构建稳定、高效、弹性且易于维护的大模型多副本生产环境
大模型多副本部署技术要求涵盖基础设施、编排管理、流量调度和监控运维等关键环节。基础设施需满足GPU独占、高速网络和共享存储等要求;部署编排依赖Kubernetes实现容器化管理和自动扩缩;流量管理通过负载均衡、健康检查等机制保障服务稳定性;监控体系需覆盖指标、日志和链路追踪。采用容器化、服务网格等技术方案,可实现高可用、高并发的大模型推理服务。
·
关于大模型多副本部署技术要求的详细说明。多副本部署是实现高可用、高并发服务的关键,其技术要求覆盖了基础设施、部署编排、流量管理、监控运维等多个层面。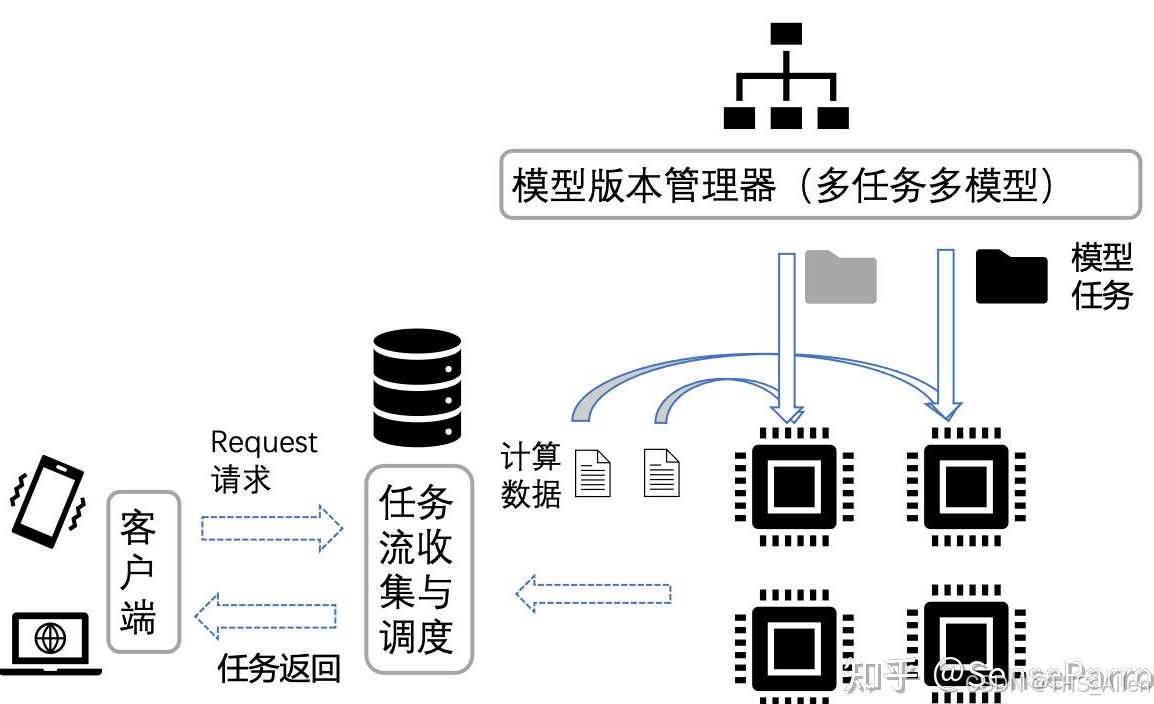
大模型多副本部署核心技术要求
多副本部署的核心目标是:通过部署多个完全相同的模型实例,共同分担用户请求,从而实现高可用、高并发、可扩展且稳定的推理服务。
🔧 一、基础设施要求
1. 计算资源
- GPU 资源:
- 需求:每个模型副本必须能够独占或共享(通过 MIG/vGPU 等技术)所需的 GPU 资源。
- 要求:集群需具备足够的 GPU 卡(如 A100/H100/A800等),并能灵活分配给不同副本。算力与显存都必须满足模型运行的最低要求。
- CPU 与内存:
- 需求:虽然计算主要在 GPU,但 CPU 负责数据预处理/后处理和流程控制,内存用于加载模型权重和临时数据。
- 要求:配置合理的 CPU 核心数和内存大小(通常建议 1:4 到 1:8 的 GPU 显存与系统内存比例)。
2. 网络资源
- 高带宽、低延迟:
- 需求:节点间(尤其是 GPU 服务器之间)需要高速互联。
- 要求:推荐使用 RDMA 技术(如 InfiniBand 或 RoCEv2),以降低多副本部署中模型权重同步(如果涉及)、监控数据采集和负载均衡器分流的延迟。
- 网络策略:
- 需求:严格控制网络访问。
- 要求:配置防火墙和 Kubernetes Network Policies,确保只有负载均衡器和授权服务能访问模型副本的端口。
3. 存储资源
- 共享模型存储:
- 需求:所有副本必须加载完全相同版本的模型文件。
- 要求:使用高性能共享存储(如 NFS、CephFS、对象存储 S3/MinIO)存放模型文件。避免每个节点本地重复存储,便于版本管理和统一更新。
- 持久化存储:
- 需求:记录日志、监控指标和可能的输出内容。
- 要求:配置可扩展的持久化卷(PV),用于存储日志和临时数据。
🧩 二、部署与编排要求
1. 容器化
