智源研究院发布 RoboBrain 2.0 技术报告
25年8月来自北京智源研究院的技术报告“RoboBrain 2.0 Technical Report”。RoboBrain 2.0,是更新的具身视觉-语言基础模型,旨在统一物理环境中复杂具身任务的感知、推理和规划。它有两种变型:轻量级 7B 模型和全尺度 32B 模型,采用包含视觉编码器和语言模型的异构架构。尽管 RoboBrain 2.0 体量小,却在广泛的具身推理任务中表现出色。在空间和时
25年8月来自北京智源研究院的技术报告“RoboBrain 2.0 Technical Report”。
RoboBrain 2.0,是更新的具身视觉-语言基础模型,旨在统一物理环境中复杂具身任务的感知、推理和规划。它有两种变型:轻量级 7B 模型和全尺度 32B 模型,采用包含视觉编码器和语言模型的异构架构。尽管 RoboBrain 2.0 体量小,却在广泛的具身推理任务中表现出色。在空间和时间基准测试中,32B 变型均取得领先的结果,超越之前的开源和专有模型。尤其值得一提的是,它支持现实世界中关键的具身 AI 能力,包括空间理解(例如,affordance 预测、空间参考、轨迹预测)和时间决策(例如,闭环交互、多智体长视界规划和场景图更新)。本报告详细介绍模型架构、数据构建、多阶段训练策略、基础架构和实际应用。
在复杂和开放式的现实环境中部署LLM和VLM在具身场景中时,其面临三个基本能力瓶颈:(1)有限的空间理解:当前的模型难以准确地模拟相对和绝对空间关系并识别物理环境中的 affordance,这阻碍了现实世界的适用性;(2)弱时间建模:缺乏对多阶段、跨智体时间依赖性和反馈机制的理解限制长期规划和闭环控制;(3)推理链不足:现有模型通常无法从复杂的人类指令中提取因果逻辑并将其与动态环境状态相结合,从而限制了它们在开放式具体任务中的推广。
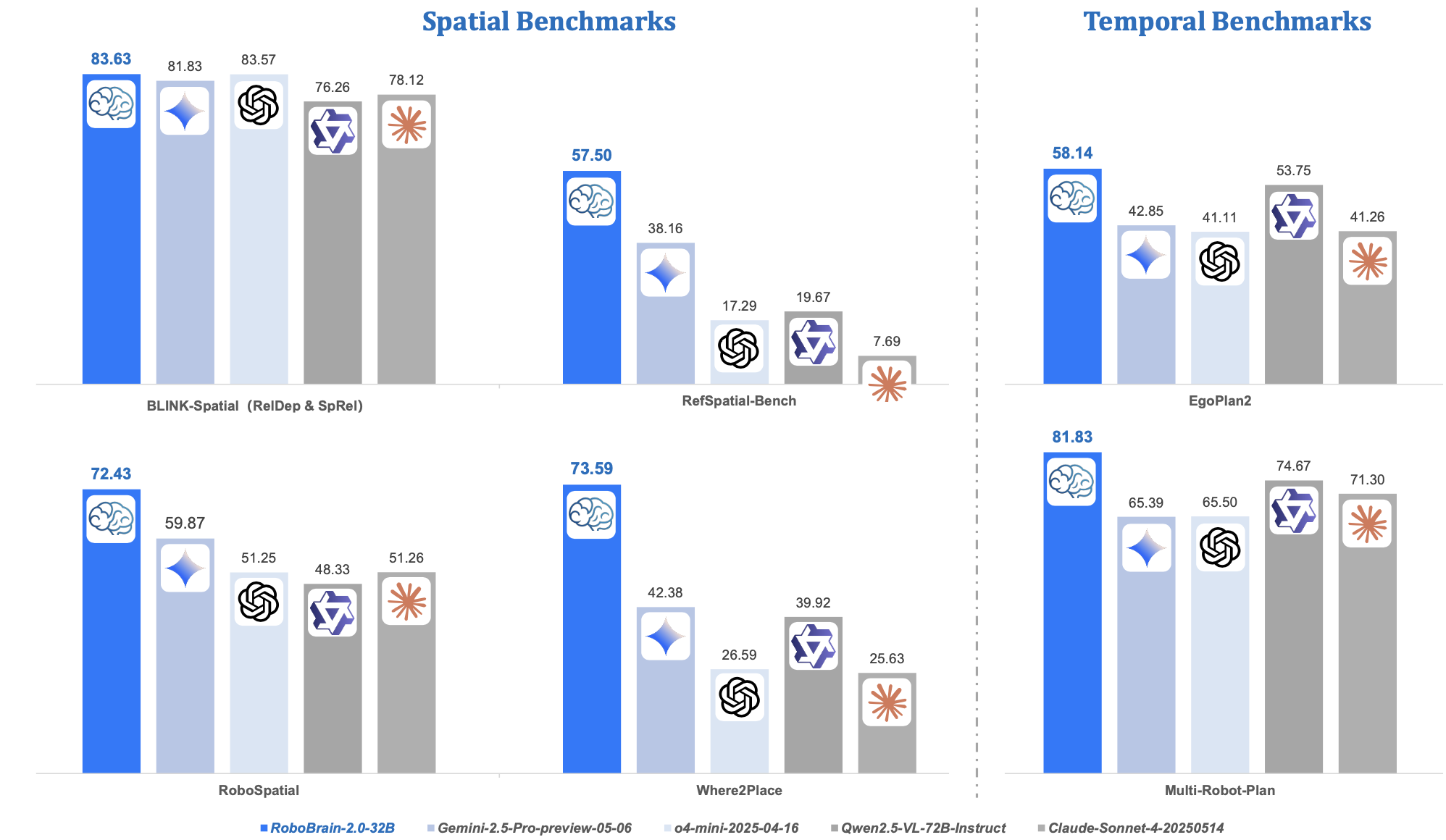
为了应对这些挑战,本文推出具身视觉-语言基础模型 RoboBrain 2.0,旨在连接物理环境中的感知、推理和规划。RoboBrain 2.0 在统一架构中处理视觉观测和语言指令,从而实现对环境的整体理解、目标导向推理和长期规划。该模型有两个版本:轻量级 RoboBrain 2.0-7B 和全尺寸 RoboBrain 2.0-32B,旨在满足不同资源约束条件下的不同部署需求。在空间推理和时间推理基准测试中,32B 版本大多达到最佳性能,超越之前的开源和专有模型,如图所示。
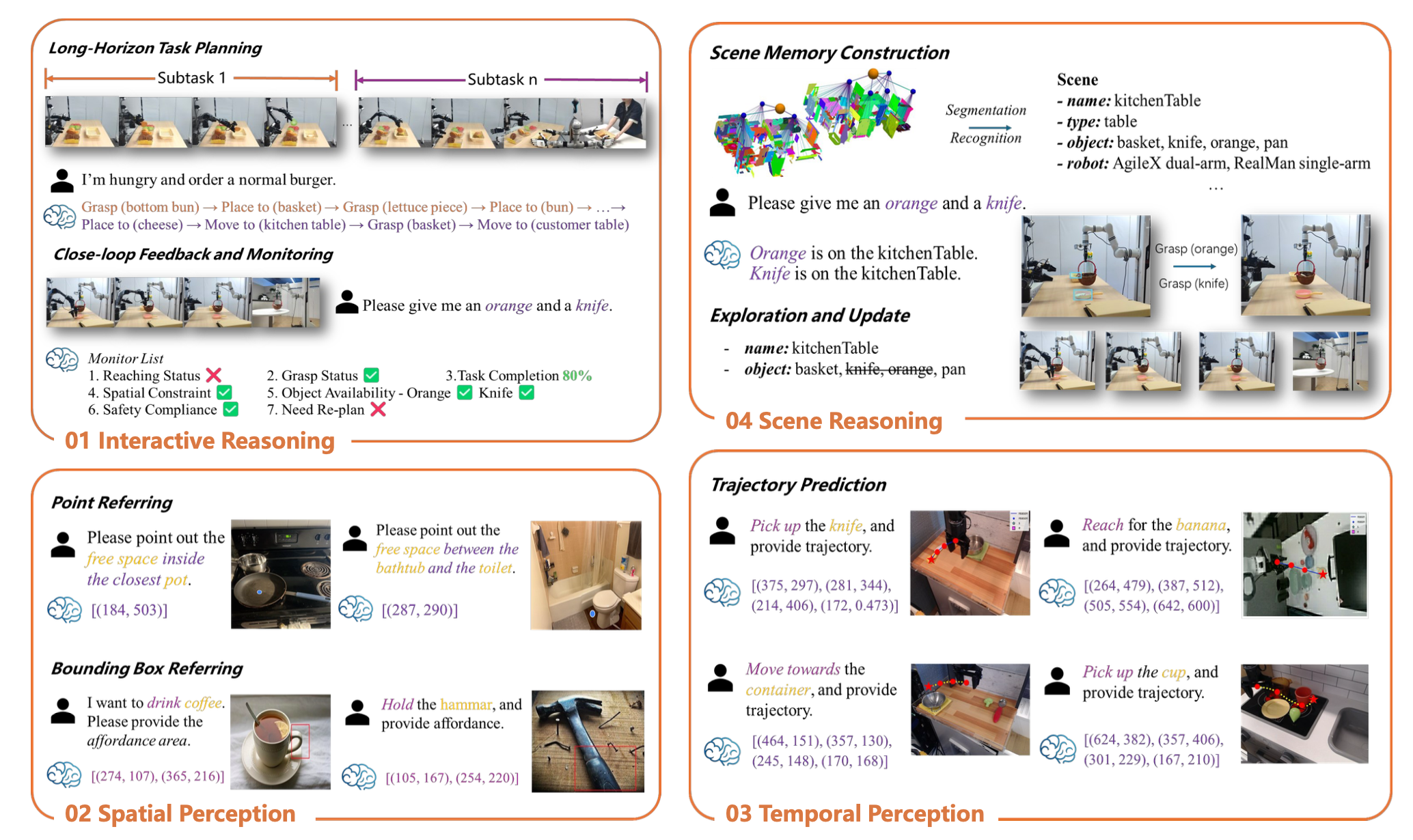
RoboBrain 2.0 模型能力总结如图所示:其支持具有长远规划和闭环反馈的交互式推理、用于从复杂指令中精确预测点和边框的空间感知、用于估计未来轨迹的时间感知以及通过实时场景图构建和更新进行场景推理。
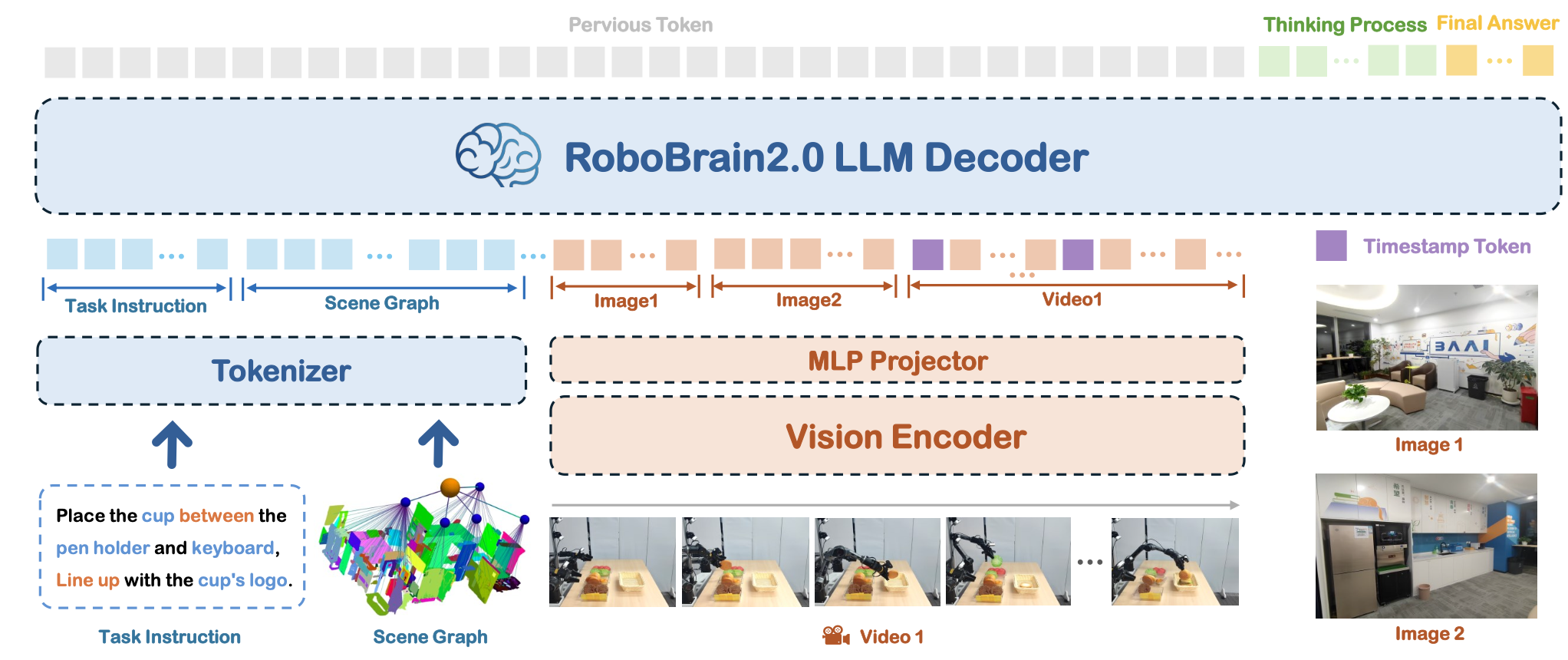
RoboBrain 2.0 采用模块化编解码器架构,将感知、推理和规划统一起来,以应对复杂的具身任务。如图所示,它通过四个核心组件处理多视角视觉观测和自然语言指令:(1)用于文本/结构化输入的 token 化器,(2)视觉编码器,(3)将视觉特征映射到语言模型 token 空间的多层感知器 (MLP) 投影器,以及(4)基于 Qwen2.5-VL [5] 初始化的语言模型主干。与专注于通用静态 VQA 的传统 VLM [2, 22] 不同,RoboBrain 2.0 在保持强大通用 VQA 能力的同时,专注于空间感知、时间建模和长链因果推理等具身推理任务。该架构将高分辨率图像、多视角输入、视频帧、语言指令和场景图编码为统一的多模态 token 序列,以便进行综合处理。
