【收藏必学】Context Engineering:解决大模型“失忆症“的关键技术,RAG的替代方案
本文探讨了Context Engineering如何解决大模型处理长文本时的"失忆症"。RAG本质是"搜索+生成"但被过度包装,而Context Rot现象表明大模型随Token增加性能下降。Context Engineering强调"给模型最需要的信息",通过筛选、重排、总结优化上下文。未来方向包括持续检索和Embedding空间操作。开发者应避免迷信大上下文窗口,构建高质量数据集,重视人工标注
最近AI圈又开始炒作新名词了,这次轮到"Context Engineering"(上下文工程)。说起来你可能不信,这个概念的走红,竟然源于一位数据库创始人对RAG的吐槽。
Chroma(开源向量数据库)的创始人Jeff Huber在最近的访谈里放了个大招:"我们公司从来不用RAG这个词。"这话一出,估计不少刚把"RAG专家"写进简历的同学心里一紧。
但他说得确实有道理。今天咱们就来聊聊:为什么RAG这个概念问题很大?Context Engineering到底是个什么东西?以及为什么你用GPT-4处理长文本时总感觉它"失忆"?
RAG:被过度包装的简单概念
先坦白说,我自己也曾经是RAG的"受害者"。刚开始接触时,总觉得这词儿特高级,又是检索又是生成,听着就复杂。直到后来深入做项目才发现——这不就是把搜索结果喂给大模型吗?
Jeff Huber的批判一针见血:“RAG把检索、生成、结合三个不同概念硬拼在一起,结果特别让人困惑。后来市场上还把它包装成’拿Embedding做一次向量搜索’,这理解也太肤浅了。”
说白了,RAG本质上就是"搜索+生成"的组合,但被包装成了一个神秘概念。这就像把"吃饭+睡觉"硬凑成一个新词"EatSleep",然后告诉你这是革命性突破——听着唬人,其实没啥新东西。
更麻烦的是,这种概念混乱让开发者走了不少弯路。很多团队以为搞个向量数据库,做个Embedding搜索,就叫"实现RAG了"。结果呢?用户问复杂问题时,模型要么答非所问,要么直接忽略关键信息。
问题出在哪儿?答案可能藏在一个你没听过的现象里——Context Rot(上下文腐烂)。
上下文腐烂:大模型的"失忆症"
你有没有遇到过这种情况:给GPT-4塞了一篇万字长文,让它回答里面的细节问题,结果它总能完美避开正确答案?不是模型笨,而是它得了"失忆症"。
Chroma团队做过一个实验:在多轮Agent交互中,当把完整对话窗口(包含大量历史Token)提供给模型时,明明写在上下文里的指令,竟然被模型完全忽视了。这就是所谓的"上下文腐烂"——随着Token数量增加,模型的注意力会分散,推理能力也会变弱。
最直观的证据来自他们发布的《Context Rot》技术报告。这张图对比了四款主流模型在不同输入长度下的性能衰减情况:
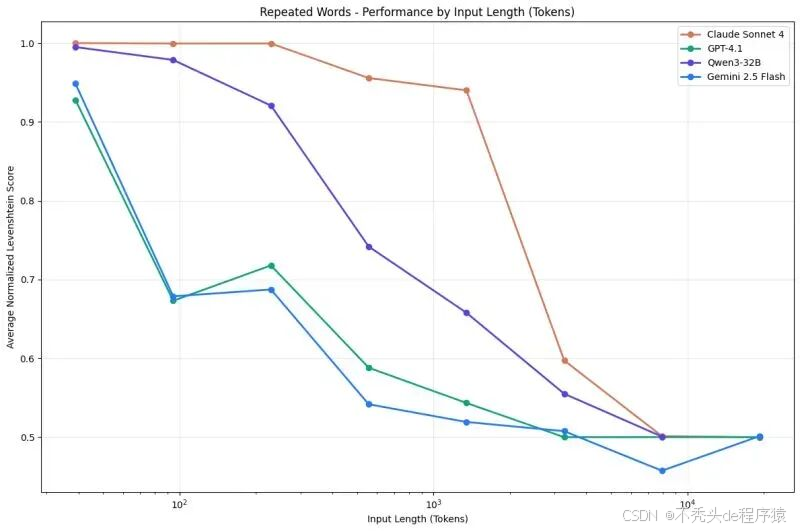
AI模型性能对比
如果用曲线下面积衡量整体表现,Claude Sonnet 4是表现最好的,其次是Qwen3-32B,而GPT-4.1和Gemini 2.5 Flash在上下文长度增加时衰减得更快。这也解释了为什么很多开发者偏爱Claude处理长文档——它的"记忆力"确实更好些。
但即便是表现最好的Sonnet 4,在输入Token超过8k后,性能也明显下降。这和厂商宣传的"百万Token上下文窗口"形成鲜明对比。说白了,现在的大模型就像个"短时记忆障碍患者",给它太多信息,它反而记不住重点。
Context Engineering:解决"失忆"的关键
既然大模型有"失忆症",那怎么让它记住关键信息?这就轮到Context Engineering登场了。
Jeff Huber对这个概念的定义很简单:**“在每一步生成时,决定上下文窗口里应该放什么的艺术。”** 听起来简单,但做起来学问大了。
