火山方舟AI应用实验室(AI App Lab)全面解析:构建AI大模型应用的一站式解决方案
火山方舟AI应用实验室(AI App Lab)全面解析:构建AI大模型应用的一站式解决方案
火山方舟AI应用实验室(AI App Lab)全面解析:构建AI大模型应用的一站式解决方案
官网:https://github.com/volcengine/ai-app-lab
前言
在人工智能快速发展的今天,将大模型技术真正落地到实际业务场景中是一个既复杂又极具挑战性的任务。开发者不仅需要深入理解行业业务背景,还需要解决模型接口调用、多种插件协同适配、多模态深度融合交互、各类工具调用等一系列技术难题。
为了解决这些痛点,字节跳动火山方舟团队推出了AI App Lab——一个包含高代码SDK Arkitect和海量原型应用代码的综合性开发平台,旨在帮助中小企业开发者快速构建符合自身业务场景的AI大模型应用,真正打通大模型应用落地的最后一公里。
一、项目整体架构概览
1.1 核心设计理念
AI App Lab采用分层设计理念,从底层SDK到上层应用实例,为开发者提供了完整的AI应用开发链路:
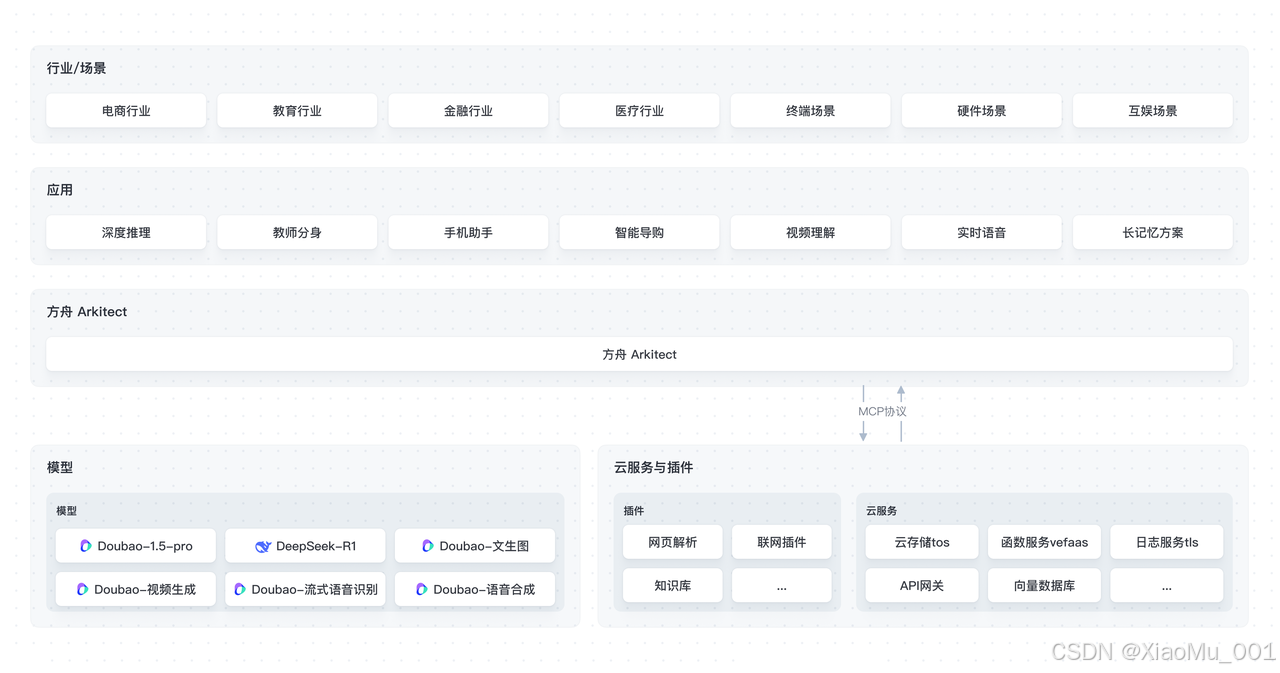
1.2 项目结构
ai-app-lab/
├── arkitect/ # 高代码Python SDK
├── demohouse/ # 海量原型应用代码
├── docs/ # 文档和集成指南
├── examples/ # 快速入门示例
├── mcp/ # MCP服务器实现
└── tests/ # 测试代码
二、Arkitect高代码SDK深度解析
2.1 SDK核心特性
Arkitect是火山方舟推出的专业级Python SDK,面向具有开发能力的企业开发者设计。其核心优势包括:
✨ 高度定制化
- 提供高代码智能体应用编排方式
- 灵活服务客户高度定制化和自定义需求
- 支持复杂业务逻辑的实现
🛠️ 丰富的业务工具
- 高质量、有保障的业务工具集
- 丰富的业务插件库与工具链
- 支持与先进大模型的组合串联
🔧 一站式开发与托管
- 简化智能体应用部署和管理流程
- 增强系统稳定性
- 提供完整的开发生命周期支持
🔒 安全可靠
- 火山方舟安全加固实践
- 增强业务数据安全性和保密性
- 降低数据泄漏风险
2.2 技术架构设计
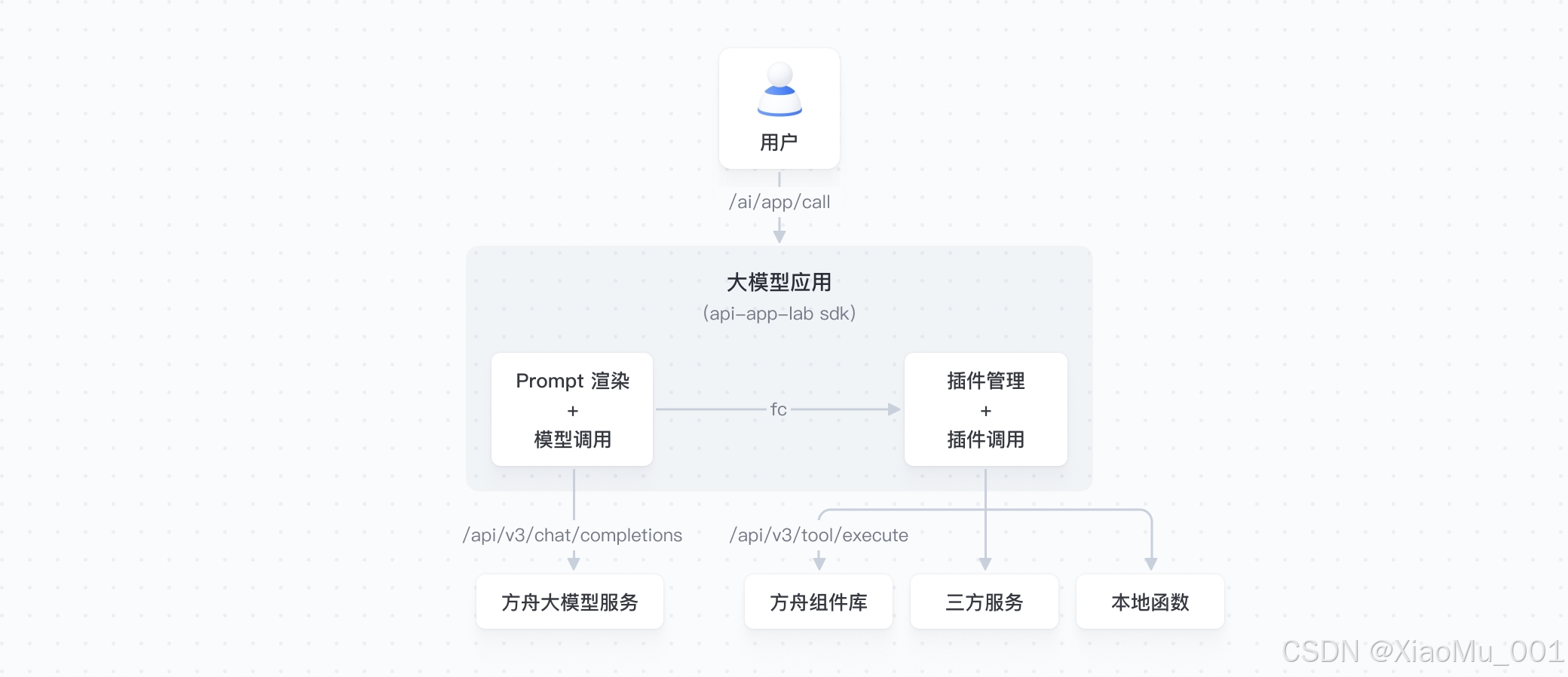
Arkitect采用模块化设计,主要包含以下核心组件:
arkitect/
├── core/ # 核心组件
│ ├── client/ # 客户端组件
│ ├── component/ # 业务组件
│ ├── errors/ # 错误处理
│ ├── runtime/ # 运行时
│ └── utils/ # 工具类
├── launcher/ # 启动器
├── telemetry/ # 遥测监控
└── types/ # 类型定义
2.3 核心功能特性
| 功能模块 | 功能描述 | 应用场景 |
|---|---|---|
| Prompt渲染及模型调用 | 简化调用模型时的prompt渲染和结果处理流程 | 所有AI对话场景 |
| 插件调用 | 支持插件本地注册、管理及对接FC模型自动化调用 | 工具调用、API集成 |
| Trace监控 | 支持对接OTEL协议的trace管理及上报 | 性能监控、问题排查 |
2.4 快速上手示例
基础聊天实现
"""基础LLM聊天示例"""
import os
from typing import AsyncIterable, Union
from arkitect.core.component.context.context import Context