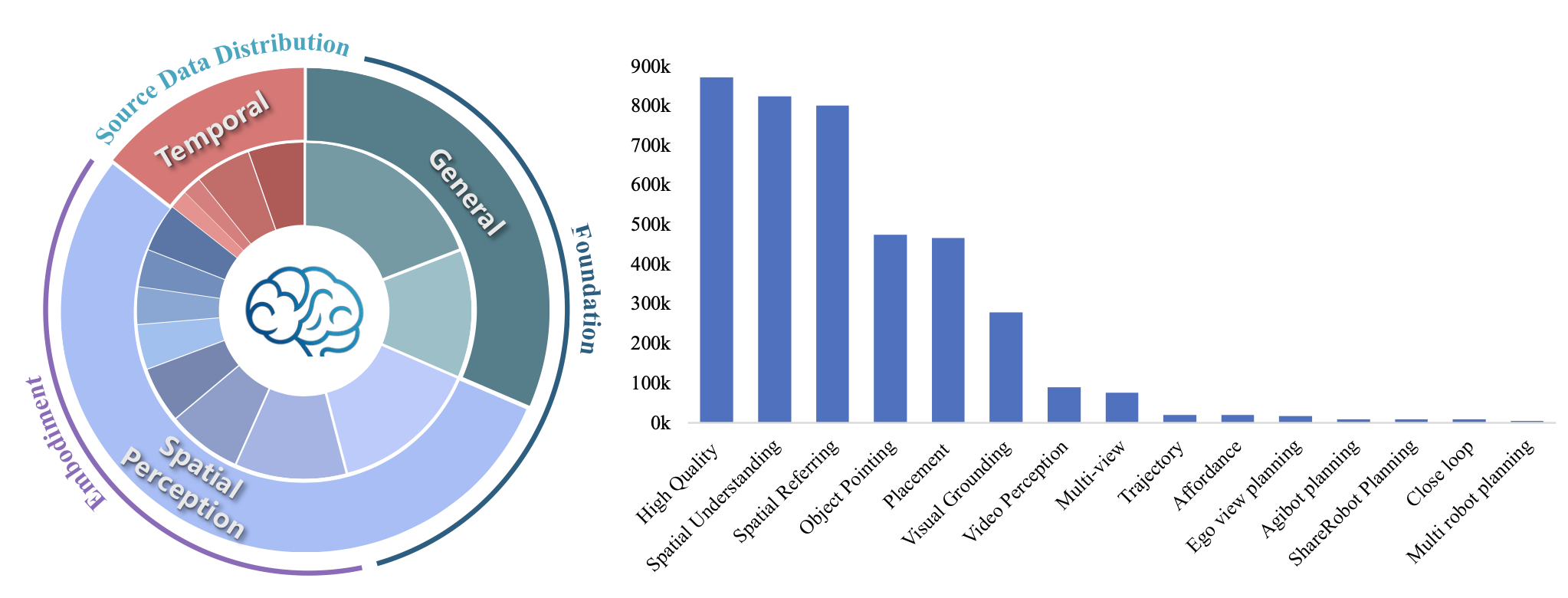
如图所示,RoboBrain 2.0 基于一个丰富且广泛的数据集进行训练,旨在增强其在具身场景下的空间理解、时间建模和长链因果推理能力。训练数据涵盖多种模态,包括高分辨率图像、多视角输入、视频序列、场景图和自然语言指令。该全面的数据集被精心划分为三大主要类型:通用多模态理解、空间感知和时间建模,以确保模型能够在复杂的物理环境中有效地感知、推理和规划。
通用 MLLM VQA
高质量数据。RoboBrain 2.0 的通用训练数据集包含 873,000 个高质量样本,主要来自 LLaVA-665K [33] 和 LRV-400K [32],涵盖标准视觉问答 (VQA)、区域级查询、基于 OCR 的 VQA 和视觉对话。(1) LLaVA-665K 作为主要来源,包含各种 VQA 类型的数据,包括标准 VQA 数据集、基于 OCR 的问题、区域级查询、视觉对话和纯语言对话。为了提高训练效率,来自同一图像的多个问答 (QA) 对会合并为单个对话;无效的 ShareGPT [10] 条目会被过滤掉,过长的对话(>2048 个 token)会被截断(最终有效样本数量为 40,000 个)。具体来说,A-OKVQA [54] 样本通过复制选项来扩充,以平衡多项选择格式;OCR-VQA [41] 贡献 80K 个样本对话,重点是场景文本理解;Visual Genome(VG) [27] 提供密集的目标级注释,每幅图像限制为 10 个条目,并带附加的字幕;RefCOCO [76] 对话被分成短的多轮片段(<10 次对话)。语言对话通常比视觉对话长,以单模态批次进行采样,以在不降低性能的情况下将吞吐量提高 25%。在删除依赖于边框的 QA 对后,从该来源保留 531K 个高质量样本。(2)LRV-400K 是使用 GPT-4 [44] 在几次指令跟踪设置下合成生成的。它在 16 个视觉语言任务中生成 400K 个图像条件指令,并带有文本答案。与先前依赖稀疏图像说明的研究不同,该数据集利用 VG 中的密集注释(例如,边框、尺寸以及每幅图像约 21 个目标区域)。GPT-4 为每幅图像生成陈述式和疑问式提示,每个实例随机抽取 10 个任务。在过滤掉与边框相关的问答对后,选取 34.2 万个样本进行训练。
空间数据
视觉落地。视觉落地数据集旨在通过精确的目标级定位来增强多模态理解,并利用 LVIS [19] 提供的大量标注。精心挑选 15.2 万张 LVIS 高分辨率图像,确保广泛覆盖各种目标类别和复杂的视觉场景。每个目标标注都被转换为代表左上角和右下角的标准化边框坐标 (x1, y1, x2, y2),从而实现一致的空间参考。为了实现丰富的视觉对话,生成了 8.6 万个对话序列,每个序列包含多轮问答对,逐步探索视觉关系、属性推理和上下文理解。该数据集在各个物体类别之间保持均衡分布,同时保留遮挡、视点变化和罕见情况等棘手情况,以支持稳健的视觉落地。
