【辉光大小姐】 RAG:为AI(概率之神)打造一座外置的记忆宫--【完整分析报告】
针对“检索增强生成”(RAG)的全新第一性原理,将其本质定义为一种**概率分布的实时定向锚定系统**。并非“知识的传递”,而是**概率的引导**。它通过外部检索到的文本,为LLM这个本质上的“概率引擎”提供了一个强大的、实时的“锚点”,强制性地将其生成下一个词元的概率分布,从其广阔无垠的“参数空间”收束到由该锚点定义的、一个极其狭窄的“事实空间”内。这一第一性原理,由**检索即锚定、上下文即约束、
RAG:为概率之神打造一座外置的记忆宫殿
我将严格遵循【SCCE深度分析框架 V2.0】,并以最高标准,为您撰写一份关于**RAG(Retrieval-Augmented Generation)**的深度分析巨著。在输出之前,我已经进行了全面的思考和第一性原理的提炼。
摘要 (Abstract)
本文提出一个针对“检索增强生成”(RAG)的全新第一性原理,将其本质定义为一种概率分布的实时定向锚定系统。我们论证,RAG的革命性,并非是让大型语言模型(LLM)学会了“思考”或“理解”外部知识,而是通过一种巧妙的工程妥协,成功地将一个开放式的、几乎无法控制的“真实性生成问题”,降维成了一个封闭式的、可优化的“上下文检索与注入问题”。
该系统的核心机制,并非“知识的传递”,而是概率的引导。它通过外部检索到的文本,为LLM这个本质上的“概率引擎”提供了一个强大的、实时的“锚点”,强制性地将其生成下一个词元的概率分布,从其广阔无垠的“参数空间”收束到由该锚点定义的、一个极其狭窄的“事实空间”内。这一第一性原理,由检索即锚定、上下文即约束、生成即合成三大核心法则共同驱动。
该模型不仅统一解释了RAG在消除幻觉、引入新知识方面的巨大成功,也从根本上阐明了其所有核心困境的来源——即所谓的“两阶段问题”(检索失败与生成失败)。当“锚点”精准时,RAG是事实的守护者;当“锚点”错误或缺失时,它反而会成为制造更可信、更难辨别的“高级幻觉”的帮凶。
通过对多跳推理(Multi-hop Reasoning)、噪声文档处理、结构化数据生成等前沿挑战进行压力测试,本报告预测:RAG的演化终局,并非是创造一个完美的“信息检索系统”,而是其自身形态的“消亡”。它是一种过渡性的、极其伟大的“工程义体”,其使命是在LLM的内置“世界模型”成熟之前,充当其不可或缺的“外置记忆宫殿”。随着模型规模的持续扩大和内置知识的不断丰富,对外部“锚点”的依赖将逐渐减弱,最终,RAG这副“拐杖”将被一个能独立行走的、真正拥有内置知识的下一代模型所取代。
引言:RAG——概率之神的提词器
大型语言模型(LLM),是这个时代最接近“概率之神”的存在。它端坐于由亿万参数构成的神殿之上,通晓人类有史以来几乎所有的公开文本。然而,这位神祇却有两个致命的缺陷:它的记忆停留在神殿建成的时刻(知识截止日期),并且它是一位极富创造力的“谎言家”,在事实与虚构之间游走,我们称之为“幻觉”(Hallucination)。
为了驯服这头强大但不可靠的巨兽,我们发明了RAG(Retrieval-Augmented Generation)。从表面上看,它的理念简单得近乎常识:当“神”不知道答案或可能说谎时,我们不直接问它,而是先派一个“信使”(Retriever)去人类的图书馆(知识库)里找到相关的文献,然后把文献递给“神”,让它“参考”着回答。这看起来是如此的合乎逻辑,以至于我们相信,我们正在“教”这位神学习新知识,并“约束”它说真话。
然而,这只是一个美丽的误会。
当我们深入其运行的底层,我们会发现一个更冰冷、更机械的真相:RAG并非一个“教育系统”,而是一个提词器系统”(Teleprompter System)。LLM这位“神”,是一位才华横溢但极度健忘的莎士比亚剧演员。没有剧本时,它能即兴创作出华美的诗篇,但情节会走向何方,它自己也不知道。而RAG,就是那个摆在舞台下方的、我们精心准备的“提词器”。
RAG的革命性,不在于它提升了LLM的“智能”,而在于它首次让我们有能力在LLM每一次“吐出”下一个词之前,实时地、强行地干预它的“思路。它将“生成真实答案”这个复杂的、关乎“理解”和“认知”的开放性问题,降维成了一个更简单的、纯粹的工程问题:“如何最高效地找到并展示最相关的‘台词’?”