from arkitect.types.llm.model import (
ArkChatCompletionChunk,
ArkChatParameters,
ArkChatRequest,
ArkChatResponse,
Response,
)
from arkitect.launcher.local.serve import launch_serve
from arkitect.telemetry.trace import task
@task()
async def default_model_calling(
request: ArkChatRequest,
) -> AsyncIterable[Union[ArkChatCompletionChunk, ArkChatResponse]]:
parameters = ArkChatParameters(**request.__dict__)
ctx = Context(model="doubao-1.5-pro-32k-250115", parameters=parameters)
await ctx.init()
messages = [
{"role": message.role, "content": message.content}
for message in request.messages
]
resp = await ctx.completions.create(messages=messages, stream=request.stream)
if request.stream:
async for chunk in resp:
yield chunk
else:
yield resp
if __name__ == "__main__":
port = os.getenv("_FAAS_RUNTIME_PORT")
launch_serve(
package_path="main",
port=int(port) if port else 8080,
health_check_path="/v1/ping",
endpoint_path="/api/v3/bots/chat/completions",
clients={},
)
工具调用(Function Calling)实现
"""Function Calling示例"""
from arkitect.core.component.context.model import ToolChunk
def adder(a: int, b: int) -> int:
"""Add two integer numbers
Args:
a (int): first number
b (int): second number
Returns:
int: sum result
"""
return a + b
@task()
async def default_model_calling(
request: ArkChatRequest,
) -> AsyncIterable[Union[ArkChatCompletionChunk, ArkChatResponse]]:
parameters = ArkChatParameters(**request.__dict__)
ctx = Context(
model="deepseek-v3-241226",
tools=[adder], # 注册工具函数
parameters=parameters,
)
await ctx.init()
# ... 其余逻辑与基础聊天类似
三、Demohouse原型应用深度剖析