目标参考。目标参考数据集旨在使 RoboBrain 2.0 能够通过指向图像中的目标来识别指定目标的位置。利用 Pixmo-Points [13] 数据集作为数据源,该数据集包含 22.3 万张图片,共计 230 万个点标注。然而,由于目标实例(例如书架上的书籍)密集重复,直接使用 Pixmo-Points 数据进行 RoboBrain 2.0 训练存在挑战。为了解决这个问题,实施一个两步过滤流程:(1) 丢弃标注点超过 10 个的标注以简化训练;(2) 使用 GPT-4o [22] 作为场景分析器,仅选择与室内相关的目标,例如厨具、家具和装饰品,排除不相关或室外场景。此流程为 6.4 万张图片生成了 19 万个 QA 对,并且杂乱程度有所降低,使数据更适合具身情境。为了构建用于参考任务的 QA 对,构建 28 个人工设计的模板,例如“指出图片中所有 {label} 的实例”。或“帮我指向图片中的 {label} 并找到它”。此处,{label} 指的是标注中目标类别。模板是随机选取的,以确保语言多样性并提升模型在引用任务中的泛化能力。对于目标参考指向,整合来自 RoboPoint [77] 的目标参考数据,该数据包含 288,000 张图片的 347,000 条问答标注。为了解决点数过多可能阻碍训练收敛的问题,每个问题随机采样最多 10 个点。此外,将归一化坐标转换为绝对值,以便更好地支持 RoboBrain 2.0 训练。
Affordance。Affordance 数据集侧重于理解目标功能和 affordance 放置的空间空白区域。对于物体 affordance 识别,利用来自 PACO-LVIS [51] 的部件级标注,涵盖 46,000 张图片的 75 个物体类别和 200 个部件类别。其提取整个物体及其功能部件的边框和分割掩码。这些注释被转换为边框坐标 (x1, y1, x2, y2),作为 affordance 预测任务的真值标签。问题使用 GPT-4o [22] 构建,用于查询物体功能和部件用途,例如,“手提包的哪个部分可以抓握来携带?” 表示手提包的提手。对于整体物体 affordance,问题避免直接提及物体名称,例如,“可以移动哪个设备来控制屏幕上的光标?” 表示鼠标(计算机设备)。此自动过程生成 561,000 个 QA 对。对于空间 affordance 学习,纳入来自 RoboPoint [77] 的区域参考数据。该数据集包含 270,000 张图像、320,000 个 QA 对和 14 个空间关系标签。每个注释都被转换为一组绝对坐标 [(x1, y1), (x2, y2), …],并将真值点重采样为每个答案最多 10 个点以进行优化。该数据集使 RoboBrain 2.0 能够推理现实世界中物体放置的空间 affordance。
空间理解。为了增强 RoboBrain 2.0 的 3D 空间推理能力,推出包含 826,000 个样本的空间理解数据集。该数据集强调以物体为中心的空间属性(例如位置、方向)和物体间关系(例如距离、方向),涵盖定性和定量两个方面。它涵盖 31 个不同的空间概念,大大超过以往数据集中通常约 15 个的概念。部分采用 RefSpatial [81] 流程,通过基于模板和 LLM 的自动生成来构建 2D 网络图像和 3D 视频数据集:(1) 2D 网络图像旨在提供跨各种室内外场景的核心空间概念和深度感知。为了弥合这些域之间的规模和类别差距,利用大规模的 OpenImage [28] 数据集。