全文分析 e-GPU -- An Open-Source and Configurable RISC-V Graphic Processing Unit for TinyAI Applications
tiny gpu:skybox:ventus gpgpu:vortex gpgpu:virgo gpu:e-GPU:一个用于 TinyAI 应用的开源可配置 RISC-V 图形处理单元图形处理单元(GPU)擅长并行处理,但由于其功耗和面积限制,以及缺乏合适的编程框架,在超低功耗边缘设备(TinyAI)中仍未得到充分探索。为了应对这些挑战,本工作介绍了嵌入式 GPU(e-GPU),一个专为 Tiny
tiny gpu:
https://github.com/Kleenelan/tiny-gpu/tree/masterskybox:
https://github.com/vortexgpgpu/skyboxventus gpgpu:
https://github.com/THU-DSP-LAB/ventus-gpgpuvortex gpgpu:
https://github.com/vortexgpgpu/vortexvirgo gpu:
https://github.com/ucb-bar/virgo
e-GPU:一个用于 TinyAI 应用的开源可配置 RISC-V 图形处理单元
摘要
图形处理单元(GPU)擅长并行处理,但由于其功耗和面积限制,以及缺乏合适的编程框架,在超低功耗边缘设备(TinyAI)中仍未得到充分探索。为了应对这些挑战,本工作介绍了嵌入式 GPU(e-GPU),一个专为 TinyAI 设备设计的开源可配置 RISC-V GPU 平台。其广泛的可配置性支持对面积和功耗进行优化,同时一个专用的 Tiny-OpenCL 实现提供了一个为资源受限环境量身定制的轻量级编程框架。为了展示其在真实场景中的适应性,我们将 e-GPU 与可扩展异构能效平台(X-HEEP)集成,以实现用于 TinyAI 应用的加速处理单元(APU)。所提出的系统具有多种 e-GPU 配置,在台积电(TSMC)16 nm SVT CMOS 工艺中实现,并在 300 MHz 频率和 0.8 V 电压下运行。我们分析了它们的面积和漏电特性,以确保符合 TinyAI 的限制。为了评估运行时开销和应用级效率,我们采用了两个基准测试:通用矩阵乘法(GeMM)和生物信号处理(TinyBio)工作负载。GeMM 基准测试用于量化 Tiny-OpenCL 框架引入的调度开销。结果表明,对于大于 256×256 的矩阵大小(或等效问题大小),该延迟变得可以忽略不计。然后使用 TinyBio 基准测试来评估基线主机的性能和能量改进。结果表明,具有 16 个线程的高端 e-GPU 配置可实现高达 15.1 倍的加速,并将能耗降低高达 3.1 倍,同时仅产生 2.5 倍的面积开销,并在 28 mW 的功率预算内运行。
关键词: 超低功耗,开源,图形处理单元,微控制器,人工智能。
I 引言
对基于机器学习的实时计算日益增长的需求推动了边缘计算的快速扩张。通过本地处理数据而非依赖云服务器,边缘计算减少了延迟、增强了隐私性并提高了能效,使其成为众多边缘应用的理想解决方案。然而,这些工作负载对计算性能、实时响应能力和功耗提出了限制,因此需要专门的硬件架构 [1]。
应对这些挑战的一个有前景的方法是采用异构架构,该架构将主机中央处理单元(CPU)与特定领域的加速器集成,以平衡效率和性能 [2, 3]。在这些加速器中,图形处理单元(GPU)已被证明在利用数据并行性执行机器学习和信号处理任务方面特别有效。当与主机 CPU 结合时,GPU 形成加速处理单元(APU),实现了一个统一的平台,能够高效处理通用任务和计算密集型工作负载。
虽然存在从高性能到嵌入式解决方案的各种 GPU 实现,但它们在超低功耗边缘设备(TinyAI)背景下的权衡取舍仍未得到充分探索。这些电池供电的设备在严格的功率约束下运行(通常在几十毫瓦范围内),需要高效的 GPU 架构。它们的小尺寸也施加了严格的面积限制,整个片上系统(SoC)仅占用几平方毫米。此外,缺乏文件系统和多线程支持阻止了传统 GPU 编程框架(例如标准开放计算语言(OpenCL)实现 [4])的使用,因此需要自定义优化。
由于上述限制,超低功耗设备通常依赖于专门的加速器,例如粗粒度可重构阵列(CGRAs)[5, 6]、脉动阵列 [7]、近内存 [8] 或内存计算 [9] 解决方案,而 GPU 在该领域的潜力仍未得到充分探索。
本工作通过引入一个开源可配置的 RISC-V 平台——嵌入式 GPU(e-GPU),探讨了将 GPU 用于 TinyAI 应用的可行性及相关权衡。该平台广泛的可配置性支持对面积和功耗进行优化,以满足该领域的要求。此外,一个定制的微型开放计算语言(Tiny-OpenCL)实现克服了上述限制,并提供了一个专门为资源受限设备开发的轻量级编程框架。为了展示所提出平台在真实场景中的适应性,我们将 e-GPU 与可扩展异构能效平台(X-HEEP)[10, 11] 集成,以实现用于 TinyAI 工作负载的 APU。
所提出的系统具有多种 e-GPU 配置,在台积电(TSMC)16 nm SVT CMOS 工艺中实现,并在 300 MHz 频率和 0.8 V 电压下运行。我们分析了它们的面积和漏电特性,以确保符合 TinyAI 的限制。为了评估运行时开销和应用级效率,我们采用了两个基准测试:通用矩阵乘法(GeMM)和生物信号处理(TinyBio)工作负载。GeMM 基准测试用于量化 Tiny-OpenCL 框架引入的调度开销,而 TinyBio 基准测试则用于评估相对于基线主机的性能和能量改进。
这项工作的主要贡献如下:
-
我们主张将特定领域的 GPU 作为 TinyAI 领域的合适解决方案。
-
我们提出了 e-GPU [12],一个为 TinyAI 工作负载设计的开源可配置 RISC-V GPU 平台。
-
我们分析了该应用领域的编程限制,并引入了一个用于资源受限设备的 Tiny-OpenCL 框架。
-
我们探讨了将 GPU 用于 TinyAI 应用的可行性和权衡。
-
我们发布了一个开源代码库,包括完整的 e-GPU¹,以允许研究人员为该平台适配其 TinyAI 领域。
本文的其余部分组织如下。第 2 节讨论了相关工作。第 3 节总结了背景概念。第 4 节描述了 e-GPU 硬件,而第 5 节重点介绍 e-GPU 软件。第 6 节解释了与主机的集成。第 7 节概述了实验设置,第 8 节展示了实验结果。最后,第 9 节对本文进行了总结。
II 现有技术
本节分析了与我们平台设计选择相关的最重要的商业和学术 GPU 解决方案。
II-A 商业 GPU