Demohouse是AI App Lab的应用展示区,包含了从教育、娱乐、办公到企业服务等多个垂直领域的AI原型应用。每个应用都是开源的完整解决方案,开发者可以"一键复制"并根据自己的业务需求进行定制。
3.1 应用概览
| 应用类别 | 应用名称 | 核心功能 | 技术特点 |
|---|---|---|---|
| 内容创作 | 互动双语视频生成器 | 主题生成富有寓意的双语视频 | 文生图+视频生成+语音合成 |
| 智能问答 | 深度推理 | 复杂问题多角度分析 | DeepSeek-R1+联网搜索 |
| 实时交互 | 语音实时通话-青青 | 虚拟角色语音对话 | 低延时WebSocket |
| 视觉理解 | 视频实时理解 | 摄像头画面实时分析 | 视觉大模型+记忆系统 |
| 移动端 | 手机助手 | 移动端智能助手 | 跨平台部署 |
| 教育场景 | 教师分身 | 智能教育解决方案 | 视觉理解+深度推理 |
3.2 重点应用详解
3.2.1 互动双语视频生成器(Chat2Cartoon)
这是一款为内容创作打造的创新工具,能够根据用户输入的主题快速生成富有寓意的双语视频。
核心技术栈:
- Doubao-Seed-1.6:生成故事大纲与分镜脚本
- Doubao-Seedream-3.0-t2i:创作故事角色和分镜画面
- Doubao-语音合成:生成配音文件
- Doubao-Seedance-1.0-lite:生成分镜动画视频
技术实现亮点:
- 流程状态机设计
用户输入主题 → 脚本创建 → 分镜创建 → 角色描述 → 角色画像
→ 首帧描述 → 首帧画像 → 视频描述 → 视频生成 → 音色对话
→ 音频生成 → 影片合成
- 前后端交互协议
{
"Messages": [
{
"content": "写个龟兔赛跑的故事",
"role": "user"
},
{
"content": "phase=Script\n\n「故事脚本...」",
"role": "assistant"
}
]
}
3.2.2 深度推理(Deep Search)
利用DeepSeek-R1大模型的强大推理能力,对复杂问题进行多角度分析,并结合互联网资料生成最优解决方案。
核心架构:
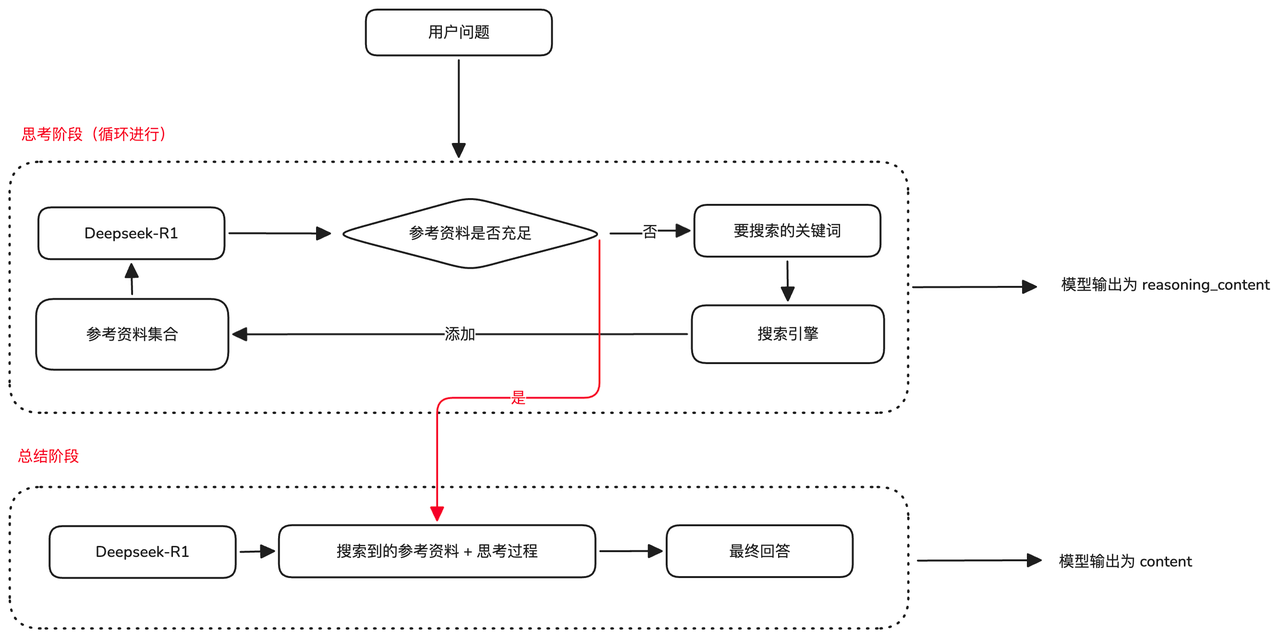
技术实现特点:
-
两阶段处理流程
- 思考阶段:DeepSeek-R1循环使用搜索引擎获取参考资料
- 总结阶段:基于收集的资料和思考过程生成总结性回答
-
多搜索引擎支持
- 火山方舟零代码联网应用
- Tavily开源搜索引擎
- 其他自定义Search API
-
标准API兼容
# 严格遵循OpenAI Chat Completion API规范 { "reasoning_content": "思考过程", "content": "最终答案" }
3.2.3 语音实时通话-青青
打造沉浸式虚拟角色语音对话体验,实现近乎实时的对话响应。
技术架构特点:
-
低延时WebSocket方案
- 易于实现和部署
- 跨平台兼容性好
- 高效资源利用
-
二进制协议设计
┌─────────────────────────────────────────────────────┐
│ Protocol version(4bit) │ Header size(4bit) │
├─────────────────────────────────────────────────────┤
│ Message type(4bit) │ Message flags(4bit) │
├─────────────────────────────────────────────────────┤
