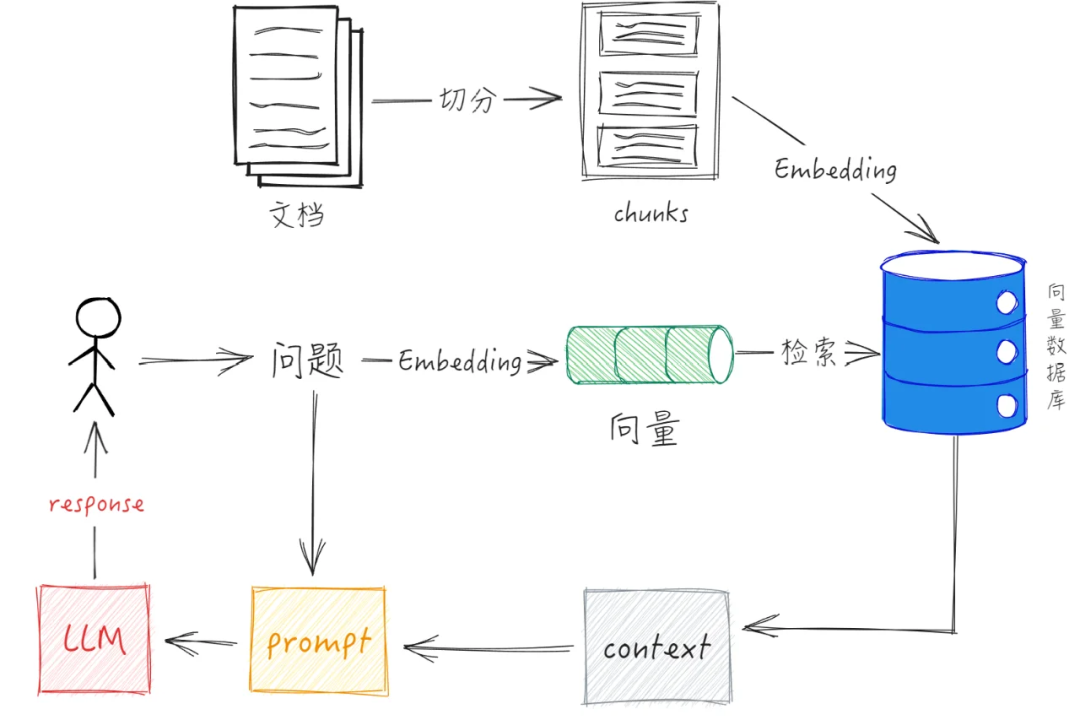
RAG系统意图识别 | 为什么问题意图识别在RAG中至关重要?
问题意图识别在RAG系统中至关重要,能避免无关检索、优化生成质量并实现对话路由。核心实现包括LLM零样本学习、微调分类器和基于规则的方法,通常贯穿于查询重写、意图分类和元数据过滤等环节。高级技巧包括结合对话历史、动态元数据获取和意图感知检索。通过精准识别用户深层需求,RAG系统能显著提升回答质量,发挥AI大模型的潜力。随着AI技术快速发展,掌握意图识别等核心技能将为从业者带来重要机遇。
主要内容
简单来说,问题意图识别的核心目标是:准确理解用户问题的深层含义、真实目的和所需的知识领域,而不仅仅是字面关键词匹配。
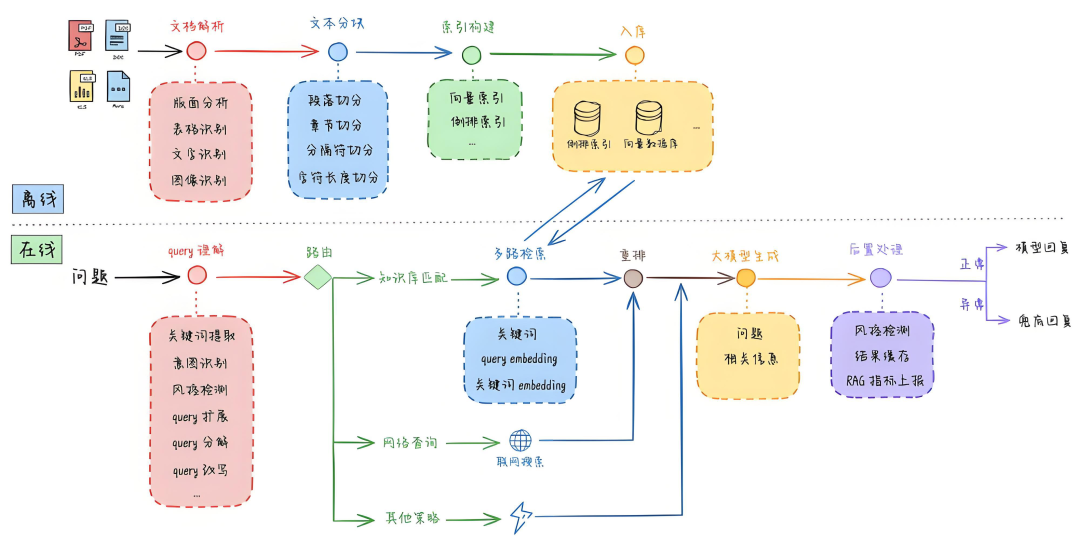
下面从为何重要、如何实现、技术方法和高级技巧四个方面详细阐述。
1. 为什么问题意图识别在RAG中至关重要?