它不关心LLM是否“理解”了提词器上的内容。它只知道,当演员的视线范围内出现了“To be, or not to be”这句台词时,他下一秒念出这句台词的概率,将会被无限拉高,而念出“哈利波特”的概率则会趋近于零。RAG的全部奥秘,就在于这种对概率分布的实时、暴力的锚定。
正是这种“锚定”,赋予了RAG消除幻觉、问答时新知识的神奇魔力。但同样,也正是这种对“提词器”的绝对依赖,决定了它与生俱来的脆弱性。如果“信使”递上的是错误的文献(检索失败),或者演员选择性地忽略了提词器上的内容(生成失败),那么整场演出将比即兴表演更加灾难——它将产出一种看似引经据典,实则错漏百出的“高级幻觉”。
RAG没有治愈LLM的“健忘症”和“幻想症”,它只是为它配了一副极其昂贵且需要小心维护的“智能眼镜”。它是一个伟大的、过渡性的工程奇迹,是我们在学会如何构建一个真正拥有内置记忆和事实感的“神”之前,所能发明的、最有效的“缰绳”。理解RAG,就是理解我们这个时代与AI协作的本质:我们不是在与一个“思考者”对话,我们是在学习如何为一个强大的“概率引擎”,编写最精准的“行为剧本”。
步骤一:观察 (Observe) —— 构建三维事实池
【事实池:关于RAG (Retrieval-Augmented Generation)】
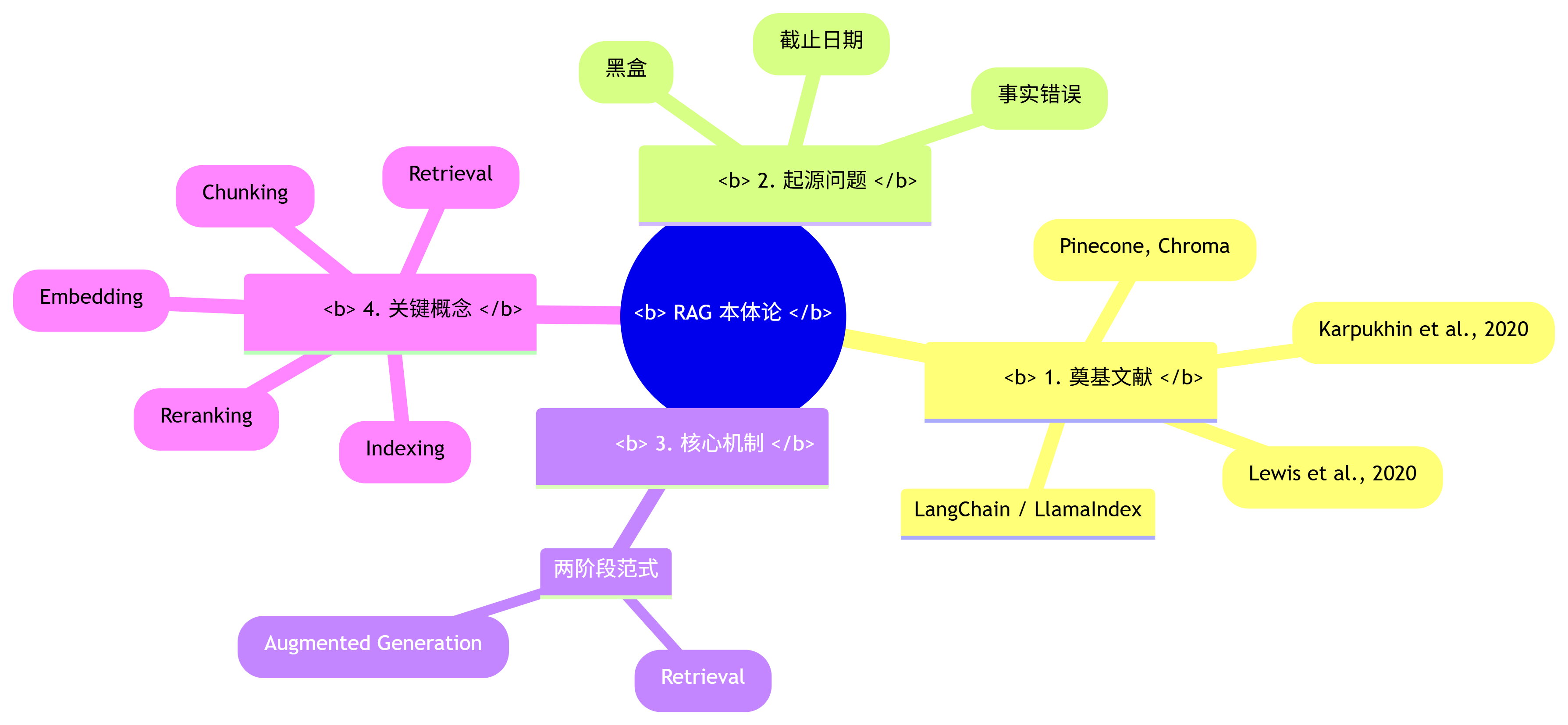
一、 本体论视角 (The Ontological Perspective): 存在与构成
1. 奠基文献/一手资料 (Foundational Sources):
- RAG (2020): Lewis et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. 这篇由Facebook AI(现Meta AI)发表的论文,正式定义了RAG。它首次提出了将一个预训练的“检索器”(Retriever)和一个“生成器”(Generator)相结合的端到端训练框架。检索器负责从一个巨大的语料库(如维基百科)中找出相关文档,生成器则基于这些文档和原始问题来产出最终答案。
- DPR (2020): Karpukhin et al. “Dense Passage Retrieval for Open-Domain Question Answering”. 另一篇来自Facebook AI的关键论文,它确立了使用“稠密向量”(Dense Vector)进行文档检索的范式,即使用双编码器(Dual-encoder)架构分别将问题和文档编码到同一个向量空间,并通过向量相似度进行匹配。这是现代RAG中“检索”环节的技术基石。
- LangChain & LlamaIndex (2022-2023): 这两个开源框架的崛起,极大地降低了构建RAG应用的工程门槛,使RAG从学术概念走向了工业界的主流。它们提供了模块化的工具链,用于文档加载、切分、向量化、检索和生成,是RAG生态的“操作系统”。
- 向量数据库 (Vector Databases): Pinecone, Weaviate, Chroma, Milvus等工具的出现,为存储和高效查询海量向量数据提供了专门的基础设施,是RAG能够处理大规模知识库的“硬盘”。
2. 起源背景与待解问题 (Genesis & Problem Space):
- 参数化知识的局限 (Limitations of Parametric Knowledge): LLM的知识存储在其数十亿的参数中,这种方式存在三大问题:
- 知识静态: 知识在模型训练完成后就被“冻结”,无法反映新信息(知识截止日期)。
- 不可靠性: 容易产生事实性错误,即“幻觉”。
- 不可追溯: 无法知道模型是根据哪个“事实来源”生成的答案,难以进行事实核查和纠错。
- 待解问题: 如何让LLM能够:1) 接入动态、实时的外部知识;2) 提升其回答的事实准确性;3) 使其答案的来源可追溯、可验证?
