AI学习日记——k均值聚类
·
目录
一、聚类
定义:聚类是一种无监督学习技术,用于将数据分组为具有相似特征的类别。
在最开始不会告诉你三角和圆形两种类别,我们需要找到相似的样本点划为一类。
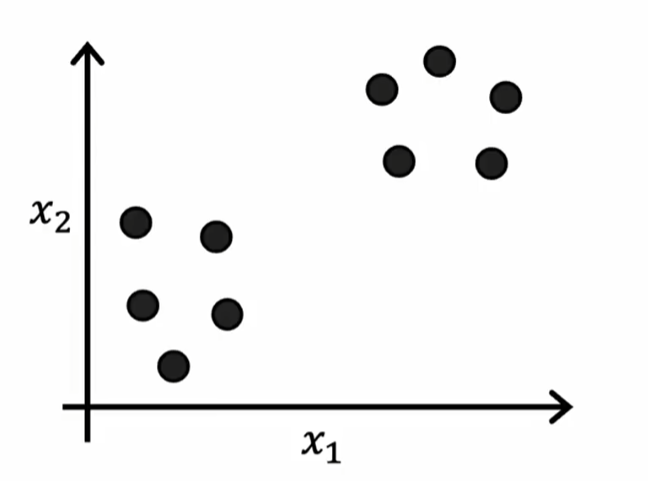
二、K-means聚类
1.算法步骤
- 随机选择K个初始中心点。
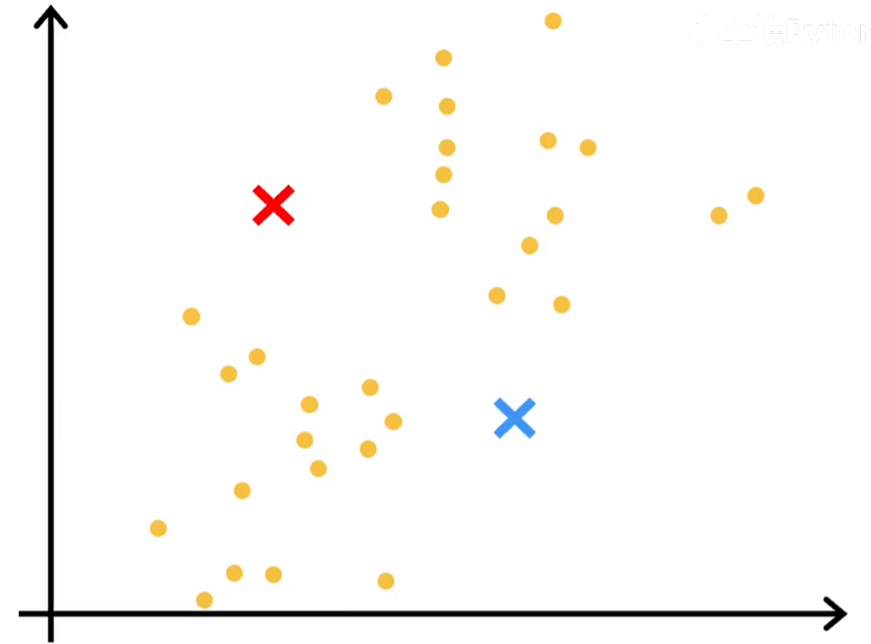
- 计算每个数据点到中心点的距离,分配到最近的中心点所属簇。
- 重新计算每个簇的中心点(均值)。
- 重复步骤2-3直到中心点不再显著变化或达到最大迭代次数。
2.损失函数
(1)公式
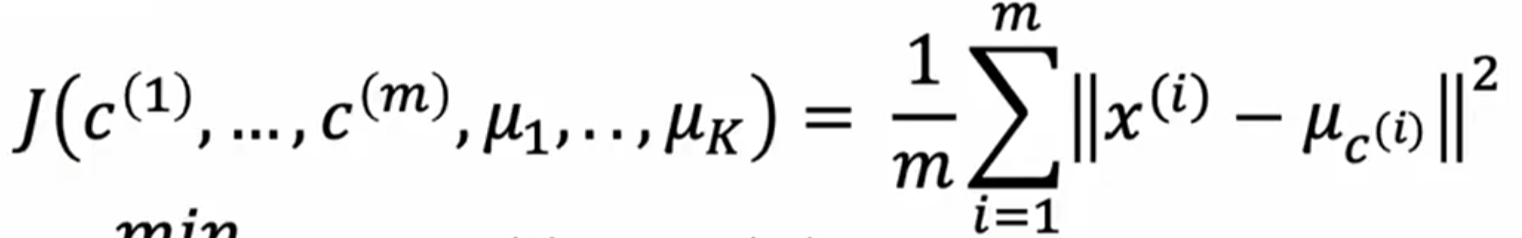
- k :簇的数量(主要根据实际应用场景选择,少数情况根据elbow法找损失函数图像转折点选择)
- Ci :表示第 i 个簇
:第 i 个簇的中心(均值)
- ( x -
(2)直观解释
-