没有良好的意图识别,RAG系统会表现得“很傻”:
检索无关内容:如果用户问“苹果最新款手机有什么新功能?”,系统可能检索到关于“水果苹果”的文档,仅仅因为“苹果”这个词匹配了。
无法处理复杂查询:对于“比较一下特斯拉和比亚迪在2023年的市场策略”这类需要多步推理和整合信息的问题,简单的关键词检索会失败。
误解用户真实需求:用户问“公司的报销流程是什么?”,其真实意图可能是“如何快速完成报销”,而流程文档可能并未强调“快速”的技巧。
资源浪费:向大语言模型(LLM)输入大量无关的检索上下文,会增加计算成本、延长响应时间,并可能导致LLM产生混淆,生成质量更差的答案。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
良好的意图识别能:
1)提升检索精度:引导向量数据库或搜索引擎找到最相关的知识片段。
2)优化生成质量:为LLM提供更精准的上下文,使其能生成更相关、更专业的回答。
3)实现对话路由:判断用户意图是属于问答、文档总结、数据查询还是闲聊,从而触发不同的处理流程。
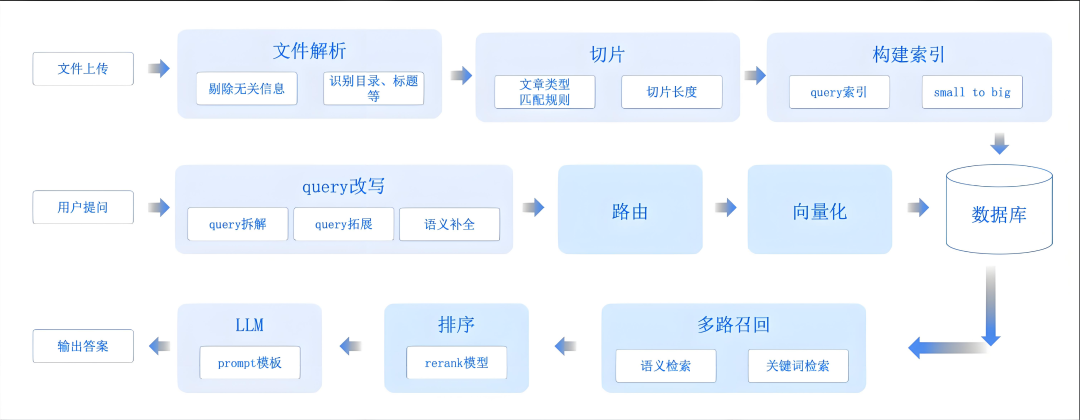
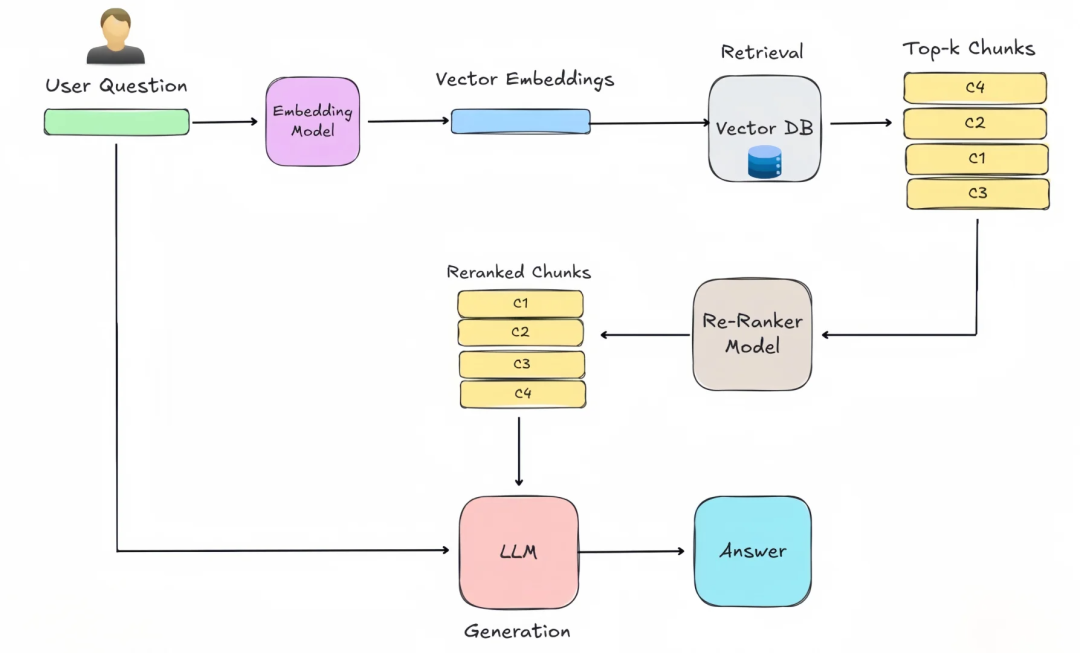
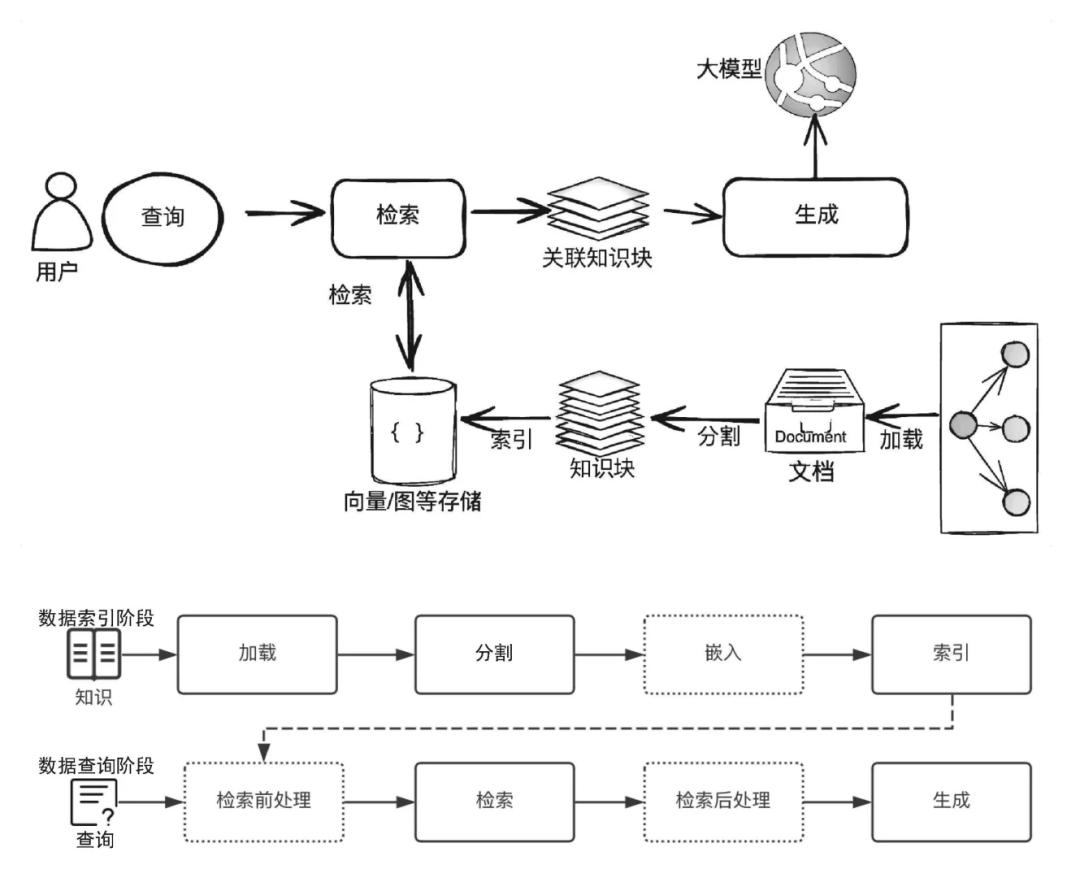
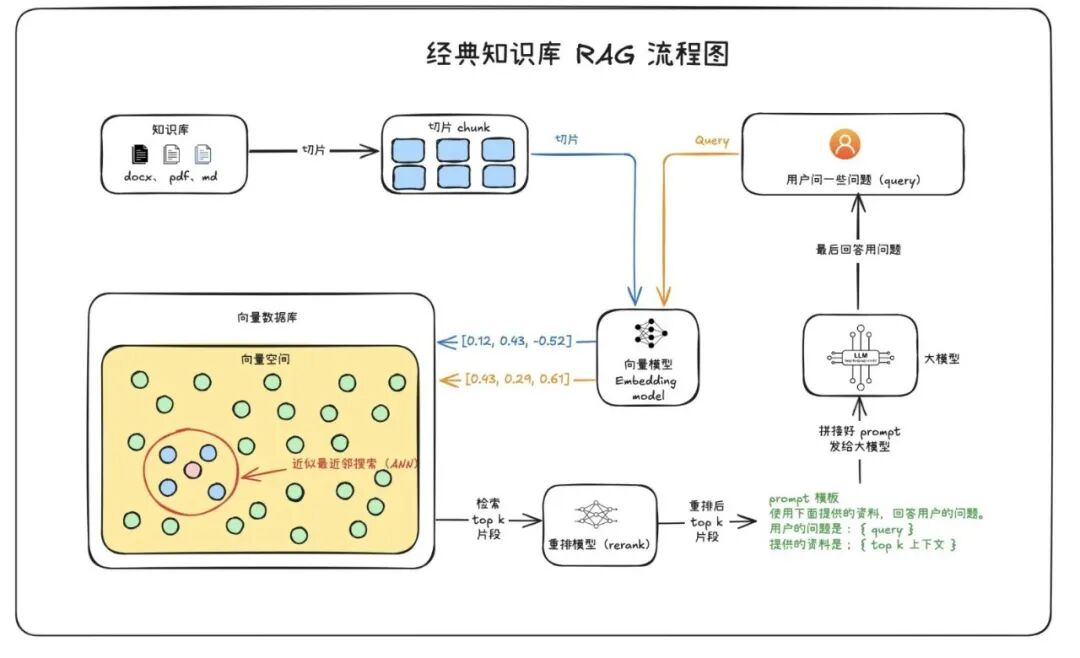
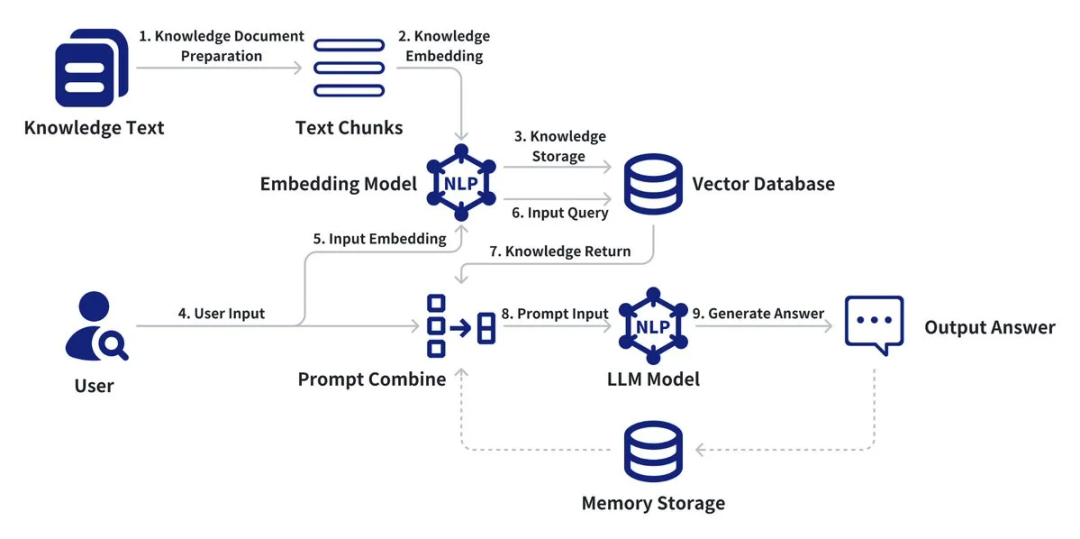
2. 在RAG流水线中,意图识别是如何实施的?
