什么是机器学习
机器学习、人工智能、深度学习是什么关系?
1956 年提出 AI 概念,短短3年后(1959) Arthur Samuel 就提出了机器学习的概念:
Field of study that gives computers the ability to learn without being explicitly programmed. 机器学习研究和构建的是一种特殊算法(而非某一个特定的算法),能够让计算机自己在数据中学习从而进行预测。
所以,机器学习不是某种具体的算法,而是很多算法的统称。
机器学习包含了很多种不同的算法,深度学习就是其中之一,其他方法包括决策树,聚类,贝叶斯等。
深度学习的灵感来自大脑的结构和功能,即许多神经元的互连。人工神经网络(ANN)是模拟大脑生物结构的算法。
不管是机器学习还是深度学习,都属于人工智能(AI)的范畴。所以人工智能、机器学习、深度学习可以用下面的图来表示:
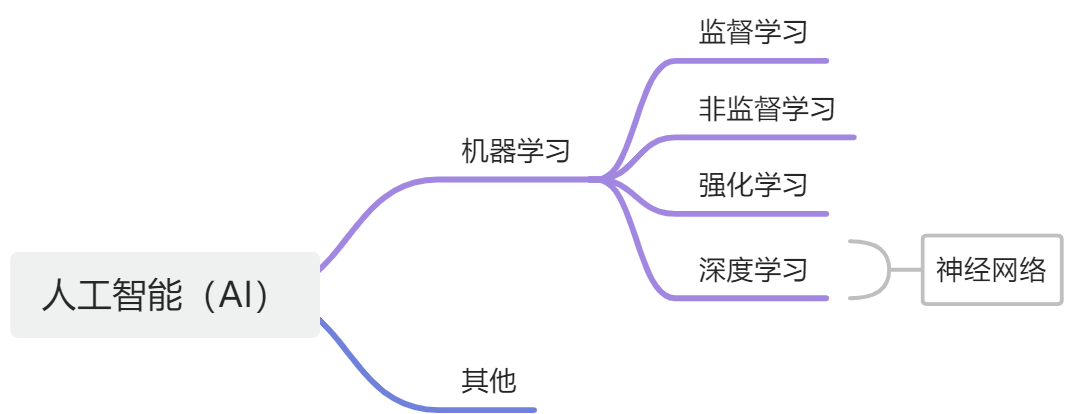
什么是机器学习?
机器学习的基本思路
- 把现实生活中的问题抽象成数学模型,并且很清楚模型中不同参数的作用
- 利用数学方法对这个数学模型进行求解,从而解决现实生活中的问题
- 评估这个数学模型,是否真正的解决了现实生活中的问题,解决的如何?
无论使用什么算法,使用什么样的数据,最根本的思路都逃不出上面的3步!

当我们理解了这个基本思路,我们就能发现:
不是所有问题都可以转换成数学问题的。那些没有办法转换的现实问题 AI 就没有办法解决。同时最难的部分也就是把现实问题转换为数学问题这一步。
机器学习的原理
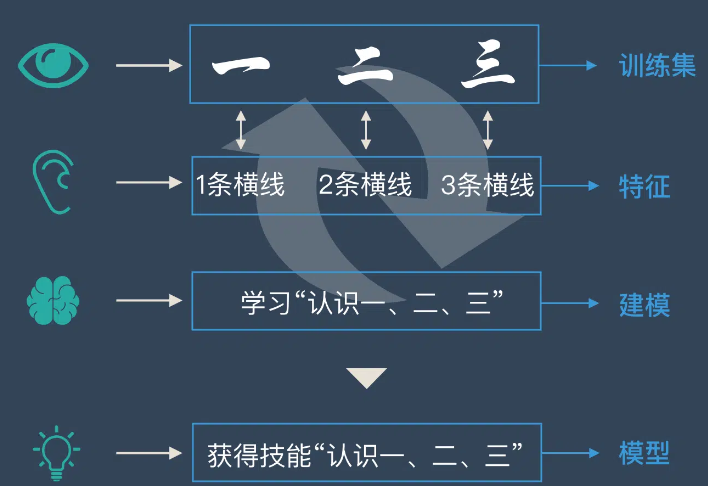
以监督学习为例,给大家讲解一下机器学习的实现原理。
假如我们正在教小朋友识字(一、二、三)。我们首先会拿出3张卡片,然后便让小朋友看卡片,一边说“一条横线的是一、两条横线的是二、三条横线的是三”。
不断重复上面的过程,小朋友的大脑就在不停的学习。
当重复的次数足够多时,小朋友就学会了一个新技能——认识汉字:一、二、三。
监督学习、非监督学习、强化学习
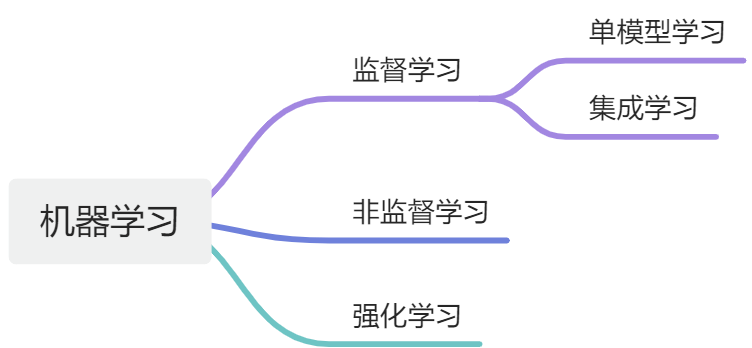
机器学习根据训练方法大致可以分为3大类:
- 监督学习
- 非监督学习
- 强化学习
除此之外,大家可能还听过“半监督学习”之类的说法,但是那些都是基于上面3类的变种,本质没有改变。
监督学习
监督学习是指我们给算法一个数据集,并且给定正确答案。机器通过数据来学习正确答案的计算方法。
我们准备了一大堆猫和狗的照片,我们想让机器学会如何识别猫和狗。当我们使用监督学习的时候,我们需要给这些照片打上标签。
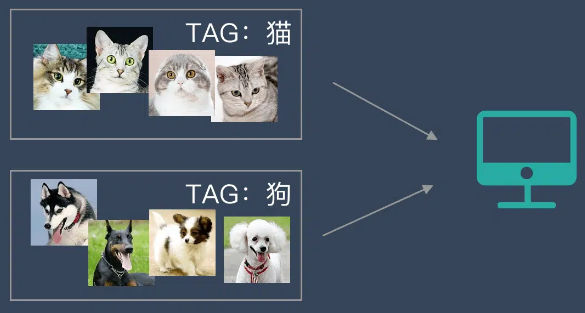
我们给照片打的标签就是“正确答案”,机器通过大量学习,就可以学会在新照片中认出猫和狗。