商业边缘 GPU 的格局多种多样,解决方案在性能和能效之间取得平衡。高通(Qualcomm)的 Adreno GPU 集成于骁龙(Snapdragon)SoC 中,为移动和边缘应用实现高能效计算。特别是 Adreno 600 系列,广泛用于机器学习推理,采用了先进的节能机制。类似地,ARM 的 Mali GPU 嵌入在各种 SoC 中,并已演变为具有功耗优化架构。Mali-G52 和 Mali-G72 系列中的细粒度电源门控等创新提高了能效,使其适用于低功耗场景。另一个关键参与者是 Imagination Technologies 的 PowerVR GPU,其优先考虑高能效性能,Series8XT 在边缘设备中展示了有竞争力的计算能力。
尽管取得了这些进步,商业 GPU 并非专为 TinyAI 应用设计。它们的功耗通常从几百毫瓦到几瓦不等,超出了这些应用对功耗(几十毫瓦级别)的严格要求。此外,这些 GPU 的专有性质阻止了详细的性能和功耗特性分析,限制了它们在研究和能效设计探索中的使用。
II-B 学术 GPU
学术界的 GPU 研究侧重于为各种计算领域开发可编程和可配置的架构。表 I 基于六个基本特性比较了 GPU 平台:(1) 开源代码以便快速获取,(2) 开源指令集架构(ISA)以便轻松自定义扩展,(3) 可配置性以适应特定应用需求,(4) 可综合的寄存器传输级(RTL)代码以便进行准确的性能和功耗评估,(5) 与主机 CPU 的集成能力以研究 CPU-GPU 交互,以及 (6) 针对 TinyAI 应用的超低功耗设计。
学术 GPU 解决方案范围从软件模拟器到硬件实现。
II-B1 软件模拟器
GPGPU-Sim [13] 对基于 CUDA 的 GPU 进行建模,模拟 NVIDIA Fermi 和 GT200 等架构。gem5-gpu [14] 通过集成 gem5 [15] 的 x86 CPU 和内存模型对此进行了扩展,便于研究 CPU-GPU 交互。另一个例子是 Multi2Sim [16],它模拟 AMD Evergreen GPU 系列以及多线程 x86 处理器。
虽然软件模拟器有助于快速进行架构探索,但它们对 TinyAI 研究存在显著局限性,包括缺乏可综合的 RTL 代码(这阻止了准确的功率和能量分析),缺乏开源 ISA(限制了扩展机会),以及它们主要关注高性能计算,使其不适用于超低功耗边缘应用。
II-B2 硬件实现
一些学术 GPU 项目提供了可综合的 RTL 代码,为功率和性能指标提供了更深入的见解。Skybox [17] 是一个专为图形研究设计的 RISC-V GPU 框架,支持 Vulkan API。然而,它依赖基于 PCIe 的与主机 PC 的通信,使其不适合集成到 SoC 中(SoC 常用于超低功耗应用)。ZJX-RGPU [18] 将 RISC-V CPU 和片段引擎集成到一个 12.25 mm² 的芯片中,在 200 MHz 下运行,功耗约为 20 mW,但其闭源性质和有限的文档限制了其在架构探索中的使用。
Vortex [19] 代表了一项重大进步,它是一个支持 OpenCL 和 OpenGL 的可配置 RISC-V GPU。使用 15 nm 教育版单元库综合单个计算单元,在 300 MHz 下消耗 46.8 mW。然而,其硬件未经大量修改无法本地综合,并且它针对 PC 级主机环境。这些特性阻碍了其集成到 SoC 中,而对于超低功耗应用,轻量级互连和紧密的硬件-软件耦合至关重要。
METASAT 平台 [20] 将 Vortex 适配用于一个安全关键的 RISC-V SoC,将其与 NOEL-V 处理器和 SPARROW 单指令多数据(SIMD)加速器集成。该平台设计为在 RTEMS 和 XtratuM 管理程序下运行,消除了 OpenCL 依赖,并使得 GPU 可在分区实时环境中使用。然而,其 GPU 继承了 Vortex 的局限性,并且仅作为将 GPU 集成到未来空间系统的概念验证,而非解决以能效为首要关注点的 TinyAI 计算的方案。
Virgo [21] 基于 Vortex 构建,引入了一种具有集群级矩阵单元的解聚式 GPU 架构,与核心耦合设计相比,提高了数据复用并降低了能耗。虽然 Virgo 实现了高能效并且完全开源,但它针对大规模 GEMM 操作和数据中心级的深度学习工作负载,限制了其在问题规模较小的 TinyAI 场景中的灵活性。此外,Virgo 依赖相对复杂的内存层次结构和跨计算单元的复杂同步机制,这可能难以适应具有严格面积和功耗限制的极简 SoC 设计。
Ventus [22] 基于 RISC-V 向量扩展(RVV)构建,并引入了一种高性能 GPGPU 架构,具有用于单指令多线程(SIMT)执行、谓词分支、同步和张量操作的自定义指令。它可扩展至 16 个计算单元和 256 个 warp(线程束),与 Vortex 相比,展示了高达 87.4% 的 CPI(每条指令周期数)降低和 83.9% 的指令数减少。然而,Ventus 专为部署在大规模 FPGA 上而设计,并未集成到 SoC 中,目标是 PC 级主机。尽管使用台积电 12 nm 库报告了综合结果以进行频率和面积评估,但未提出低功耗或流片优化。因此,Ventus 针对高吞吐量应用和架构研究,而非 TinyAI 场景。
TABLE I: Comparison of relevant academic GPU platforms based on key features.
| GPU Platform | Open-source | Open ISA | Configurable | Synthesizable | Integrable | Ultra-low-power |
| GPGPU-Sim [13] | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ |
| gem5-gpu [14] | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ |
| Multi2Sim [16] | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ |
| Skybox [17] | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| ZJX-RGPU [18] | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| Vortex [19] | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
| METASAT [20] | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ |
| Virgo [21] | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ |
