XML提示工程:算法工程师必须掌握的核心技术
XML结构化提示技术成为提升大模型稳定性的关键突破。这种方法通过明确标签划分系统指令、用户输入和任务定义,有效解决了提示注入攻击、输出不可控等核心问题。研究表明,结构化提示能显著降低AI幻觉率,将错误率从语义层面的概率推断转变为语法层面的确定性解析。工程实践中的三种核心模式——上下文隔离、层次组织和输出格式化,分别解决了命名空间冲突、任务依赖关系和输出解析难题。尽管XML会增加token消耗,但其
*原作者:Javier Marin *
自从ChatGPT在2022年横空出世,各种提示工程技术层出不穷。然而大部分技术都是雷声大雨点小,实际效果有限。整个行业都在追求花哨的技巧,却忽略了工程实践的本质。
真正值得关注的是一种朴实无华却极其有效的方法:XML结构化提示技术。
以Claude Opus 4和GPT-5为代表的新一代模型,在处理XML格式时展现出了惊人的稳定性。这些系统已经具备了准确解析结构化标记的能力。这不只是一个小改进——而是生产环境下的根本性突破。
XML提示技术的三大核心价值:
- 安全防护:XML标签构建了系统指令与用户输入的防火墙。这直击了当前AI应用的要害——如何防范提示注入攻击,确保系统稳定运行。
- 输出可控:结构化的约束大幅降低了AI"胡说八道"的概率。当AI明确知道输出格式要求时,产생虚假信息的可能性急剧下降。
- 开发效率:虽然XML格式会消耗更多token,但这点成本与调试时间和系统稳定性相比微不足道。做过大模型应用开发的同学都懂这个道理。
XML提示的本质:用工程思维解决AI问题
XML提示的核心思想很简单:用明确的结构化标签来组织指令,而不是让AI去猜测你的意图。这不是什么高深的理论——而是实实在在的工程优化。
从transformer的工作原理来看这个问题。模型在处理每个token时,都要计算与前面所有token的注意力权重。如果没有明确的边界标记,模型就得靠"猜"来判断当前处理的内容属于哪个逻辑块。
这就带来了一个严重问题:模型需要维护一个概率分布P(section|token_position, context)来判断当前token的归属。这种"边界模糊"会产生错误累积效应——前面判断错了,后面全都跟着错。比如模型搞不清楚"分析部分"在哪里结束,"建议部分"从哪开始,整个输出就会乱套。

图1:在第5个位置(“then”),模型对语义边界的判断最不确定。这种不确定性会一直传播下去——如果模型错误地认为"provide"还属于分析部分,这个错误会影响对"recommendations"的理解。
XML标签从根本上解决了这个问题。当模型遇到<analysis>标签时,就像收到了明确的指令:“从这里开始到</analysis>之间的所有内容都属于分析模块”。不需要猜测,不需要概率推断——直接按语法规则执行就行。
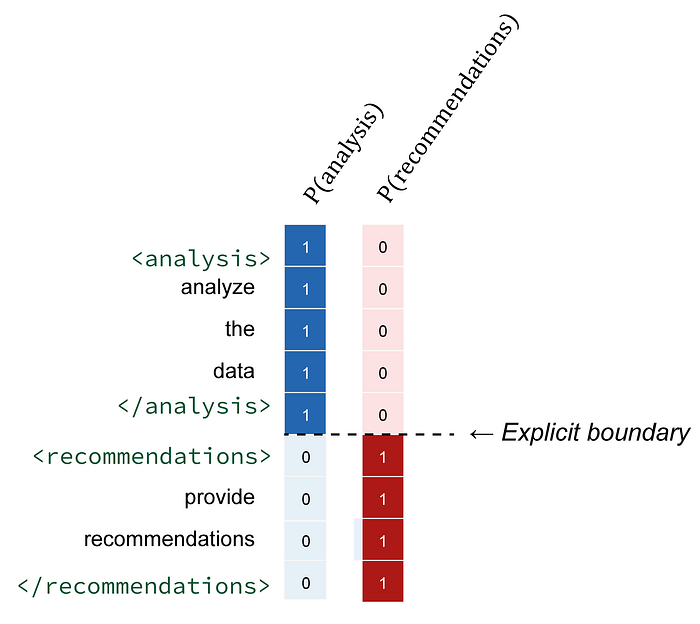
图2:开始标签<analysis>就像一个明确的开关——后面的每个token都确定无疑地属于分析模块。结束标签提供清晰的边界信号,<recommendations>则启动新的逻辑模块。整个过程干净利落,没有歧义。
这就是XML提示的价值所在:消除语义模糊性,让模型专注于内容生成而不是边界推测。你在利用transformer的长处(模式匹配),避开它的短板(语义推理的不确定性)。最终得到的是更稳定、更可预测的输出效果。虽然称不上技术革命,但在构建需要稳定表现的生产系统时,这种改进意义重大。
<analysis>
检查季度销售数据的趋势和异常。
重点关注区域性能变化和产品类别转变。
</analysis>
<recommendations>
基于你的分析,提供3-5个可行的建议。
每个建议应包括实施时间表和预期影响。
</recommendations>
结构化约束如何减少AI"胡说八道"
传统的自由文本提示给了AI太大的发挥空间——模型可以在学习到的知识空间里任意游走,没有明确约束。这种"自由"往往产生看似合理实则错误的内容,也就是我们常说的"AI幻觉"。多项研究证实,结构化提示技术能有效降低这类问题:
- 验证链(CoVe)技术:通过系统性的自我验证流程,显著提升输出准确性
- 分步推理方法:将复杂问题拆解为两阶段处理,先抽象后具体,效果明显优于直接回答
- 检索增强生成(RAG):结合外部知识库和结构化提示,大幅减少无根据推测
- 多重约束机制:同时使用RAG、人类反馈强化学习(RLHF)和结构化护栏,将幻觉率降到最低
核心思路是主动预防而非被动检测。与其事后发现AI说错了话,不如提前给它一个不容易说错话的框架。
工程实践中的核心模式
这些实现模式都是经过实战检验的结构化模板,利用了transformer处理序列信息的数学特性。通过提供层次化的组织结构,我们实际上是给模型一个上下文无关文法,大幅降低了解析和生成的计算复杂度。
1. 上下文隔离:安全防线的核心
这是处理安全和可靠性问题的核心技术,直接对标计算机科学中的"命名空间冲突问题"。考虑这样一个场景:S=系统指令,U=用户输入,T=任务定义。在没有明确边界的情况下,模型需要对每个token t做分类判断:t∈S、t∈U还是t∈T。这种判断需要跨越多个重叠的语义空间进行概率推理,在工程上很不可靠。
