AI学习日记——过拟合
·
目录
一、拟合
1.过拟合&欠拟合
过拟合(Overfitting)指模型在训练数据上表现良好,但在测试数据或新数据上表现较差,通常因为模型过于复杂,学习了训练数据中的噪声和细节。对应图3
欠拟合(Underfitting)指模型在训练数据和测试数据上均表现不佳,通常因为模型过于简单,未能捕捉数据中的关键模式。对应图1
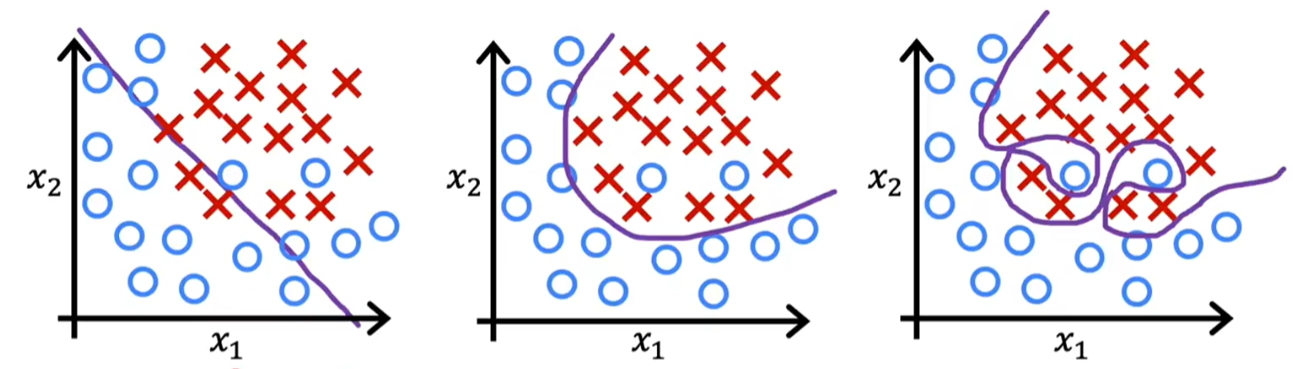
2.解决过拟合问题
(1)获取更多的训练数据
(2)筛选更相关的特征集
缺点:可能会丢失一些有效信息
(3)使用正则化减少参数值
定义:通过向损失函数添加惩罚项来限制模型复杂度。它在训练过程中约束模型参数,使其趋向于较小的值,从而提高泛化能力。
如下图,如果我认为x3和x4与结果没有那么强相关,我就把其对应的参数值调低
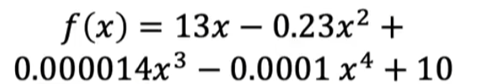
3.带正则化的损失函数
为了消除某一项特征对结果的影响,我们把对应项的参数减小,可以通过在损失函数中加对应特征的正则项来实现【损失函数越小越好】
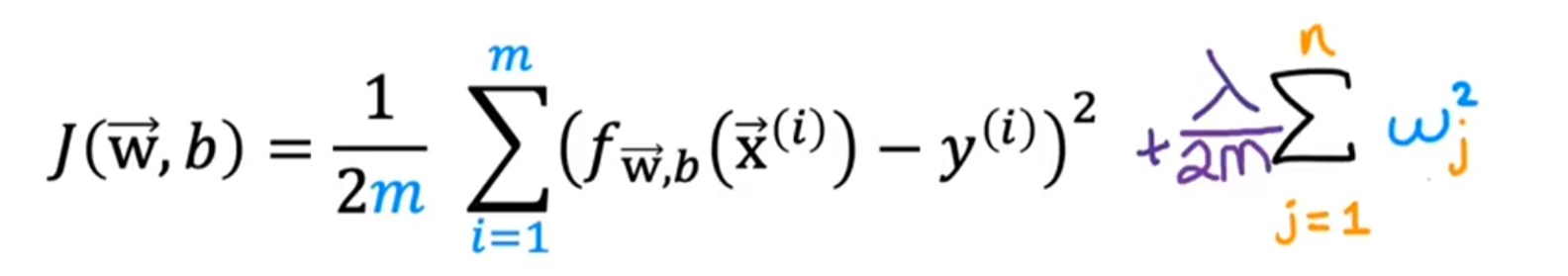
:正则化参数(如同梯度下降法的步长/学习率
)
正则项中的1/2m是什么作用?
一是为了和第一项保持特征缩放一致,二是为了在样本数量增加的情况也不会影响
总结
以上就是今天学习的内容,本文简单介绍了过拟合的概念与解决办法,并展开了一下正则化损失函数的学习

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)