| Ventus [22] | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| Proposed e-GPU | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
III 背景
本节根据标准 OpenCL 定义总结了所需术语。这些术语按照平台模型、执行模型和运行时模型进行组织。平台模型定义了主机系统与负责执行内核的计算设备之间的关系。执行模型描述了内核如何启动,以及工作项(work-item)和工作组(work-group)如何组织并在可用硬件上执行。最后,运行时模型规定了内核执行在硬件级别的行为,包括线程调度、同步和执行资源的利用。
III-A 平台模型
在平台模型中,主机(host)指运行 OpenCL 主机代码的主要系统(通常是 CPU),负责跨计算设备管理和分派内核执行。设备(device)是执行 OpenCL 内核的加速器(例如 GPU)。每个设备由一个或多个计算单元(compute unit)组成,计算单元是负责执行工作组(work-group)的架构块。计算单元内有多个处理元素(processing element),它们是最低级别的执行资源,执行工作项(work-item)的算术和逻辑操作。
III-B 执行模型
执行模型管理计算的组织和启动方式。主机代码(host code)从主机端协调执行过程,向设备发出命令并管理数据传输。内核(kernel)是在计算设备上运行的 OpenCL 函数,由许多工作项并行执行。每个工作项(work-item)对应内核执行的一个实例,并处理输入数据的不同部分,由唯一的全局 ID 标识。工作项被分组为工作组(work-group),工作组被分配给计算单元。组内的工作项可以通过本地内存(local memory)共享数据,并使用屏障(barrier)彼此同步。全局大小(global size)指定要启动的工作项总数,而本地大小(local size)决定其中有多少个工作项被分到每个工作组中。
III-C 运行时模型
运行时模型描述了内核在硬件级别如何执行。一个线程(thread)代表在处理元素上运行的一个内核实例,维护其自己私有的寄存器集。线程通常被分组为 warps(线程束),这些线程束是锁步(lockstep)执行的线程集合,意味着它们共享相同的程序计数器并同时执行相同的指令。根据硬件能力,多个 warp 可能在流水线中同时处于活动状态,从而实现细粒度并行并有效利用执行资源。
IV e-GPU 硬件
本节描述了 e-GPU 架构以及旨在最小化面积、功耗和能量消耗的软硬件协同设计决策,同时使平台适应 TinyAI 领域。图 1 展示了所提出的 e-GPU 的架构,而表 II 列出了可通过 SystemVerilog 参数访问的可用可配置选项。
IV-A 计算单元
计算单元基于 Vortex 核心 [19]。它采用乱序执行的 RISC-V 架构,具有内部可配置选项,允许调整并行线程和并发 warp。调整线程数量通过改变处理元素的数量来修改数据并行性,而配置 warp 数量则通过启用细粒度多线程使多个 warp 并发执行,从而增强资源和内存带宽利用率。
由于功耗和面积限制,我们移除了浮点单元,优先处理整数和定点算术运算,因为该平台目标是基于整数的 TinyAI 模型。此外,我们使用自定义的 SLEEP_REQ 指令扩展了 RISC-V ISA 以提高能效。在内核处理结束时,该指令等待所有先前获取的指令执行完毕,然后向 GPU 控制器生成一个事件,信号表示操作完成。此机制使得 GPU 控制器能够在计算单元不再使用时,通过时钟门控或电源门控(如果可用)立即将其关闭,从而提高整体能效。在设计时,可以配置计算单元的数量以权衡面积、功耗和处理需求。
IV-B 内存层次结构
内存层次结构采用统一架构,其中主机主内存和 e-GPU 全局内存映射到主机上的同一物理内存。这种共享内存模型通过消除在独立内存区域之间进行显式数据传输的需要,增强了可编程性。特别是,不再需要复杂的显式双缓冲方案来在主机主内存和 e-GPU 全局内存之间移动输入和输出数据。
每个计算单元包含一个私有指令缓存,以减少内存访问延迟并提高性能,同时一个共享数据缓存在所有计算单元之间使用。
缓存逻辑基于 Vortex 缓存 [19],具有直接映射、多存储体(multi-bank)架构和行交错(line-interleaved)寻址方案。对未完成请求(outstanding requests)的支持允许后续 warp 发出新的缓存访问,即使先前的 warp 因缓存未命中而停滞。在设计时,可以根据目标应用的具体要求调整缓存大小、存储体数量和行大小。我们集成了专用的内存包装器(memory wrapper),以便为每个指令存储体无缝实例化生产级 SRAM 宏。
每个计算单元都连接到一个私有指令缓存。当多个计算单元执行相同内核时,这种设计提高了随着计算单元数量增加的可扩展性,并避免了共享指令缓存可能产生的冲突。事实上,无法保证每个计算单元在每个时钟周期获取相同的指令。因此,拥有独立的私有指令缓存有助于减少未命中并减轻性能下降。此外,当不同的计算单元执行不同的内核时,独立的缓存提高了局部性。
在数据方面,所有计算单元共享一个公共数据缓存。这种设计在主机较慢的主内存和计算单元较快的寄存器文件之间提供了一个中间存储层,从而提高了数据访问效率。此外,使用共享缓存使得计算单元之间能够直接共享数据,而无需额外传输到主机主内存或从主机主内存传输出来。
输入数据在第一个内核开始时从主机加载到共享数据缓存中,并在中间内核的整个执行过程中保持可用(假设缓存足够大以容纳整个工作集)。这种方法通过最小化数据传输来提高性能,最终实现能效的提升。
最后,我们重新设计了数据缓存接口,以支持来自所有计算单元的多线程并行请求。每个计算单元发出多个同时请求(每个活动线程一个),但接收单个统一响应。根据请求线程的选择性掩码(selectively masked)输入和输出数据。这种对多维请求的支持通过在未发生存储体冲突时实现对共享缓存的并发访问,增强了带宽利用率。
在系统边界,内存接口有效地将缓存请求适配为主机内存事务。这些事务分三步管理。(1) 发生未命中时,缓存请求整个多字(multi-word)行,然后将其序列化为单独的 32 位事务。(2) 缓存协议被转换为 OBI [23] 协议,这是一种在边缘系统中广泛采用的低功耗总线协议。(3) 一个仲裁器 [24] 管理对共享输出端口的访问,确保公平有效的资源分配。
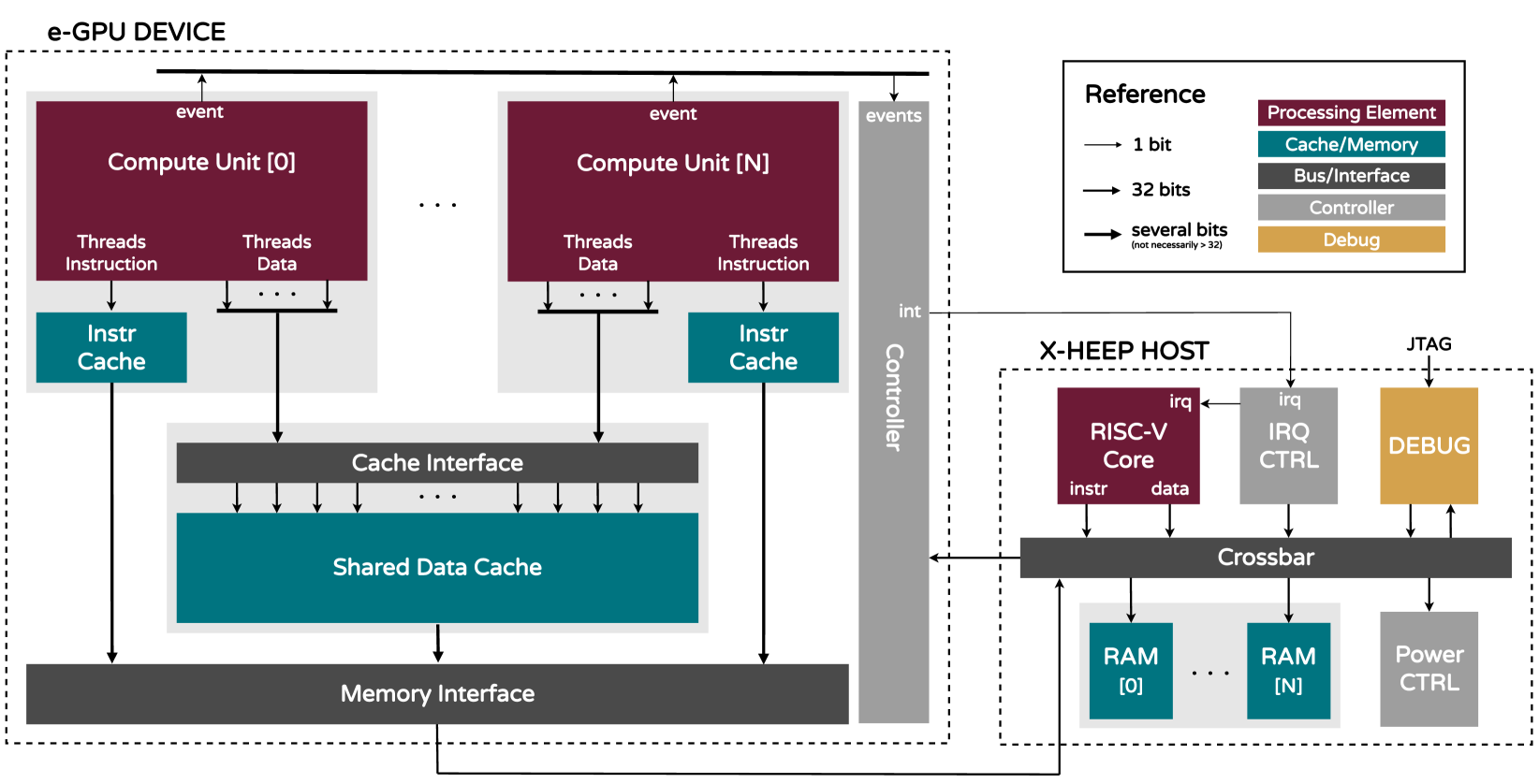
Figure 1: Architecture of the presented e-GPU platform and its integration with an X-HEEP host [10].
