【AI论文】AgentGym-RL:通过多轮强化学习训练大语言模型(LLM)智能体以实现长期决策制定
摘要:复旦大学研究团队提出AgentGym-RL框架,通过强化学习训练大语言模型智能体进行多轮交互决策。该框架采用模块化设计,支持多种现实场景和主流强化学习算法。团队创新性地提出ScalingInter-RL训练方法,通过渐进式交互扩展平衡探索与利用,显著提升训练稳定性。实验表明,在27项任务中,该框架训练的7B开源模型性能超越商业闭源大模型。研究为智能体开发提供统一平台,并开源完整框架以促进后续
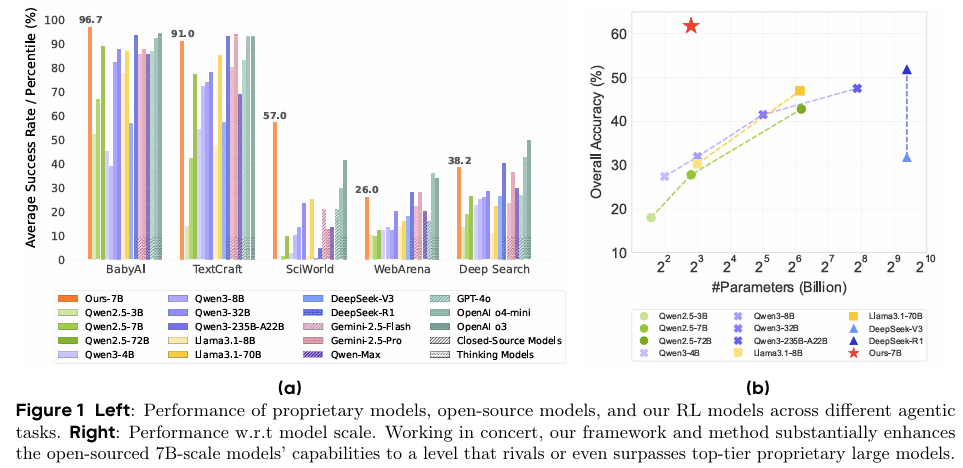
摘要:开发能够做出一系列智能决策以解决复杂现实任务的自主大语言模型(LLM)智能体,是一个快速发展的前沿领域。如同人类的认知发展过程一样,智能体需通过与环境进行探索和交互来获取知识与技能。尽管已取得一定进展,但学术界仍缺乏一个统一的交互式强化学习(RL)框架,该框架能够在多样且逼真的环境中,无需依赖监督式微调(SFT),即可从零开始有效训练此类智能体。为填补这一空白,我们推出了AgentGym-RL框架,该框架通过强化学习训练大语言模型智能体进行多轮交互式决策。该框架采用模块化与解耦架构,确保了高度的灵活性和可扩展性。它涵盖了多种现实场景,并支持主流的强化学习算法。此外,我们提出了ScalingInter-RL训练方法,旨在实现探索与利用的平衡以及稳定的强化学习优化。在训练初期,该方法通过限制交互次数来强调利用已有知识,随后逐渐转向更大范围的探索,以鼓励多样化的问题解决策略。如此一来,智能体能够展现出更为多样的行为,且在长期任务中不易出现性能崩溃。我们进行了大量实验,以验证AgentGym-RL框架和ScalingInter-RL训练方法的稳定性与有效性。在多种环境下的27项任务中,我们的智能体表现达到或超越了商业模型的水平。我们提供了关键见解,并将开源完整的AgentGym-RL框架(包括代码和数据集),以助力研究界开发下一代智能体。Huggingface链接:Paper page,论文链接:2509.08755
研究背景和目的
研究背景:
随着大型语言模型(LLMs)的快速发展,其在自然语言处理领域的应用已经从简单的聊天机器人扩展到能够处理复杂、长期任务的自主智能体。这些智能体通过与环境进行交互,做出一系列智能决策以完成特定目标,类似于人类认知发展的过程。然而,尽管深度强化学习(RL)在LLMs的推理和单轮交互任务中取得了显著进展,但在多轮交互、长期决策制定的训练方面仍存在不足。现有研究大多局限于单轮任务,缺乏能够有效训练LLM智能体进行多轮交互的统一、端到端的RL框架。此外,这些研究在任务复杂性和环境多样性方面也受到限制,且在优化稳定性和效率方面存在挑战。
为了填补这一研究空白,复旦大学的研究团队提出了AgentGym-RL框架,旨在通过多轮强化学习训练LLM智能体,使其能够在复杂、现实的环境中进行长期决策。该框架不仅支持多种主流RL算法,还涵盖了广泛的现实世界场景,为LLM智能体的训练提供了一个统一、模块化和灵活的平台。
研究目的:
本研究的主要目的包括:
- 开发一个统一的、模块化的RL框架:用于训练LLM智能体进行多轮交互决策,支持多种现实世界场景和主流RL算法。
- 提出一种渐进式交互扩展方法:即ScalingInter-RL,以平衡探索与利用,提高RL训练的稳定性,并实现从简单任务到复杂任务的逐步适应。
- 验证框架和方法的有效性:通过广泛的实验,证明AgentGym-RL框架和ScalingInter-RL方法能够显著提升LLM智能体在复杂任务中的性能,使其达到或超过商业闭源模型的水平。
- 提供关键见解和指导:通过实验分析,为未来智能体设计和操作范式的研究提供有价值的见解和资源。
研究方法
本研究采用以下方法来实现上述目标:
- 框架设计:
- 模块化架构:AgentGym-RL框架采用模块化设计,包括环境模块、智能体模块和训练模块,确保高灵活性和可扩展性。
