南开大学等提出RAM++:从关注“降质”到关注“内容”,实现鲁棒的全能图像恢复
当AI模型面对一张雨天、雾天或充满噪点的模糊照片时,它应该先“识别”这是什么类型的降质,再去修复它?还是应该直接“想象”出这块区域原本清晰的样子?来自南开大学等机构的研究者们在一篇名为《RAM++: Robust …
当AI模型面对一张雨天、雾天或充满噪点的模糊照片时,它应该先“识别”这是什么类型的降质,再去修复它?还是应该直接“想象”出这块区域原本清晰的样子?来自南开大学等机构的研究者们在一篇名为《RAM++: Robust Representation Learning via Adaptive Mask for All-in-One Image Restoration》的论文中,给出了一个颠覆性的答案:关注内容,而非降质。
他们提出了一个名为 RAM++ 的两阶段一体化图像恢复框架。RAM(Robust Representation Learning via Adaptive Mask)的核心思想是,通过一种新颖的自适应掩码预训练,让模型学会强大的图像内容先验和生成先验,从而实现一种“面向内容”的鲁棒恢复,而不是停留在“面向降质”的传统思路上。该框架通过三大核心设计,有效解决了现有方法在任务间性能不平衡、易对已知降质过拟合、对未知降质泛化差等一系列痛点。实验表明,RAM++在多种已知、未知、极端和混合降质场景下,均展现了鲁棒、均衡且领先的性能。目前,代码和模型即将开源。