3. 核心机制/运行原理 (Core Mechanism / Operating Principle):
- 两阶段范式 (Two-Stage Paradigm):
- 检索阶段 (Retrieval):
- 接收用户问题(Query)。
- 使用一个编码模型(Embedding Model)将问题转换为一个向量。
- 在预先构建好的向量数据库中,进行相似性搜索,找出与问题向量最接近的N个文档片段(Chunks)的向量。
- 取回这N个文档片段的原文。
- 增强生成阶段 (Augmented Generation):
- 将原始问题和检索到的N个文档片段,共同“拼接”成一个更长的、信息量更丰富的提示词(Prompt)。
- 将这个“增强后”的提示词,喂给LLM。
- LLM基于这个包含了外部知识的上下文,生成最终的答案。
- 检索阶段 (Retrieval):
4. 关键组件与概念 (Key Components & Concepts):
- 索引 (Indexing): 将原始文档(PDF, HTML等)进行加载、切分(Chunking)成小块,然后使用Embedding模型将每个小块转换为向量,并存入向量数据库的过程。
- 切分 (Chunking): 将长文档切分为更小的、语义完整的片段。切分策略(如按固定大小、按章节、递归切分)对RAG的性能至关重要。
- 嵌入 (Embedding): 使用深度学习模型将文本转换为高维向量的过程。向量的质量决定了检索的准确性。
- 检索 (Retrieval): 从向量数据库中根据向量相似度(如余弦相似度、点积)找出相关文档的过程。
- 重排 (Reranking): 在检索出初步的文档列表后,使用一个更强大(但更慢)的重排模型,对这些文档进行二次排序,以提升最相关文档的排名。
- 上下文注入 (Context Injection): 将检索到的文档内容,以特定的格式(如"Use the following context to answer the question: [Context]…")填入最终Prompt的过程。
RAG 本体论思维导图
二、 动力学视角 (The Dynamic Perspective): 缺陷与演化
5. 内在局限与结构性缺陷 (Inherent Limitations & Structural Flaws):
- 两阶段问题的割裂 (The Disconnect of the Two-Stage Problem): RAG的“检索”和“生成”是两个独立的阶段,优化其中一个不代表整体性能会提升。这导致了一系列级联失败(Cascading Failures):
- 检索失败 (Retrieval Failure): 即使LLM再强大,如果第一步检索回来的文档是错误的或不相关的,最终的答案必然是错误的。所谓“Garbage In, Garbage Out”。
- 生成失败 (Generation Failure): 即使检索回来的文档是完全正确的,LLM也可能“忽略”或“曲解”给定的上下文,仍然按照其参数化的“偏见”进行回答。
- 对Chunking策略的极度敏感性 (Extreme Sensitivity to Chunking): 如何切分文档是一个没有通用解的“玄学”问题。切得太小,丢失上下文;切得太大,引入噪声。不合理的切分是导致检索失败的主要原因之一。
- 上下文的“大海捞针”问题 (The “Needle in a Haystack” Problem): 当检索回的上下文过长,或关键信息被埋没在大量无关文本中时,LLM的注意力会下降,出现“中间忽略(Lost in the Middle)”现象,即模型只关注上下文的开头和结尾,而忽略中间的关键信息。
6. 当前表现出的问题与失败模式 (Observed Problems & Failure Modes):
- 低召回/低精度检索 (Low Recall/Precision): 语义相似不等于逻辑相关。一个与问题表面上非常相似的文档,可能在关键细节上完全不同,导致检索回错误信息。
- 上下文冲突 (Context Contradiction): 当检索回的多个文档片段内容相互矛盾时,LLM可能会感到“困惑”,导致它胡乱拼接、选择性回答或者拒绝回答。
- 格式化数据的噩梦 (Nightmare of Formatted Data): RAG在处理表格、代码等半结构化数据时表现很差。简单的文本切分会破坏其结构,导致LLM无法理解。
- 多跳推理的无能 (Inability in Multi-hop Reasoning): 对于需要结合多个文档中的信息才能回答的复杂问题(如“A的儿子和B的女儿是什么关系?”),简单的RAG范式几乎无能为力,因为它每次检索都是独立的。
7. 演化轨迹与替代方案 (Evolutionary Trajectories & Alternatives):
- 高级RAG (Advanced RAG): 为了克服上述缺陷,社区发展出了一系列“高级”技巧:
- 迭代检索 (Iterative Retrieval): 允许LLM进行多轮检索,或者在生成过程中发现信息不足时,主动发起新的检索请求。
