大模型技术演变-1词向量革命Efficient Estimation of Word Representations in Vector Space读后笔记
Word2Vec论文开创了自然语言处理的新范式,通过无监督学习从大规模文本中获取高质量词向量表示。论文提出的CBOW和Skip-gram模型基于"相似上下文词语义相近"的假设,采用层次Softmax、负采样等优化技术,显著提升了训练效率。实验证明词向量能捕捉丰富的语义语法关系,如"国王-男人+女人≈女王"的向量运算。该研究奠定了词嵌入技术基础,推动了NLP从
1 论文背景与意义
在深度学习革命前夕的2013年,自然语言处理(NLP)领域面临着一个根本性挑战——如何让计算机真正理解人类语言的语义内涵。在Word2Vec提出之前,主流方法主要使用独热编码(one-hot encoding) 来表示单词,这种方法将每个词表示为一个大而稀疏的向量,向量维度等于词汇表大小,其中只有一个元素为1(表示该词的位置),其余全为0。尽管这种方法简单直观,但其存在明显局限性:它无法捕捉词语之间的语义关系,所有词在向量空间中都相互正交,无法表达"国王"与"君主"或"男人"与"女人"之间的语义关联性。
Tomas Mikolov等人于2013年发表的《Efficient Estimation of Word Representations in Vector Space》开创性地提出了Word2Vec模型,彻底改变了自然语言处理的表示学习方法。这篇论文的意义在于它首次证明了可以通过无监督学习从大规模文本语料中高效地学习到高质量的词向量表示,这些向量能够捕捉丰富的语义和语法关系。论文中提出的连续词袋模型(CBOW)和Skip-gram模型成为了后续词嵌入技术的基础,推动了整个NLP领域从符号处理向语义理解的范式转变。
表:不同文本表示方法的比较
|
表示方法 |
维度特点 |
能否捕获语义 |
计算效率 |
稀疏性 |
|---|---|---|---|---|
|
One-Hot编码 |
高维(词汇表大小) |
否 |
高(但表示简单) |
极高(极度稀疏) |
|
词袋模型(BoW) |
高维(词汇表大小) |
有限(基于频率) |
中等 |
高(稀疏) |
|
TF-IDF |
高维(词汇表大小) |
有限(加权频率) |
中等 |
高(稀疏) |
|
Word2Vec |
低维(通常50-1000维) |
是(丰富语义关系) |
训练耗时但推理高效 |
低(稠密向量) |
Word2Vec的革命性在于它证明了分布式表示(Distributed Representation)的强大能力。与传统方法不同,分布式表示将每个词映射为一个低维稠密向量(通常50-300维),使得语义相似的词在向量空间中距离接近。这种表示不仅解决了维度灾难问题,更重要的是揭示了语言中的潜在语义结构——例如,通过简单的向量运算就能得到"国王" - "男人" + "女人" ≈ "女王"这样的语义关系。
2 核心思想与模型架构
Word2Vec的核心思想基于一个基本假设:出现在相似上下文中的单词往往具有相似的含义(分布式假设)。这一假设使得模型能够从大量无标注文本中自动学习词语的语义表示,而不依赖于人工标注的数据。论文提出了两种不同的神经网络模型架构来实现这一目标:Continuous Bag-of-Words(CBOW)和Skip-gram模型。
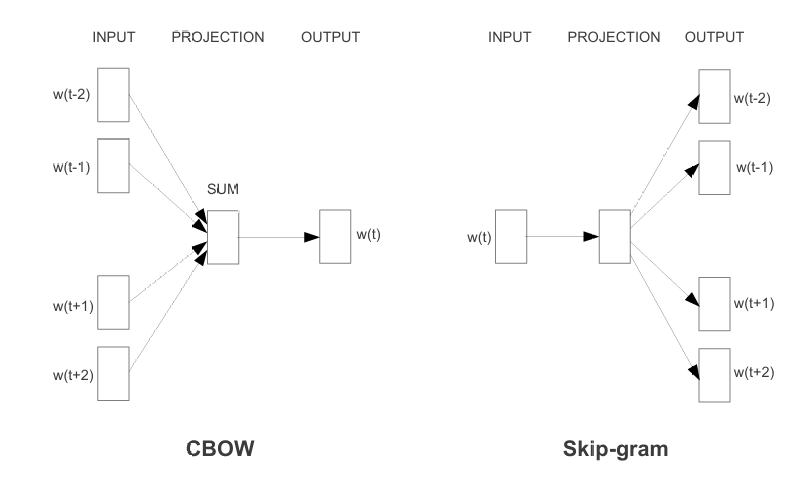
2.1 CBOW模型架构
