RAG学习day01-探索一个最小相关项目
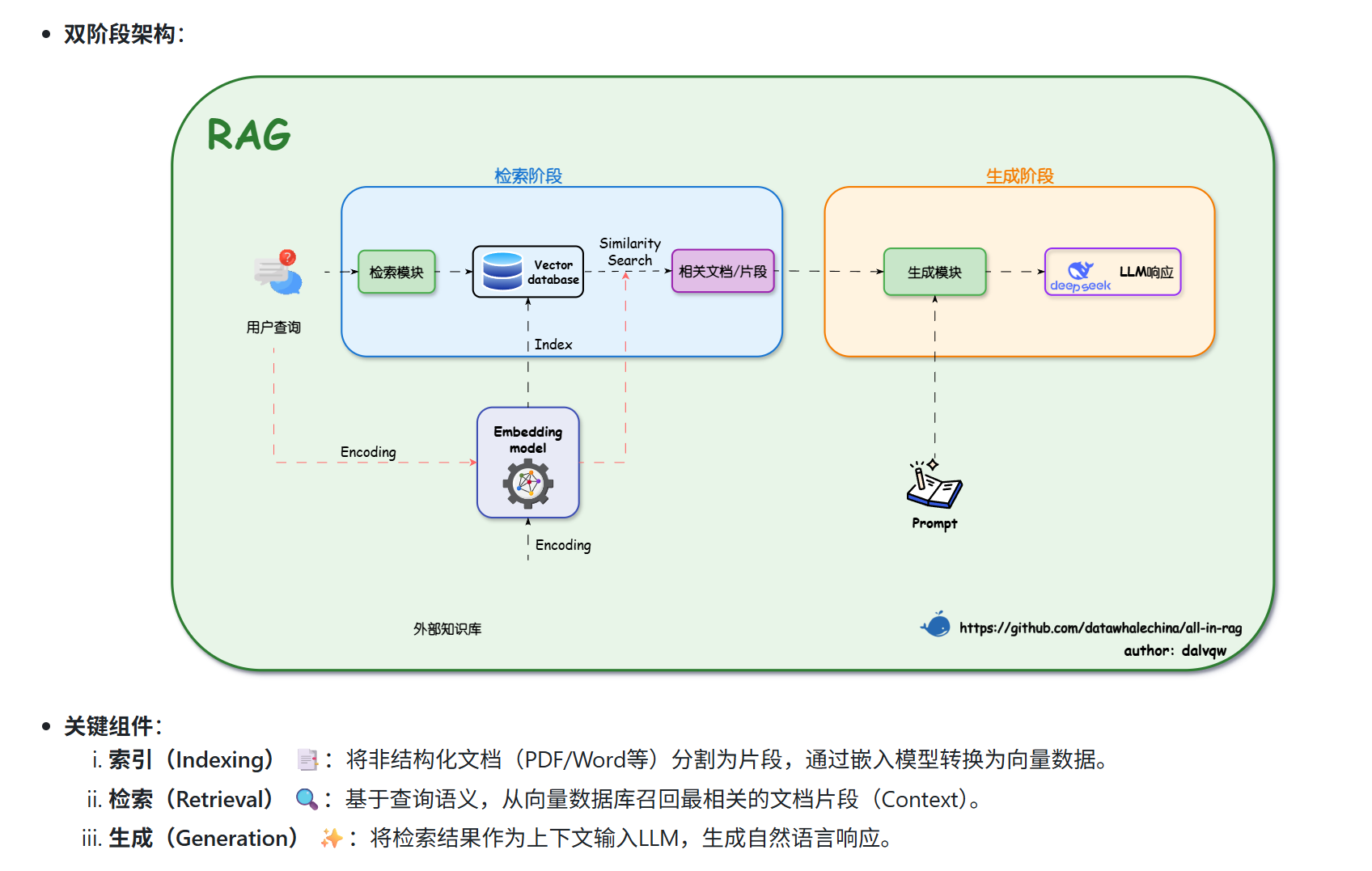
RAG(检索增强生成)是一种结合大语言模型与外部知识库的技术流程。其核心步骤包括:文档加载分块、向量化存储、相似性检索,最后将问题及相关文本输入大模型生成答案。实验使用LangChain框架,通过调整文本分块参数(chunk_size/overlap)观察输出差异,并对比了LangChain与LlamaIndex的实现效果。项目采用BAAI/bge-small-zh中文嵌入模型和DeepSeek大
RAG是什么?
RAG是基于大语言模型,使用数据库对其微调,获取答案的过程。
他的基本流程是文本(外部知识库)分块向量化,查询一个问题,去向量索引库寻找与问题相似的文本,把问题和相关知识送入大语言模型,获取答案。
他目前有一些主流框架包括:langchain,llamaindex等。
为什么?
既然大语言训练模型已经如此优秀了,为什么要进行RAG检索增强引入外部文档呢?
