if config.Save_origin:
np.save(filename + "11ori_data.npy", ori_data) # 保存原始数据
np.save(filename + "std_state_data.npy", std_state)
np.save(filename + "std_a_data.npy", std_a)
train_logger.export_scalars_to_json(train_log_dir + 'summary.json')
train_logger.close()
print('-------------display_end-------------')
# Press the green button in the gutter to run the script.3、入口函数与执行流程
代码的入口是 if __name__ == '__main__':,通过 Config 类的 display 参数控制执行流程:
if __name__ == '__main__':
config = Config() # 实例化配置类
if config.display:
if config.meta:
train_meta(config) # 1. 若启用元学习,先执行元学习优化
display(config) # 2. 执行测试与可视化
else:
train(config) # 3. 若不启用可视化,执行常规训练结果:
进行50次TF试验,成功率为: 0.96

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)