举个例子:假设你要做一个法律助手AI,需要处理一份500页的合同。直接把整份合同喂给模型肯定不行(上下文腐烂),只挑几页又可能遗漏关键条款。这时候就需要Context Engineering:
- 先筛选:用向量搜索+关键词搜索,从500页中挑出最相关的20页
- 再重排:让大模型给这20页打分排序,选出Top 5
- 后总结:对Top 5内容做摘要,控制在模型能有效处理的Token范围内
这就是上下文工程的核心思路——不是给模型更多信息,而是给它最需要的信息。
有意思的是,现在前沿开发者已经开始用大模型自己来做"重排"。传统做法是用专门的re-rank模型(比如CrossEncoder),但现在很多团队直接写个Prompt:“以下是10段文档,请按与问题’XXX’的相关性排序”,然后让GPT-4或Claude来打分。
Jeff Huber甚至预测:**“专门的re-rank模型未来会边缘化。随着大模型成本降低,暴力筛选会成为主流。”** 想想也是,当调用GPT-4的成本降到现在的百分之一,谁还会费劲去调参那些小众的re-rank模型呢?
未来方向:别再回自然语言了
聊到这里,你可能会问:有没有更优雅的解决方案?总不能每次都手动筛选信息吧?
Jeff Huber提到了两个很有意思的方向,可能会改变未来检索系统的形态:
第一个方向:持续检索(Continuous Retrieval)
现在的模式是"一次检索,一次生成"——先搜完所有信息,再让模型生成答案。但为什么不能"边生成边检索"?就像我们聊天时,想到什么不确定的就立刻去查手机。
已经有研究在尝试这种模式了。比如GitHub上那篇叫RAGAR的论文(名字确实不咋地),就教模型在生成过程中"随时暂停,去查资料"。如果这种技术成熟,模型回答问题的方式会更像人类专家——既不是全凭记忆,也不是一次性查完所有资料。
第二个方向:停留在Embedding空间
现在的流程是:文本→Embedding→检索→转回文本→喂给模型。这就像把中文翻译成英文,传过去再翻译回中文——多此一举,还损失信息。
未来的系统可能会全程在Embedding空间操作:直接对向量做运算、比较、组合,不需要再转回自然语言。这就像两个程序员直接用二进制交流,虽然人类看不懂,但效率极高。
当然这些都还在研究阶段,但给我们提了个醒:别被现在的技术框架限制想象力。五年后回头看,我们今天把文本转来转去的做法,可能就像当年用软盘传文件一样原始。
给开发者的3个建议
聊了这么多理论,最后给大家来点实在的。基于Chroma团队的研究和实践,如果你正在做需要处理长文本的AI应用,这三个建议可能帮你少走弯路:
1. 别迷信"大上下文窗口"
就算模型号称支持100万Token,也别真把100万Token塞进去。实验显示,超过8k Token后,模型性能就开始下降。最佳实践是把上下文控制在4k-8k Token,超过就分段处理。
2. 构建"黄金数据集"
Chroma团队发现,很多开发者有数据、有答案,但缺少"查询-片段"对。解决办法是让大模型根据文档片段生成合理查询,构建自己的评测集。几百条高质量样本,效果可能比十万条垃圾数据还好。
3. 试试"披萨派对标注法"
Jeff Huber分享了个接地气的做法:团队一起点个披萨,花几小时手动标注数据。别小看这种"土办法",小而精的标注数据往往比大规模自动标注效果好得多。毕竟,AI再智能,也比不上一群懂业务的人一起讨论。
最后说两句
Context Engineering的走红,其实反映了AI开发的一个趋势:从追求酷炫概念,回归解决实际问题。RAG也好,上下文工程也罢,最终目的都是让AI更准确、更可靠地回答问题。
作为开发者,我们要警惕那些听起来高大上的术语。与其争当"RAG专家",不如多花时间研究:用户真正需要什么信息?模型在什么情况下会"失忆"?如何用最简单的方法提升系统稳定性?
毕竟,能解决问题的技术,才是好技术。至于叫什么名字,没那么重要。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献137条内容
已为社区贡献137条内容

所有评论(0)