- 需求:实现环境隔离、依赖管理和快速部署。
- 要求:
- 将模型、推理代码、依赖库等打包成 Docker 镜像。
- 镜像应尽可能轻量化,并使用多阶段构建减少体积。
- 指定明确的启动命令和健康检查接口。
2. 编排系统
- 需求:自动化地部署、管理和伸缩多个副本。
- 要求:必须使用 Kubernetes。
- 使用 Deployment 或 StatefulSet 资源定义副本数(
replicas),K8s 会确保始终有指定数量的 Pod 在运行。 - 为 Pod 配置 Resource Requests/Limits(
nvidia.com/gpu,cpu,memory),帮助 K8s 调度器做出正确的决策,避免资源竞争。
- 使用 Deployment 或 StatefulSet 资源定义副本数(
3. 服务发现与负载均衡
- 需求:客户端无需知道所有副本地址,流量应自动、均匀地分发到健康副本上。
- 要求:
- 使用 Kubernetes Service(如
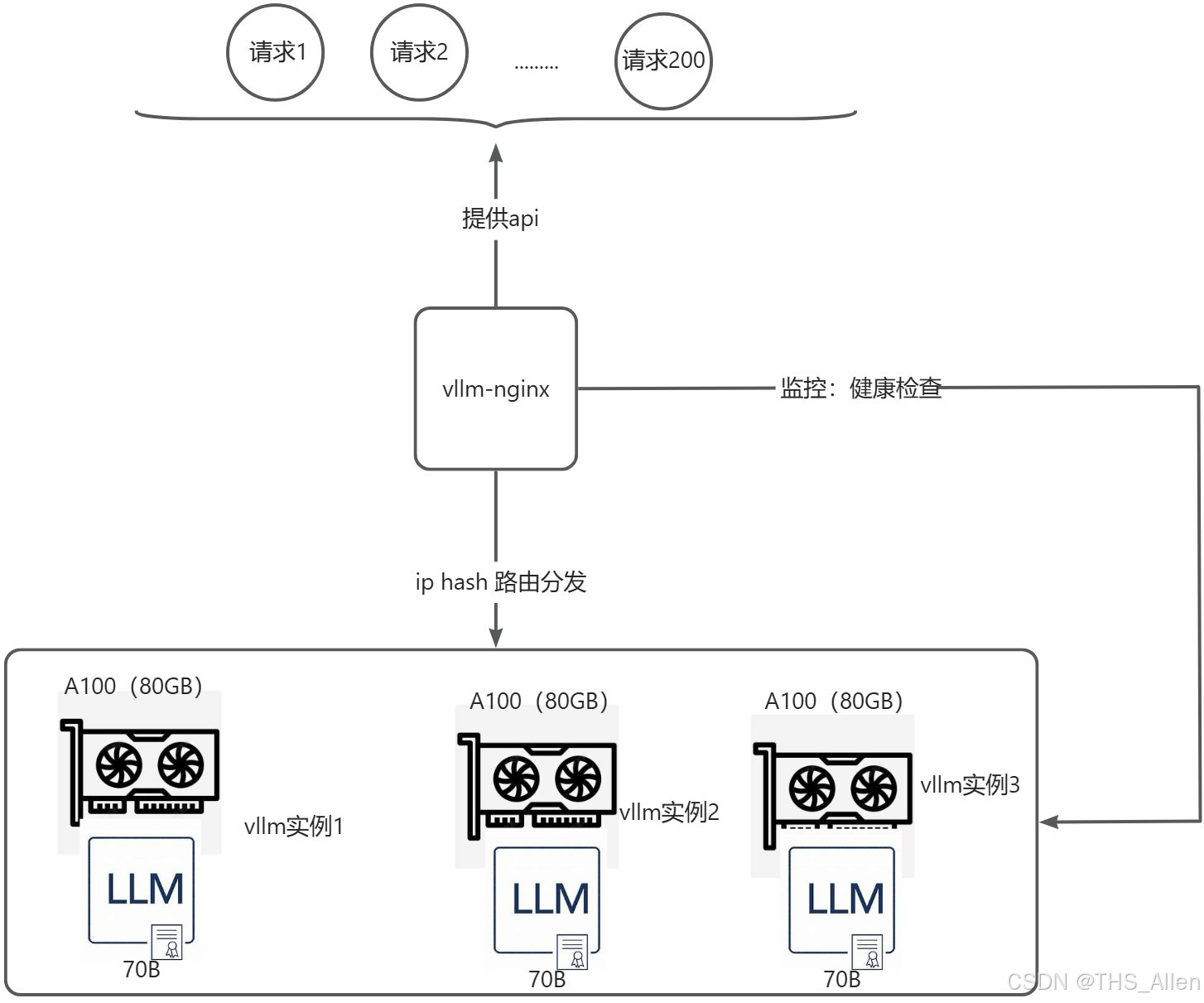
ClusterIP或LoadBalancer)为一组 Pod 副本提供稳定的访问入口和内部负载均衡。 - 对于更高级的策略(如一致性哈希、基于 GPU 利用率的负载均衡),可以使用 Ingress Controller(如 Nginx, Traefik)或 服务网格(如 Istio)。
- 使用 Kubernetes Service(如
📊 三、流量管理与调度要求
1. 负载均衡策略
- 需求:避免单个副本过载,充分利用所有资源。
- 要求:负载均衡器应支持:
- 轮询:最基本的策略。
- 最少连接:将新请求发送给当前连接数最少的副本。
- IP Hash:保证同一客户端的请求总是落到同一个副本上(有助于保持会话,但可能破坏负载均衡)。
2. 弹性伸缩
- 需求:根据实时负载动态调整副本数量,以应对流量高峰和低谷,节约成本。
- 要求:使用 Kubernetes HPA。
- 配置 HPA 基于自定义指标(如 QPS、GPU 利用率、请求延迟)自动扩缩容。
- 示例:当平均 QPS 超过 50 时,自动增加副本;当低于 10 时,自动减少副本。
3. 健康检查
- 需求:及时隔离不健康的副本,防止将流量路由到无法正常服务的实例。
- 要求:在 K8s Pod 定义中配置:
- 就绪探针:检查副本是否已完成加载并准备好接收流量。未通过检查的副本会从 Service 的负载均衡池中移除。
- 存活探针:检查副本进程是否还在运行。如果检查失败,K8s 会重启该 Pod。