图 1: 所展示的 e-GPU 平台架构及其与 X-HEEP 主机 [10] 的集成。
IV-C 控制器
我们设计了一个专用控制器来管理 e-GPU 的操作。一组内存映射配置寄存器支持诸如重置、启动和停止加速器等操作。此外,该控制器集成了一个电源控制器,该控制器与第 IV-A 节中描述的低功耗 RISC-V 扩展协同工作。
在内核启动后,电源控制器监视来自每个计算单元的执行结束事件。一旦接收到事件,相应的计算单元就会被关闭。一旦接收到所有事件(表明所有计算单元已完成执行),控制器就会产生一个外部中断来通知主机 CPU。
V e-GPU 软件
本节描述了 Tiny-OpenCL 框架,这是一个轻量级且高度优化的 OpenCL 实现,旨在编译内核以在 e-GPU 上执行。该框架最大限度地提高了与现有 GPU 软件的兼容性,同时确保了跨平台的可移植性。
V-A Tiny-OpenCL 框架
该框架包括以下软件组件:(1) SIMT RISC-V 扩展 API [19],提供对低级计算单元功能的访问,例如激活和停用线程与 warp、通过分裂(splitting)和合并(joining)处理分支(divergences)以及管理同步屏障(barriers);(2) 启动函数(startup functions),负责初始化 e-GPU 并执行必要的设置操作,包括计算每个线程的栈指针;(3) 调度函数(scheduler functions),协调工作项在可用计算资源(计算单元、线程和 warp)上的执行,确保高效的工作负载分配。这些组件使用标准的 RISC-V GNU 工具链预编译成一个静态库。
随后,一个解析器脚本(parser script)会分析 OpenCL 内核,执行必要的代码转换,将其转换为具有等效功能的标准 C 函数。然后可以使用 RISC-V GNU 工具链编译此 C 函数以生成相应的目标文件。这些转换实现了与现有编译工具的无缝集成,消除了对专用编译器的需求。在内核被处理并编译后,将其与 Tiny-OpenCL 静态库链接以生成最终的二进制文件。
在内核地址空间中,保留了一个内存区域用于存储内核参数(kernel arguments),这些参数由主机在执行前写入。这些参数包括执行参数,例如全局和本地大小、指向输入和输出缓冲区的指针以及其他配置细节。
为了增强灵活性,该框架允许用户自定义表 II 中列出的参数。这些参数包括内核的基地址,该地址用作 e-GPU 的启动地址,并允许执行位于系统内任何地址偏移处的内核。线程栈的位置和大小也可以配置,确保根据目标应用的具体要求进行正确的映射和大小调整。
V-B Tiny-OpenCL 执行
在第 VI-C 节描述的、运行在主机上的 OpenCL 运行时(runtime)启动 e-GPU 加速后,内核执行开始并经历三个阶段:启动(startup)、调度(scheduling)和处理(processing)。
在启动阶段,每个计算单元以单线程模式执行,意味着只有一个线程和一个 warp 处于活动状态。在此阶段,执行启动函数来初始化系统。这包括激活所有并行线程和并发 warp,并为每个线程和 warp 设置资源(如栈指针)。初始化完成后,计算单元返回到单线程模式,调度阶段开始。
在调度阶段,调用调度函数。这些函数从内核参数区域读取全局和本地大小,以确定工作组(work-group)的数量和每个组中的工作项(work-item)数量。这些值与从控制和状态寄存器(CSRs)中检索到的硬件资源信息(计算单元、线程和 warp)相结合。基于这些数据,调度函数激活必要的资源并将工作项分配到可用线程上,以最大化并行性并最小化执行时间。此外,它们会停用未使用的资源以降低功耗并提高整体能效。
一旦工作项在线程上启动,处理阶段就开始了。在此阶段,用户定义的内核执行目标算法。从内核参数区域获取输入和输出参数,工作项根据其全局 ID(可以表示为一维或二维索引)计算其特定的数据部分。由于调度函数预先执行了边界检查,用户内核无需处理此类逻辑。
TABLE II: Configurability knobs of the presented e-GPU platform.
| Hardware |
| • Number of compute units (CUs). |
| • Number of threads running in parallel on each CU. |
| • Number of warps running concurrently on each CU. |
| • Size of the instruction cache. |
| • Number of banks in the instruction cache. |
| • Line size of the instruction cache. |
| • Size of the data cache. |
| • Number of banks in the data cache. |
| • Line size of the data cache. |
| Software |
| • Base address of the kernel. |
| • Base address of the stacks. |
| • Size of the stacks. |
VI APU 系统
本节描述了如何将 e-GPU 与主机集成以实现用于 TinyAI 应用的 APU。本节首先详细介绍 e-GPU 接口,然后介绍所选的主机系统及其配置。最后,介绍了一个轻量级的主机端 Tiny-OpenCL 运行时,该运行时是为了克服资源受限设备固有的编程限制而开发的。
VI-A e-GPU 接口
e-GPU 暴露了以下端口:(1) 一个从(slave)OBI 端口,用于配置;(2) 一个主(master)OBI 端口,用于向主机主内存读写内核指令和数据;(3) 一条连接到主机中断控制器的中断线,用于在内核完成时通知 CPU。
e-GPU 在一个专用的电源域内运行,支持细粒度的电源管理。时钟门控(Clock-gating)在短暂空闲期间降低功耗,而电源门控(power-gating)在长时间不活动时完全关闭加速器。这些机制的控制信号连接到主机电源管理器,确保高效和自主的能量管理。
VI-B 主机配置
选择 X-HEEP [11, 25, 26] 系统作为平台的主机,因为其可配置和可扩展的架构便于加速器集成。所选配置包括:(1) 一个轻量级 CPU [27],经过优化以执行控制任务,同时将性能密集型计算卸载到加速器,确保低功耗;(2) 两个 32 KiB 的 SRAM 存储体,配置为连续寻址模式,允许为 CPU 和加速器单独分配内存,减少访问冲突;(3) 一个全连接交叉开关(crossbar),提供高带宽数据传输能力;(4) 一个中断控制器,用于管理内部和外部中断;(5) 一个电源控制器,负责管理内部和外部的节能策略,包括时钟门控和电源门控;(6) 一个调试单元,用于通过 JTAG 进行完整的系统控制;(7) 可扩展加速器接口(XAIF),配置有一个 OBI 主端口、一个 OBI 从端口和一个中断接口,用于连接 e-GPU 的相应端口。图 1 详细说明了连接细节。
VI-C Tiny-OpenCL 运行时
标准的开源 OpenCL 实现(例如 PoCL [4])需要一个能够运行操作系统的主机来支持其运行时,该运行时与加速器交互并控制它们。然而,X-HEEP 是一个 RISC-V 微控制器,缺乏运行像 Linux 这样的操作系统所需的 ISA 支持。相反,它依赖 Newlib [28]——一个为边缘系统优化的开源 C 标准库,它提供了一整套基本功能,包括 I/O、内存和字符串实用程序,通常在缺乏文件系统和多线程支持的完整操作系统时使用。
由于没有文件系统,主机应用程序必须编译成单个二进制文件,消除了动态库链接的需要。同样,由于缺乏多线程,主机应用程序必须在单线程中执行。
为了克服这些限制,第 V 节介绍的 Tiny-OpenCL 框架扩展了一个专为支持 Newlib 的微控制器(如 X-HEEP)设计的专用运行时。该运行时使用标准的 GNU RISC-V 工具链编译,并实现了标准 OpenCL 运行时 API 的一个子集。这些函数提供了从主机对 e-GPU 的完全控制,包括初始化数据缓冲区、配置内核参数、分派内核以及通过等待操作完成来进行同步。
VII 实验设置
本节介绍了我们实验所选的 e-GPU 配置。然后介绍了采用的基准测试,选择这些基准测试是为了展示所提出平台对代表性 TinyAI 应用领域(生物信号处理)严格要求的适应性。随后,详细说明了我们系统的实现,并描述了用于提取性能、功耗和面积指标的方法。
VII-A e-GPU 配置
所选配置总结在表 III 中。每个实例包括两个计算单元和数量递增的并行线程(每个计算单元从 2 个到 8 个)。这种设置为内核执行提供了足够的性能,同时在面积和功耗之间保持了平衡。为了隐藏内存访问延迟,每个计算单元配备了 4 个并发 warp。鉴于共享数据缓存的访问延迟为 4 个周期,此配置允许缓存流水线填充 4 个未完成请求(outstanding requests),从而实现每个周期一次访问的最大吞吐量。
指令缓存采用单存储体(single-bank)配置。这种安排具有面积和功耗效率,有助于提高整体能效。16 字节(四条指令)的行大小(line size)最大限度地提高了空间局部性并增强了内核代码的预取,而 4 KiB 的总指令缓存大小(每个计算单元 2 KiB)确保了我们基准测试中的每个内核都能容纳得下。
共享数据缓存采用具有行交错(line-interleaved)寻址的多存储体(multi-bank)配置。它有两个存储体,每个计算单元一个,以最大化并行访问效率。行大小设置为 T x 4 字节,其中 T 表示每个计算单元的并行线程数。这种设计允许所有线程在访问连续内存位置时同时读取数据,因为一次缓存行读取就足够了。最后,提供了 16 KiB 的总数据缓存大小以适应所需的内核数据,从而最大限度地减少缓存和主机主内存之间的流量。
VII-B 基准测试
采用了两个基准测试:GeMM 和 TinyBio 工作负载。GeMM 基准测试包括大小递增的通用矩阵乘法内核,范围从 32×32 到 256×256。相比之下,TinyBio 领域包括为分析从人体获取的生物信号并提取有意义的特征而开发的内核 [29, 30]。其中,我们选择了 MBio-Tracker 应用 [31],该应用是专门为测量认知负荷(cognitive workload)而开发的。该应用具有一个四阶段的流水线:预处理(pre-processing)、描绘(delineation)、特征提取(feature extraction)和预测(prediction)。这些异构内核包含了各种具有不同复杂性和内存需求的算法,使其成为我们实验的合适选择。
在预处理阶段,对原始输入数据应用有限脉冲响应(FIR)滤波器。在描绘阶段,识别滤波后信号的波峰和波谷以确定吸气和呼气时间。然后使用提取的值计算时域特征,例如均值、中位数和均方根(RMS),而频域特征通过对滤波后的信号执行 Stockham 快速傅里叶变换(FFT)来获得。最后,使用支持向量机(SVM)算法来估计认知负荷。
VII-C 方法学
每个系统均使用台积电(TSMC)16 nm FinFET SVT CMOS 工艺进行综合,在 300 MHz 频率和 0.8 V 电压下运行。进行综合后仿真(post-synthesis simulations)以提取开关活动(switching activity)用于功耗分析。然后使用这些数据来估算能耗。
TABLE III: Selected system configurations for our experiments.