- 论文标题: RAM++: Robust Representation Learning via Adaptive Mask for All-in-One Image Restoration
- 作者: Zilong Zhang, Chujie Qin, Chunle Guo, Yong Zhang, Chao Xue, Ming-Ming Cheng, Chongyi Li
- 机构: 南开大学, Tiandy Technologies.
- 论文地址: https://arxiv.org/abs/2509.12039
- 项目地址: https://github.com/DragonisCV/RAM
“面向降质”的困境与“面向内容”的破局
一体化图像恢复(All-in-One Image Restoration)旨在用一个模型解决多种图像降质问题(如去雨、去雾、去噪、去模糊等),是底层视觉领域极具挑战性的任务。然而,现有方法大多遵循一种“面向降质”的思路:模型试图区分不同类型的降质,并为每种降质学习特定的恢复策略。
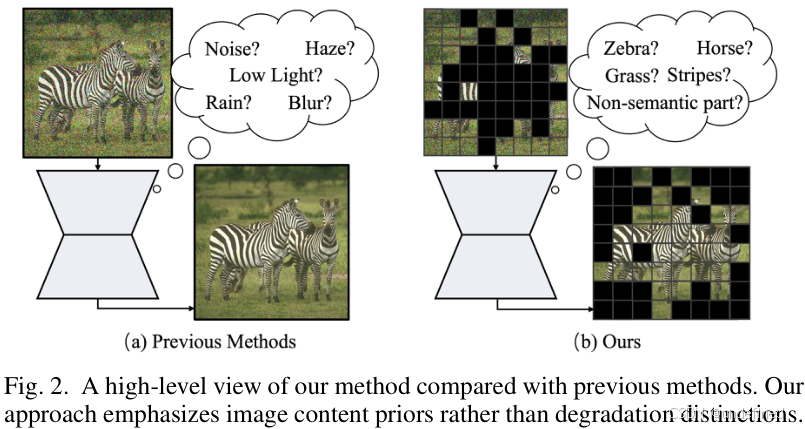
这种思路存在明显瓶颈:
- 性能不均衡:模型可能精通去雨,却拙于去雾。
- 泛化能力差:对训练时见过的合成降质类型容易过拟合,一旦遇到真实世界中未见过的、或多种降质混合的复杂场景,效果便会大打折扣。
- 极端场景失效:当降质与图像的自身结构(如纹理、边缘)强耦合时,模型很难分清哪些是降质、哪些是内容,导致恢复失败。
