神经网络:解密人脑与AI的奥秘
人工神经网络(ANN)是模拟生物神经系统的计算模型,由相互连接的神经元组成,具有分布式存储、容错性和自适应学习能力。文章详细介绍了神经网络的基本概念、发展历程、结构特点及分类,重点阐述了BP神经网络和Hopfield神经网络的工作原理及应用。BP神经网络通过误差反向传播调整权重,广泛用于函数逼近和模式识别;Hopfield神经网络则用于解决组合优化问题如TSP。文章还探讨了神经网络的学习规则、激活
1. 神经网络的概念
1.1. 什么是神经网络?
人工神经网络(Artificial neural network,简称ANN)简称为神经网络,是相对于生物学中的生物神经网络而言的,是由许多被称为神经元(Neuron,也称感知器)的基本计算单元通过广泛联结所组成的自适应非线性动态系统,能够模拟生物神经系统对真实世界物体所作出的交互反应。
网络的信息处理由神经元之间的相互作用来实现,网络的学习与识别决定于各神经元的动态演化过程。它是在现代生物神经科学研究成果的基础上提出来的,反映了人脑功能的基本特征。

生物神经网络(Biological Neural Networks)一般指生物的大脑神经元、细胞、触点等组成的网络,用于产生生物的意识,帮助生物进行思考和行动 。
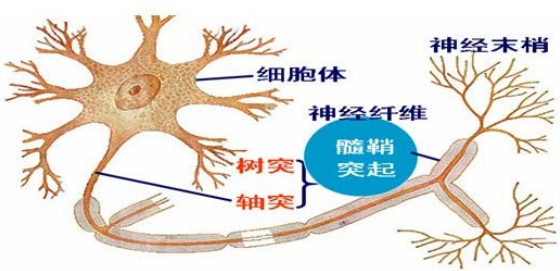
生物神经系统是由大量的神经细胞(神经元)组成的一个复杂的系统。据统计,人脑约有百亿~千亿个神经元。 每个神经元与103~105个其他神经元相连,从而构成一个极为复杂庞大的网络。神经元一般由胞体、树突、轴突三部分组成,如图所示。
胞体:也称为细胞体,包括细胞质、细胞核和细胞膜三部分,是细胞的营养中心。
树突:胞体的伸延部分产生的分枝称为树突,是接受从其它神经元传入的信息入口。但不一定是神经传入的唯一通道,还可以是胞体膜。