| Metric | e-GPU 4T | e-GPU 8T | e-GPU 16T |
|---|---|---|---|
| Compute Units | 2 | ||
| Parall. Threads | 2 xCU | 4 xCU | 8 xCU |
| Concur. Warps | 4 xCU | ||
| I-Cache Size | 2 KiB/ xCU | ||
| I-Cache Banks | 1 xCU | ||
| I-Cache Line | 16 B/ xCU | ||
| D-Cache Size | 16 KiB/ | ||
| D-Cache Banks | 2 | 4 | 8 |
| D-Cache Line | 8 B/ | 16 B/ | 32 B/ |
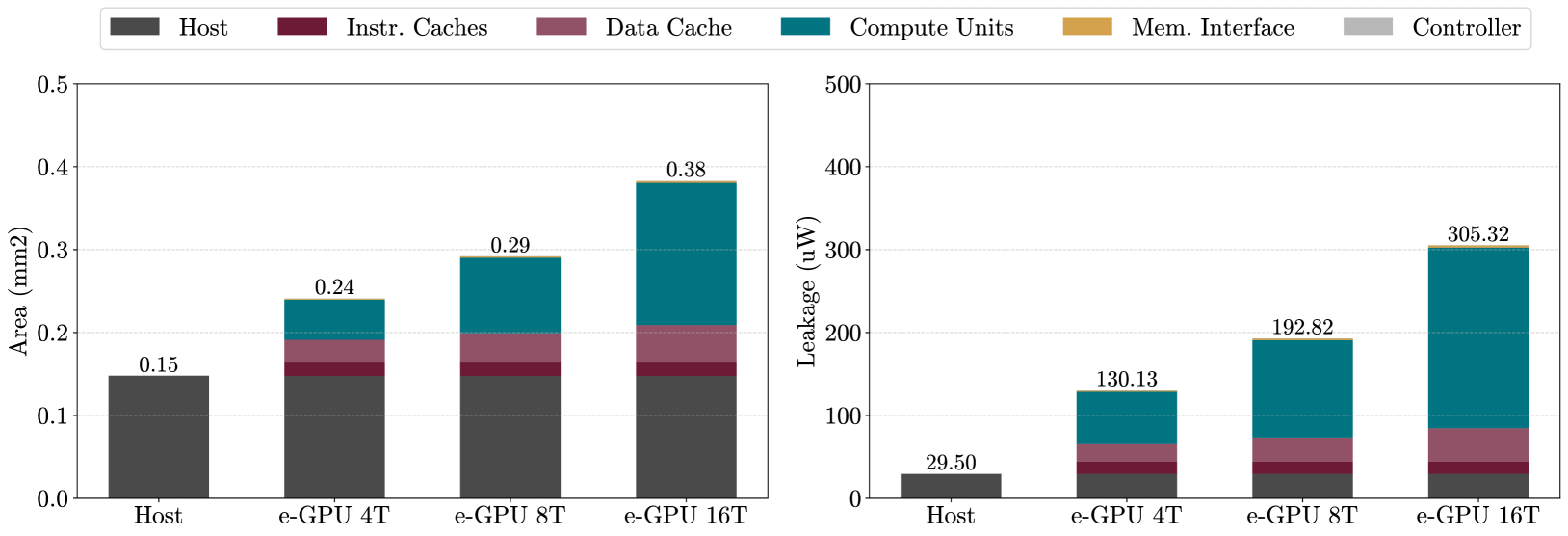
Figure 2: Breakdown of area and leakage power for the selected e-GPU systems compared to the baseline host system.
图 2: 所选 e-GPU 系统与基线主机系统相比的面积和漏电功耗分解。
VIII 实验结果
本节展示并分析了我们的实验结果。首先是对每个系统的静态特性分析,接着检查与使用 e-GPU 相关的开销。然后,我们介绍了 TinyBio 基准测试的特性分析。最后,通过整体讨论强调了有效利用每个系统的权衡取舍。
VIII-A 静态特性分析
图 2 显示了所分析系统的面积分解。e-GPU 系统的总面积范围从 0.24 mm² 到 0.38 mm²。这些结果证明了所提出系统部署在 TinyAI 应用中的可行性,因为目标设备的小尺寸施加了严格的面积限制,整个 SoC 通常仅限于几平方毫米。此外,与占用 0.15 mm² 的独立主机系统相比,e-GPU 仅引入了 1.6 倍到 2.5 倍的面积开销,同时在运行 TinyBio 基准测试时提供了高达 3.6 倍到 15.1 倍的加速,如图 4 所示。
分解对总面积的贡献,指令缓存在所有 e-GPU 配置中保持不变。这是预期的行为,因为指令缓存在增加线程数和性能时未被修改或缩放。
相比之下,数据缓存的面积略有增加,尽管其总容量在配置之间保持不变。这种增加是由于内存层次结构的调整旨在更高水平的并行性(即更高的线程数)下最大化内存访问带宽。具体来说,需要更多的缓存端口(每个线程一个端口)和更大的缓存行(每个线程一个字)。通过增加存储体数量来实现更大的行大小:4 线程 e-GPU 有两个存储体,8 线程版本有四个存储体,16 线程版本有八个存储体。分成几个子存储体相对于具有相同总大小的单个存储体而言,面积效率较低。
最后,计算单元的面积显著增长,并且它们的贡献随着性能配置的提升几乎翻倍。这种增长反映了集成额外资源的需要,例如更多的算术单元、更大的寄存器文件和扩展的控制逻辑,以有效支持更多数量的并行线程。
分析漏电功耗时观察到类似的趋势,如图 2 所示。e-GPU 系统的漏电范围从 130.13 µW 到 305.32 µW,与消耗 29.50 µW 的独立主机系统相比,有 4.4 倍到 10.3 倍的开销。这进一步证明了所提出设计对于 TinyAI 应用的适用性,这些应用中电池供电的设备必须遵守严格的功率预算(通常为几十毫瓦级别)。
总体而言,面积和漏电分析一致表明,最显著的变化集中在计算单元内部,而缓存除数据缓存的适度调整外保持相对稳定。这些结果突显了所提出的 e-GPU 架构的可扩展性,证实了其在严格的 TinyAI 部署约束下(如图 4 所示),能够有效地权衡面积和漏电开销以换取显著的性能增益。
VIII-B 开销特性分析
图 3 显示了在选定的 e-GPU 系统上执行的、大小递增的矩阵乘法的开销与计算时间的分解。
考虑了两种类型的开销:传输(transferring)和调度(scheduling)。传输指的是用内核数据填充数据缓存所花费的时间。这在内核执行之前发生,数据以 32 位/周期的带宽从主机内存移动到 e-GPU 缓存。假设缓存足够大以容纳整个工作集,则传输的数据在后续内核执行期间保持驻留,从而提高了性能和能效。对于高端 e-GPU 系统,这种传输延迟随着矩阵大小的增加而增加,从大约 27 µs 到 1.7 ms,因为必须传输 progressively more 的数据。
在固定的矩阵大小下,使用更多并行线程提高性能会导致传输时间略有减少。这种效应可归因于 progressively larger 的缓存行,这使得每次读未命中时可以将更多数据预取到数据缓存中。因此,计算和数据传输之间的重叠增加,减少了仅用于数据移动的时间比例。
总体而言,传输开销稳定在略高于执行时间的 20%,因为传输时间的增加被由于 progressively higher 性能而减少的计算延迟所补偿。
与传输互补,调度表示分配计算资源并将工作项分配给它们所需的时间。e-GPU 依赖第 V 节描述的 Tiny-OpenCL 框架提供的运行时调度(run-time scheduling)。随着工作项数量的增加,这种开销变得更加明显,因为必须对可用资源执行更多次迭代。
在我们的实验中,我们配置了矩阵乘法内核,使工作项的数量与可用线程的数量(计算单元 × 并发 warp × 并行线程)相匹配。这种方法优化了调度时间并提高了整体内核性能。因此,调度时间保持恒定在大约 25 µs,无论系统性能或矩阵大小如何增加。