│ Serialization(4bit) │ Compression(4bit) │
├─────────────────────────────────────────────────────┤
│ Reserved(8bit) │
├─────────────────────────────────────────────────────┤
│ Payload (JSON/Binary) │
└─────────────────────────────────────────────────────┘
- 事件驱动交互
// 主要事件类型
{
"BotReady": "连接建立成功",
"SentenceRecognized": "语音识别完成",
"TTSSentenceStart": "开始语音合成",
"TTSDone": "语音输出完成"
}
3.2.4 视频实时理解(Video Analyser)
基于豆包视觉理解模型,实现对摄像头传输实时画面的深度分析和理解。
核心技术实现:
-
双重请求策略优化延时
- 包含所有长期记忆的请求
- 仅包含当前问题和图像的请求
- 智能选择最优回答路径
-
长期记忆压缩机制
# 使用VLM对图片信息进行总结,只存储总结信息 def compress_memory(frame_image): summary = vlm.summarize(frame_image) memory_store.save(summary) # 而非原始图片 -
前后端交互约定
- 实时抽帧请求:每秒发送图片,存入长期记忆
- 用户提问请求:包含问题文字和当前图片,返回语音回复
四、企业级应用场景
4.1 智能驾舱解决方案
为汽车行业提供车载智能交互系统:
# 车载场景示例
class CarAssistant:
def __init__(self):
self.ctx = Context(
model="doubao-pro-32k",
tools=[
weather_query, # 天气查询
music_control, # 音乐控制
navigation, # 导航功能
car_control # 车机控制
]
)
async def handle_voice_command(self, audio_input):
# 语音识别
text = await self.asr.recognize(audio_input)
# 智能理解和执行
response = await self.ctx.completions.create(
messages=[{"role": "user", "content": text}]
)
# 语音回复
audio_output = await self.tts.synthesize(response)
return audio_output
4.2 金融智能投顾
为金融行业提供智能投资建议服务:
class FinancialAdvisor:
def __init__(self):
self.ctx = Context(
model="doubao-pro-32k",
tools=[
stock_analysis, # 股票分析
risk_assessment, # 风险评估
portfolio_optimization, # 投资组合优化
market_data_query # 市场数据查询
]
)
async def provide_investment_advice(self, user_profile, query):
# 结合用户画像和市场数据提供个性化建议
messages = [