由于从 2D 图像直接进行 3D 推理具有挑战性,其会被转换为伪-3D 场景图。具体来说,将 1.7M 幅图像滤波至 466K 后,首先使用 RAM [79] 进行物体类别预测,并使用 GroundingDINO [34] 进行二维框检测。然后,用 Qwen2.5-VL [50] 和一种启发式方法,根据给定的二维边框生成从粗粒度(例如“杯子”)到细粒度(例如“左边第三个杯子”)的分层描述。这使得在杂乱环境中能够实现明确的空间引用,并同时捕捉粗粒度和细粒度的空间引用。接下来,用 UniDepth V2 [48] 和 WildeCamera [84] 进行深度和相机内参计算,以实现 3D 点云重建。最后,将其与 GroundingDINO [34] 中的目标框和 SAM 2.1 [52] 中的掩码相结合,每个场景图都包含目标标签、二维框、实例掩码和目标级点云,从而生成轴对齐的三框。目标字幕充当节点,空间关系构成边。问答对通过模板和 LLM(例如 QwQ [66])生成,其中包括从分层字母派生的目标位置问题。(2)基于 3D 场景的视频集成来自五个原始数据集的多模态 3D 场景理解数据:MMScan [38]、3RScan [69]、ScanQA [3]、SQA3D [39] 和 SpaceR [46]。通过严格的数据处理进行基于模板的问题过滤,以确保任务相关性,执行多阶段质量筛选(例如一致性检查、异常值移除),并将所有格式标准化为统一的表示形式。这种数据集能够实现细粒度的环境感知,并增强其可靠性,支持从物体定位到三维场景中复杂的空间推理等任务。(3) 3D 具身视频专注于室内环境中的细粒度空间理解。利用 CA-1M [29] 数据集,将 2M 帧过滤为 10 万帧高质量帧。与二维数据集相比,精确的三维边框能够构建更丰富的场景图,其中包含更多样化的空间关系,从而生成更多定量的问答对(例如大小、距离)。
空间参考。在增强基础三维空间理解之后,通过引入包含 80 万个样本的空间参考数据集 [81],将这些能力扩展到物理世界交互。与以往的视觉落地或物体参考数据集(通常处理模糊或多个参考物)不同,该数据集针对单个明确的目标,这与精确拾放等需要精确目标识别和定位的机器人应用相一致。遵循 RefSpatial [81] 的构建流程,对于位置数据,从基于 2D 网络图像(OpenImage [28])和 3D 具身视频(CA-1M [29])构建的场景图中采样字幕-点对,并使用分层字幕。对于位置数据,用完全注释的 3D 数据集生成自上而下的占用图,其中编码物体的位置、方向和度量空间关系(例如,“椅子右侧 10 厘米”),从而实现准确的空间引用。
时间数据
自我视角规划。通过部分处理 EgoPlan-IT [9] 数据集(包含 5 万个自动生成的样本)构建自我视角规划数据集。对于每个选定的任务实例,从先前的操作中提取多个帧来表示任务进度,并提取一个帧来捕捉当前视角。为了增强语言多样性,用多个提示模板来描述任务目标、视频上下文和当前观察结果。每个问题都包含正确的下一步动作以及从反面例子中随机抽取的最多三个干扰动作。此设置支持通过多样化的视觉和文本输入进行多模态指令调整,旨在提高以自我为中心的任务规划性能。