本文的作者们认为,与其让模型费力去“分辨降质”,不如让它学会“理解内容”。一个强大的恢复模型,应该具备对清晰图像的“想象力”,即强大的图像内容先验和生成先验。基于此,他们提出了RAM++,一个“面向内容”的全新范式。
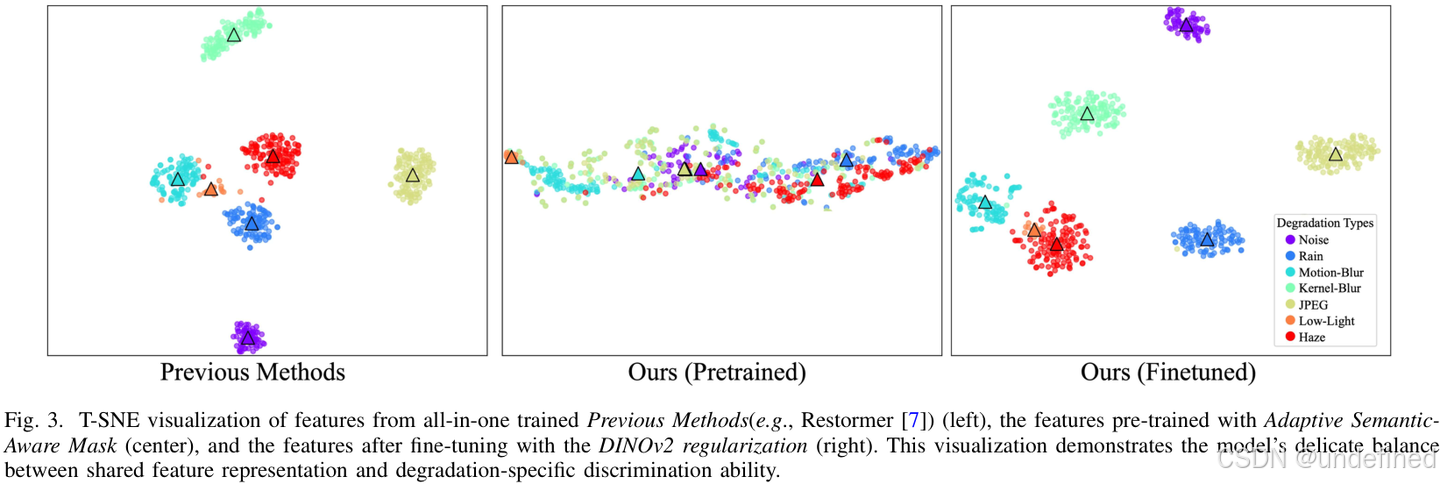
上图的t-SNE可视化清晰地展示了这一思想的优越性。传统方法(左图)学习到的特征在不同降质任务间界限分明,难以泛化。而RAM++经过预训练(中图)和微调(右图)后,其特征表示在不同任务间既有共享(实现一体化),又保留了必要的区分度,达到了理想的平衡状态。
RAM++:三大核心设计详解
RAM++是一个两阶段框架,包含“预训练”和“微调”两个阶段。其卓越性能的背后,是三个精心设计的模块:AdaSAM, MAC, 和 RFR。
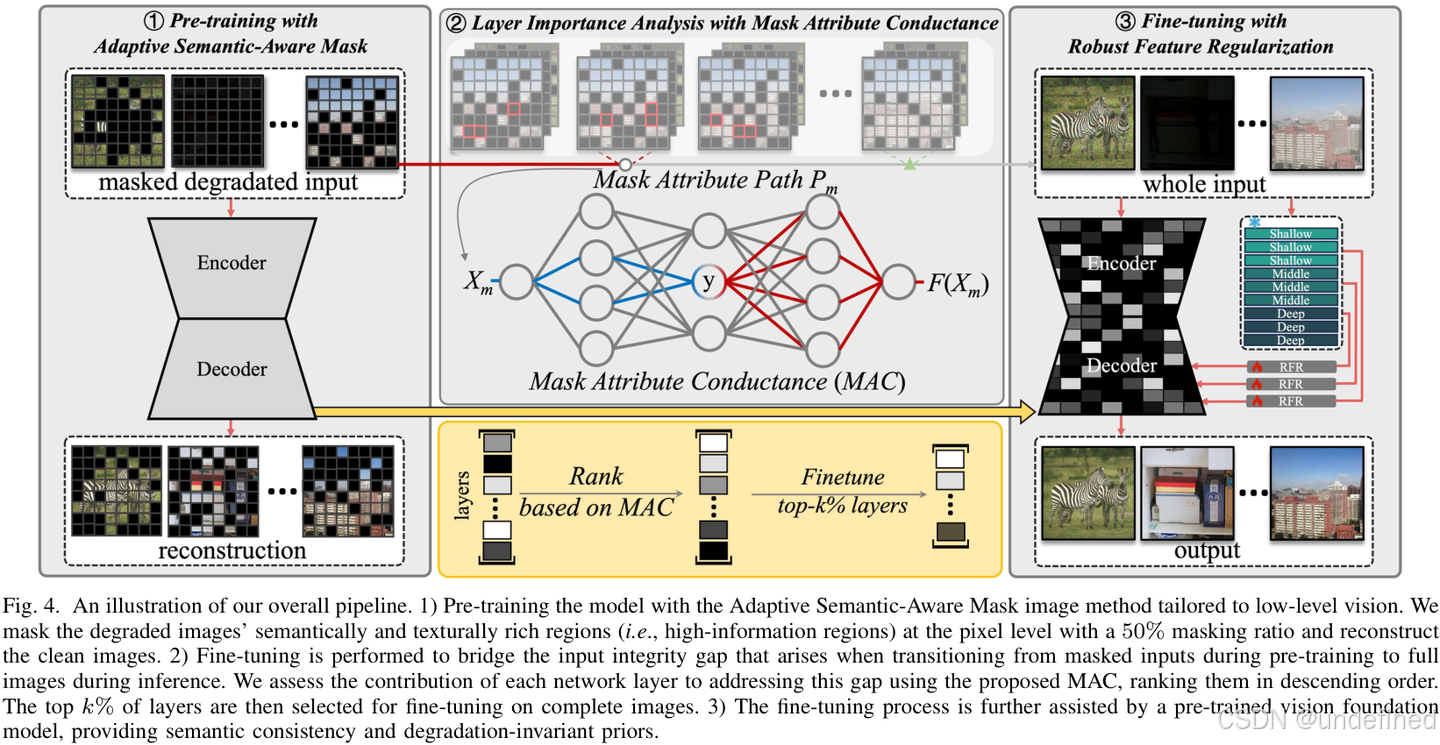
上图是RAM++的整体流程图,清晰地展示了预训练、微调和最终推理的完整过程。
1. 自适应语义感知掩码 (AdaSAM): 更聪明的预训练
RAM++的预训练阶段受到了掩码图像建模(MIM)的启发,但做出了关键的、针对底层视觉任务的改进。传统的MIM(如MAE)通常在图像块(Patch)级别上随机掩码,但这对于需要精细纹理恢复的底层任务来说过于粗糙。

如上图所示,像素级的掩码比块级的掩码能更好地保留图像的结构信息,对恢复任务至关重要。
