AutoDL配置以及部署大模型
本文介绍了在AutoDL算力平台上部署AI模型的完整流程:1)租用实例时选择无卡模式降低成本;2)通过VSCode远程连接服务器,使用SSH插件完成配置;3)提供两种模型下载方式(GitLFS和ModelScopeSDK),详细说明GitLFS的安装和模型下载步骤;4)部署运行阶段,指导安装vllm并启动服务,强调需指定模型路径和名称参数。整个过程覆盖从实例创建到模型服务的全链路操作。
1、AutoDL服务租用
在算力市场选择需要使用的配置,进行租用
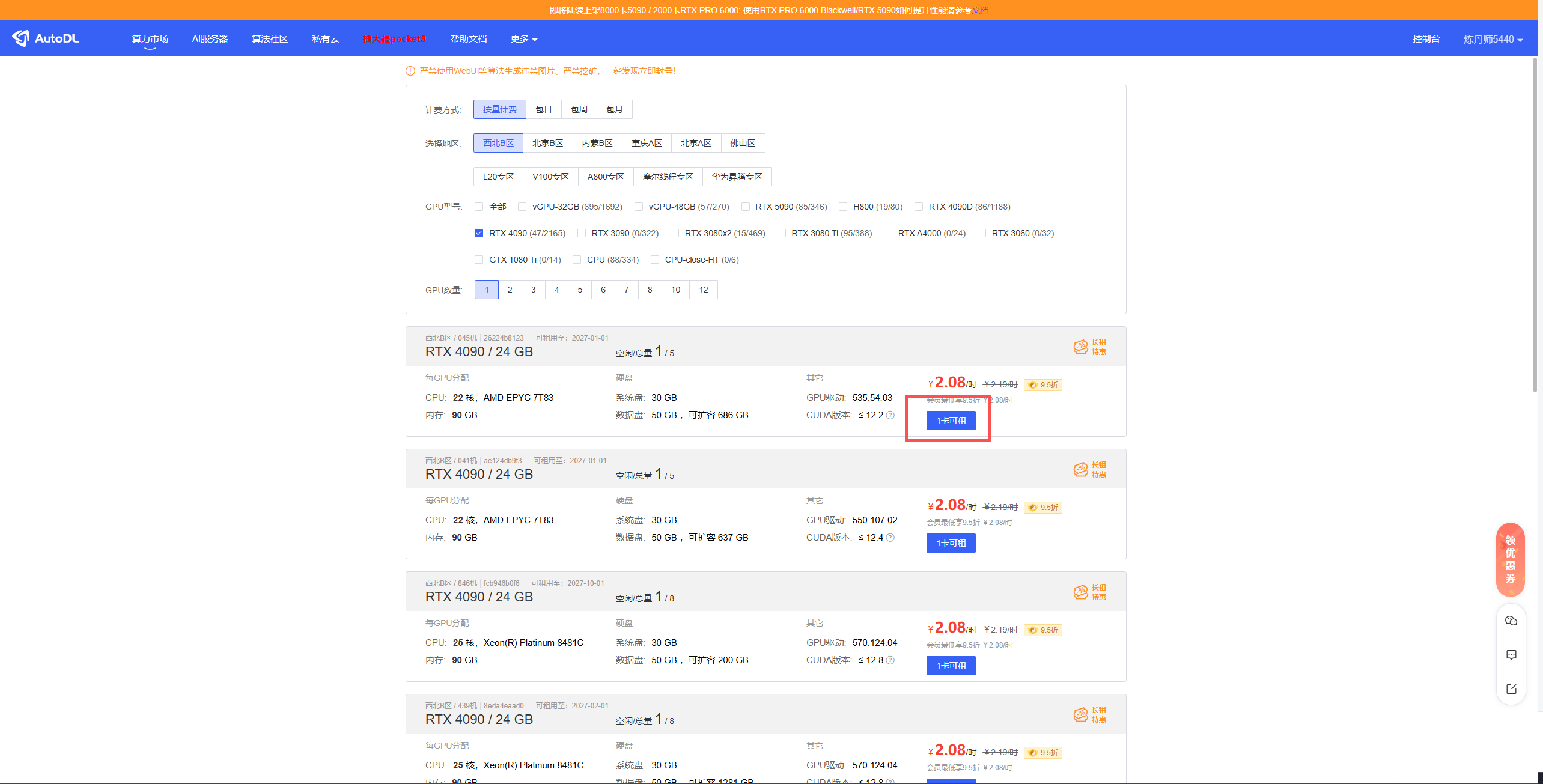
选择需要的环境后,点击创建并开机即可
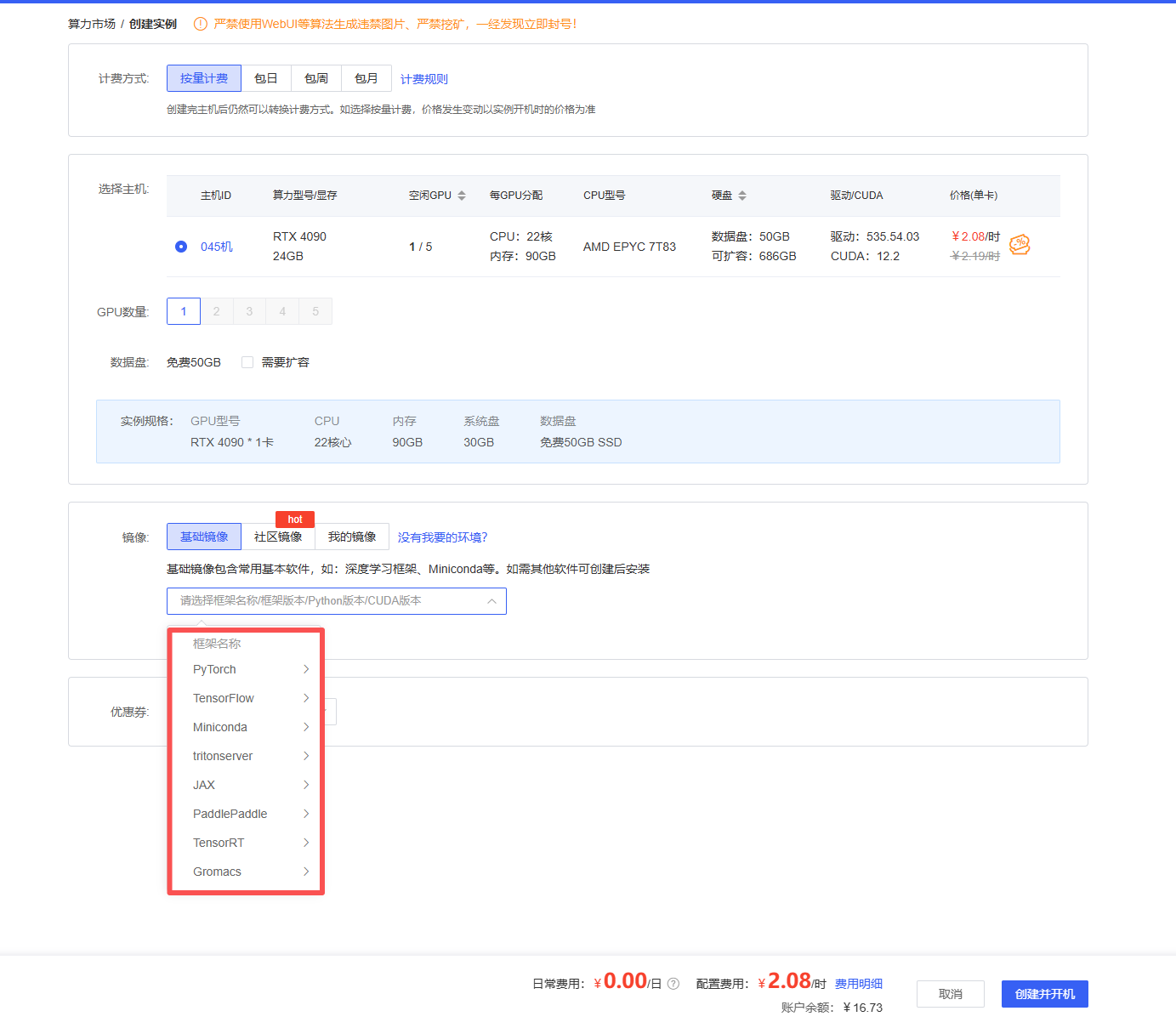
这样实例就创建好了

2、基础配置