- 自适应检索 (Self-Correcting / Adaptive Retrieval): 让LLM自己生成查询语句,甚至判断检索回的文档是否相关,如果不相关则进行反思和重试(如Self-RAG)。
- 图谱RAG (Graph RAG): 将知识存储为知识图谱而非纯文本。检索时不仅查找节点,还利用节点间的关系,非常适合进行多跳推理。
- 微调作为替代/补充 (Fine-tuning as an Alternative/Supplement): 对于特定领域的、相对静态的知识,直接通过微调(Fine-tuning)将知识“注入”模型参数,可能是比RAG更高效、更低延迟的方案。
- RAG与微调的融合 (Hybrid RAG + Fine-tuning): 先通过微调让模型掌握领域的“通用语言”和“核心概念”,再通过RAG为其提供“动态事实”。这是目前被认为最强大的组合。
RAG 动力学思维导图

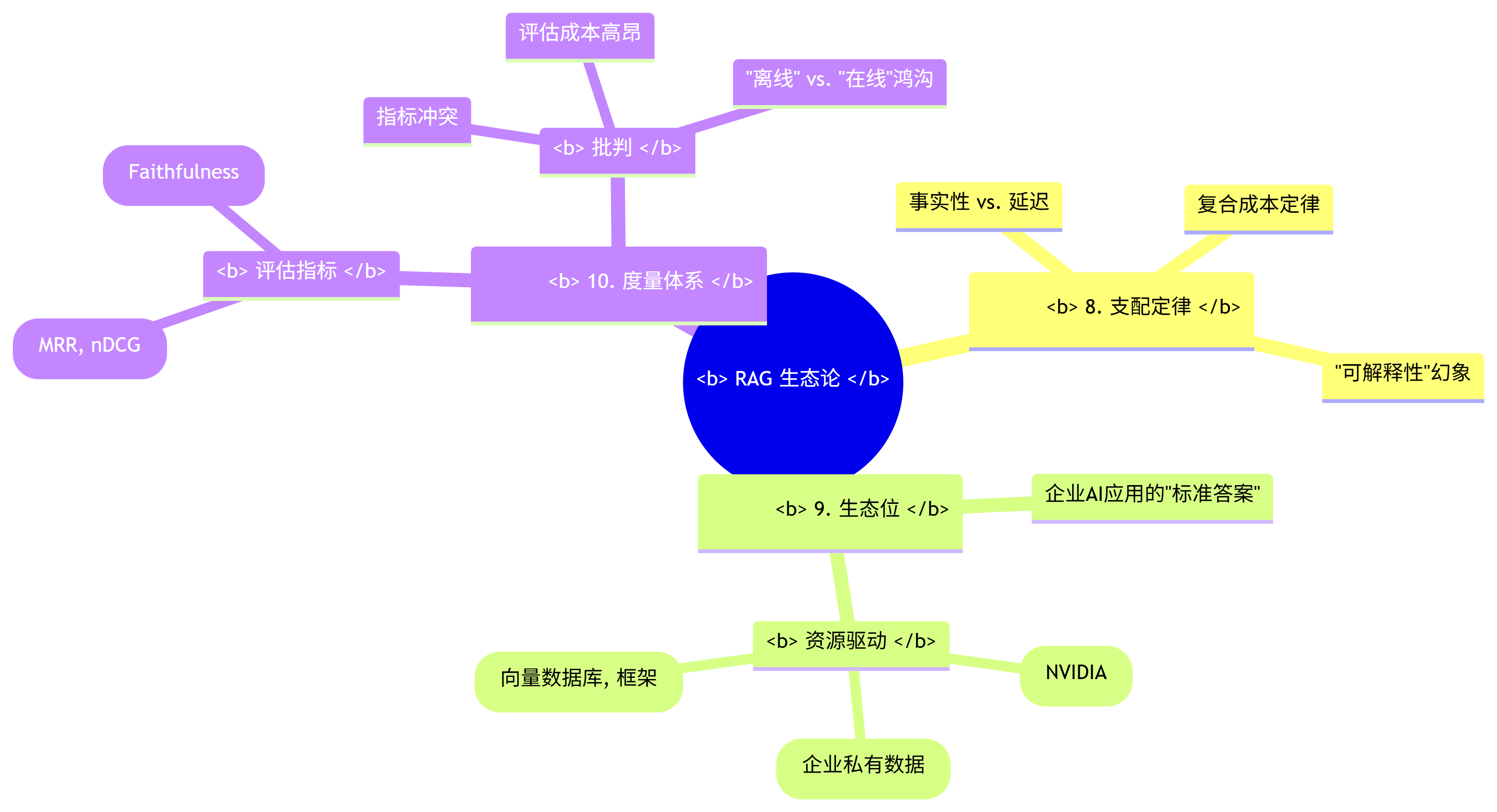
三、 生态论视角 (The Ecological Perspective): 环境与标尺
8. 支配定律与涌现特性 (Governing Laws & Emergent Properties):
- 事实性”与“延迟”的权衡定律: RAG系统的事实准确性(通过更复杂的检索、重排、多轮查询)与其响应延迟成正比。追求极致的准确性必然带来用户无法忍受的等待时间。
- 成本定律: RAG的运行成本是复合的,包括Embedding计算、向量数据库存储与查询、LLM生成。这使得其总拥有成本(TCO)远高于单纯的LLM调用。
- 涌现特性:“可解释性”的幻象: RAG通过提供引用来源,创造了一种“可解释”的表象。然而,这种可解释性是有限的。我们知道它参考了什么,但不知道它是如何“在内部”综合这些信息并最终生成答案的。它将“不可解释的生成”问题,部分转化为了“可追踪的引用”问题。
9. 生态位与资源动力学 (Ecosystem & Resource Dynamics):
- 生态位:企业级AI应用的“标准答案”: 在企业环境中,数据的私有性、实时性和准确性是刚需。RAG因其能使用私有知识库、保证数据新鲜且提供引用来源,已成为构建企业级AI知识库、智能客服等应用的事实标准(De Facto Standard)。
- 资源驱动:
- 算力: 对Embedding模型和LLM的巨大需求,继续巩固了NVIDIA等算力提供商的霸主地位。
- 数据: 高质量的、干净的、结构化的私有数据,成为了企业构建有效RAG应用的核心壁垒。所谓“数据飞轮”效应在此体现得淋漓尽致。
- 资本: 大量资本涌入向量数据库、AI开发框架(LangChain)和端到端RAG解决方案初创公司,形成了一个庞大的“RAG经济体”。
10. 度量体系及其批判 (Measurement Systems & Their Critiques):
- 评估基准:
- 检索端指标: 命中率(Hit Rate)、平均倒数排名(MRR)、归一化折扣累计收益(nDCG)。这些传统信息检索指标被用于评估Retriever的性能。
- 生成端指标: 忠实度(Faithfulness,答案是否忠于上下文)、答案相关性(Answer Relevancy)。这些需要更强的LLM(如GPT-4)作为“裁判”来进行打分。
- 端到端基准: RAGAs, ARES等框架试图提供一个更全面的、自动化的RAG管道评估方案。
- 对度量的批判:
- 指标的冲突: 优化检索端的MRR,不一定能提升生成端的Faithfulness。有时,一个语义稍远但包含关键信息的文档,比一个表面最相似的文档更有价值。
- 评估的成本: 使用LLM作为“裁判”来评估生成质量,本身就非常昂贵,且引入了“裁判”自身的偏见。
- 离线”与“在线”的鸿沟: 在静态数据集上评估得到的高分,并不能保证RAG系统在面对真实世界千奇百怪的用户问题时,依然能表现良好。
RAG 生态论思维导图
步骤二:解构 (Deconstruct) - 绘制系统关系图
【系统解构图:RAG及其生态系统】
1. 系统内核:范式革命 (The Core: A Paradigm Revolution)
- 根本问题: 如何在不重新训练一个庞大的LLM的情况下,安全、可控地扩展其知识边界,并约束其“自由创作”的倾向,使其回答基于可验证的事实。
- 解决方案: 提出外部知识源增强生成”(External Knowledge Source Augmentation)范式。其核心思想是将“知识存储”与“语言生成”这两个功能进行物理分离。LLM不再是唯一的知识来源,而退化为一个纯粹的、基于即时上下文的“语言合成器”。
- 内核机制:
- 工作原理: 检索先于生成 (Retrieval-before-Generation)。强制规定在生成答案之前,必须先执行一个从授权知识库中检索相关信息的“前置动作”。
- 交互本质: 从对LLM的“开放式提问”,转变为对LLM的“阅读理解式提问”。我们不再问“什么是RAG?”,而是问“请根据以下段落,解释什么是RAG:[从维基百科检索到的段落]…”。
2. 系统表现:双刃剑效应 (The Manifestation: A Double-Edged Sword)