CBOW模型的目标是根据上下文词语来预测当前目标词。具体而言,给定一个位置前后各C个上下文词(窗口大小为C),模型通过训练来预测中心词出现的概率。CBOW的架构包含三层:
-
输入层:将上下文词的one-hot向量表示作为输入。假设词汇表大小为V,窗口大小为C,则输入是C个V维向量。
-
投影层:将C个输入向量通过一个共享的权重矩阵W(V×N矩阵,N是词向量维度)投影到N维空间,然后将这些向量平均求和形成一个隐藏层向量。
-
输出层:通过另一个权重矩阵W'(N×V矩阵)将隐藏层向量映射回V维空间,然后应用softmax函数计算每个词作为目标词的概率。
CBOW模型的训练目标是最大化观察到实际目标词的对数概率,通过反向传播算法调整权重矩阵W和W'的参数。训练完成后,矩阵W的行向量即为所需的词向量表示。
2.2 Skip-gram模型架构
与CBOW相反,Skip-gram模型根据当前中心词来预测其上下文词语。给定一个中心词,模型尝试预测其周围窗口大小为C内的每个上下文词。Skip-gram同样包含三层结构:
-
输入层:中心词的one-hot向量表示(V维)。
-
投影层:通过权重矩阵W将输入向量投影到N维隐藏层(实际上就是提取矩阵W中对应行的向量)。
-
输出层:对于窗口内的每个位置,通过权重矩阵W'计算每个词作为上下文词的概率。
Skip-gram模型的训练目标是最大化所有上下文位置预测到实际上下文词的对数概率之和。实践表明,Skip-gram通常在生僻词和小数据集上表现更好,而CBOW在频繁词和大数据集上训练更快。
2.3 技术实现与优化
Word2Vec在技术实现上采用了多项创新性优化策略,使其能够高效处理海量文本数据:
-
层次Softmax:替代传统softmax的计算密集型操作,使用霍夫曼编码树将复杂度从O(V)降低到O(log(V))。高频词拥有更短的路径,进一步加速训练。
-
负采样:通过随机采样少量"负样本"(非目标词)来近似整个词汇表的概率分布,大幅减少计算量。负采样技术不仅加速训练,还提高了词向量的质量。
-
高频词下采样:随机丢弃高频词(如"the"、"a"等)的训练实例,既能加速训练又能改善低频词的向量质量。
这些优化技术使得Word2Vec能够处理大规模语料库(如数十亿词汇),在单个机器上几天内完成训练,而之前的神经网络语言模型需要数周时间。
表:Word2Vec两种主要模型的比较
|
特性 |
CBOW模型 |
Skip-gram模型 |
|---|---|---|
|
训练目标 |
通过上下文预测中心词 |
通过中心词预测上下文 |
|
训练速度 |
较快(约快几倍) |
较慢 |
|
表现特点 |
对频繁词效果更好 |
对生僻词和罕见用法效果更好 |
|
数据效率 |
更适合大规模数据集 |
在中小规模数据集上表现良好 |
|
类比任务 |
在语法类比上表现稍好 |
在语义类比上表现更优 |
3 技术革新与性能表现
Word2Vec带来的技术革新不仅体现在模型架构上,更体现在其对自然语言处理研究范式的转变。论文通过系统实验证明了Word2Vec在语义和语法任务上的卓越表现。
3.1 语义语法关系捕捉
论文中最令人印象深刻的成果是展示了词向量空间能够捕捉丰富的语言学规律。通过简单的向量运算,可以发现诸如"国王" - "男人" + "女人" ≈ "女王"这样的语义关系,以及"big" - "bigger" + "smaller" ≈ "small"这样的语法关系。这种语义和语法规律的线性表征表明,Word2Vec学习到的向量空间具有良好的数学结构性质,各种语言学关系对应着向量空间中的特定方向。