{"role": "system", "content": f"用户画像:{user_profile}"},
{"role": "user", "content": query}
]
advice = await self.ctx.completions.create(messages=messages)
return advice
4.3 电商库存管理
为电商行业提供智能库存管理解决方案:
class InventoryManager:
def __init__(self):
self.ctx = Context(
model="doubao-pro-32k",
tools=[
inventory_query, # 库存查询
demand_forecast, # 需求预测
supplier_management, # 供应商管理
order_optimization # 订单优化
]
)
async def optimize_inventory(self, current_inventory, sales_data):
# 基于当前库存和销售数据优化库存策略
analysis_prompt = f"""
当前库存情况:{current_inventory}
销售数据:{sales_data}
请分析并提供库存优化建议
"""
optimization_plan = await self.ctx.completions.create(
messages=[{"role": "user", "content": analysis_prompt}]
)
return optimization_plan
五、部署与运维指南
5.1 本地开发环境搭建
环境要求
# Python环境
Python >= 3.10, < 4.0
# Node.js环境(前端应用需要)
Node.js >= 16.2.0
# 包管理工具
Poetry >= 1.6.1
PNPM >= 8.0
快速启动
# 1. 克隆项目
git clone https://github.com/volcengine/ai-app-lab.git
cd ai-app-lab
# 2. 安装Arkitect SDK
pip install arkitect --index-url https://pypi.org/simple
# 3. 配置环境变量
export ARK_API_KEY=your_api_key_here
# 4. 运行示例应用
cd demohouse/video_analyser
bash backend/run.sh # 启动后端
bash frontend/run.sh # 启动前端
5.2 生产环境部署
使用火山方舟高代码应用部署
-
创建高代码应用
- 登录火山方舟控制台
- 选择"创建高代码应用"
- 配置基础信息
-
上传代码包
# 打包项目代码 zip -r code.zip * # 通过控制台上传code.zip -
配置环境变量
ARK_API_KEY=your_api_key LLM_ENDPOINT=your_endpoint_id TTS_APP_ID=your_tts_app_id TTS_ACCESS_TOKEN=your_tts_token -
安装依赖并发布
- 执行"安装依赖"
- 设置执行超时时间(建议900s)
- 点击"发布"完成部署
Docker容器化部署
# Dockerfile示例
FROM python:3.11-slim
WORKDIR /app
# 安装Poetry
RUN pip install poetry==1.6.1
# 复制项目文件
COPY pyproject.toml poetry.lock ./
COPY . .