实例创建完成后,需要进行一些基础配置
使用VSCode进行远程连接
首先点击更多选择无卡模式开机,实例在有卡模式下开机运行,费用是正常的(比如我选的服务,4090D显卡,一小时收费1.88),但是在无卡模式下开机,费用就很低。我们进行配置,不需要使用显卡,选择无卡模式即可
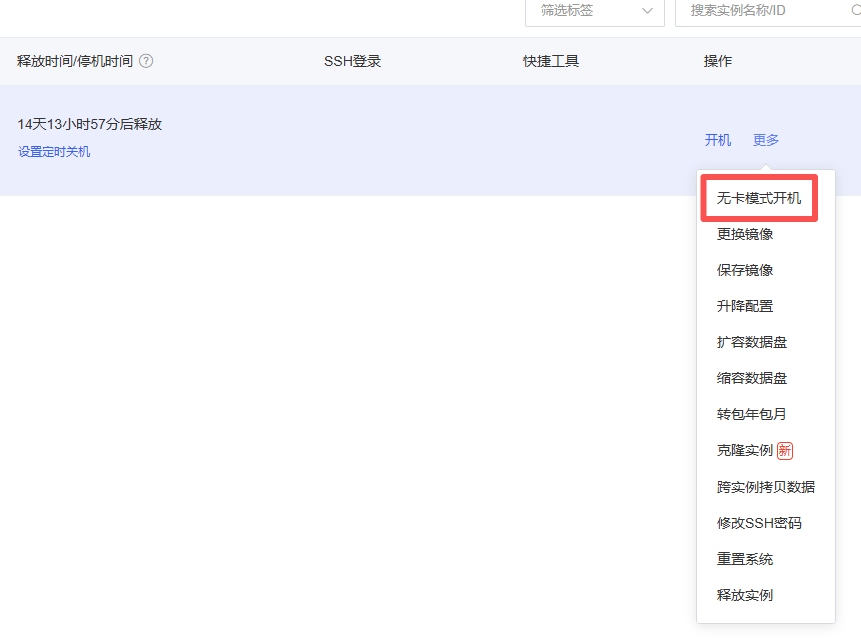
无卡模式下,收费如下图
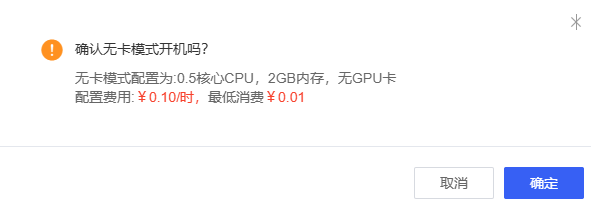
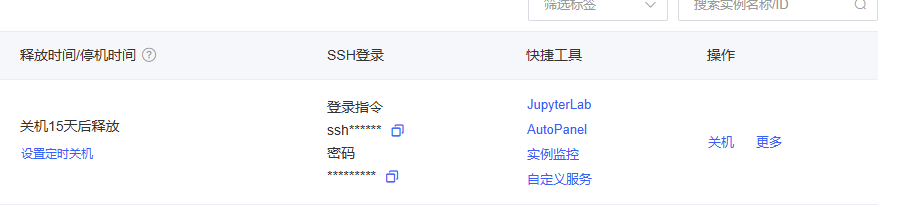
开机后,SSH登录位置会出现登录指令和密码
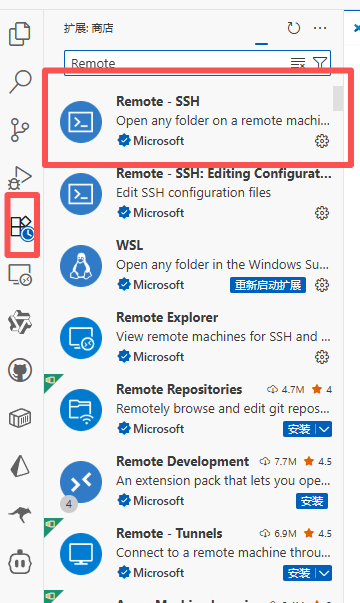
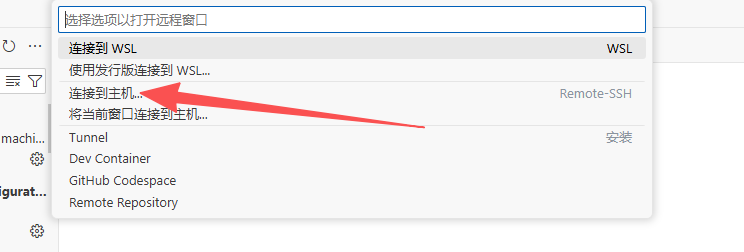