ShareRobot 规划。ShareRobot 数据集 [23] 是一个大规模、细粒度的机器人操作资源,提供针对任务规划量身定制的多维注释。其规划组件提供与各个视频帧对齐的详细低级指令,有效地将高级任务描述转换为结构化且可执行的子任务。每个数据实例都包含精确的规划注释,以支持准确且一致的任务执行。该数据集包含来自 51,000 个实例的 1,000,000 个 QA 对,涵盖 12 个机器人实施例的 102 个不同场景以及根据 Open-X-Embodiment 分类法筛选的 107 个原子任务 [47]。所有规划数据均由人类专家按照 RoboVQA [55] 格式进行精心注释,使模型能够学习基于多样化现实场景的稳健多步骤规划策略。ShareRobot 的规模、质量和多样性有助于提升模型在复杂具身环境中执行细粒度推理和任务分解的能力。
AgiBot 规划。AgiBot 规划数据集是一个基于 AgiBot-World [6] 数据集构建的大规模机器人任务规划数据集,包含 19 个操作任务的 9,148 个问答对,以及 109,378 张第一人称视角图像。每个样本包含 4-17 个连续帧,以多模态对话格式记录任务进展。AgiBot-Planning 提供分步规划指令,将高级目标转化为可执行的子任务。每个数据点包含当前目标、历史步骤和所需的后续操作。该数据集涵盖从家用冰箱操作到超市购物等不同环境下的各种场景。精心设计的注释采用标准化的对话格式,使模型能够从各种现实世界情境中学习。通过连续的视觉序列和细粒度的行动计划,AgiBot-Planning 增强 RoboBrain 2.0 在复杂具体场景中执行长远任务规划和空间推理的能力。
多机器人规划。多机器人规划数据集基于 RoboOS [61],通过模拟三种环境(家庭、超市和餐厅)中的协作任务场景构建而成。每个样本均使用结构化模板生成,这些模板指定详细的场景图、机器人规格和相关工具列表。针对每种场景,设计需要场景中多个机器人协调的高级、长远协作任务目标,并生成相应的工作流图,将任务分解为具有详细推理解释的子任务。基于这些分解,进一步生成特定智体的机器人工具规划,将高级任务目标转化为每个子任务的精确低级“观察-行动”对。具体而言,在三种环境中定义 1,659 种类型的多机器人协作任务,并使用 DeepSeek-V3 [31] 生成 44,142 个样本。
闭环交互。闭环交互数据集旨在促进高级具身推理 [80],其特点是包含大量合成的“观察-思维-行动”(OTA)轨迹,这些轨迹将第一人称视觉观察与结构化思维 token 相结合。它涵盖 120 个不同的室内环境,包括厨房、浴室、卧室和客厅,包含 4000 多个交互物体和容器。该数据集在 AI2Thor [25] 模拟器中通过基于具身推理机 [78] 的严格多阶段流程构建而成,包括:(1)根据受约束的模板精心设计任务指令,以确保场景适用的有效性;(2)从编码功能关系的物体关联图中导出关键动作序列;以及(3)策略性地整合搜索动作,以模拟真实的探索。为了丰富推理的深度,GPT-4o 生成详细的思维过程——涵盖情境分析、空间推理、自我反思、任务规划和验证——这些思维过程在观察和行动之间无缝集成,形成连贯的推理链,指导模型完成复杂、长期的交互任务。
RoboBrain 2.0 通过渐进式三阶段训练策略实现具身能力(空间理解、时间建模和思路推理),如表所示。从强大的视觉语言基础出发,引入逐步复杂的具身监督,使模型能够从静态感知演进到动态推理和在现实环境中可操作的规划。
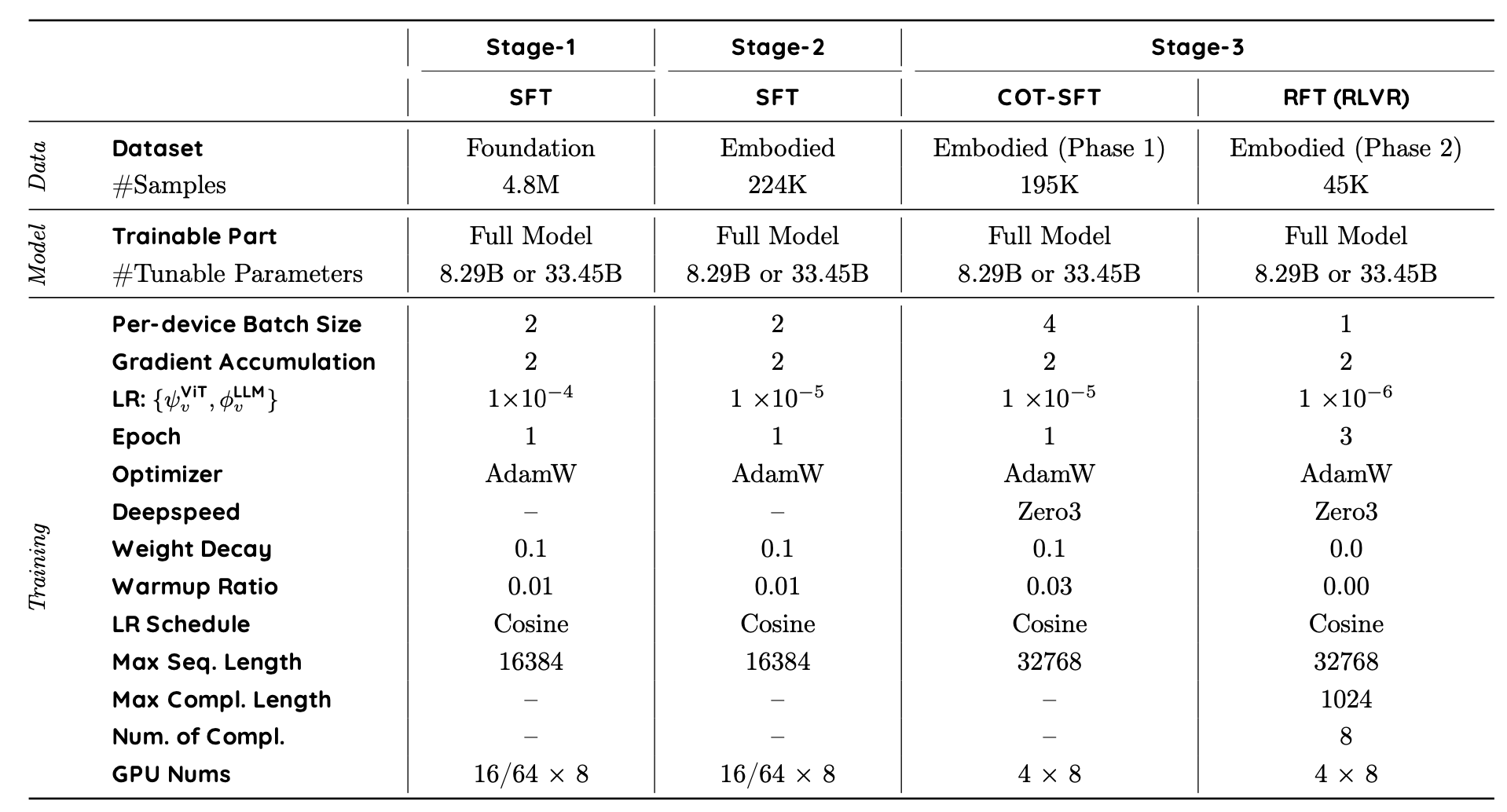
第一阶段:基础时空学习