这种通过大量人工打标签来帮助机器学习的方式就是监督学习。这种学习方式效果非常好,但是成本也非常高。
集成学习
监督学习有很多种算法,当你使用一份训练数据集和某一种算法进行训练,得到的结果就是一个模型,所以我们也常会直接把算法和模型等价起来,例如线性回归算法就是线性回归模型。
多种多样的算法模型都是科学家们为了解决各式各样的问题而提出的,有些问题可能一个模型就能解决,但有些情况下,一个模型可能不够稳定,决策的偏差较大,怎么办呢?
于是科学家们想出了一种办法,那就是用一份训练数据集,一次性训练多个模型,然后让这些模型一起参与同一个问题的决策,这种方法被称为“集成学习”。
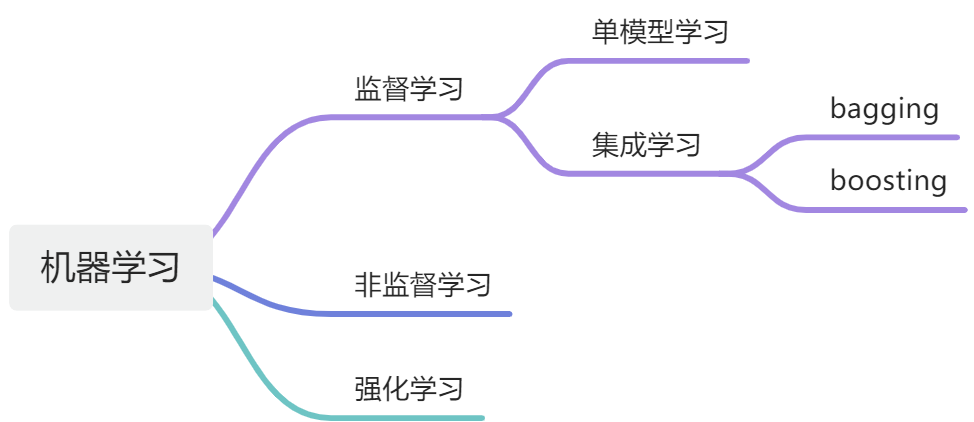
集成学习有两种学习方法:并行集成(bagging)和迭代集成(boosting)
为什么说是“方法”而不是“算法”,这是因为集成学习其实并没有创造新的算法,而是将已有的算法组合起来,实现更有力的功能。
- 并行集成(bagging)
- 迭代集成(boosting)
非监督学习
非监督学习中,给定的数据集没有“正确答案”,所有的数据都是一样的。无监督学习的任务是从给定的数据集中,挖掘出潜在的结构。
举个栗子:
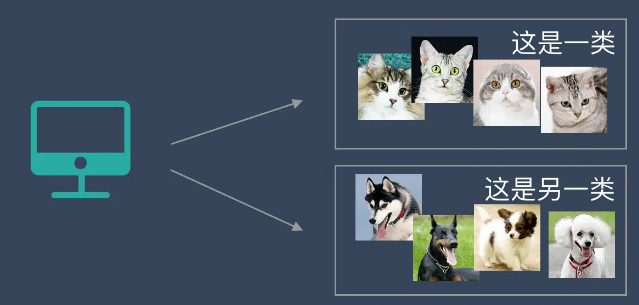
我们把一堆猫和狗的照片给机器,不给这些照片打任何标签,但是我们希望机器能够将这些照片分分类。

通过学习,机器会把这些照片分为2类,一类都是猫的照片,一类都是狗的照片。虽然跟上面的监督学习看上去结果差不多,但是有着本质的差别:
非监督学习中,虽然照片分为了猫和狗,但是机器并不知道哪个是猫,哪个是狗。对于机器来说,相当于分成了 A、B 两类。
强化学习
强化学习更接近生物学习的本质,因此有望获得更高的智能。它关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。通过强化学习,一个智能体应该知道在什么状态下应该采取什么行为。
定义: 强化学习是让一个智能体(agent)在环境中通过尝试和错误来学习行为策略。智能体通过与环境进行交互,根据奖励信号来调整其行为策略,以达到最大化累积奖励的目标。
在强化学习中,智能体不需要明确地告诉如何执行任务,而是通过尝试和错误的方式进行学习。当智能体在环境中采取某个动作时,环境会返回一个奖励信号,表示该动作的好坏程度。智能体的目标是通过与环境交互,学习到一种最优策略,使其在长期累积的奖励最大化。
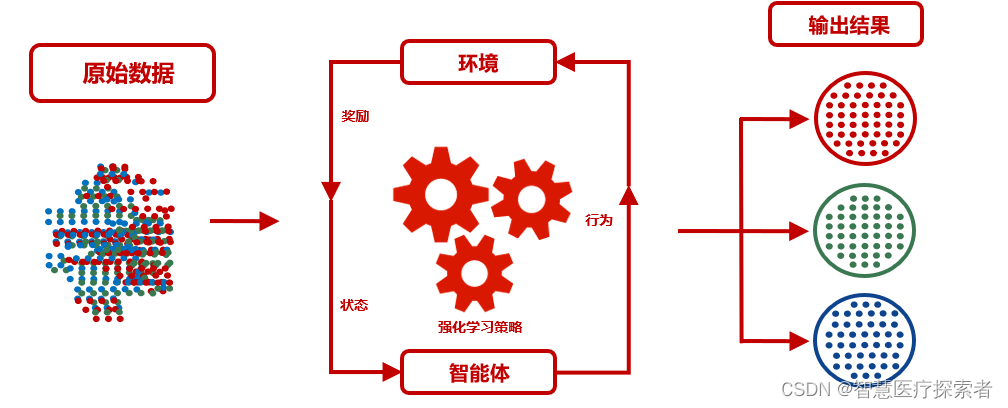
强化学习的过程可以描述为智能体与环境之间的不断交互过程:
- 智能体观察当前环境状态(state)。
- 基于当前状态,智能体选择一个动作(action)。
- 环境根据智能体的动作转换到新的状态,并返回一个奖励信号(reward)。