首先是因为大语言模型本身训练所需要的海量资源和算力,对他进行训练和微调很费资源。
其次是因为大语言模型的输入窗口大小有限,容纳不了太多的输入资料。但我们又需要精确定位这部分相关知识,那么RAG里的相似性检索就很有效果。某种程度上来说,大语言模型本身就是在对query请求输入做相似性检索,现在这种情况是通过外置知识库来更精确和轻量化的完成这部分功能。
怎么办?(基本步骤)
- 环境变量配置,配置deepseekapi进入基本Linux环境中。
- 文档加载,使用textloader加载文档。
- 文本分块,以分段和分句保留最大语义来对文档分块。
- 嵌入模型配置(BBAI——使用北京智源研究院(BAAI)开发的中文嵌入模型
bge-small-zh-v1.5,这是一个针对中文优化的轻量级嵌入模型) - 向量存储构建,以向量形式存储词embedding
- 提示词模板创建,构建向大模型提问的模板——话术+问题+上下文内容+异常判断
- 大语言模型配置——deepseek相关(模型,token,温度,api)
- 用户查询处理:发送查询请求
- 生成提示词并且调用LLM
代码相关
import os
# hugging face镜像设置,如果国内环境无法使用启用该设置
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from dotenv import load_dotenv
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.prompts import ChatPromptTemplate
from langchain_deepseek import ChatDeepSeek
#print("当前DEEPSEEK_API_KEY:", os.environ.get("DEEPSEEK_API_KEY"))
load_dotenv()
markdown_path = "../../data/C1/markdown/easy-rl-chapter1.md"
# 加载本地markdown文件
loader = UnstructuredMarkdownLoader(markdown_path)
docs = loader.load()
# 文本分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
chunks = text_splitter.split_documents(docs)
# 中文嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 构建向量存储
vectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(chunks)
# 提示词模板
prompt = ChatPromptTemplate.from_template("""请根据下面提供的上下文信息来回答问题。
请确保你的回答完全基于这些上下文。
如果上下文中没有足够的信息来回答问题,请直接告知:“抱歉,我无法根据提供的上下文找到相关信息来回答此问题。”
上下文:
{context}
问题: {question}
回答:"""
)
# 配置大语言模型
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0.7,
max_tokens=2048,
api_key=os.getenv("DEEPSEEK_API_KEY")
)
# 用户查询
question = "文中举了哪些例子?"
# 在向量存储中查询相关文档
retrieved_docs = vectorstore.similarity_search(question, k=3)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print("answer:", answer)
print("answer.content:",answer.content)
个人思考
在配环境和api调用上折腾了一下,熟悉了数据准备的基本流程和向量库的构建,对大模型+数据库有了基本的了解,期待后面仔细学习。
课后作业
根据课后作业,我调整了一些参数下面是总结:
作业1:修改Langchain代码中RecursiveCharacterTextSplitter()的参数chunk_size和chunk_overlap,观察输出结果有什么变化。
首先,源代码如下,这是一句文本分块的代码。
text_splitter = RecursiveCharacterTextSplitter()
texts = text_splitter.split_documents(docs)可以采用默认参数,什么也不写,这样分块的逻辑就会倾向于按段落和句子分。
如果使用参数,chunk_size代表分块的最大文字数,chunk_overlap代表重合字数。
以下是源文档描述:
文本分块 (Chunking): 为了便于后续的嵌入和检索,长文档被分割成较小的、可管理的文本块(chunks)。这里采用了递归字符分割策略,使用其默认参数进行分块。当不指定参数初始化
RecursiveCharacterTextSplitter()时,其默认行为旨在最大程度保留文本的语义结构:
默认分隔符与语义保留: 按顺序尝试使用一系列预设的分隔符
["\n\n" (段落), "\n" (行), " " (空格), "" (字符)]来递归分割文本。这种策略的目的是尽可能保持段落、句子和单词的完整性,因为它们通常是语义上最相关的文本单元,直到文本块达到目标大小。保留分隔符: 默认情况下 (
keep_separator=True),分隔符本身会被保留在分割后的文本块中。默认块大小与重叠: 使用其基类
TextSplitter中定义的默认参数chunk_size=4000(块大小)和chunk_overlap=200(块重叠)。这些参数确保文本块符合预定的大小限制,并通过重叠来减少上下文信息的丢失。
我分别调整尝试了默认参数,[chunk_size=500,chunk_overlap=50],[chunk_size=200,chunk_overlap=20]三组参数。忘记存储答案了,只能口述一下:
默认参数会产生七条答案
500,50的参数也产生七条答案,但前三条与默认参数不同。
200,20的参数只产生四条答案。
因此,chunk_size越大,猜测每个文本分块内容越多,信息越容易被完整提取。
作业2 LangChain代码最终得到的输出携带了各种参数,查询相关资料尝试把这些参数过滤掉得到content里的具体回答。
如下所示,将print(answer)改成print(answer.content)即可
可以多聊一点相关参数,以下是大语言模型给的答案,总结就是它除了返回内容,还返回了大语言模型接口的版本,状态,使用token数等。
在您的输出中,`additional_kwargs`、`response_metadata` 和 `usage_metadata` 是 LangChain 或 DeepSeek 模型返回的元数据字段,用于提供关于模型响应的额外信息。以下是这些参数的详细解释:
---
### **1. `additional_kwargs`**
- **作用**:存储模型返回的额外自定义参数。
- **字段说明**:
- `refusal`: 表示模型是否拒绝了回答(例如,因敏感内容或超出范围)。`None` 表示未触发拒绝逻辑。
