AI应用开发(埋坑版)
一:文本,图像,数据库数据等数据源的理解和生成能力整合至企业AI应用;langchain开发框架,向量检索和嵌入模型技术,向量数据库(milvus);构建私域知识图谱,TF-IDF,BM25,精通Elasticsearch,opensearch等检索工具二:RAG信息检索与生成模块(RAG准确率提升优化经验),including:文档嵌入,索引构建,知识增强,大模型前置/后置处理三:优化RAG应用
一些需要掌握的技能点
一:文本,图像,数据库数据等数据源的理解和生成能力整合至企业AI应用;langchain开发框架,向量检索和嵌入模型技术,向量数据库(milvus);构建私域知识图谱,TF-IDF,BM25,精通Elasticsearch,opensearch等检索工具
二:RAG信息检索与生成模块(RAG准确率提升优化经验),including:文档嵌入,索引构建,知识增强,大模型前置/后置处理
三:优化RAG应用的推理和生成模块(提升RAG系统的整体性能和可扩展性)
四:熟悉OCR技术,多模态模型处理富文档
五:流程编排引擎(Airflow),LLM应用开发框架(eino),复杂AI Agent的任务链编排与管理,LLM/VLM训练与优化技术,包括微调,强化学习(RLHF),知识蒸馏
学习Embedding:
破除我们对于这些专有名词的陌生感,换言之,先让我们和他们熟络起来:
Embedding技术
一种将高维数据映射到低维空间的方法,通常用于将离散的,非连续的数据转换为连续的向量表示,以便计算机进行处理。
推荐系统中极其重要的Embedding技术:
Embedding直观上看,是一个数组,元素是小数数字;物理意义上,每个小数代表一个兴趣强度
如Embedding:[0.8,0.3],数组第一个元素代表“喜剧”,第二个代表“动作”,用户Embedding:[0.8,0.3]含义是这个人喜欢0.8强度的喜剧,喜欢0.3强度的动作。而机器学习得到用户/物品的Embedding,这个数值没法解释代表什么“兴趣”,但这样的“兴趣向量”可以大量使用,也叫做latent factor,隐因子,隐含兴趣向量
传统Embedding
几乎所有词向量嵌入技术都依赖于海量文本数据来提取词语之间的关系
TF-IDF(词频-逆文档频率)
TF-IDF的理念是通过考虑两个因素来计算单词在文档中的重要性:
1.词频(TF)词语在文档中出现的频率。TF值越高,表示词语对文档越重要
TF=在某一类中词条w出现的次数/该类中所有的词条数目
2.逆文档频率(IDF)词语在文档中的稀缺性。这种方法是基于这样的假设:出现在多篇文档中的词语的重要性低于仅出现在少数文档中的词语
IDF=log(语料库的文档总数/包含词条w的文档数+1),分母加一是为了避免分母为0
TF-IDF实际上为:TF*IDF。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF-IDF应用:(1)搜索引擎(2)关键词提取(3)文本相似性(4)文本摘要
使用数据生成Embedding
1.基于内容word2vec的Embedding
2.协同过滤矩阵分解的方法
3.DNN深度学习的方法
学习知识图谱
What is 知识图谱?
信息VS知识
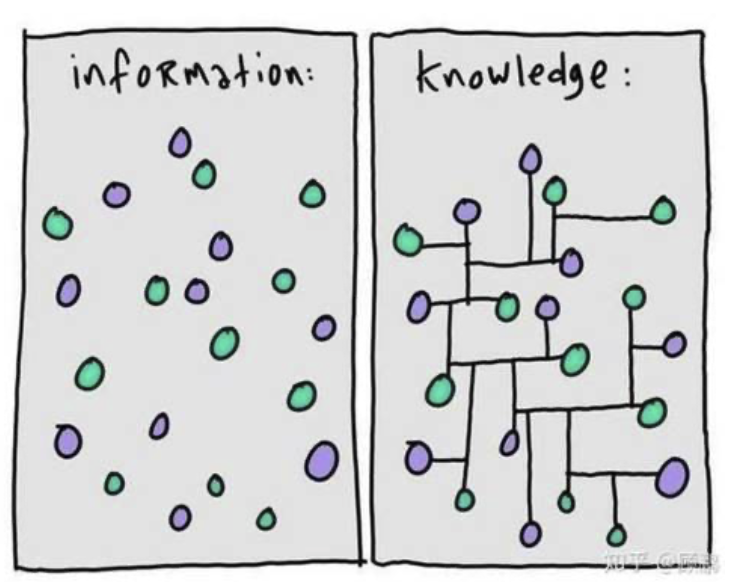
在信息的基础上,建立实体之间的联系,就能形成“知识”,或者称为叫事实(Fact)更为合适。
知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate- Object)。
知识图谱的构建
知识图谱的构建是从原始数据开始,包括结构化,半结构化和非结构化数据。通过一系列自动或半自动的技术手段,从原始数据库和第三方数据库中提取知识,并将其存入知识库的数据层和模式层。
这个过程包括五个阶段:数据采集,知识抽取,知识融合,知识加工和知识应用
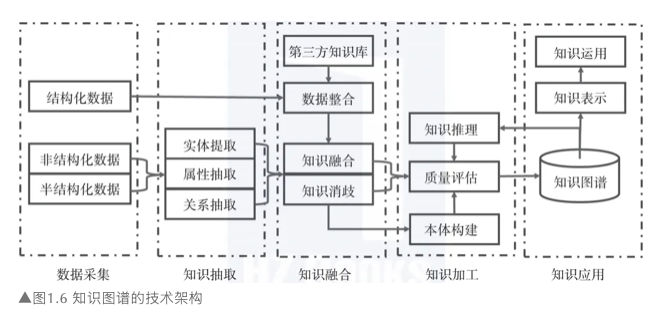
知识图谱的构建方式主要有自顶向下和自底向上两种:
自顶向下是先定义知识图谱的本体和数据模式,然后将实体添加到知识库中。这种构建方式需要利用一些现有的结构化知识库作为基础知识库,例如Freebase项目。大多数制造业企业应用初期采用这种构建方式。
自底向上是从开放链接数据中提取实体,选择置信度较高的实体加入知识库,然后构建顶层的本体模式。
数据类型和存储方式
知识图谱的原始数据类型一般来说有三类:
结构化数据:如关系数据库
半结构化数据:如XML,JSON,百科
非结构化数据:如图片,音频,视频,文本
如何存储这上面的三类数据类型?一般有两种选择:一种是通过RDF(资源描述框架)这样的规范格式来进行存储;一种是使用图数据库来进行存储,常用的有Neo4j等。
RDF
RDF中的基本概念包括资源,属性,声明和图。
资源:可以认为一个资源是一个对象,每个资源都有一个URL
属性:它们描述了资源之间的关系
声明:一个声明是一个实体-属性-取值的三元组,由一个资源,一个属性和一个属性值组成。属性值要么是一个资源,要么是一个文字。文字是原子值,如数字,字符串或日期。
Neo4j
Neo4j的数据存储形式主要是节点(node)和边(edge)来组织数据。node可以代表知识图谱中的实体,edge可以代表实体间的关系,关系可以有方向,两端对应开始节点和结束节点。
另外也可以在node上加一个或多个标签表示实体的分类,以及一个键值对集合来表示该实体除了关系属性之外的一些额外属性。关系也可以附带额外的属性。
。。。。
一句箴言:“计算机科学领域的任何问题都可以通增加一个间接的中间层来解决”
参考文章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)