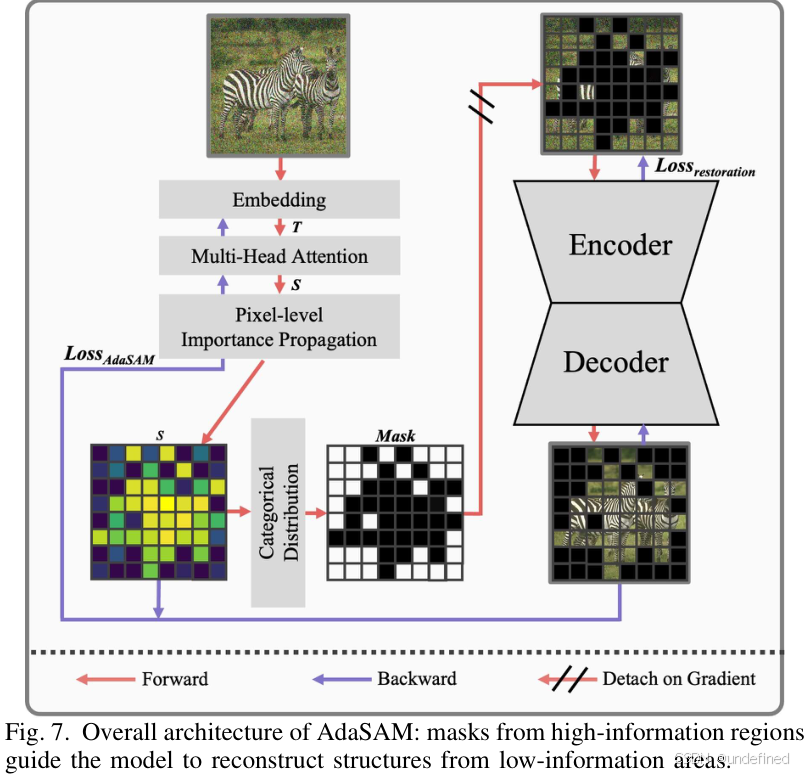
AdaSAM (Adaptive Semantic-Aware Mask) 的核心思想是:在信息量最丰富的区域进行掩码。它不再随机掩码,而是自适应地选择那些语义丰富、纹理复杂的区域(如物体的边缘、细节部分),在这些区域进行像素级的掩码。然后,模型被要求根据周围信息重建这些被掩盖的高信息量区域。通过这个“完形填空”的高难度任务,模型被迫学习到图像的内在结构和纹理规律,即强大的内容先验和生成先验,而不是去死记硬背各种降质的模式。
2. 掩码属性传导 (MAC): 更高效的微调
预训练阶段模型看的是“残缺”的图像,而推理时输入的是完整的图像,这之间存在“完整性差距”(integrity gap)。传统的做法是微调整个网络来适应,但这可能破坏预训练阶段学到的宝贵先验知识。
MAC (Mask Attribute Conductance) 提出了一种更高效的选择性微调策略。它首先通过一种传导机制,评估网络中每一层对于弥补这个“完整性差距”的贡献度,然后只选择性地微调那些贡献度最高的 Top-k% 的网络层。这种“好钢用在刀刃上”的做法,既高效地弥合了差距,又最大程度地保留了预训练学到的鲁棒先验。
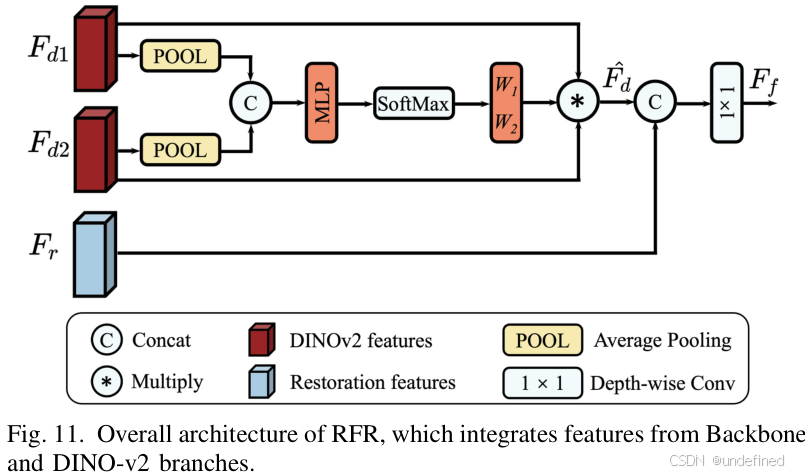
3. 鲁棒特征正则化 (RFR): 更具语义的恢复