论文采用了多种评估方法验证词向量质量:
-
语义合成任务:评估词向量在词语相似度和相关度任务上的表现,与人类判断高度相关。
-
语法准确性测试:专门设计测试集评估词向量捕捉语法关系(如形容词比较级、动词时态等)的能力。
-
大规模类比推理:包含语义和语法类别的综合测试集(如"德国" : "柏林" :: "法国" : ?)。
实验结果表明,Word2Vec在所有这些任务上都显著超越了先前的最佳方法,而且模型表现随训练数据量和向量维度增加而持续提升。
3.2 计算效率突破
Word2Vec的另一个突破在于其惊人的计算效率。通过优化算法和并行化训练,模型能够在合理时间内处理数十亿词汇的大规模语料库。相比之下,之前的神经网络语言模型(如Bengio2003年的模型)需要数周甚至数月才能完成训练,而Word2Vec仅需数天即可在普通硬件上处理相同规模的数据。
高效训练使得研究者能够探索大规模数据与模型性能之间的关系。论文发现,随着训练数据量的增加和词向量维度的提升,模型性能几乎呈对数线性增长,这表明更大的模型和更多的数据可以持续改进词向量质量。这一发现为后续大模型研究奠定了重要基础——扩展法则(Scaling Laws)的雏形已在此显现。
3.3 超参数影响分析
论文详细分析了不同超参数对模型性能的影响,为后续研究提供了重要指导:
-
向量维度:维度太低无法捕捉全部语义信息,太高则可能导致过拟合和计算浪费。300-500维通常在不同任务上表现稳健。
-
训练窗口大小:较小的窗口(约5)更倾向于捕捉语法关系,较大的窗口(约10-20)更倾向于捕捉语义关系。
-
训练数据量:性能随训练数据量增加而持续提升,几乎没有观察到平台期,表明更大规模数据仍有潜力。
4 影响与启示
《Efficient Estimation of Word Representations in Vector Space》这篇论文的影响远远超出了其本身的技术贡献,它实质上开创了自然语言处理的新范式,为后续一系列突破性进展奠定了基础。
4.1 对NLP领域的直接影响
Word2Vec的提出立即在NLP社区引起巨大反响,其影响主要体现在:
-
语义表示标准化:词向量成为NLP任务的标准输入特征,取代了传统的one-hot表示和手工设计特征。
-
迁移学习范式:预训练+微调的模式成为NLP新范式——先在大规模无标注文本上预训练词向量,然后在特定任务上用标注数据微调。
-
工具生态形成:Word2Vec的开源实现推动了整个NLP工具生态的发展,促进了研究者之间的合作与比较。
Word2Vec的成功也激发了研究者对词向量可视化技术的探索,如t-SNE降维可视化使得研究者能够直观观察词向量空间中的语义聚类结构。这种可视化不仅有助于理解模型行为,也为解释深度学习模型的"黑箱"提供了一条途径。
4.2 对后续技术发展的影响
Word2Vec的思想和技术直接启发了后续一系列重要发展:
-
GloVe模型:斯坦福团队2014年提出的GloVe模型结合了Word2Vec的局部窗口特性和全局矩阵分解的优点,进一步提升了词向量性能。
-
段落与文档向量:Word2Vec的扩展模型(如Doc2Vec)将词向量技术推广到更长文本的表示学习。
-
Word2Vec到BERT的演进:Word2Vec的预训练思想直接启发了ELMo、BERT等深度预训练模型的发展。BERT可视为Word2Vec思想在深度上下文条件下的扩展。