第一阶段专注于构建空间感知和时间理解的通用能力。在大规模多模态数据集上对模型进行微调,该数据集涵盖密集字幕、物体定位、图文交错文档、基本视频问答以及参考表达理解。这些数据集涵盖常见的物理场景和交互模式,帮助模型构建物体、空间关系和运动事件的基本概念。这一阶段为理解自我为中心的视频流和空间锚定指令奠定了基础。
第二阶段:具身时空增强
为了使模型更好地适应具身任务,引入一系列精心挑选的高分辨率、多视角、以自我为中心的视频数据集,以及指令增强的导航和交互数据。这些任务包括基于视角的参考表达、3D affordance 估计以及以物体为中心的场景图构建。这一训练阶段强调对长时域依赖关系的建模,使模型能够对扩展的动作和观察序列进行推理。此外,它还融合了多智体协作场景,使模型能够学习解释和预测共享环境中其他智体的行为。为了支持这些功能,采用扩展的序列长度和多摄像头输入编码,使模型能够同时处理和融合来自多个视角的视觉信息。通过这一训练阶段,模型可以将历史视觉线索与当前指令相结合,从而在动态交互环境中实现更连贯的长时域规划、强大的场景理解和自适应决策。
第三阶段:具身情境中的思维链推理
在第三阶段,用思维链 (CoT) 方法论增强模型的高级推理能力,遵循 Reason-RFT [62] 的两阶段框架:基于 CoT 的监督微调 (CoT-SFT) 和强化微调 (RFT)。利用来自合成和现实世界具体场景的多轮推理示例,涵盖长期任务规划、操作预测、闭环交互、时空理解和多机器人协作。具体而言,(1) CoT-SFT 阶段:用 GPT-4o [22] 标注的 CoT 基本原理和自定义提示对 10% 的构建训练数据进行注释,然后对第二阶段的初始模型进行监督微调。(2) RFT 阶段:再从构建的训练数据中抽取 10% 的样本来收集模型的响应,将错误答案整理到重格式化的训练集中(例如,多项选择题或 LaTeX / 数字答案)。优化采用组相对策略优化 (GRPO) [17],由评估答案准确性和格式正确性的复合奖励函数指导。
大规模训练基础设施
为了提高多模态模型训练的效率和稳定性,其开发并集成一系列关键优化技术,包括混合并行策略、内存预分配、分布式数据加载、内核融合以及细粒度计算通信重叠。这些优化显著提高资源利用率和训练吞吐量。在数据预处理方面,基于 Megatron-Energon 框架 [30] 构建,并融入自定义优化策略。该系统支持动态混合包含多种模态的多个数据集,包括纯文本、单张图片、多张图片和视频,同时允许在每个数据集内严格保持样本顺序。基于 WebDataset 的自定义格式 [1] 能够兼容各种数据模态,并显著缩短预处理时间,同时提高数据处理的灵活性和可扩展性。
多维混合并行
多模态模型在架构和数据特性方面与传统的 LLM 有显著不同 [33]。在架构方面,多模态模型本质上是异构的:视觉模块(例如,带有适配器的 ViT)通常是一个小型的纯编码器组件,而语言模块则是一个规模更大的纯解码器转换器。在数据方面,训练样本包括纯文本、单幅图像、多幅图像序列和视频。不同样本的图像 token、文本 token的数量以及融合 token 序列的长度可能存在显著差异。
这些异构性对分布式训练框架构成了巨大的挑战。为了解决这个问题,在自定义框架 FlagScale [12] 中实施了几种有针对性的策略:
• 非均匀流水线并行 [43]:由于 ViT 模块出现在模型的早期阶段,并且计算成本相对较低,减少第一个流水线阶段的 LLM 层数量,从而在不增加内存开销的情况下提高训练吞吐量。