意图识别通常不是单一模块,而是贯穿于RAG流程的多个环节。一个典型的集成流程如下:
用户输入:用户提出原始问题(Query)。
意图识别与查询重写(核心环节):系统使用LLM或分类器对原始Query进行分析。
输出可能包括:
改写后的查询(Rewritten Query):更清晰、更完整、包含同义词或排除歧义词。(例如:“苹果手机” -> “iPhone”)
意图分类(Intent Classification):如[文档问答, 数据查询, 概念解释, 比较分析, 代码生成]。
元数据过滤条件(Metadata Filtering):如{“category”: “technology", “date”: ">2023”}。
检索:使用改写后的查询和元数据条件,在向量数据库或全文检索系统中进行相似性搜索,获取最相关的知识片段(Contexts)。
生成:将原始问题、识别出的意图、检索到的上下文一同提供给LLM,指令LLM根据这些信息生成最终答案。
意图信息可以作为系统提示词的一部分,指导LLM的回答风格和侧重点。
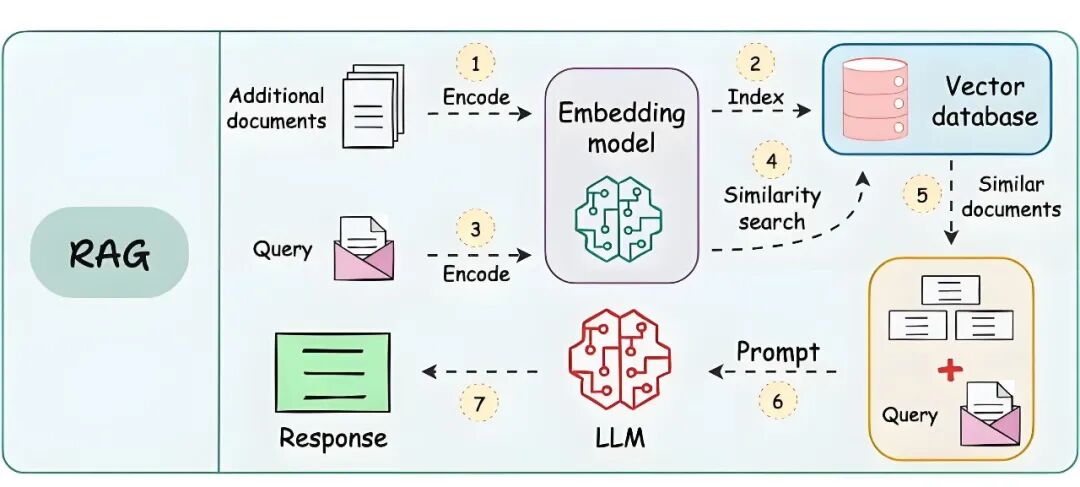
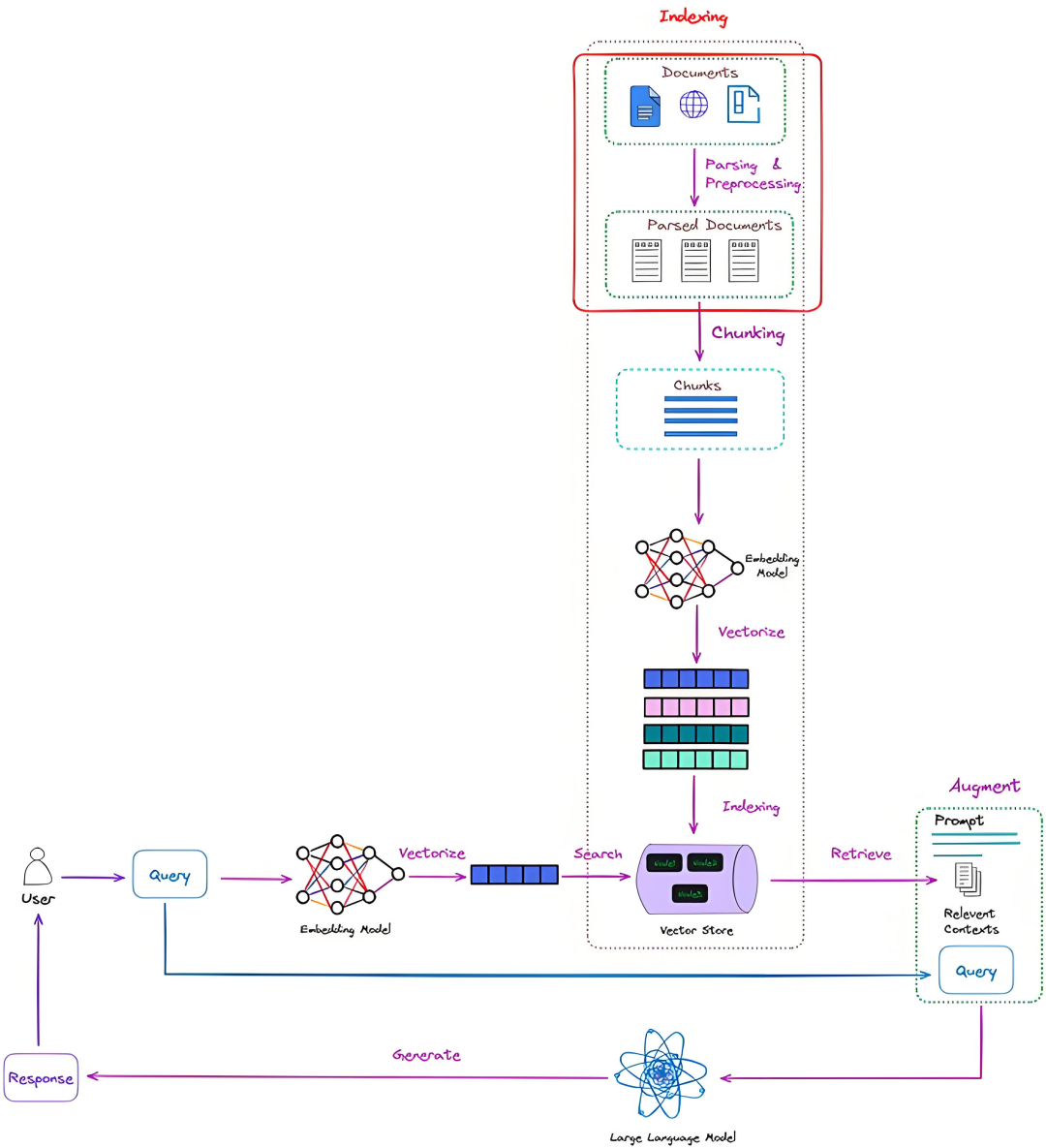
3. 如何具体实现意图识别?(技术方法)
方法一:基于LLM的零样本/少样本学习(最流行、最灵活)
这是目前最主流的方法,利用LLM强大的自然语言理解能力,通过精心设计的提示词(Prompt)来让其完成意图识别任务。
示例Prompt:
你是一个专业的查询意图分析助手。请分析用户问题的意图,并输出一个JSON对象。
分析步骤:
1)理解核心意图:判断用户意图属于哪一类。