然而,它对总执行时间的相对贡献随着问题规模的增加而减少,从大约 15% 到不到 1%。这证明了所提出的 Tiny-OpenCL 框架的可行性,该框架提供了高度的灵活性和改进的可编程性,对于大于 256×256 的矩阵大小(或等效问题大小),开销可以忽略不计。
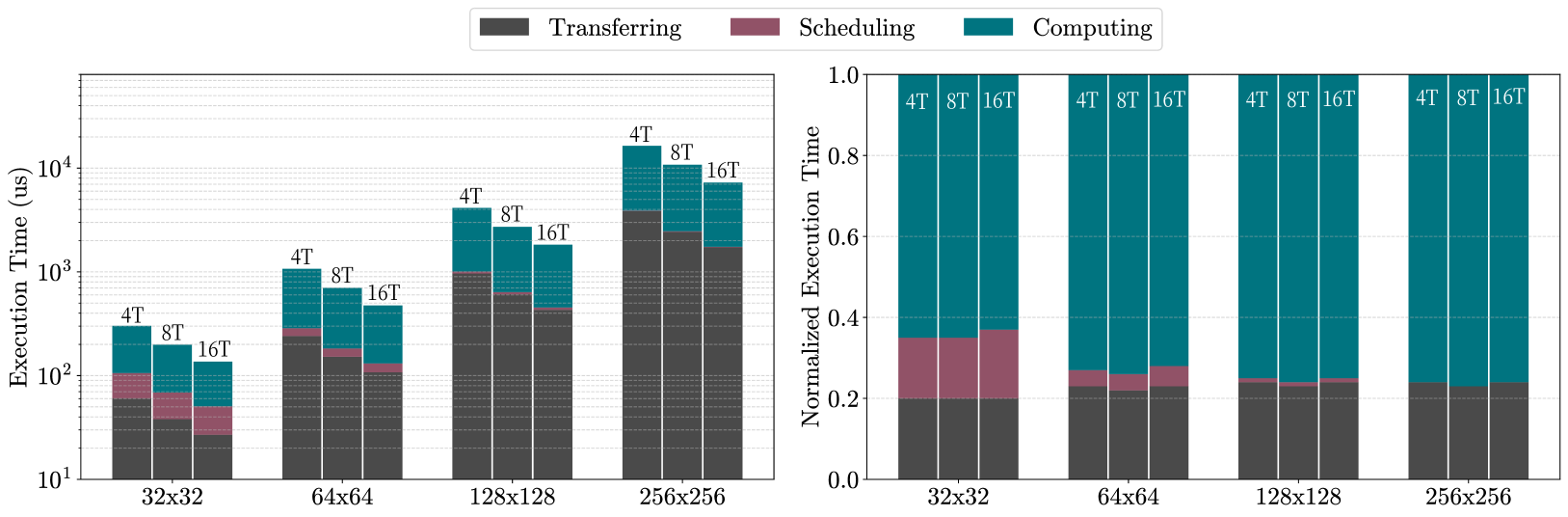
Figure 3: Breakdown of execution time (in logarithmic scale) and normalized execution time for the selected e-GPU systems (4T: e-GPU with 4 threads, 8T: e-GPU with 8 threads, 16T: e-GPU with 16 threads) across matrix multiplication kernels of increasing size.
图 3: 所选 e-GPU 系统(4T:4 线程 e-GPU,8T:8 线程 e-GPU,16T:16 线程 e-GPU)在不同大小矩阵乘法内核上的执行时间分解(对数尺度)和归一化执行时间。
VIII-C TinyBio 基准测试特性分析
图 4 展示了第 VII-B 节描述的 TinyBio 基准测试的每个内核,在分析的 e-GPU 系统上执行时,相对于基线主机系统所实现的加速和能量减少。
在预处理阶段,执行 FIR 滤波器。该算法高度可并行化,因为每个输出样本可以独立计算,允许多个线程同时处理不同的样本。计算涉及固定数量的乘加运算,这些运算可以高效地映射到 e-GPU 的处理单元。此外,FIR 滤波器表现出规则且顺序的内存访问模式,增强了局部性并实现了高效合并的内存访问(coalesced memory accesses),从而最小化延迟并最大化带宽利用率。
得益于这些有利特性,e-GPU 系统相比主机系统实现了 3.6 倍到 15.1 倍的加速,从而导致能耗降低了 1.7 倍到 3.1 倍。
相比之下,描绘阶段的特点是用于检测局部极大值和极小值的控制密集型算法。此工作负载仅部分可并行化,并未充分利用 e-GPU 的能力。此外,GPU 并未针对涉及频繁分支的、以控制为主的代码进行优化,在这些代码中,不同的执行路径使用线程掩码(thread masking)进行串行化,从而降低了并行效率。
尽管存在这些限制,e-GPU 系统相比主机仍实现了 3.1 倍到 13.1 倍的加速,并伴随 1.5 倍到 2.7 倍的能耗降低。
在特征提取阶段,执行 Stockham FFT 算法。与传统的 Cooley-Tukey FFT 不同,Stockham FFT 通过在每个阶段对数据重新排序,消除了对单独的位反转排列(bit-reversal permutation)的需要。它采用双缓冲(ping-pong)方案,在两个数组之间交替存储中间结果。在其 log₂(N) 个阶段的每个阶段,它执行独立的蝶形运算(butterfly operations),具有规则且顺序的内存访问,使其特别适合并行架构。在计算结束时,输出数据已经处于正确的顺序,无需显式的最终排列步骤。
然而,此阶段的主要限制是需要在顺序阶段之间进行同步,这减少了可用的并行性并限制了整体性能。尽管如此,e-GPU 系统仍提供了 3.3 倍到 14.0 倍的加速,同时能耗降低了 1.6 倍到 2.9 倍。
总体而言,当考虑整个应用程序时,e-GPU 系统在处理阶段实现了 3.4 倍到 14.3 倍的整体性能提升,同时能耗降低了 1.6 倍到 2.9 倍。
VIII-D 整体讨论
所评估系统的特性突出了在为 TinyAI 应用设计或选择平台时必须考虑的关键权衡。
基线主机系统提供了最低的复杂性,使其非常适合计算需求适中且资源限制严格的场景。其轻量级设计确保了最小的面积和功耗使用,这对于能源可用性严重受限的应用(例如电池供电的边缘设备)至关重要。然而,这些好处是以计算能力为代价的。主机 CPU 难以有效处理更密集的 TinyAI 工作负载的需求,导致执行时间延长,从而增加了整体能耗。随着 TinyAI 应用 increasingly require 更大的处理能力来支持更复杂的模型和数据分析,基线主机 CPU 对此类用例变得不太可行。
相比之下,e-GPU 系统相比主机系统引入了适度的面积和漏电开销。然而,这些额外的成本被性能和能效方面的显著增益所抵消。e-GPU 提供了 3.6 倍到 15.1 倍的加速,并实现了 1.7 倍到 3.1 倍的节能。这些改进对于涉及密集型数据处理但仍必须在严格的面积和功率预算内运行的 TinyAI 应用特别有价值。尽管控制密集型工作负载对 e-GPU 来说仍然更具挑战性(由于 SIMT 架构在管理分支代码时的固有效率低下),但该系统有效地处理了此类情况以维持性能和能效。
总体而言,e-GPU 系统成为 TinyAI 应用的高效且多功能的解决方案。其架构成功平衡了计算吞吐量、能效和灵活性,解决了资源受限环境中面临的关键挑战。通过显著提高性能、降低能耗,同时保持适中的面积和功耗占用,e-GPU 满足了现代 TinyAI 工作负载的严格要求。
IX 结论