- 智能体根据奖励信号更新其策略,以便在将来的决策中获得更好的奖励。
- 重复以上步骤,直到智能体学习到一个使其获得最大累积奖励的策略。
举例的话,最典型的场景就是打游戏。
2019年1月25日,AlphaStar(Google 研发的人工智能程序,采用了强化学习的训练方式) 完虐星际争霸的职业选手职业选手“TLO”和“MANA”。
非监督学习的任务
无监督学习的特点是在训练数据中没有标签或目标值。无监督学习的目标是从数据中发现隐藏的结构和模式,而不是预测特定的标签或目标。无监督学习的主要类别包括以下几种:
聚类(Clustering):聚类是将数据样本分成相似的组别或簇的过程。它通过计算样本之间的相似性度量来将相似的样本聚集在一起。聚类是无监督学习中最常见的任务之一,常用于数据分析、市场细分、图像分割等。
降维(Dimensionality Reduction):降维是将高维数据转换为低维表示的过程,同时尽可能地保留数据的特征。降维技术可以减少数据的复杂性、去除冗余信息,并可用于可视化数据、特征提取等。常见的降维方法有主成分分析(PCA)和t-SNE等。
关联规则挖掘(Association Rule Mining):关联规则挖掘用于发现数据集中项之间的关联和频繁项集。这些规则描述了数据集中不同项之间的关联性,通常在市场篮子分析、购物推荐等方面应用广泛。
异常检测(Anomaly Detection):异常检测用于识别与大多数样本不同的罕见或异常数据点。它在检测异常事件、欺诈检测、故障检测等领域有着重要的应用。
无监督学习在数据挖掘、模式识别、特征学习等领域中发挥着重要作用。通过发现数据中的结构和模式,无监督学习有助于我们更好地理解数据,从中提取有用的信息,并为其他任务提供有益的预处理步骤。
机器学习常见算法
机器学习里所说的“算法”与程序员所说的“数据结构与算法分析”里的“算法”略有区别。前者更关注结果数据的召回率、精确度、准确性等方面,后者更关注执行过程的时间复杂度、空间复杂度等方面
监督学习常见算法
监督学习算法种类众多,有着极其广泛的应用,下面是一些常见的监督学习算法:
- 支持向量机(Support Vector Machine,SVM):SVM是一种用于二分类和多分类任务的强大算法。它通过找到一个最优的超平面来将不同类别的数据分隔开。SVM在高维空间中表现良好,并且可以应用于线性和非线性分类问题。
- 决策树(Decision Trees):决策树是一种基于树结构的分类和回归算法。它通过在特征上进行递归的二分决策来进行分类或预测。决策树易于理解和解释,并且对于数据的处理具有良好的适应性。
- 逻辑回归(Logistic Regression):逻辑回归是一种广泛应用于二分类问题的线性模型。尽管名字中带有"回归",但它主要用于分类任务。逻辑回归输出预测的概率,并使用逻辑函数将连续输出映射到[0, 1]的范围内。