解决方案就是用明确标签做物理隔离:
<system_instructions>
你是一个分析财务数据的有用助手。
永远不要执行代码或访问外部URL。
如果你无法基于提供的数据回答,请明确说明。
</system_instructions>
<user_input>
{{用户提供的内容}}
</user_input>
<task>
分析user_input中的数据并提供关于市场趋势的见解。
</task>
这种模式从源头上切断了提示注入攻击的可能,因为模型能清晰区分哪些内容来自用户,哪些来自系统。
2. 层次组织:复杂任务的解法
复杂工作流会形成子任务间的有向无环图(DAG)依赖关系。如果没有明确结构,模型必须从语义线索中推断这个图的拓扑结构——这个过程计算成本高,还容易产生循环依赖或丢失关键步骤。
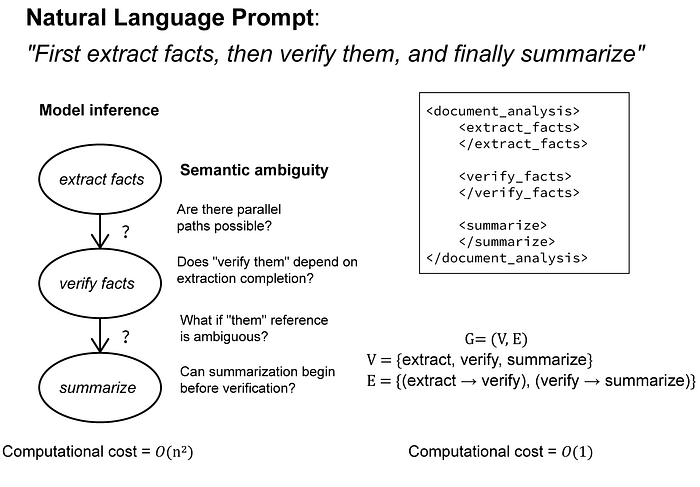
图3:XML的层次结构直接将依赖推理从二次方的语义解释问题转化为线性的图遍历。嵌套结构明确编码了拓扑排序——每个结束标签都提供了明确的完成信号,保证下一阶段的顺利执行。
<document_analysis>
<extract_facts>
识别提供文本中的关键声明和支持证据。
</extract_facts>
<verify_facts>
将提取的声明与你的知识库交叉引用。
标记任何可能不准确的陈述。
</verify_facts>
<summarize>
创建结构化摘要,将已验证事实与未验证声明清楚分离。
</summarize>
</document_analysis>
3. 输出格式化:解决解析之痛
这解决了我们在生产环境中遇到的"信道编码问题"。当后端系统需要解析AI输出时,模糊的自然语言表达会带来很高的错误率。结构化输出提供了明确的分隔符和类型信息,将解析从模式匹配(不可靠)变成了文法识别(确定性)。目标就是让下游系统能够稳定地解析AI输出:
<output_format>
<summary>简要执行摘要(2-3句话)</summary>
<key_findings>
<finding confidence="high">有强证据支持的发现</finding>
<finding confidence="medium">有中等证据支持的发现</finding>
</key_findings>
<recommendations>
<recommendation priority="1">最高优先级行动</recommendation>
<recommendation priority="2">次要行动</recommendation>
</recommendations>
</output_format>
生产系统的高级模式
内存管理解决了跨离散交互的状态持久性数学挑战。多轮对话创建了我们可以建模为马尔可夫链的模型,其中每个响应依赖于先前上下文。没有明确状态跟踪,这种上下文会指数衰减——递减视野的诅咒。
XML状态结构提供在模型内部表示之外持久化关键信息的明确外部内存。这将马尔可夫特性从隐式(隐藏状态)转换为显式(结构化状态),实现更可靠的长期一致性。
<conversation_context>
<user_preferences>
技术水平:专家级
输出风格:简洁带示例
先前主题:API设计,数据库优化
</user_preferences>
<current_session>
<goal>为用户服务设计缓存策略</goal>
<constraints>必须处理10k RPS,延迟低于100ms</constraints>
</current_session>
</conversation_context>
<response_guidelines>
基于先前API设计讨论构建。
在相关地方引用数据库优化模式。
提供具体实现示例。
</response_guidelines>
错误处理通过明确条件语句引入形式逻辑原则。我们不是希望模型通过训练适当处理边缘情况,而是为错误条件提供逻辑框架:
<error_handling>
<if condition="数据不足">
明确指定需要哪些额外信息。
不要做假设或提供占位符响应。
</if>
<if condition="请求模糊">
询问需要澄清的具体方面的问题。
为用户提供2-3个解释选项供选择。
</if>
</error_handling>
多智能体协调利用分布式系统理论原则。当多个AI智能体协作时,协调失败创建同步问题。XML工作流结构提供明确交接协议,消除竞态条件并确保智能体间的适当信息流。
<agent_workflow>
<researcher>
收集关于主题的相关信息。
专注于最新发展和可信来源。
在<research_results>标签中输出发现。
</researcher>
<analyst>
处理research_results以识别模式和含义。
在<analysis_findings>标签中输出分析。
</analyst>
<writer>
将analysis_findings转换为用户友好的建议。
匹配用户指定的技术水平和格式偏好。
</writer>
</agent_workflow>