打开VSCode,下载Remote-SSH插件,连接服务器
下载完成后,会出现
点击图标或者下方的图标进行连接
![]()
这里填写AutoDL平台实例上的SSH登录-登录指令,这里平台提供复制功能,回车之后选择Linux,输入SSH登录-密码即可完成配置
3、服务器上部署自己的模型
安装模型方式
使用Git进行下载、ModelScope SDK下载、Huggingface下载
这里我们只讨论git和modelscope下载,国内网络访问Huggingface超时
Git下载模型
安装Git LFS(用于大文件下载)
git lfs install这会启用Git的Large File Storage,支持模型文件的下载
如果不能进行git lfs下载,执行下面的操作即可
sudo apt-get update
sudo apt-get install git-lfs验证安装
git lfs version使用git仓库进行下载,在huggingface或者魔搭找到你要使用的模型文件,上面有要使用的git下载地址,进行下载即可
命令会提供,如我是用的模型页面
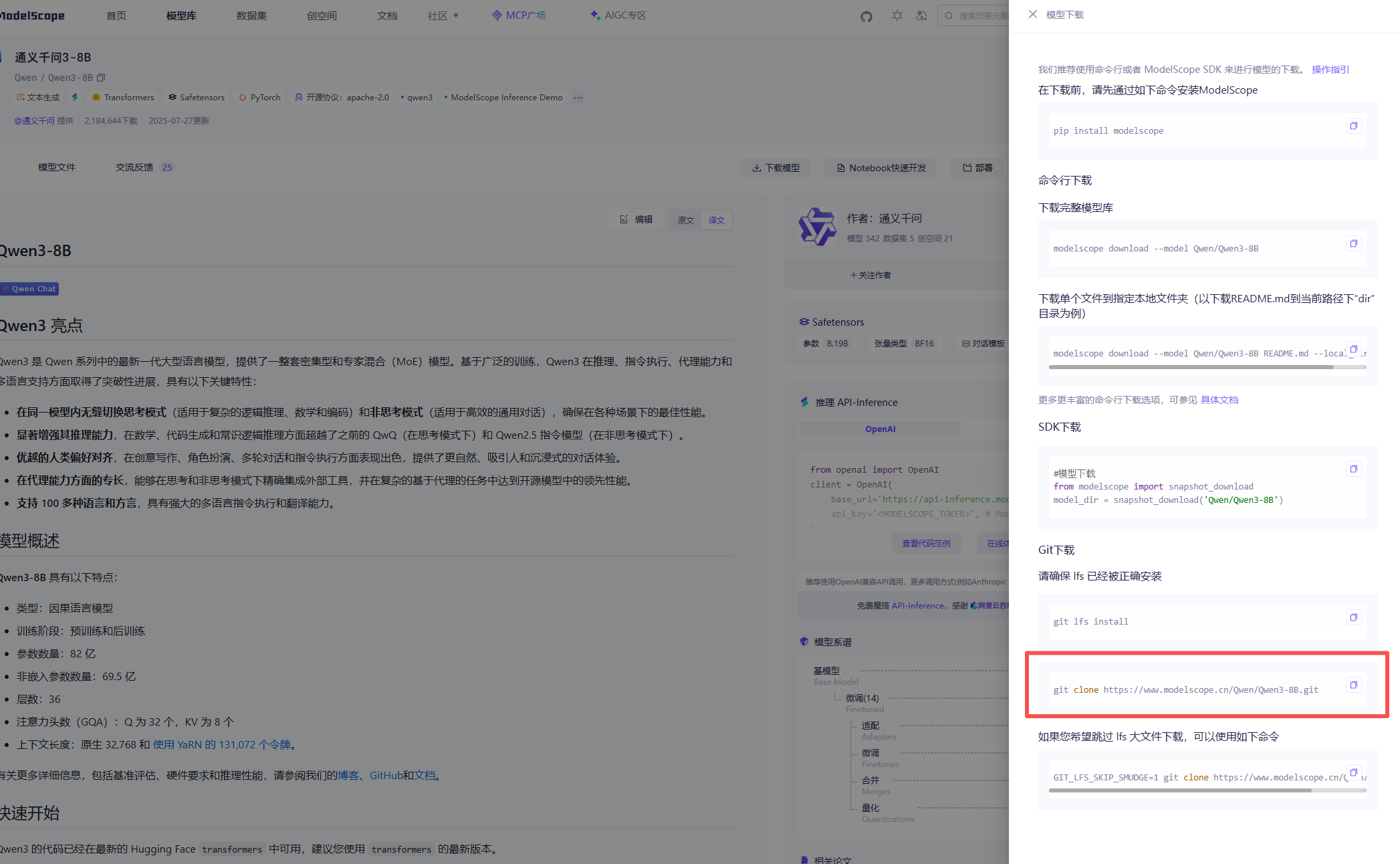
这样下载耗时会比较久,但是这样下载,我是完整下载成功
ModelScope SDK下载
安装ModelScope
pip install modelscope这里下载依赖,最好使用虚拟环境进行下载
创建虚拟环境
conda create -n env-name python=3.10激活虚拟环境
conda activate env-name模型下载
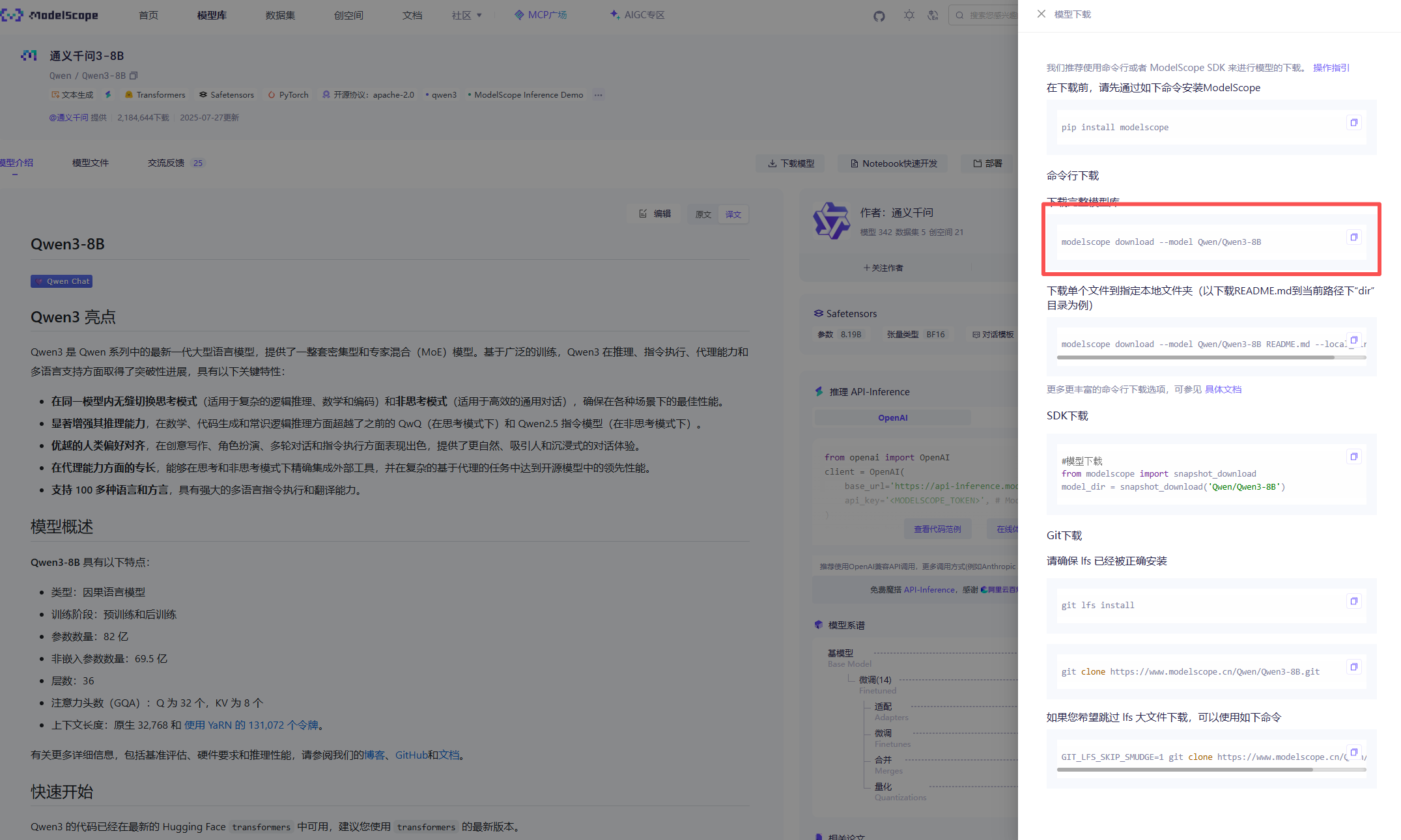
等待下载完成即可
4、运行模型
下载vllm
pip install vllm
使用vllm运行模型
vllm serve 模型下载路径 \
--host 0.0.0.0 \
--port 8001 \
--dtype bfloat16 \
--max-model-len 4096这里最好加上模型名称进行启动,否则后续使用过程需要使用模型下载路径进行连接
vllm serve 模型路径 \
--host 0.0.0.0 \
--port 8001 \
--dtype bfloat16 \
--max-model-len 4096 \
--served-model-name Qwen3
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)