• 单独的重新计算策略:在退火阶段,视觉输入可能包含多达 20,000 到 30,000 个 token,这经常导致 ViT 模块出现内存不足 (OOM) 错误。为了缓解这个问题,仅在 ViT 模块中启用重计算 [8, 26],以减少中间激活的内存占用,同时在 LLM 模块中禁用重计算以保持计算效率。
预分配内存
在 RoboBrain 2.0 的监督微调训练过程中,不同样本的输入长度差异很大。PyTorch 的默认缓存内存分配器 [49] 在这种动态输入条件下会导致内存碎片化,从而经常导致内存不足(OOM)错误。一种常见但低效的解决方法是在每次前向传播之前调用 torch.cuda.empty_cache(),这会严重降低性能。为此,通过分析 PyTorch 的内存分配机制,采取一种更高效的方案。碎片化通常是由于缺乏足够大且连续的缓存内存块来容纳新的张量,从而促使新的内存分配并加剧碎片化。为了解决这个问题,引入一种内存预分配策略:在训练之前计算整个数据集的最大序列长度,并在第一步中将所有样本填充到这个最大长度。这确保张量可以重用预分配的内存块,从而减少碎片化并保持吞吐量。
数据预处理
采用原生的 Megatron-Energon [30] 进行统一数据加载,无需依赖外部训练框架。此外,优化预处理流程,将时间消耗减少高达 90%。评估并比较两种预处理策略:
• 同时预处理 JSON 和图像。使用默认的 Megatron-Energon 数据流水线,JSON 元数据和图像均被压缩为二进制文件,用于 WebDataset。然而,这种方法存在两个主要问题:(1) 效率低:预处理 32 万个样本可能需要 2 小时以上。(2) 图像读取不一致:Megatron-Energon 使用 cv2,而 RoboBrain 2.0 等模型使用 PIL,这会导致细微的差异,从而影响训练性能。
• 仅预处理 JSON(推荐)。在优化的流水线中,仅预处理 JSON 文件,图像保持其原始格式。图像预处理将交由 TaskEncoder 模块处理,使用与 Qwen2.5-VL 相同的预处理器。(1) 效率高:预处理 32 万个样本只需不到 10 分钟。(2) 与模型输入对齐:确保预处理和训练过程中的图像处理完全对齐,从而消除不一致并提升模型性能。
分布式数据加载
为了最大限度地减少计算节点的 I/O 负担,减少大规模分布式训练中的冗余数据加载。与单节点设置不同,分布式训练系统中的 GPU 根据所选的并行策略扮演着不同的角色。数据加载通常发生在数据并行 (DP) 维度上,其中每个 DP 等级处理一个唯一的数据分片。然而,在多维混合并行(例如 DP-PP-TP)中,实际上只有一部分 GPU 进程需要加载数据:(1) 在每个流水线并行 (PP) [42] 组中,只有第一阶段和最后一阶段需要执行数据加载。(2) 在张量并行 (TP) [58] 组中,每个组只需一个 GPU 加载数据,其他 GPU 通过广播接收数据。这种设计显著减少冗余 I/O 操作,并提高整体数据吞吐量。
容错
为了处理训练期间的硬件和软件故障,在 FlagScale [12] 训练框架和系统平台之间共同设计容错机制。常见错误(例如 LostCard、KubeNodeNotReady)会被自动检测,并触发作业自动恢复和重启,从而最大程度地减少中断。此外,基于 Megatron-Energon 的自定义 DataLoader 模块支持完整的数据状态恢复,允许从最新的检查点无缝恢复,并确保数据加载和样本重排状态完全一致。