簇内紧致性
损失函数衡量的是簇内数据点的紧密程度。值越小,说明数据点离其簇中心越近,簇内结构越紧凑。 -
算法优化目标
K均值算法通过迭代更新簇中心和数据点分配,不断降低损失函数的值,直到收敛(即簇中心不再显著变化)。
3.初始化k均值
一般情况下会随机选择k个样本点直接作为簇的中心,但是这样也会出现一个问题:
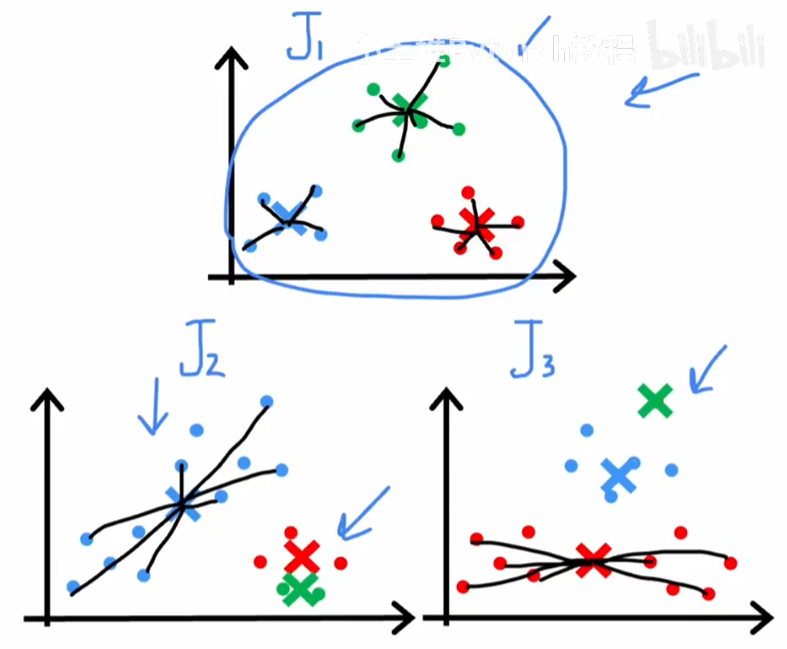
如图所示,下面两种情况会导致陷入到局部最优的情况,该如何解决?
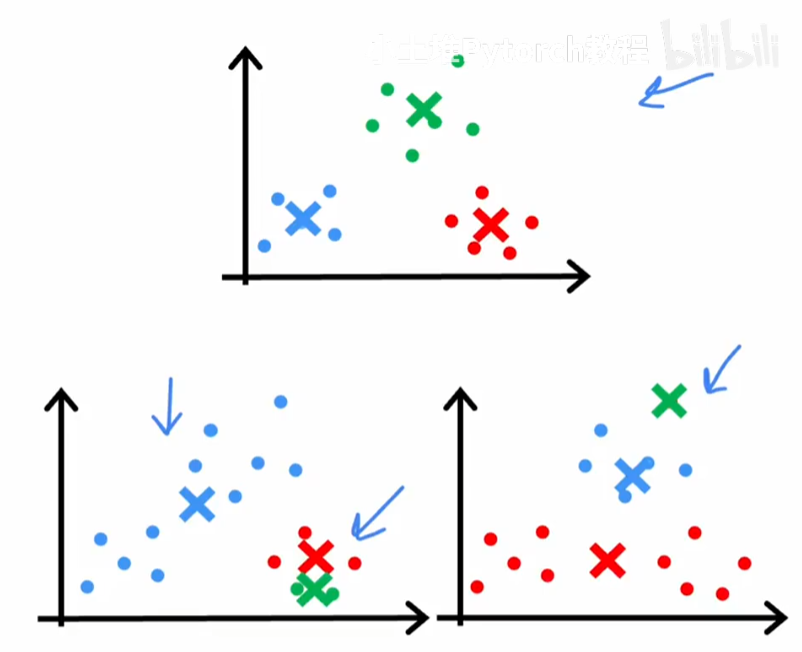
可以采用多次随机初始化k均值的簇中心,然后进行遍历,如下图三个图片就是三次初始化遍历的最终结果。我们持续计算每个初始化最终结果中的J损失函数,最终收敛
总结
本文主要介绍一种非监督式学习技术-------聚类算法中的k均值聚类算法K-means。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)