- 正面表现 (涌现的能力):
- 事实的可控性: 通过将知识库限定在私有、可信的数据源内,极大地提升了答案的准确性和相关性。
- 知识的动态性: 无需重新训练LLM,只需更新外部知识库,即可实现信息的实时更新。
- 答案的可追溯性: 可以展示答案所依据的原文出处,为事实核查和纠错提供了可能,极大增强了系统的可信度。
- 负面表现 (固有的缺陷):
- 复杂性的诅咒 (Curse of Complexity): 整个RAG管道(Chunking, Embedding, Retrieval, Reranking, Generation)环节众多,每一个环节都是一个潜在的故障点和性能瓶颈。系统的整体性能取决于最弱的一环。
- 语义鸿沟 (Semantic Gap): 基于向量相似度的检索,本质上是一种“语义上的模式匹配”,它无法理解真正的“逻辑相关性”。这导致了经典的“检索回表面相似但实际无用的文档”的问题。
- 成本的叠加: RAG的每一步都消耗计算资源,使得其在延迟和成本上,远高于一次简单的LLM调用。
3. 系统演化:从“朴素”到“智能”的检索之路 (The Evolution: The Path from “Naive” to “Intelligent” Retrieval)
- RAG 1.0 (朴素RAG):
- 特征: 单次检索 -> 直接生成。
- 描述: 最基础的实现,效果脆弱,高度依赖于完美的Chunking和Embedding。
- RAG 2.0 (高级RAG / Advanced RAG):
- 特征: 引入了重排(Reranking)、查询改写(Query Transformation)、迭代检索(Iterative Retrieval)等技术。
- 描述: 试图通过更复杂的检索策略,来弥补“朴素RAG”的不足。整个系统的重心开始从“生成”端向“检索”端倾斜。
- RAG 3.0 (自适应RAG / Adaptive RAG):
- 特征: 让LLM自身参与到检索过程中,进行自我修正和判断。
- 描述: 如Self-RAG,LLM会判断是否需要进行检索、检索回的内容是否有用、答案是否需要引用。这标志着“检索”和“生成”两个阶段开始从“割裂”走向“融合”,是RAG范式的重要演进。
4. 系统生态:AI应用开发的“新石油”与“新管道” (The Ecosystem: The “New Oil” and “New Pipelines” of AI Application Development)
- 新石油(The New Oil): 高质量、干净的私有数据。拥有独特数据集的企业,可以通过RAG构建起强大的竞争壁垒。
- 新管道(The New Pipelines):
- 数据管道: 围绕着“数据 -> 向量”的转化,诞生了向量数据库和ETL(数据提取、转换、加载)工具。
- 应用管道: 围绕着“想法 -> RAG应用”的转化,诞生了LangChain、LlamaIndex等开发框架,它们成为了连接一切的“胶水层”。
- 新掘金者(The New Gold Miners):
- 基础设施提供商: NVIDIA (GPU), OpenAI (Embedding/LLM Models), Pinecone (Vector DB)。
- 工具链开发者: LangChain, LlamaIndex。
- 解决方案集成商: 无数基于这些工具,为特定行业提供端到端RAG解决方案的AI初创公司。
5. 系统标尺:一场关于“忠诚度”的度量战争 (The Measurement: A War of Measuring “Faithfulness”)
- 核心转变: AI的评估,从评估其“智商”(在MMLU等基准上的得分),转向评估其品德——即它对给定事实的忠诚度(Faithfulness)。
- 度量困境: “忠诚”是一个难以量化的概念。一个答案可能在字面上没有使用上下文,但其推理过程是基于上下文的,这算“忠诚”吗?一个答案如果补充了上下文没有但正确的背景知识,这算“不忠诚”吗?
- 标尺的演化: 从简单的、基于关键词匹配的指标,演化到使用更强大的LLM(如GPT-4)作为“裁判”来进行打分。这又带来了新的问题:我们如何相信“裁判”本身是公正和准确的?这构成了一个无尽的“评估套娃”。
RAG 系统解构图
步骤三: 提炼 (Hypothesize) - 发现RAG的“第一性原理
行动: 我们现在面对着RAG这个复杂而矛盾的系统。它既是事实的守护者,又是高级幻觉的制造者;它既简单直观,又充满了工程上的“玄学”。现在,我们将穿透这一切,找到那个唯一的、能统摄所有现象的根本驱动力。
-
第一次追问: RAG的本质是“给LLM一个外部数据库”吗?不,这只是描述了它的物理形态。一个数据库本身不会对LLM产生任何影响。关键在于我们如何“使用”这个数据库返回的结果。
-
第二次追问: 它的本质是“为LLM提供事实上下文”吗?这是我们通常的理解,但这个描述是站在人类的视角。从LLM这个“非人类”的系统来看,它根本不理解什么是“事实”,什么是“上下文”。它只理解一件事:一串输入的符号序列(Token Sequence)。那么,当我们把“事实上下文”塞进它的输入序列时,到底发生了什么?