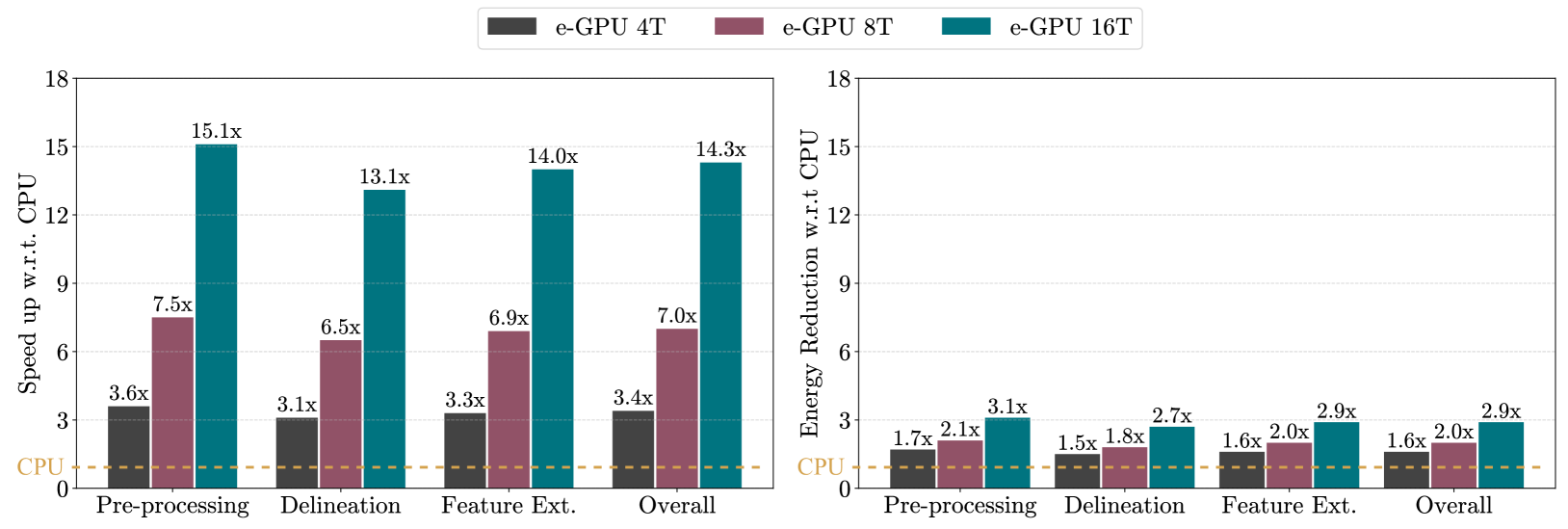
Figure 4: Speed-up and energy reduction of the TinyBio benchmark on the selected e-GPU systems compared to the baseline host system.
图 4: 所选 e-GPU 系统与基线主机系统相比,TinyBio 基准测试的加速和能量减少。
对基于机器学习的实时计算日益增长的需求加速了边缘计算的采用,在边缘计算中,本地数据处理增强了延迟、隐私和能效。然而,这些工作负载对计算性能、面积和功耗施加了严格的限制,需要专门的硬件解决方案。在可用的加速器中,GPU 在利用数据并行性执行机器学习和信号处理任务方面提供了强大的潜力。然而,它们在 TinyAI 设备背景下的权衡取舍此前仍未得到充分探索。
为了应对这些挑战,本工作介绍了 e-GPU,一个专为 TinyAI 应用设计的开源可配置 RISC-V GPU 平台。其广泛的可配置性支持细粒度的面积和功耗优化,而专用的 Tiny-OpenCL 框架提供了一个为资源受限环境量身定制的轻量级且灵活的编程模型。
e-GPU 与 X-HEEP 主机 [10] 集成,实现了一个为 TinyAI 应用优化的 APU。所提出系统的多个实例具有不同的 e-GPU 配置,在台积电(TSMC)16 nm SVT CMOS 工艺中实现,并在 300 MHz 频率和 0.8 V 电压下运行。分析了它们的面积和漏电特性以确保符合 TinyAI 的限制。为了评估运行时开销和应用级效率,我们采用了两个基准测试:GeMM 和 TinyBio 工作负载。GeMM 基准测试用于量化 Tiny-OpenCL 框架引入的调度开销。结果表明,对于大于 256×256 的矩阵大小(或等效问题大小),该延迟变得可以忽略不计。然后使用 TinyBio 基准测试来评估相对于基线主机的性能和能量改进。结果表明,高端 e-GPU 配置可实现高达 15.1 倍的加速,并将能耗降低高达 3.1 倍,同时仅产生 2.5 倍的面积开销,并在 28 mW 的功率预算内运行。
通过提供一个具有竞争力面积、功耗和可编程性的开源且高度可配置的 GPU 平台,本工作为进一步研究用于 TinyAI 应用的 GPU 平台奠定了基础,为边缘端灵活且高能效的计算开辟了新的机遇。
致谢
我们要感谢整个 X-HEEP 团队对平台的重大贡献。特别感谢 Miguel Peón-Quirós 博士在系统架构设计方面提供的宝贵支持。
References
- [1]
- F. Ponzina, S. Machetti, M. Rios, B. Denkinger, A. Levisse, G. Ansaloni, M. Peón-Quirós, and D. Atienza, “A hardware/software co-design vision for deep learning at the edge,” IEEE Micro, vol. 42, no. 6, pp. 48–54, 2022.
- [2]
- S. Machetti, P. D. Schiavone, T. C. Müller, A. Levisse, M. Peón-Quirós, and D. Atienza, “Heepocrates: An ultra-low-power risc-v microcontroller for edge-computing healthcare applications,” Europractice Activity Report, 2024.
- [3]
- S. Machetti, “Asip design for motion estimation in video compression algorithms,” Master Thesis, Polito, 2018.
- [4]
- P. Jääskeläinen, C. S. Lama, E. Schnetter, K. Raiskila, J. Takala, and H. Berg, “pocl: A performance-portable opencl implementation,” Int. J. Parallel Program., vol. 43, no. 5, p. 752–785, Oct. 2015. [Online]. Available: https://doi.org/10.1007/s10766-014-0320-y
- [5]
- B. W. Denkinger, M. Peón-Quirós, M. Konijnenburg, D. Atienza, and F. Catthoor, “Vwr2a: a very-wide-register reconfigurable-array architecture for low-power embedded devices,” in Proceedings of the 59th ACM/IEEE Design Automation Conference, ser. DAC ’22. New York, NY, USA: Association for Computing Machinery, 2022, p. 895–900.