# 安装依赖
RUN poetry config virtualenvs.create false \
&& poetry install --no-dev
# 启动应用
CMD ["python", "main.py"]
# docker-compose.yml
version: '3.8'
services:
ai-app:
build: .
ports:
- "8080:8080"
environment:
- ARK_API_KEY=${ARK_API_KEY}
- LLM_ENDPOINT=${LLM_ENDPOINT}
volumes:
- ./logs:/app/logs
5.3 监控与运维
性能监控
# 使用OpenTelemetry进行链路追踪
from arkitect.telemetry.trace import task
@task()
async def monitored_function():
# 自动记录执行时间、成功率等指标
pass
日志管理
import structlog
logger = structlog.get_logger()
@task()
async def business_logic():
logger.info("开始处理请求", request_id="12345")
try:
# 业务逻辑
result = await process_request()
logger.info("请求处理成功", result=result)
return result
except Exception as e:
logger.error("请求处理失败", error=str(e))
raise
六、最佳实践与优化建议
6.1 性能优化策略
模型调用优化
# 1. 使用连接池减少连接开销
class OptimizedContext:
def __init__(self):
self.connection_pool = create_connection_pool(
max_connections=10,
keepalive_timeout=300
)
async def create_completion(self, messages):
async with self.connection_pool.get_connection() as conn:
return await conn.create_completion(messages)
# 2. 批量处理减少请求次数
async def batch_process(requests):
tasks = [process_single_request(req) for req in requests]
results = await asyncio.gather(*tasks)
return results
# 3. 缓存常用结果
from functools import lru_cache
@lru_cache(maxsize=1000)
def get_cached_response(prompt_hash):
return cached_results.get(prompt_hash)
内存管理优化
# 1. 长期记忆压缩
class MemoryManager:
def __init__(self, max_memory_size=1000):
self.max_size = max_memory_size
self.memory_store = []
def add_memory(self, new_memory):
if len(self.memory_store) >= self.max_size:
# 移除最旧的记忆
self.memory_store.pop(0)
# 压缩记忆内容
compressed_memory = self.compress(new_memory)
self.memory_store.append(compressed_memory)
def compress(self, memory):
# 使用摘要算法压缩记忆
return summarize(memory)
# 2. 流式处理大文件
async def process_large_file(file_path):
async with aiofiles.open(file_path, 'rb') as f:
async for chunk in f:
yield await process_chunk(chunk)
6.2 安全最佳实践
API密钥管理
import os
from cryptography.fernet import Fernet
class SecureConfig:
def __init__(self):
self.cipher = Fernet(os.environ['ENCRYPTION_KEY'])
def get_api_key(self):
encrypted_key = os.environ['ENCRYPTED_API_KEY']
return self.cipher.decrypt(encrypted_key.encode()).decode()
def set_api_key(self, api_key):
encrypted = self.cipher.encrypt(api_key.encode())
os.environ['ENCRYPTED_API_KEY'] = encrypted.decode()
输入验证与过滤
from pydantic import BaseModel, validator
import re
class UserInput(BaseModel):
message: str
user_id: str
@validator('message')
def validate_message(cls, v):
# 过滤危险字符
if re.search(r'[<>"\']', v):
raise ValueError('消息包含非法字符')
# 限制长度
if len(v) > 10000:
raise ValueError('消息长度超出限制')
return v
@validator('user_id')
def validate_user_id(cls, v):
if not re.match(r'^[a-zA-Z0-9_-]+$', v):
raise ValueError('用户ID格式不正确')
return v
6.3 可扩展性设计
插件系统架构
class PluginManager:
def __init__(self):
self.plugins = {}