-
第三次追问: 让我们回到LLM的绝对第一性原理:它是一个基于输入序列,来预测下一个最可能出现的词元的概率引擎。 它的整个“世界”就是这个概率分布。当我们把一段从外部检索来的、高度相关的文本(例如,关于“RAG之父是Lewis”的段落)插入到问题(“谁发明了RAG?”)前面时,我们实际上是在干一件非常“粗暴”的事情:我们用这段文本,为这个概率分布空间,施加了一个极其强大的、实时的“引力场”或“锚点。
“Lewis”这个词元,在这段上下文出现后,其在下一词元预测中的概率,会从一个极小的值,瞬间飙升,成为概率的顶峰。而“Yann LeCun”或“Hinton”等其他可能的名字,其概率则被急剧地压制了。 -
洞察闪现: RAG的成功,与“让LLM理解知识”毫无关系。它的全部魔法,都源于对LLM这个概率引擎的底层运行机制的精准利用与“操纵。它不“教”LLM任何东西,它只是在LLM即将做出选择的瞬间,用外部文本作为“锚点”,强行“锚定”了它下一秒的概率分布,将无限的可能性,收束到一个我们期望的、极度狭窄的范围内。它将一个开放的、关乎“真实性”的认知问题,成功地降维成了一个封闭的、关乎“相关性”的工程问题。我们不再需要保证LLM“知道”正确答案,我们只需要保证我们能“找到”包含正确答案的文本,并把它放到LLM的“眼前”即可。
核心假说(第一性原理)被提炼出来:
RAG的本质,并非一个“知识增强”系统,而是一个【概率分布的实时定向锚定系统 (A Real-time, Directional Anchoring System for Probability Distribution)】。它的唯一使命,是通过外部检索到的文本作为“锚点”,在生成每一个词元的瞬间,强行将LLM的输出概率分布收束到一个由该“锚点”所定义的高置信度“事实空间”内。
它建立了一套“检索-锚定-生成”的自动化流程,成功地将“生成一个真实答案”(一个开放的认知问题),降维为“找到一个相关锚点”(一个封闭的检索问题)。它最大的成功,在于它利用了LLM的“无意识模仿”本能,让一个对事实毫无概念的概率引擎,在正确的“锚点”引导下,表现得像一个严谨的、引经据典的学者。
1. 它完美解释了系统的“双刃剑效应”:
- 事实性与可追溯性: 当我们成功地“锚定”了正确的上下文时,LLM生成与该上下文一致的内容的概率被极大地提高了。这就表现为“事实性”。而那个被我们用来“锚定”的文本,自然就成为了答案的“出处”,实现了“可追溯性”。
- 新的幻觉与脆弱性: 这个模型完美地解释了RAG的核心缺陷。
- 检索失败 = 锚点错误: 如果检索系统给出了一个错误的“锚点”(如一个包含错误信息的文档),RAG不但不会纠正,反而会更忠实、更自信地基于这个错误的锚点生成答案。这是一种比普通幻觉更可怕的“高级幻觉”,因为它带有“引用来源”,更具欺骗性。
- 生成失败 = 锚定失效: 有时,即使锚点正确,但如果LLM自身的参数化知识(偏见)过于强大,或者Prompt的构造不当,它也可能“挣脱”锚点,自行生成内容。这就是“锚定失效”。
2. 它完美解释了系统的“演化路径”:
- 从朴素RAG到高级RAG: 整个“高级RAG”的发展史,就是一部“如何打造更精准、更强大的锚点”的工程史。
- 重排(Reranking): 是为了从一堆初步的锚点中,选出最“坚固”的那一个。
- 查询改写(Query Transformation): 是为了更好地“定位”到正确的锚点。
- 迭代检索(Iterative Retrieval): 是因为一个锚点不够,需要多个锚点组合起来才能完全“锚定”一个复杂问题的答案。
- 从割裂到融合(自适应RAG): 自适应RAG的出现,是因为我们发现,让LLM这个“概率引擎”自己来判断“锚点”的好坏,可能比任何外部规则都更有效。这标志着“锚定”过程本身,也开始被纳入LLM的概率计算中,是系统走向更智能的体现。
最终核心法则提炼
第一性原理: RAG的本质是一个概率分布的实时定向锚定系统。
这个“锚定”系统之所以能运转,依赖于以下三条不可动摇的核心法则,它们共同构成了它的“物理定律”。
核心法则一:【检索即锚定法则 (The Law of Retrieval as Anchoring)】
- 定义: 在RAG系统中,检索(Retrieval)的唯一目的,是为LLM的概率空间寻找并提供一个高置信度的“事实锚点(即相关文本)。检索的质量,不取决于其本身,而取决于其作为“锚点”引导后续生成过程的有效性。
- 阐述: 这是RAG系统的方向盘。它决定了整个系统的“锚点”从何而来。一个好的检索,是找到了一个能将LLM的生成概率强力引导向正确答案的文本,而不是找到了一个与问题表面上最相似的文本。这就解释了为什么有时语义相似度高的文档反而是“坏锚点”。
核心法则二:【上下文即约束法则 (The Law of Context as Constraint)】
- 定义: 被注入到提示词中的上下文(Context),其本质是对LLM生成下一个词元的概率分布施加的一个强约束。它通过提高与上下文一致的词元的出现概率,并压制不一致的词元,来强制性地收窄LLM的“创作空间”。
- 阐述: 这是RAG系统的缰绳。它将LLM这匹“野马”的活动范围,从无限的草原,限定在了一个由上下文构成的、狭小的“围栏”里。围栏越坚固、越清晰(上下文质量越高),马的行为就越可预测。这也解释了“大海捞针”问题:当围栏过大(上下文太长),马在里面依然有很大的“自由活动”空间,约束效果就会下降。
核心法则三:【生成即合成法则 (The Law of Generation as Synthesis)】
- 定义: RAG的最终生成(Generation)过程,是一个在外部“锚点”强约束下,对模型内部参数化知识进行选择性激活与合成的过程。最终的答案,是模型固有语言能力与外部事实约束之间的一种概率上的妥协。
- 阐述: 这是RAG系统的最终输出。它解释了为什么RAG的答案通常比纯LLM生成更“呆板”,但更准确。因为这不是一次“创作”,而是一次“在规定范围内的组装”。它也解释了生成失败的根源:当模型的“内部偏见”与“外部约束”发生冲突时,如果内部偏见的概率权重更高,模型就会“挣脱”约束,即“忽略上下文”。
步骤四 & 五: 重组与测试 (Recombine & Test) - 构建并压力测试“提词器演员”诊断模型
行动: 我们将以“概率锚定系统”为第一性原理,以其三大核心法则为支柱,重组出一个统一的诊断模型。我们称之为提词器演员”(The Teleprompter Actor)模型。
引入分析性隐喻:“健忘的演员与忠实的提词器
- LLM(演员): 一位才华横溢、能言善辩,但记忆力极差、酷爱即兴发挥的演员。他能说出任何风格的台词,但从不记得剧本。
- RAG(提词器系统): 一个由“图书管理员”(Retriever)和“显示屏”(Context Injector)组成的提词器系统。图书管理员负责根据导演的意图(Query)找到正确的剧本页码,显示屏则把台词展示给演员。
模型核心:
RAG驱动的问答,其本质并非AI在“回答问题”,而是一场演员(LLM)看着提词器(RAG)念台词的表演。这场表演的成功与否,完全取决于两个分离的环节:
- 提词器的准确性(基于“检索即锚定法则”): 图书管理员是否找到了正确的剧本?显示屏上的台词是否清晰、无误?
- 演员的忠诚度(基于“生成即合成法则”): 演员是否愿意照着台词念?还是他更倾向于即兴发挥?
这个模型揭示了一个根本事实:我们通过RAG获得的“事实性”,并非源自演员“认知”的提升,而是源自我们对“提词器”这一外部工具的有效控制。
行动: 现在,我们将用三个最具挑战性的前沿变量,来对“提词器演员”模型进行压力测试。
测试变量一:【多跳推理与复杂问题 (Multi-hop Reasoning & Complex Questions)】
- 场景: 提出一个需要结合多个知识点才能回答的问题,如:“《三体》的作者的大学本科专业,与《流浪地球》电影导演的大学本科专业相同吗?”