为了保证恢复出的图像不仅清晰,而且在语义上是正确的(比如,不能把猫恢复成狗),微调阶段还需要一个“语义监督员”。
RFR (Robust Feature Regularization) 巧妙地利用了强大的视觉基础模型 DINOv2 的特征作为正则化项。DINOv2的特征以其强大的语义一致性和对降质的鲁棒性而闻名。在微调时,RAM++不仅要最小化重建损失,还要确保其生成的特征与DINOv2提取的特征保持一致。这相当于有了一个“语义老师”在旁边指导,确保恢复结果在内容和结构上是合理且连贯的。
实验结果:均衡、鲁棒、SOTA
论文在去雾、去雨、去噪、运动去模糊、低光增强等7个主流图像恢复任务上进行了全面评估。
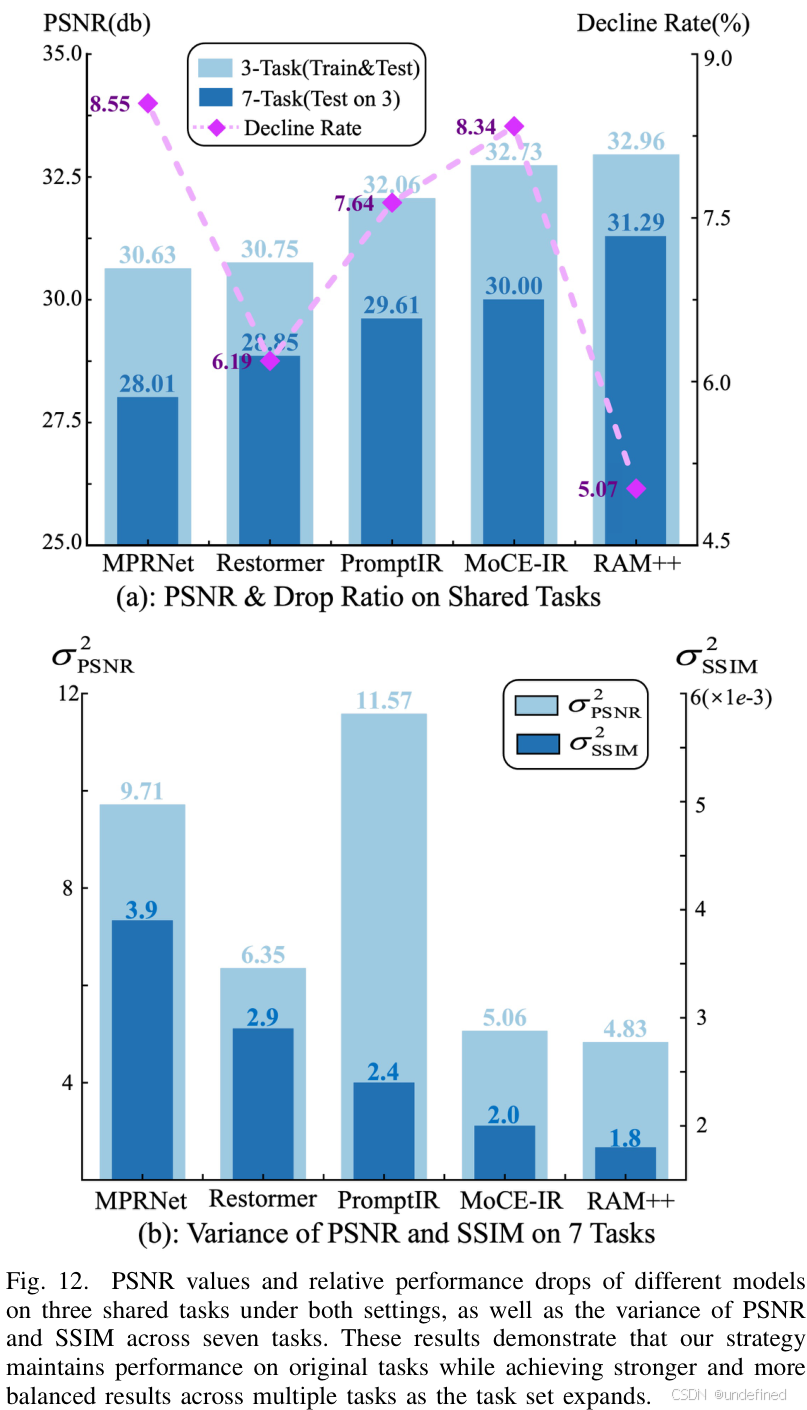
任务性能的均衡性

上表展示了在7个任务上的定量对比结果。可以看出,RAM++不仅在多个单项任务上取得了SOTA性能,更重要的是,它的平均性能和性能方差都表现最佳。这说明RAM++不像其他模型那样“偏科”,而是一个能力均衡的“全能选手”。
对未知降质的强大泛化能力
RAM++最令人印象深刻的是其强大的泛化能力。研究者在一些模型从未见过的“分布外”(OOD)降质任务上进行了测试,如水下图像增强、胡椒噪声去除等。
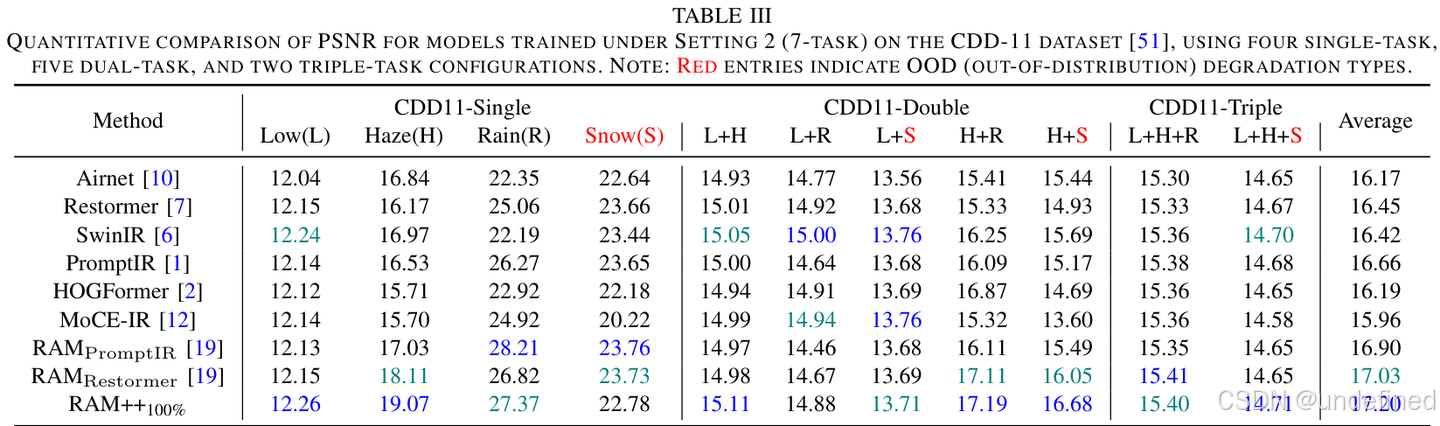
结果如上表所示(红色条目为OOD任务),RAM++在这些OOD任务上的表现显著优于其他方法,证明其学习到的内容先验使其能够从容应对未知的挑战。