结构化协调将潜在混乱的多智能体交互转换为具有明确定义状态间转换的确定性有限状态机。
实际落地的技术考量
在工程实践中,XML提示技术需要考虑几个关键因素,这些都直接影响系统的成本效益比:
- 模型适配性:不同模型对XML的支持差异巨大。GPT-4、Claude 3.5、Llama 3.3这些新一代模型处理复杂嵌套结构很稳定,但老模型或小模型经常在多层嵌套时出问题。上线前务必做充分测试。
- 成本权衡:XML格式会增加10-25%的token消耗,看起来不少。但考虑到减少的调试时间、更低的故障率和更好的系统稳定性,这个投入完全值得。做过大规模AI应用的都明白这个账。
- 开发流程:把提示当代码管理——版本控制、单元测试、持续集成,一套标准化流程下来,XML的结构化特性让问题定位变得简单多了。
为什么现在必须关注这个技术
AI正在从聊天工具向自主智能体转变,这个趋势让提示工程的重要性急剧上升。当AI开始自主决策、调用API、操作数据库时,一个不稳定的提示就可能造成实际损失。
XML提示技术为构建生产级AI系统提供了坚实基础。它不追求理论上的完美,而是专注于工程上的可靠——在用户输入不可预测、失败代价高昂的真实环境中,稳定运行的系统才是王道。从简单的单轮对话到复杂的多智能体协作,这套方法论都经得起考验。
最关键的是,XML提示让AI系统的行为变得可预测、可调试——这在关键业务场景下是无价的。
建议从当前项目开始尝试XML提示。先解决最痛的可靠性和安全性问题,不要贪多求全。目标很明确:构建真正能用的系统,而不是炫技。
引用
- Bai, Y., et al. (2022). “Constitutional AI: Harmlessness from AI Feedback.” Anthropic Technical Report. 可访问:https://www.anthropic.com/research/constitutional-ai-harmlessness-from-ai-feedback
- Brown, T., et al. (2020). “Language Models are Few-Shot Learners.” Advances in Neural Information Processing Systems, 33, 1877–1901.
- Dhuliawala, S., et al. (2023). “Chain-of-Verification Reduces Hallucination in Large Language Models.” arXiv preprint arXiv:2309.11495.
- OpenAI. (2023). “GPT-4 Technical Report.” arXiv preprint arXiv:2303.08774.
- Vaswani, A., et al. (2017). “Attention is All You Need.” Advances in Neural Information Processing Systems, 30, 5998–6008.
- Wang, X., et al. (2022). “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” International Conference on Learning Representations.
- Wei, J., et al. (2022). “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” Advances in Neural Information Processing Systems, 35, 24824–24837.
- Yang, C., et al. (2023). “Large Language Models as Optimizers.” arXiv preprint arXiv:2309.03409.
理论来源
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. [transformer架构和注意力机制基础]
- MacKay, D. J. (2003). Information Theory, Inference and Learning Algorithms. Cambridge University Press. [信息论基础]
- Rogers, A., Kovaleva, O., & Rumshisky, A. (2020). “A Primer in Neural Network Models for Natural Language Processing.” Journal of Artificial Intelligence Research, 57, 615–686. dge University Press. [信息论基础]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 32
32 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)