def register_plugin(self, name, plugin_class):
"""注册插件"""
self.plugins[name] = plugin_class
def load_plugin(self, name, config):
"""加载插件"""
if name in self.plugins:
return self.plugins[name](config)
raise ValueError(f"插件 {name} 未找到")
def execute_plugin(self, name, *args, **kwargs):
"""执行插件"""
plugin = self.load_plugin(name, {})
return plugin.execute(*args, **kwargs)
# 插件接口定义
class BasePlugin:
def __init__(self, config):
self.config = config
def execute(self, *args, **kwargs):
raise NotImplementedError
微服务架构示例
# API网关
class APIGateway:
def __init__(self):
self.services = {
'llm': 'http://llm-service:8080',
'tts': 'http://tts-service:8080',
'asr': 'http://asr-service:8080'
}
async def route_request(self, service_name, endpoint, data):
service_url = self.services.get(service_name)
if not service_url:
raise ValueError(f"服务 {service_name} 不存在")
async with httpx.AsyncClient() as client:
response = await client.post(
f"{service_url}/{endpoint}",
json=data
)
return response.json()
# 服务发现
class ServiceDiscovery:
def __init__(self):
self.registry = {}
def register_service(self, name, host, port):
self.registry[name] = f"http://{host}:{port}"
def discover_service(self, name):
return self.registry.get(name)
七、成本优化与资源管理
7.1 模型调用成本优化
class CostOptimizer:
def __init__(self):
self.model_costs = {
'doubao-pro-32k': 0.001, # 每1K tokens成本
'doubao-lite': 0.0005,
'deepseek-r1': 0.002
}
def select_optimal_model(self, task_complexity, budget_limit):
"""根据任务复杂度和预算选择最优模型"""
if task_complexity == 'simple' and budget_limit < 0.001:
return 'doubao-lite'
elif task_complexity == 'complex':
return 'deepseek-r1'
else:
return 'doubao-pro-32k'
def estimate_cost(self, prompt, model):
token_count = len(prompt.split()) * 1.3 # 粗略估算
cost_per_token = self.model_costs[model] / 1000
return token_count * cost_per_token
7.2 资源池管理
import asyncio
from typing import Dict, List
class ResourcePool:
def __init__(self, max_size: int = 10):
self.max_size = max_size
self.active_connections: Dict[str, any] = {}
self.available_connections: List[any] = []
self.lock = asyncio.Lock()
async def get_connection(self):
async with self.lock:
if self.available_connections:
return self.available_connections.pop()
elif len(self.active_connections) < self.max_size:
conn = await self.create_connection()
conn_id = str(id(conn))
self.active_connections[conn_id] = conn
return conn
else:
# 等待可用连接
await self.wait_for_available_connection()
return await self.get_connection()
async def release_connection(self, conn):
async with self.lock:
self.available_connections.append(conn)
八、故障排查与调试指南
8.1 常见问题与解决方案
问题1:模型调用超时
# 解决方案:设置合理的超时时间和重试机制
import asyncio
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
async def call_model_with_retry(prompt):
try:
async with asyncio.timeout(30): # 30秒超时
response = await model.create_completion(prompt)
return response
except asyncio.TimeoutError:
logger.warning("模型调用超时,正在重试...")