- [6]
- B. W. Denkinger, M. Peón-Quirós, M. Konijnenburg, D. Atienza, and F. Catthoor, “Acceleration of control intensive applications on coarse-grained reconfigurable arrays for embedded systems,” IEEE Transactions on Computers, vol. 72, no. 9, pp. 2548–2560, 2023.
- [7]
- F. Conti, D. Rossi, G. Paulin, A. Garofalo, A. Di Mauro, G. Rutishauer, G. m. Ottavi, M. Eggimann, H. Okuhara, V. Huard, O. Montfort, L. Jure, N. Exibard, P. Gouedo, M. Louvat, E. Botte, and L. Benini, “A 12.4tops/w @ 136gops ai-iot system-on-chip with 16 risc-v, 2-to-8b precision-scalable dnn acceleration and 30%-boost adaptive body biasing,” in IEEE ISSCC, 2023, pp. 21–23.
- [8]
- M. Caon, C. Choné, P. D. Schiavone, A. Levisse, G. Masera, M. Martina, and D. Atienza, “Scalable and risc-v programmable near-memory computing architectures for edge nodes,” 2024.
- [9]
- W. A. Simon, Y. M. Qureshi, M. Rios, A. Levisse, M. Zapater, and D. Atienza, “Blade: An in-cache computing architecture for edge devices,” IEEE Transactions on Computers, vol. 69, no. 9, pp. 1349–1363, 2020.
- [10]
- S. Machetti, P. D. Schiavone, T. C. Müller, M. Peón-Quirós, and D. Atienza, “X-heep: An open-source, configurable and extendible risc-v microcontroller for the exploration of ultra-low-power edge accelerators,” arXiv, 2024.
- [11]
- P. D. Schiavone, S. Machetti, M. Peón-Quirós, J. Miranda, B. Denkinger, T. C. Müller, R. Rodríguez, S. Nasturzio, and D. A. Alonso, “X-heep: An open-source, configurable and extendible risc-v microcontroller,” in Proceedings of the ACM International Conference on Computing Frontiers, 2023, p. 379–380.
- [12]
- S. Machetti, P. D. Schiavone, G. Ansaloni, and D. Atienza, “An open-source and configurable risc-v cpu/gpu accelerated processing unit for ultra-low-power wearable devices,” SMARTHEP Edge Machine Learning School - CERN, 2024.
- [13]
- A. Bakhoda, G. L. Yuan, W. W. L. Fung, H. Wong, and T. M. Aamodt, “Analyzing cuda workloads using a detailed gpu simulator,” in 2009 IEEE International Symposium on Performance Analysis of Systems and Software, 2009, pp. 163–174.
- [14]
- J. Power, J. Hestness, M. S. Orr, M. D. Hill, and D. A. Wood, “gem5-gpu: A heterogeneous cpu-gpu simulator,” IEEE Computer Architecture Letters, vol. 14, no. 1, pp. 34–36, 2015.
- [15]
- N. Binkert, B. Beckmann, G. Black, S. K. Reinhardt, A. Saidi, A. Basu, J. Hestness, D. R. Hower, T. Krishna, S. Sardashti, R. Sen, K. Sewell, M. Shoaib, N. Vaish, M. D. Hill, and D. A. Wood, “The gem5 simulator,” SIGARCH Comput. Archit. News, vol. 39, no. 2, p. 1–7, 2011.
- [16]
- R. Ubal, B. Jang, P. Mistry, D. Schaa, and D. Kaeli, “Multi2sim: A simulation framework for cpu-gpu computing,” 2012 21st International Conference on Parallel Architectures and Compilation Techniques (PACT), pp. 335–344, 2012.
- [17]
- B. Tine, V. Saxena, S. Srivatsan, J. R. Simpson, F. Alzammar, L. Cooper, and H. Kim, “Skybox: Open-source graphic rendering on programmable risc-v gpus,” Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, p. 616–630, 2023.
- [18]
- Y. Zhou, X. Jin, and T. Xiang, “Risc-v graphics rendering instruction set extensions for embedded ai chips implementation,” Proceedings of the 2020 2nd International Conference on Big Data Engineering and Technology, p. 85–88, 2020. [Online]. Available: https://doi.org/10.1145/3378904.3378926
- [19]
- B. Tine, K. P. Yalamarthy, F. Elsabbagh, and K. Hyesoon, “Vortex: Extending the risc-v isa for gpgpu and 3d-graphics,” MICRO-54, p. 754–766, 2021.
- [20]
- M. S. i Bonet, J. Wolf, and L. Kosmidis, “A risc-v multicore and gpu soc platform with a qualifiable software stack for safety critical systems,” 2025.
- [21]
- H. Kim, R. R. Yan, J. You, T. V. Yang, and Y. S. Shao, “Virgo: Cluster-level matrix unit integration in gpus for scalability and energy efficiency,” in Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’25. New York, NY, USA: Association for Computing Machinery, 2025, p. 1382–1399.
- [22]
- J. Li, K. Yang, C. Jin, X. Liu, Z. Yang, F. Yu, Y. Shi, M. Ma, L. Kong, J. Zhou, H. Wu, and H. He, “Ventus: A high-performance open-source gpgpu based on risc-v and its vector extension,” in 2024 IEEE 42nd International Conference on Computer Design (ICCD), 2024, pp. 276–279.
- [23]
- Open bus interface protocol. [Online]. Available: https://github.com/openhwgroup/obi
- [24]
- A. Rahimi, I. Loi, M. R. Kakoee, and L. Benini, “A fully-synthesizable single-cycle interconnection network for shared-l1 processor clusters,” in 2011 Design, Automation and Test in Europe, 2011, pp. 1–6.
- [25]
- S. Machetti, P. D. Schiavone, T. C. Müller, M. Peón-Quirós, and D. Atienza, “X-heep: An open-source, configurable and extendible risc-v microcontroller for the exploration of ultra-low-power edge accelerators,” EcoCloud Event 2023, 2023.
- [26]
- S. Machetti, M. Peón-Quirós, D. Kasap, J. Sapriza, R. Rodríguez, J. Miranda, P. D. Schiavone, and D. Atienza, “Femu: An open-source risc-v emulation platform for the exploration of accelerator-based edge applications,” DATE, 2024.
- [27]
- M. Gautschi, P. D. Schiavone, A. Traber, I. Loi, A. Pullini, D. Rossi, E. Flamand, F. K. Gürkaynak, and L. Benini, “Near-threshold risc-v core with dsp extensions for scalable iot endpoint devices,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 25, no. 10, pp. 2700–2713, 2017.
- [28]
- C. Vinschen, “Newlib,” http://sourceware.org/newlib, 2001.
- [29]
- E. De Giovanni, F. Montagna, B. W. Denkinger, S. Machetti, M. Peón-Quirós, S. Benatti, D. Rossi, L. Benini, and D. Atienza, “Modular design and optimization of biomedical applications for ultralow power heterogeneous platforms,” IEEE TCAD, vol. 39, no. 11, pp. 3821–3832, 2020.
- [30]
- Y. Wang, L. Orlandic, S. Machetti, G. Ansaloni, and D. Atienza, “Ace: Automated optimization towards iterative classification in edge health monitors,” TBioCAS, vol. 19, no. 1, pp. 82–92, 2025.
- [31]
- F. Dell’Agnola, U. Pale, R. Marino, A. Arza, and D. Atienza, “Mbiotracker: Multimodal self-aware bio-monitoring wearable system for online workload detection,” IEEE Transactions on Biomedical Circuits and Systems, vol. 15, no. 5, pp. 994–1007, 2021.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)