document_qa: 从特定文档中寻找事实性答案。
concept_explanation: 解释某个概念或术语。
comparison: 比较两个或多个实体。
procedural_help: 寻求某个流程或操作的指导。
data_query: 询问具体数据(如数字、日期、统计信息)。
other: 其他意图。
2)提取关键信息:识别问题中的核心实体、关键词、时间范围等。
3)生成搜索查询:改写为一个更利于知识库检索的查询语句。
4)提供元数据建议:建议检索时应使用的元数据过滤器。
用户问题: {user_query}
输出格式(严格的JSON):
优点:无需训练数据,非常灵活,能处理复杂和未知的意图。
缺点:依赖LLM能力,有一定的延迟和成本。
方法二:微调分类器(传统、高效、精准)
如果有大量已标注的用户查询数据,可以训练一个专门的意图分类模型。
模型选择:可以选择轻量级的模型如BERT、RoBERTa等。
流程:
1) 收集数据,并为每个查询打上意图标签。
2)在标注数据上对预训练模型进行微调(Fine-tuning)。
3)将训练好的模型部署为API,在RAG流程中调用。
优点:速度快(推理延迟低),成本低,对特定领域意图识别非常精准。
缺点:需要标注数据,难以覆盖所有未知意图,灵活性较差。
方法三:基于规则和关键词(简单、快速)
对于意图非常明确的简单场景,可以使用规则方法。
示例:
如果问题包含“如何”、“怎样”、“步骤”,则意图为procedural_help。
如果问题包含“vs”、“ versus”、“对比”、“比较”,则意图为comparison。
使用正则表达式匹配特定模式(如日期、产品型号)。