轴突:每个神经元只有一个轴突,一般自胞体发出,与一个或多个目标神经元连接,为神经元的输出通道,其作用是将细胞体发出的神经冲动传递给另一个或多个神经元。
1.2. 人脑的活动
- 如能把大脑的活动转换成电能, 相当于一只20瓦灯泡的功率;
- 根据神经学家的部分测量,人脑的神经细胞回路比今天全世界的电话网络还要复杂1400多倍;
- 每一秒钟人的大脑中进行着10万种不同的化学反应;
- 人体5种感觉器官不断接受的信息中,仅有1%的信息经过大脑处理,其余99%均被筛去;
- 大脑神经细胞间最快的神经冲动传导速度为400多公里/小时;
- 人体内有45英里的神经;
- 人的大脑细胞数超过全世界人口总数2倍多,每天可处理8600万条信息,其记忆贮存的信息超过任何一台电子计算机。
- 神经元间信息的产生、传递和处理是一种电化学活动。每个神经元随着所接受的多个激励信号的综合结果呈现出兴奋与抑制状态。
- 神经元之间的突触连接方式和连接强度不同并且具有可塑性,因此人脑呈现出千变万化的复杂的信息处理能力。
1.3. 人脑的结构与功能
- 人脑分为左右脑,交叉进行支配。左脑主要是语言中枢,同时从事分析性工作,如逻辑推理、数学运算和写作等。右脑主要处理空间概念和模式识别。
- 人工智能可看成是对人脑左脑功能的研究,主要基于逻辑思维,如计算机就是模拟人脑逻辑思维的人工智能系统。
- 人工神经网络是探索人的形象思维,即针对右脑的认知规律的研究产物。
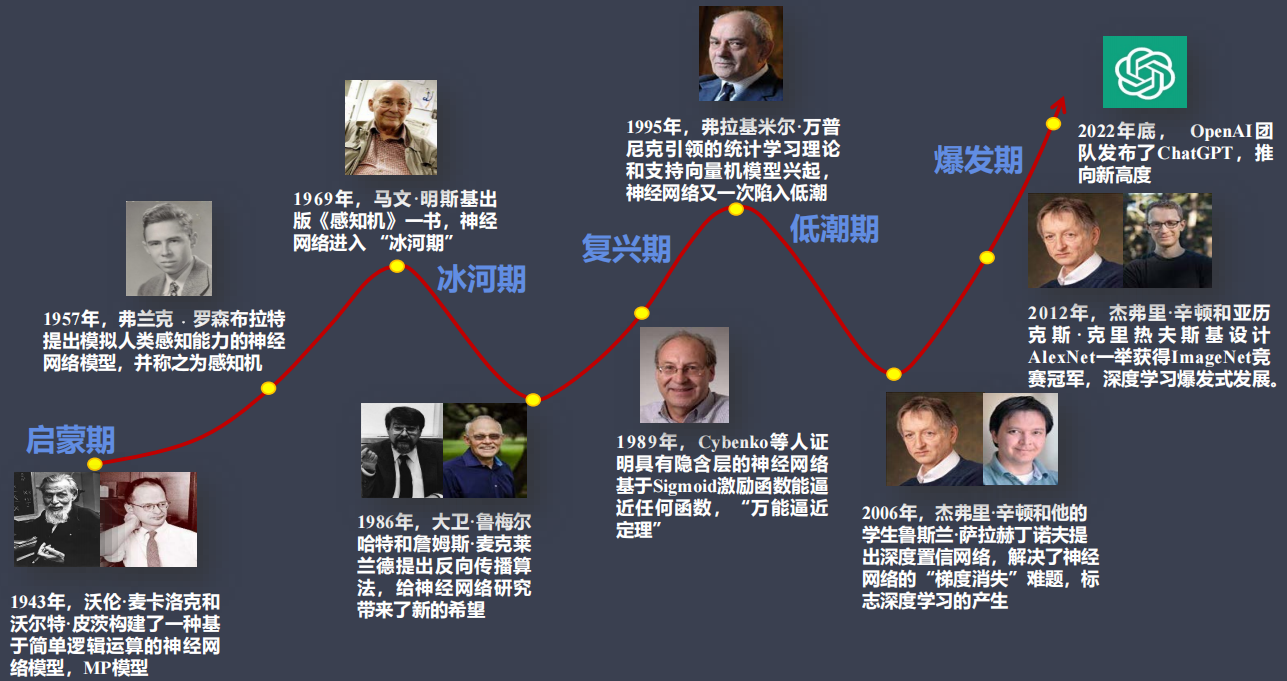
2. 神经网络的发展
人工神经网络分为五个阶段:
3. 神经网络的特点
由于人工神经网络是模拟人的大脑所设计,它具有以下特征:
分布式联想存储
人工神经网络的存储是联想式的,神经元之间的联结值就是存储单元,权值代表了网络所存知识的当前状态。如果给网络输入一个不完备的信息,则它会自动在网络的权值中进行搜索,直至找到与输入信息最匹配的联结单元为止。