raise
问题2:内存泄漏
# 解决方案:定期清理和监控内存使用
import gc
import psutil
class MemoryMonitor:
def __init__(self, threshold_mb=1000):
self.threshold = threshold_mb * 1024 * 1024
def check_memory_usage(self):
process = psutil.Process()
memory_usage = process.memory_info().rss
if memory_usage > self.threshold:
logger.warning(f"内存使用过高: {memory_usage / 1024 / 1024:.2f}MB")
self.cleanup_memory()
def cleanup_memory(self):
# 清理缓存
global_cache.clear()
# 强制垃圾回收
gc.collect()
问题3:并发处理异常
# 解决方案:使用信号量限制并发数
class ConcurrencyManager:
def __init__(self, max_concurrent=5):
self.semaphore = asyncio.Semaphore(max_concurrent)
async def process_with_limit(self, task):
async with self.semaphore:
try:
return await task()
except Exception as e:
logger.error(f"任务执行失败: {e}")
raise
8.2 调试工具和技巧
分布式追踪
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
# 配置追踪
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
otlp_exporter = OTLPSpanExporter(
endpoint="http://jaeger:14250",
insecure=True,
)
span_processor = BatchSpanProcessor(otlp_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
# 使用追踪
@tracer.start_as_current_span("model_call")
async def call_model(prompt):
with tracer.start_as_current_span("preprocess"):
processed_prompt = preprocess(prompt)
with tracer.start_as_current_span("api_call"):
response = await api_call(processed_prompt)
with tracer.start_as_current_span("postprocess"):
return postprocess(response)
九、社区生态与扩展
9.1 开源贡献指南
AI App Lab是一个开源项目,欢迎社区贡献。主要贡献方式包括:
-
新增应用示例
- 在
demohouse/目录下添加新的应用 - 提供完整的README和部署文档
- 包含前后端完整代码
- 在
-
SDK功能增强
- 在
arkitect/目录下扩展核心功能 - 添加新的组件或工具
- 完善文档和测试用例
- 在
-
文档完善
- 更新使用文档
- 添加最佳实践案例
- 翻译多语言版本
9.2 生态集成
MCP(Model Context Protocol)服务器
项目包含多个MCP服务器实现,用于扩展模型能力:
# MCP服务器示例
class KnowledgeBaseMCPServer:
def __init__(self):
self.tools = [
self.search_knowledge,
self.add_knowledge,
self.update_knowledge
]
async def search_knowledge(self, query: str):
"""在知识库中搜索相关信息"""
results = await self.knowledge_base.search(query)
return {"results": results}
async def add_knowledge(self, content: str, metadata: dict):
"""向知识库添加新知识"""
doc_id = await self.knowledge_base.add(content, metadata)
return {"doc_id": doc_id}
第三方集成示例
# 企业系统集成
class EnterpriseIntegration:
def __init__(self):
self.erp_client = ERPClient()
self.crm_client = CRMClient()
self.email_client = EmailClient()
async def process_business_request(self, request):
# 根据请求类型调用不同的企业系统
if request.type == 'inventory':
return await self.erp_client.query_inventory(request.params)
elif request.type == 'customer':
return await self.crm_client.query_customer(request.params)
elif request.type == 'notification':
return await self.email_client.send_email(request.params)
十、未来发展路线
10.1 技术发展方向
-
多模态融合增强
- 支持更多模态的输入和输出
- 提升多模态理解的准确性
- 优化多模态处理的性能
-
智能体编排能力
- 支持复杂的智能体工作流
- 提供可视化编排界面
- 增强智能体间协作能力
-
边缘计算支持
- 支持模型本地部署
- 优化边缘设备性能
- 提供离线运行能力
10.2 应用场景扩展
-
行业垂直解决方案
- 医疗健康AI助手
- 法律咨询智能系统
- 工业4.0智能制造
-
企业级功能增强
- 企业知识图谱集成
- 业务流程自动化
- 智能决策支持系统
结语
火山方舟AI应用实验室(AI App Lab)为开发者提供了从底层SDK到完整应用的全栈AI开发解决方案。通过Arkitect高代码SDK和丰富的Demohouse原型应用,开发者可以快速构建满足业务需求的AI应用。
项目的开源特性和完整的技术生态,使得开发者不仅可以"开箱即用",还可以根据自己的业务场景进行深度定制和扩展。无论是初学者想要快速上手AI应用开发,还是企业级用户需要构建复杂的AI系统,AI App Lab都能提供强有力的支持。
随着AI技术的不断发展和社区的持续贡献,AI App Lab将继续演进,为更多的开发者和企业提供优质的AI应用开发体验,真正实现大模型技术的普惠应用。
相关链接:
- 项目地址:https://github.com/volcengine/ai-app-lab
- 官方文档:https://www.volcengine.com/docs/82379/
- 火山方舟控制台:https://console.volcengine.com/ark/
- 应用体验广场:https://console.volcengine.com/ark/region:ark+cn-beijing/application

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)