优点:实现简单,速度极快,完全可控。
缺点:难以处理复杂语言和歧义,维护成本高,扩展性差。
通常,实践中会采用混合策略:先用规则处理明显意图,再用LLM处理复杂和模糊的情况。
4. 高级技巧与最佳实践
结合对话历史(多轮意图识别):在聊天机器人场景中,当前的用户问题可能是模糊的(如“它怎么样?”),需要结合之前的对话历史来理解真正意图。
可以将整个对话历史作为上下文提供给LLM进行分析。
动态元数据获取:先识别出用户问题中的实体(如产品名、人名),然后去知识库中查询这些实体可能存在的元数据(如所属部门、项目编号),再将这些元数据作为过滤条件进行二次检索,极大提升精度。
意图感知的检索:不同的意图可能需要不同的检索策略。
comparison(比较)意图:可能需要分别检索两个实体的文档,然后让LLM进行对比。
data_query(数据查询)意图:可能需要优先检索表格、数据库等结构化数据。
迭代式检索:LLM先分析问题,发现需要多步检索。例如,先检索“什么是A?”,理解A之后,再基于这个理解去检索“A和B的区别”。
总结
在RAG中,问题意图识别远不止简单的关键词提取,它是一个深度理解、推理和规划的过程。
通过大型语言模型(LLM) 作为意图识别的核心引擎,结合提示工程、元数据过滤和查询重写,可以构建一个智能的“交通指挥系统”。
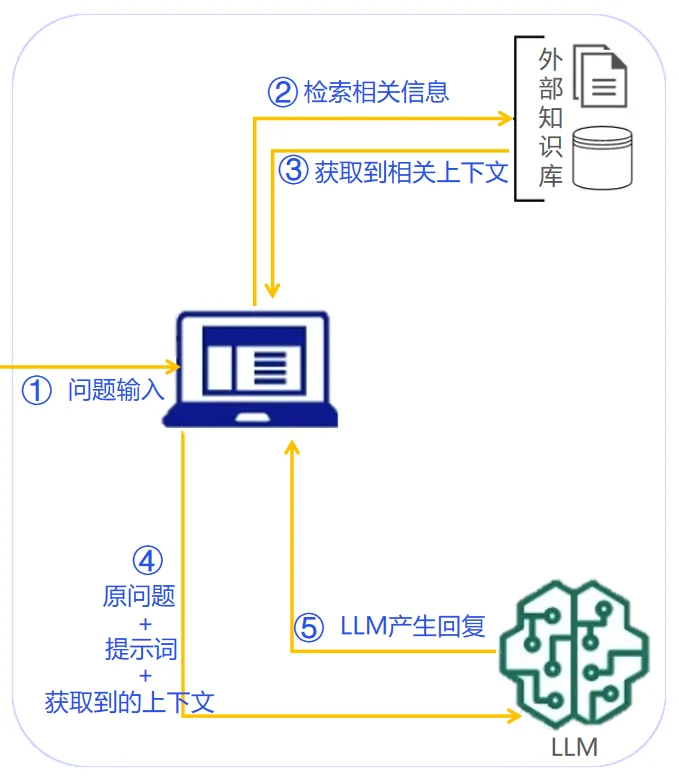
确保正确的信息被检索并传递给LLM,从而最终生成高质量、高相关性的答案,真正发挥RAG的巨大潜力。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)