- **示例**:
```python
additional_kwargs={'refusal': None}
```---
### **2. `response_metadata`**
- **作用**:记录模型响应的元数据,包括 token 使用情况、模型信息等。
- **字段说明**:
- **`token_usage`**:
- `completion_tokens`: 生成回答消耗的 token 数量(103)。
- `prompt_tokens`: 输入问题消耗的 token 数量(276)。
- `total_tokens`: 总 token 数量(379)。
- `prompt_tokens_details`: 输入 token 的详细信息(如缓存命中情况)。
- `cached_tokens`: 从缓存中读取的 token 数量(64)。
- `prompt_cache_hit_tokens`: 缓存命中的 token 数量(64)。
- `prompt_cache_miss_tokens`: 缓存未命中的 token 数量(212)。
- **`model_name`**: 使用的模型名称(`deepseek-chat`)。
- **`system_fingerprint`**: 模型系统的唯一标识符(用于版本追踪)。
- **`id`**: 请求的唯一标识符(`f32437a1-b6b6-4105-be70-d90ff82b899c`)。
- **`finish_reason`**: 生成结束原因(`stop` 表示正常结束)。
- **`logprobs`**: 生成 token 的概率分布(未启用时为 `None`)。
- **示例**:
```python
response_metadata={
'token_usage': {
'completion_tokens': 103,
'prompt_tokens': 276,
'total_tokens': 379,
'prompt_tokens_details': {'cached_tokens': 64},
'prompt_cache_hit_tokens': 64,
'prompt_cache_miss_tokens': 212
},
'model_name': 'deepseek-chat',
'system_fingerprint': 'fp_08f168e49b_prod0820_fp8_kvcache',
'id': 'f32437a1-b6b6-4105-be70-d90ff82b899c',
'finish_reason': 'stop',
'logprobs': None
}
```---
### **3. `usage_metadata`**
- **作用**:与 `token_usage` 类似,但可能包含更详细的 token 使用信息。
- **字段说明**:
- `input_tokens`: 输入 token 数量(276)。
- `output_tokens`: 输出 token 数量(103)。
- `total_tokens`: 总 token 数量(379)。
- `input_token_details`: 输入 token 的详细信息。
- `cache_read`: 从缓存中读取的 token 数量(64)。
- `output_token_details`: 输出 token 的详细信息(未提供时为 `{}`)。
- **示例**:
```python
usage_metadata={
'input_tokens': 276,
'output_tokens': 103,
'total_tokens': 379,
'input_token_details': {'cache_read': 64},
'output_token_details': {}
}
```---
### **4. `id`**
- **作用**:标识当前调用的唯一 ID(`run--933dde6c-2b13-40fe-90f5-20a1152d6aaa-0`)。
- **用途**:用于日志追踪或调试。---
### **关键点总结**
1. **Token 使用**:
- 输入问题消耗 276 tokens,其中 64 tokens 来自缓存。
- 生成回答消耗 103 tokens。
- 总消耗 379 tokens。2. **模型信息**:
- 使用 `deepseek-chat` 模型,版本标识为 `fp_08f168e49b_prod0820_fp8_kvcache`。3. **缓存优化**:
- 缓存命中减少了部分 token 计算开销(64 tokens)。4. **调试与追踪**:
- 通过 `id` 和 `system_fingerprint` 可以追踪请求来源和模型版本。---
### **如何过滤这些参数?**
如果您只需要 `content`,可以直接忽略这些元数据:
```python
print(answer.content) # 仅输出纯文本回答
```如果需要进一步处理元数据(如统计 token 消耗),可以按需提取:
```python
print("Total tokens used:", response_metadata['token_usage']['total_tokens'])
```

作业3 给LlamaIndex代码添加代码注释
比起langchain,llamaindex代码就更加简单,封装的更多。但是他的效果也会更差一点。
import os
# os.environ['HF_ENDPOINT']='https://hf-mirror.com'
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.deepseek import DeepSeek
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 加载环境变量
load_dotenv()
# 选择deepseek作为大模型
# 设置deepseek的api_key
Settings.llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"))
# 设置嵌入模型
Settings.embed_model = HuggingFaceEmbedding("BAAI/bge-small-zh-v1.5")
# 加载文档
# 使用SimpleDirectoryReader加载文档
docs = SimpleDirectoryReader(input_files=["../../data/C1/markdown/easy-rl-chapter1.md"]).load_data()
# 构建索引
index = VectorStoreIndex.from_documents(docs)
# 查询引擎
query_engine = index.as_query_engine()
print(query_engine.get_prompts())
print(query_engine.query("文中举了哪些例子?"))
项目相关
项目在cloudstudio上有完整代码,源码来源于Datawhale社区。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)