视觉效果对比

去雾效果对比

去雨效果对比

水下图像增强(OOD任务)效果对比

去噪效果对比
从大量的视觉对比中可以清晰看到,无论是对于训练中见过的任务(去雨、去噪),还是从未见过的任务(水下增强),RAM++的恢复结果在细节、色彩和整体观感上都更加出色和自然。
总结与贡献
RAM++为一体化图像恢复领域带来了深刻的启示和坚实的贡献:
- 范式革新:提出了从“面向降质”到“面向内容”的思维转变,为解决一体化恢复的根本性难题指明了新方向。
- 创新的两阶段框架:通过AdaSAM、MAC和RFR三大核心设计,构建了一个完整、高效且逻辑自洽的预训练-微调框架,成功地让模型学习到了强大的内容和生成先验。
- 卓越的性能:在已知、未知、极端和混合降质场景下,均实现了鲁棒、均衡且SOTA的性能,尤其是在泛化能力上表现突出。
- 开源贡献:承诺开源代码和模型,将极大地推动社区在这一方向上的后续研究。
CV君认为,RAM++最核心的价值在于其思想的转变。它不再纠结于“降质是什么”,而是专注于“内容应该是什么”。这种“透过现象看本质”的思路,不仅让一体化图像恢复走上了一条更通用、更鲁棒的道路,也为其他计算机视觉任务提供了宝贵的借鉴。
了解最新 AI 进展,欢迎关注公众号:我爱计算机视觉
感谢点赞支持。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献121条内容
已为社区贡献121条内容

所有评论(0)