大模型技术演变-2序列建模突破Sequence to Sequence Learning with Neural Networks读后笔记
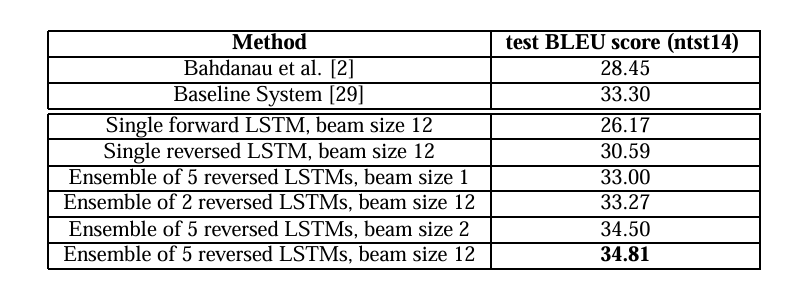
Google团队2014年提出的Seq2Seq模型开创了端到端神经机器翻译的新范式。该研究采用编码器-解码器架构,通过多层LSTM将输入序列编码为固定维向量再解码输出,创新性地引入输入反转策略提升性能。实验在WMT'14英法翻译任务上取得34.81 BLEU分,超越当时主流统计方法。尽管存在信息压缩瓶颈等问题,该工作为注意力机制和Transformer的诞生奠定基础,其端到端学习思想深刻影响了NL
这篇由Google团队在2014年发表的里程碑式论文,首次提出了端到端(End-to-End)的序列到序列(Seq2Seq)学习框架,并成功应用于机器翻译任务,为自然语言处理(NLP)领域奠定了坚实基础,其影响延续至今。
1. 核心思想与架构创新
论文的核心目标是解决变长输入序列到变长输出序列的映射问题。传统深度神经网络(DNNs)因固定输入输出维度的限制,无法处理此类任务。作者创新性地采用了编码器-解码器(Encoder-Decoder)架构,其中:
-
编码器:一个多层长短期记忆网络(LSTM),用于将输入序列编码为一个固定维度的上下文向量(Context Vector)
c。该向量旨在 encapsulate 整个输入序列的语义信息。-
数学表示:给定输入序列
(x₁, x₂, ..., x_T),编码器最终隐藏状态h_T通常作为上下文向量c = h_T。
-
-
解码器:另一个多层LSTM,其初始状态被设置为编码器最终的隐藏状态(
s₀ = c)。解码器以自回归(Autoregressive)的方式,逐步生成输出序列(y₁, y₂, ..., y_{T'})。-
数学表示:在每一步
t,解码器基于其当前状态s_{t-1}和上一步的输出y_{t-1}更新状态并预测当前输出:s_t = f_{dec}(s_{t-1}, y_{t-1}),y_t = g(s_t),其中g通常是 softmax 函数。
-
训练目标是最大化目标序列的条件概率:(1/|S|) ∑_{(T,S)∈S} log p(T|S),其中 S是训练集。
2. 关键技术与优化策略
2.1 输入序列反转(Reversing the Input Sequence)
论文一个看似简单却极其有效的技巧是将源句子中的单词顺序反转(例如,"a b c" → "c b a")。此举使得模型在测试集上的困惑度(Perplexity)从5.8降至4.7,BLEU评分从25.9提升至30.6。其原理在于:
-
引入短期依赖:反转后,输入句子的开头部分与输出句子的开头部分在距离上更接近,简化了优化问题。
-
改善记忆利用:可能帮助LSTM更好地利用其内存机制跟踪长程信息。
2.2 深度LSTM与模型规模
论文采用了4层深层LSTM,并发现其性能显著优于浅层网络。模型参数规模庞大:
-
输入词汇表大小:160,000
-
输出词汇表大小:80,000
-
词嵌入维度:1000
-
LSTM隐藏层单元数:1000
大规模模型验证了缩放定律(Scaling Laws) 的早期思想:增加模型规模、训练数据量和计算资源可以持续且可预测地提升模型性能。
2.3 训练细节与并行化
-
优化算法:使用随机梯度下降(SGD),初始学习率0.7,每完成5个训练周期(epoch)后减半。
-
梯度裁剪:将梯度范数限制在 [10, 25] 的范围内,有效防止了梯度爆炸。
-
批处理与分桶:批处理大小为128序列,并采用按句子长度分桶(bucketing) 的策略,将长度相近的句子放在同一批中,减少了填充(padding)开销,加速了训练。
-
并行化:在8个GPU上并行训练模型,每个LSTM层分配到一个GPU,其余4个GPU用于并行化softmax计算,展现了早期的大规模分布式训练思想。
3. 实验成果与性能分析
论文在 WMT'14 英语-法语数据集(包含1200万句对)上进行了实验:
-
主要结果:使用5个LSTM模型的集成,束搜索(beam search)的束宽(beam size)为2,取得了34.81的BLEU分数,优于当时基于短语的统计机器翻译(SMT)系统基线(33.30)。
-
重评分(Reranking):使用LSTM对SMT基线输出的1000个最佳候选列表进行重评分后,BLEU分数进一步提升至36.5,接近当时最好的公开结果37.0。
-
长句处理:模型在处理长句子时表现出色,通过输入反转策略,BLEU分数从25.9提高到30.6。
4. 意义、局限与后续影响
4.1 重要意义
-
端到端学习:减少了领域知识依赖,提供了一个通用的序列映射解决方案框架,推动了机器翻译从统计方法转向神经方法。
-
架构范式:编码器-解码器架构成为NLP乃至其他序列处理任务(如文本摘要、对话生成、图像描述)的核心范式之一。
-
规模验证:早期成功验证了大规模神经网络和数据的有效性,为后续大模型的发展铺平了道路。
4.2 固有局限性
-
信息压缩瓶颈:编码器需将整个输入序列的信息压缩到一个固定维度的上下文向量中。对于长序列,这如同“有损压缩”,可能导致信息丢失。
-
长程依赖与梯度问题:尽管LSTM缓解了梯度消失,但处理极长序列时,梯度传播和长期依赖捕捉仍是挑战。
4.3 深远影响
此论文直接启发并催生了后续一系列重大技术突破:
-
注意力机制(Attention Mechanism):为克服固定长度上下文向量的瓶颈,注意力机制被提出,允许解码器在生成每个词时“动态关注”输入序列的不同部分,极大提升了模型性能,尤其是长句处理能力。
-
Transformer架构:Vaswani等人于2017年在《Attention Is All You Need》中提出的Transformer模型,完全基于自注意力(Self-Attention)机制,摒弃了循环结构,实现了更好的并行化和更高效的学习,成为当今几乎所有大模型(如GPT、BERT、LLaMA)的基石。
5. 总结与展望
《Sequence to Sequence Learning with Neural Networks》是一项里程碑式的工作。它不仅证明了深度LSTM在复杂序列映射中的有效性,其提出的编码器-解码器框架和端到端学习思想更是深刻影响了NLP领域的发展轨迹。
论文中一些实践性发现(如输入反转),深刻反映了模型优化和记忆利用的内在机理。尽管原始Seq2Seq架构已被更先进的Transformer等模型超越,但其核心思想——使用神经网络端到端地学习复杂映射——仍是当前人工智能发展的核心驱动力之一。
从Seq2Seq到Attention,再到Transformer,这条技术演化脉络清晰地展示了深度学习如何通过不断自我革新来突破局限,迈向更强大的通用智能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)