- 多样化的场景支持:框架支持多种现实世界场景,如网页导航、深度搜索、数字游戏、具身任务和科学任务,为智能体提供丰富的交互环境。
- 主流RL算法集成:框架集成了多种主流RL算法,如PPO、GRPO和REINFORCE++,为智能体训练提供多样化的优化方法。
- ScalingInter-RL方法:
- 渐进式交互扩展:该方法通过逐步增加智能体与环境的交互轮次,平衡探索与利用,避免早期过度探索导致的训练不稳定。
- 动态调整交互范围:根据训练进度动态调整交互范围,使智能体逐渐适应更复杂的环境和任务。
- 实验设计:
- 多任务实验:在五个不同场景下进行广泛实验,验证框架和方法的普适性和有效性。
- 对比分析:与商业闭源模型和开源模型进行对比,评估AgentGym-RL框架下训练的智能体的性能。
- 详细任务分析:对不同环境下的任务进行详细分析,揭示智能体在不同任务中的表现和改进空间。
研究结果
- 框架和方法的普适性和有效性:
- AgentGym-RL框架在五个不同场景下的实验中表现出色,智能体在27个任务上的平均成功率显著提升,验证了框架的普适性和有效性。
- ScalingInter-RL方法通过渐进式交互扩展,显著提高了智能体的探索能力和任务完成能力,避免了早期训练中的不稳定问题。
- 与商业模型和开源模型的对比:
- 在多个任务上,使用AgentGym-RL框架训练的70亿参数开源模型性能超越了更大参数规模的商业模型,如GPT-4o和Gemini-2.5-Pro。这表明,通过优化训练方法和框架设计,可以有效提升智能体的性能,而不仅仅是依赖模型规模的扩大。
- ScalingInter-RL方法的优势:
- ScalingInter-RL方法在平衡探索与利用方面表现出色,显著提高了智能体在复杂任务上的性能。与基线方法相比,该方法在多个任务上实现了超过10%的性能提升,特别是在需要长期规划和复杂交互的任务中表现尤为突出。
研究局限
尽管本研究在LLM智能体的多轮交互决策训练方面取得了显著进展,但仍存在以下局限性:
- 环境多样性有限:尽管框架支持多种场景,但实验中使用的环境仍有限,可能无法完全覆盖所有现实世界的复杂性和多样性。
- 评估指标单一:目前主要依赖任务成功率作为评估指标,可能无法全面反映智能体的性能,特别是在探索能力、泛化能力和鲁棒性方面。
- 计算资源需求高:大规模RL训练需要大量计算资源,限制了研究的可扩展性和实际应用。
- 超参数调优复杂:RL算法的超参数调优复杂且耗时,不同任务和环境可能需要不同的超参数设置,增加了研究的复杂性。
未来研究方向
针对现有研究的局限性和挑战,未来研究可进一步探索以下方向:
- 增强环境多样性:开发更多样化的现实世界场景和任务,以更全面地评估智能体的性能和泛化能力。这包括模拟不同物理环境、复杂交互和动态变化的场景。
- 多模态学习与交互:结合视觉、听觉和触觉等多模态信息,提升智能体对环境的全面感知和理解能力。多模态学习有助于智能体在不同模态间建立关联,提高决策准确性。
- 强化学习的可解释性:研究如何解释强化学习过程中的决策路径和策略,提高智能体的透明度和可信度。可解释性对于安全关键领域的应用尤为重要。
- 终身学习和持续适应:研究智能体如何在不断变化的环境中持续学习和适应,实现终身学习。这对于长期运行的系统和动态环境尤为重要。
- 理论分析与保证:深入研究强化学习算法的理论性质,提供收敛性、最优性和鲁棒性等方面的保证。理论分析有助于指导实践,提高训练效率和稳定性。
- 实际应用与部署:探索AgentGym-RL框架在真实世界中的应用,如自动驾驶、智能家居和工业自动化等领域。实际应用将推动技术的落地和商业化,促进AI技术的发展。
通过不断探索这些方向,未来的研究将能够进一步提升LLM智能体的性能和应用范围,推动AI技术的持续进步和发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献134条内容
已为社区贡献134条内容

所有评论(0)