特别值得注意的是,Word2Vec揭示的缩放定律(Scaling Laws)——模型性能随数据和参数规模增加而持续提升——为大模型研究提供了关键理论支撑。OpenAI在2020年发表的《Scaling Laws for Neural Language Models》中系统阐述了这一规律,而这正是Word2Vec实验中早已观察到的现象的正式归纳与扩展。
4.3 局限性与发展
尽管Word2Vec取得了巨大成功,但其也存在一定局限性:
-
上下文无关表示:每个词被映射为单一固定向量,无法处理一词多义现象。
-
静态表征:无法动态适应语言使用的变化和新词义的出现。
-
窗口大小限制:基于局部窗口的训练方式难以捕捉长距离依赖和全局文档信息。
这些局限性正是后续研究(如ELMo、BERT等上下文敏感的词表示方法)试图解决的问题。BERT采用的双向Transformer架构能够根据上下文生成动态词表示,有效解决了一词多义问题。
5 总结与个人思考
《Efficient Estimation of Word Representations in Vector Space》这篇论文堪称自然语言处理领域的里程碑之作,其贡献不仅在于提出了高效训练词向量的技术方法,更在于开创了一种新的自然语言表示和学习范式。Word2Vec的成功证明了无监督学习在大规模文本数据上的巨大潜力,揭示了通过预训练从原始文本中自动获取语言知识的可行路径。
从更广阔的视角看,Word2Vec代表了表示学习革命的开端。它证明了神经网络能够自动学习数据的底层特征表示,而不依赖于手工设计的特征。这一思想后来扩展到计算机视觉、语音识别等多个AI领域,成为深度学习的重要支柱。
Word2Vec也预示了大模型发展的核心方向——缩放定律的重要性。论文中的实验清晰表明,随着模型规模和训练数据的增加,性能几乎持续提升,这一观察为后来千亿参数级别的大模型研究提供了信心和方向。当今的GPT、BERT等大型语言模型均可视为Word2Vec思想在尺度上的极致扩展和架构上的深度演进。
最后,Word2Vec的魅力还在于其简洁性与强大性的统一。相比后来复杂的深度网络架构,Word2Vec模型本身相当简洁优雅,但其产生的结果却如此强大且富有洞察力。这种简洁而强大的特性正是优秀科学工作的标志,也值得我们在科研工作中学习和借鉴。
表:Word2Vec在大模型技术演进中的历史地位
|
发展阶段 |
代表模型 |
主要创新 |
局限性 |
|---|---|---|---|
|
词向量革命 |
Word2Vec (2013) |
分布式词表示、高效训练方法 |
上下文无关、静态表征 |
|
序列建模 |
Seq2Seq (2014) |
编码器-解码器架构、注意力机制 |
固定长度向量瓶颈 |
|
Transformer架构 |
Transformer (2017) |
自注意力机制、并行化训练 |
计算复杂度随序列长度平方增长 |
|
预训练范式 |
BERT/GPT (2018) |
深度双向表征、生成式预训练 |
计算资源需求高、微调成本 |
|
缩放定律 |
GPT-3/PaLM (2020-) |
极致缩放参数与数据量、涌现能力 |
训练成本极高、难以解释 |
通过对这篇论文的深入阅读和思考,我更加清晰地认识到技术发展的连续性与突破性之间的关系。伟大的创新往往不是完全凭空产生,而是建立在深刻理解现有技术局限性基础上,提出简洁而有效的解决方案。Word2Vec的启示在于,有时候关键性的突破并不来自于复杂的算法设计,而是来自于对问题本质的深刻洞察和勇于摒弃传统框架的勇气。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)