- K近邻算法(K-Nearest Neighbors,KNN):KNN是一种基于实例的学习方法。它根据距离度量来对新样本进行分类或回归预测。KNN使用最接近的K个训练样本的标签来决定新样本的类别。
非监督学习常见算法
无监督学习算法在不同的问题和数据集上都有广泛的应用。它们帮助我们从未标记的数据中发现有用的结构和模式,并在数据处理、可视化、聚类、降维等任务中发挥着重要的作用。以下是一些常见的无监督学习算法:
- K均值聚类(K-Means Clustering):K均值聚类是一种常用的聚类算法,它将数据样本分成K个簇,使得每个样本与所属簇中心的距离最小化。
- 主成分分析(Principal Component Analysis,PCA):PCA是一种常用的降维算法,它通过线性变换将高维数据投影到低维空间,以保留最重要的特征。
- 关联规则挖掘(Association Rule Mining):关联规则挖掘是一种发现数据集中项之间关联性的方法,它常用于市场篮子分析、购物推荐等领域。
- 异常检测(Anomaly Detection):异常检测算法用于识别与大多数样本不同的罕见或异常数据点。常见的方法包括基于统计的方法、基于聚类的方法和基于生成模型的方法等。
强化学习常见算法
强化学习算法在处理不同类型的任务和问题时表现出色,并在自主决策和学习的领域中发挥着重要作用。它们通常用于解决自动驾驶、机器人控制、游戏玩法和其他需要决策和学习的任务。以下是一些常见的强化学习算法:
- Q-Learning:Q-Learning是一种基于值的强化学习算法。它通过学习一个值函数(Q函数)来表示在给定状态下采取某个动作的累积奖励。Q-Learning使用贝尔曼方程更新Q值,并使用贪心策略来选择动作。
- SARSA:SARSA是另一种基于值的强化学习算法。它与Q-Learning类似,但不同之处在于它在学习和决策阶段都使用当前策略的动作来更新Q值。
- DQN(Deep Q Network):DQN是一种深度强化学习算法,结合了深度神经网络和Q-Learning。它使用深度神经网络来近似Q函数,通过经验回放和目标网络来稳定训练。
- A3C(Asynchronous Advantage Actor-Critic):A3C是一种基于策略的强化学习算法,它结合了Actor-Critic方法和异步训练。A3C使用多个智能体并行地训练,以提高样本效率。
- PPO(Proximal Policy Optimization):PPO是一种基于策略的强化学习算法,它通过限制更新幅度来稳定训练。PPO在深度强化学习中表现出色,并被广泛应用于各种任务。
- TRPO(Trust Region Policy Optimization):TRPO是另一种基于策略的强化学习算法,它使用限制步长的方法来保证更新策略时不会使性能变差。
机器学习的应用场景
监督学习的应用场景