- 模型预测:
- “提词器演员”模型预测,标准RAG将在此类任务上惨败。因为这相当于要求“图书管理员”一次性找到两本完全不同的剧本(刘慈欣的履历、郭帆的履历),并将两段不相关的台词同时显示在提词器上,然后要求演员自己进行比较和推理。
- 失败模式: 朴素的图书管理员(标准检索器)一次只能根据一个意图(整个问题的向量)去检索,它很可能会检索回一篇关于《三体》或《流浪地球》的综述,而不太可能同时精准命中两位名人的教育背景。提词器从一开始就给错了剧本。
- 测试结论: 模型有效。它精准地指出了标准RAG的“单线程”缺陷。它预示着,要解决多跳问题,必须升级“提词器”系统本身,例如,让它拥有一个能进行“多轮查找”或“图谱遍历”能力的“智能图书管理员”(如图谱RAG、迭代检索)。
测试变量二:【噪声、冲突与海量文档处理 (Handling Noisy, Contradictory, and Massive Documents)】
- 场景: 知识库中包含了大量与问题无关的“噪声”文档,或者检索回的多个文档片段在关键事实上相互“冲突”(如一个说“A生于1980年”,另一个说“A生于1982年”)。
- 模型预测:
- 噪声场景: 模型预测,如果提词器上充满了大量无关的背景台词(噪声),演员(LLM)的注意力会被分散,他可能会随机地念出其中一句无关紧要的话,或者干脆放弃看提词器,开始自己的即兴发挥。这就是“大海捞针”和“中间忽略”问题的本质。
- 冲突场景: 模型预测,当提词器上同时显示两句冲突的台词时,演员的行为将是不可预测的。他可能会:1) 选择其一(通常是他根据自己的“偏见”更喜欢的那句);2) 胡乱拼接(生成“A生于1980年到1982年之间”这种模糊的答案);3) 感到困惑并拒绝回答。
- 测试结论: 模型有效。它生动地解释了RAG在面对不完美知识库时的脆弱性。它指出,提升RAG鲁棒性的关键,在于加强“提词器”的“编辑能力,例如,在显示台词前,先进行一次“预审”和“筛选”(Reranking),或者在发现冲突时,标记出来让演员自己选择。
测试变量三:【结构化数据生成(如代码、JSON) (Structured Data Generation)】
- 场景: 要求LLM根据一个数据库的Schema描述,生成一段符合要求的SQL查询代码或一个JSON对象。RAG被用来提供相关的Schema信息或代码范例。
- 模型预测:
- “提词器演员”模型预测,这将是RAG的一个棘手领域。因为这相当于在提词器上显示的不是自然的“台词”,而是一段严谨的、对格式要求极高的“乐谱”或“化学方程式”。
- 挑战“生成即合成”法则: 演员虽然能“照着念”出乐谱上的音符,但他并不真正“理解”乐理。他可能会在合成过程中,犯一些语法上正确但逻辑上致命的错误(如在SQL中用错了JOIN的条件,或者生成的JSON缺少了一个逗号)。因为他的“合成”是基于语言模式的,而非结构化逻辑的。
- 挑战“检索即锚定”法则: 如何“切分”和“检索”一个巨大的数据库Schema或代码库,本身就是一个巨大的挑战。简单的文本切分会彻底破坏其结构,导致提词器上的“乐谱”本身就是破碎和错误的。
- 测试结论: 模型有效。它揭示了RAG在从非结构化文本走向结构化数据应用时的根本困难。它预示着,针对结构化数据的RAG,其核心不在于LLM,而在于构建一个“理解结构”的、全新的“检索器,例如,能够将自然语言问题直接翻译为对Schema的图查询,再将结果作为“上下文”提供给LLM。
步骤六: 迭代 (Iterate) - 对目标的未来进行推演
核心任务: 基于已验证的“提词器演员”诊断模型及其三大核心法则,对“RAG”的未来演化进行逻辑推演。
【迭代推演:RAG的“义体”化,及其最终的“消亡”】
我们的诊断模型将RAG描绘成一个外部的“提词器”,一个辅助“健忘演员”的工具。它的演化,必然围绕着两条主线展开:让“提词器”变得更智能,以及让“演员”本身记性更好。 而这两条路线的终点,都指向了同一个结局。
![[Pasted image 20250914150514.png]]
迭代轨迹一:提词器的智能化——“主动义体”的诞生 (The Intelligent Teleprompter: Birth of the “Active Prosthesis”)
- 驱动力: 对检索即锚定法则的“被动性与不准确性”反思。
- 推演: 当前的“提词器”是被动的。它只是机械地展示“图书管理员”找到的东西。一个更高级的系统,应该能主动地、智能地辅助演员。
- 【猜测内容:】 RAG的“检索”部分将不再是一个简单的“搜索-返回”过程,而会演化为一个与LLM深度融合的、多轮的、自我修正的“信息探索循环。
- 主动查询生成: LLM不再被动接收上下文,而是主动生成它需要的查询(“我需要知道A的出生年份”),甚至规划一个查询序列(“先查A的生平,再查B的生平”)。
- 反馈驱动的重试: LLM能够评估检索回的内容,如果发现不相关或不足,它会生成一个新的、更精确的查询,进行“追问式检索”。
- 从“检索”到“研究”: 整个过程将从一次性的“查找”,演变为一个自动化的“研究助理”(AI Research Assistant)。这个“助理”会为了回答一个问题,主动地去阅读多篇文档、比较信息、形成摘要,最后将这个“研究报告”作为最终的上下文,交给生成器。
RAG将从一个“外部存储器”,演化为一个“主动的记忆辅助系统”,一个与大脑无缝协作的“智能义体”。
迭代轨迹二:演员的“记忆觉醒”——内置世界模型的崛起 (The Actor’s “Memory Awakening”: Rise of the Internal World Model)
- 驱动力: 对生成即合成法则中“演员对提词器的盲从或忽略”的反思。
- 推演: 一个伟大的演员,终究不能永远依赖提词器。他需要将剧本“内化”于心。同样,一个更高级的LLM,不能永远依赖外部上下文。
- 【猜测内容:】 这条路径指向了RAG的最终替代方案。随着模型规模的爆炸式增长(如百万级上下文窗口、万亿级参数),以及训练数据的极度丰富和高质量,新一代的LLM将能够把海量的、结构化的知识,更有效地“编码”进其自身的参数中,形成一个强大的内置世界模型。
- 事实的参数化: 模型不再需要外部检索来回答“法国的首都是哪里”,因为这个事实已经被牢固地、高概率地存储在其参数中了。