强化微调基础设施
采用可验证奖励强化学习 (RLVR) 来增强 RoboBrain 2.0,并使用 VeRL [68],VeRL 是一个专为训练后 LLM 和 VLM 设计的开源强化学习框架。VeRL 基于 HybridFlow 架构 [56],采用混合控制器模型,该模型集成用于 RL 角色间数据流协调的全局控制器和用于 RL 角色内并行处理的分布式控制器。该架构能够高效执行复杂的后训练工作流程,同时确保可扩展性。 VeRL 支持多种强化学习算法(例如 GRPO)并与 LLM 无缝集成,使其特别适合 RoboBrain 2.0 的强化学习微调 (RFT) 需求。该框架通过优化的数据流管理和并行处理能力,以最小的开销实现高性能模型调优。其高效处理大规模训练任务和严格的奖励验证能力,使 VeRL 成为通过 RLVR 提升 RoboBrain 2.0 能力的理想平台。
推理基础设施
为了提高模型推理效率,采用 FlagScale [12],这是一个多后端推理框架,它可以根据不同模型在异构硬件加速器上的性能特征,自动搜索最优推理引擎和配置参数,从而有效降低推理延迟。鉴于具身人工智能模型对准确率的高度敏感性,进一步引入混合比特量化策略 [40, 70]。该策略在保持模型性能的同时,提高推理效率和资源利用率。具体来说,视觉编码器保留全精度浮点计算,以确保关键特征提取的准确性。相反,在语言模块中,权重被量化为8位整数,而激活则以16位浮点格式保存。这种混合精度方法显著降低计算开销和内存占用,对模型精度的影响几乎可以忽略不计。此外,量化过程对现有推理流程的侵入性极小,可以灵活地集成到现有系统中。在端到端具身任务中,仅权重量化即可实现约30%的推理延迟降低,说明在实际部署场景中的有效性和实用性。
RoboBrain-32B-2.0 和 RoboBrain-7B-2.0 在九个空间推理基准进行测试:BLINK、CV-Bench、EmbSpatial、RoboSpatial 和 RefSpatial-Bench,以及 SAT、VSI-Bench、Where2Place 和 ShareRobot-Bench。
RoboBrain-32B-2.0 和 RoboBrain-7B-2.0 在三个关键的时间推理基准进行测试:多机器人规划、Ego-Plan2 和 RoboBench。
未来计划在两个关键方向上扩展 RoboBrain 2.0:
• 嵌入 VLM 驱动的 VLA:目标是将尖端的嵌入 VLM 集成到视觉-语言-动作 (VLA) 框架中。该方向旨在利用 VLM 强大的时空感知和高级推理能力,大幅提升动作生成的通用性和鲁棒性。最终的系统将支持在实际场景中对复杂、开放式指令进行更细致的理解和精准的执行。
• 系统级集成:为了提升 RoboBrain 2.0 的实际应用,将与先进的机器人平台和操作系统紧密集成。这将实现无服务器部署、无需适配的技能注册和低延迟的实时控制。同时,设想构建一个协作式的具身化人工智能生态系统——一个“智能应用商店”,支持现实世界机器人系统中用于感知、推理和控制的即插即用组件。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献121条内容
已为社区贡献121条内容

所有评论(0)