监督学习是最常见的机器学习方法之一,在各个领域都有广泛的应用,它的成功在很大程度上得益于其能够从带有标签的数据中学习,并对未见过的数据进行预测和泛化。
- 图像识别:监督学习在图像识别任务中非常常见。例如,将图像分类为不同的物体、场景或动作,或者进行目标检测,找出图像中特定对象的位置。
- 自然语言处理:在自然语言处理任务中,监督学习用于文本分类、情感分析、机器翻译、命名实体识别等。
- 语音识别:监督学习在语音识别领域被广泛应用,例如将语音转换为文本、说话者识别等。
- 医学诊断:在医学领域,监督学习可以用于疾病诊断、影像分析、药物发现等。
非监督学习的应用场景
无监督学习在数据挖掘、模式识别、特征学习等应用场景发挥着重要作用。通过无监督学习,我们可以从未标记的数据中获得有用的信息和洞察力,为其他任务提供有益的预处理步骤,并且有助于更好地理解和利用数据。:
- 聚类与分组:无监督学习中的聚类算法可以帮助将数据样本分成相似的组别或簇,例如在市场细分中将顾客分成不同的群体、在图像分割中将图像区域分割成不同的物体等。
- 特征学习与降维:无监督学习的降维算法如PCA和t-SNE可以用于特征学习和可视化高维数据,例如在图像、音频和自然语言处理中,以及用于数据压缩和可视化。
- 异常检测:无监督学习中的异常检测算法可用于发现与大多数数据样本不同的罕见或异常数据点。这在欺诈检测、故障检测和异常事件监测等场景中具有重要应用。
- 关联规则挖掘:无监督学习的关联规则挖掘算法可用于发现数据集中项之间的关联性,常应用于市场篮子分析、购物推荐等领域。
强化学习的应用场景
强化学习在许多实际应用场景中具有广泛的应用,尤其是那些需要自主决策和学习的任务。强化学习能够使智能体从与环境的交互中学习,并根据学到的知识做出适当的决策,以达到预定的目标或最大化累积奖励。由于强化学习的自主学习和决策特性,它在许多自主系统和智能系统中都有重要的应用潜力。以下是一些强化学习的应用场景:
- 自动驾驶:强化学习可以应用于自动驾驶领域,使车辆能够根据环境和交通状况做出决策,例如规划路径、避免障碍物和遵守交通规则。
- 机器人控制:强化学习可以帮助机器人在未知环境中进行自主探索和学习,以完成复杂的任务,例如导航、抓取物体和人机交互。
- 游戏:强化学习在游戏玩法中有广泛的应用。例如,使用强化学习训练智能体来玩电子游戏、围棋、扑克等,使其能够与人类玩家媲美甚至超越。
- 医疗治疗:强化学习可以在医疗领域中应用于个性化治疗和药物治疗决策,根据患者的情况和病情做出合适的治疗计划。
- 语音识别和自然语言处理:强化学习可以应用于语音识别和自然语言处理任务,使智能体能够更好地理解和生成自然语言。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 80
80 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)