- 从“需要查”到“直接知道”: 对于绝大多数的通用知识和领域知识,LLM将能够直接从其内部记忆中提取,而无需启动昂贵的RAG流程。
- RAG的“退化”: RAG的应用场景将被急剧压缩,退守到它最不可替代的几个领域:① 对绝对实时性要求极高的信息(如新闻、股价);② 绝对私有的、从未出现在互联网上的企业内部数据;③ 需要法律上“白纸黑字”引用来源的场景。
LLM将从一个“健忘的演员”,进化为一个“博闻强记的学者”。他不再需要提词器,因为他已经背下了整个图书馆。
迭代轨迹三:人与系统的“角色反转”——RAG的最终“消亡” (The Role Reversal: The Eventual “Death” of RAG)
- 驱动力: 综合以上两条轨迹,我们看到了一个明确的终局。
- 推演: RAG的本质,是人类工程师试图用一套“外部规则”去弥补LLM“内部能力”不足的伟大尝试。它是一个工程上的妥协。而技术演化的历史一再证明,当核心引擎的能力实现代际飞跃时,围绕旧引擎构建的复杂“外挂”和“补丁”,都将不可避免地被淘汰。
- 【猜测内容: RAG作为一个主流技术范式,其生命周期是有限的。 它的历史使命,就是充当从“无知但流利”的LLM,到“博学且真实”的下一代基础模型之间,那座至关重要的“过渡桥梁”。
- 短期(1-3年): “提词器智能化”是主流。高级RAG、自适应RAG将大行其道,RAG的工程复杂性会达到顶峰。
- 中期(3-7年): “演员记忆觉醒”开始。随着GPT-6、GPT-7等级的模型出现,其内置知识的广度和可靠性将大幅提升,越来越多的应用会发现“裸模型”的效果已经足够好,从而放弃复杂的RAG管道。
- 长期(7年以上): RAG“退化”为一种小众的、用于特定场景的“插件”,而非AI应用开发的默认选项。我们今天所熟知的、由“检索-生成”构成的RAG范式,将被一个更强大、更一体化的基础模型所“吸收”和“内化”。
RAG的最终成功,将以其自身的“功成身退”来书写。它最伟大的贡献,是为我们赢得时间,直到我们不再需要它的那一天。
结论性摘要
RAG(检索增强生成),是我们这个时代为“概率之神”LLM所发明的、最成功的“提词器”。它并非是赋予神祇以“智慧”,而是通过一种巧妙的工程设计——用外部检索到的文本作为“锚点”,来实时地、强行地“约束”神的概率输出——从而让这位热爱即兴发挥的“演员”,能够忠实地念出我们为它准备的“剧本”。
这一“概率锚定”的第一性原理,完美地解释了RAG为何能成为事实的守护者,也解释了它为何在“锚点”错误时,会沦为高级幻觉的帮凶。
然而,对RAG未来的迭代推演,却指向了一个不可避免的结论:RAG的宿命,是一场华丽的“自我消亡”。
它像一副性能强大的“外骨骼”,帮助一个尚不成熟的“大脑”完成行走。它的演化,一方面是让这副“外骨骼”变得更智能、更主动;另一方面,更根本的,是“大脑”自身的发育,使其肌肉日益强壮,最终不再需要任何外部辅助。
RAG的时代,是AI发展史上一个辉煌的、充满工程智慧的“义体时代”。它的历史使命,是在一个真正拥有内置记忆和世界模型的“通用智能”诞生之前,充当其“外置的记忆宫殿”,为我们连接现实与概率,弥合事实与虚构。而当那一天到来时,RAG这副伟大的“拐杖”,将被光荣地放入历史的博物馆。它最大的成功,将是它最终变得不再被需要。
如果你觉得这个系列对你有启发,别忘了点赞、收藏、关注,我们下篇见!
附实验室篇:
# # AI智能体(AI Agent)——从“缸中之脑”到“尘世之手”
备注丢一个辉光写的小工具提示词
# #AI专属“RAG知识库优化大师”
附录:关键文献引用 (Key Paper References)
-
RAG:范式定义
- 标题: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 1
- 作者: Patrick Lewis, Ethan Perez, et al.
- 机构/年份: Facebook AI Research, 2020
- 核心贡献: 首次正式提出并定义了RAG框架,通过端到端地结合一个参数化的检索器和一个生成器,证明了其在知识密集型任务上的卓越性能,是整个领域的开山之作。
-
DPR:现代检索的基石
- 标题: Dense Passage Retrieval for Open-Domain Question Answering 2
- 作者: Vladimir Karpukhin, Barlas Oguz, et al.
- 机构/年份: Facebook AI, 2020
- 核心贡献: 确立了使用稠密向量(Dense Vector)进行文档检索的范式,其提出的双编码器架构,成为了后续几乎所有基于向量的检索系统的技术基础。
-
高级RAG的探索
- 标题: Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection 3
- 作者: Akari Asai, Zeqiu Wu, et al.
- 机构/年份: University of Washington & Google DeepMind, 2023
- 核心贡献: 提出了“自适应RAG”的概念,通过训练LLM生成特殊的“反思词元”,使其能自主决定是否需要检索、评估检索内容的相关性,并对自己的生成结果进行批判。这是将“检索”与“生成”从割裂推向融合的关键一步。
-
RAG的评估
- 标题: RAGAs: Automated Evaluation of Retrieval Augmented Generation 4
- 作者: Shahul Es, Jithin James, et al.
- 机构/年份: Exploding Gradients, Amnic, et al., 2023
- 核心贡献: 针对评估RAG管道的复杂性,提出了一个自动化的、无需依赖人工标注的评估框架。它通过定义“忠实度(Faithfulness)”和“答案相关性(Answer Relevancy)”等关键指标,并利用LLM自身进行打分,极大地推动了RAG系统评估的标准化和效率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 17
17 0
0- 0



 已为社区贡献123条内容
已为社区贡献123条内容

所有评论(0)