⚙️ 四、监控、日志与可观测性要求
1. 指标监控
- 需求:实时掌握系统健康状况和性能表现。
- 要求:
- 基础设施监控:节点 GPU/CPU/内存/网络使用率。
- 应用层监控:每个副本的 QPS、吞吐量(Tokens/s)、请求延迟(P50, P90, P99)、错误率。
- 工具:Prometheus 采集指标,Grafana 制作可视化看板。
2. 日志收集
- 需求:集中查看和分析所有副本的日志,便于排查问题。
- 要求:
- 每个副本应将日志输出到标准输出(stdout)。
- 使用 ELK Stack 或 Loki 等工具集中收集、存储和查询日志。
3. 链路追踪
- 需求:当一个请求经过多个服务(如网关->负载均衡器->模型副本)时,能够追踪其完整路径,分析性能瓶颈。
- 要求:集成 Jaeger 或 SkyWalking 等分布式追踪系统。
🛡️ 五、安全与合规要求
- 网络隔离:使用命名空间和网络策略隔离生产环境。
- 访问控制:对模型的 API 接口实施认证和授权(如 API Key、JWT Token)。
- 数据安全:对传输中的数据进行加密(HTTPS/TLS),对敏感数据进行脱敏处理。
💎 六、最佳实践总结
| 技术要求 | 推荐工具/方案 | 目的 |
|---|---|---|
| 容器化 | Docker | 环境一致性,隔离性 |
| 编排调度 | Kubernetes (Deployment) | 自动化部署、管理、扩缩容 |
| 服务发现 | Kubernetes Service | 提供稳定访问端点 |
| 负载均衡 | Nginx Ingress, Istio | 智能分流,提高吞吐量 |
| 弹性伸缩 | K8s HPA (基于 Prometheus 指标) | 根据负载自动调整副本数,降本增效 |
| 监控指标 | Prometheus + Grafana | 实时掌握系统性能与健康状态 |
| 日志收集 | Loki, ELK Stack | 集中日志管理,便于故障排查 |
| 模型存储 | 共享存储 (NFS, S3) | 统一模型版本,快速部署副本 |
| 健康检查 | K8s Liveness/Readiness Probes | 自动隔离故障节点,保证服务可用性 |
通过满足以上技术要求,可以构建一个稳定、高效、弹性且易于维护的大模型多副本生产环境,从容应对高并发业务场景。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)