联想式存储的最大优点是能存储许多模式的信息,而且能够很快地将这些信息归类到已有的存储模式中去。
较好的容错性
在传统计算机单元中,如果一部分存储单元遭到破坏,则整个系统都将瘫痪。由于神经网络的信息不是存储在一个固定的地方,所以当某些神经元损坏时,只是使神经网络的功效降低一点,并不会使整个系统崩溃。
自适应能力强
自适应能力是指神经网络具有自我调整的能力。当网络中有联结权值发生变化时,网络便可通过学习(算法)自动恢复。另一方面,神经网络有向外界环境学习的能力,并且通过学习改进自身的功能。其学习的目的是从一组数据中提取出相关特征或内在规律。
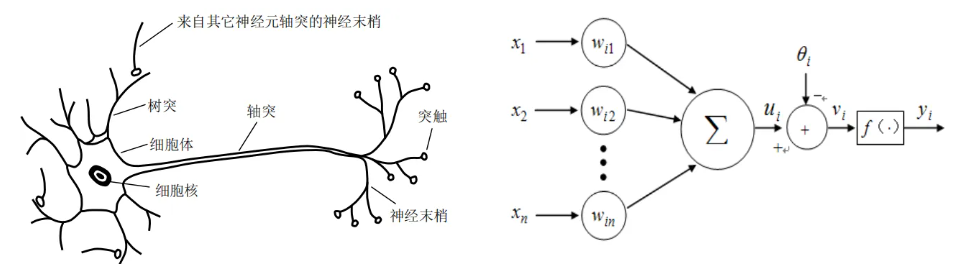
4. 神经元的基本结构
4.1. 神经元(感知机)的基本结构
人工神经网络是由若干个神经元按一定规律组合而成,每个神经元在输入信号作用下,能够从当前状态转变为另一种状态,产生相应的输出信号。神经元决定整个神经网络的特性和功能,其基本结构如图所示。
4.2. 从生物神经元到人工神经元(感知机)
神经元及其突触是神经网络的基本器件,模拟生物神经网络:
- 首先,模拟生物神经元:
-
- 节点的信息处理能力(神经元模型)
- 其次,研究神经元之间的交互:
-
- 节点与节点之间连接(网络拓扑结构)
- 节点相互连接的强度(通过学习调整)
生物神经元与人工神经元的类比关系:

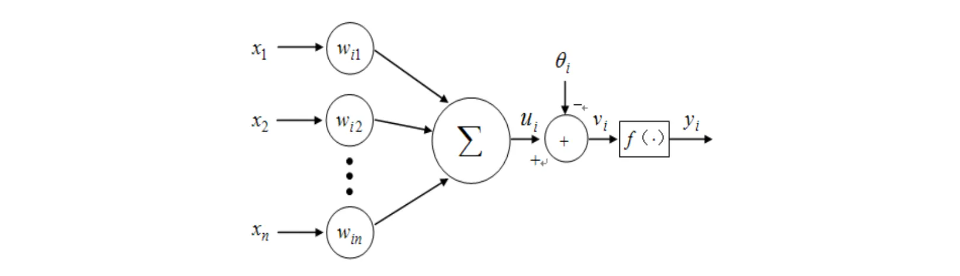
为神经元的输入信号,它既可以是外部输入,也可以是其它神经元的输出;
为其连接权重;
为神经元的加权求和计算;
为神经元输入信号的线性组合;
为神经元的阈值;
为神经元的净输入;
为神经元的传递函数,也称为激活函数;
为神经元的输出;
神经元的输出特性(及状态方程)可以表示为:
4.3. 神经元(感知机)的原始用途
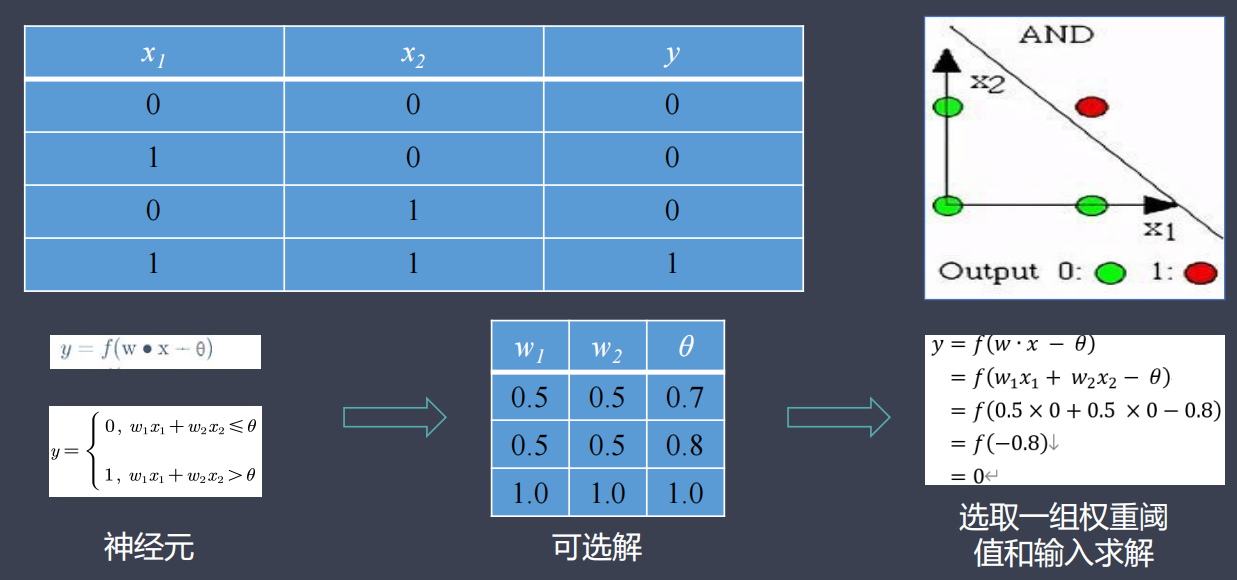
模拟简单逻辑电路:与门(AND)
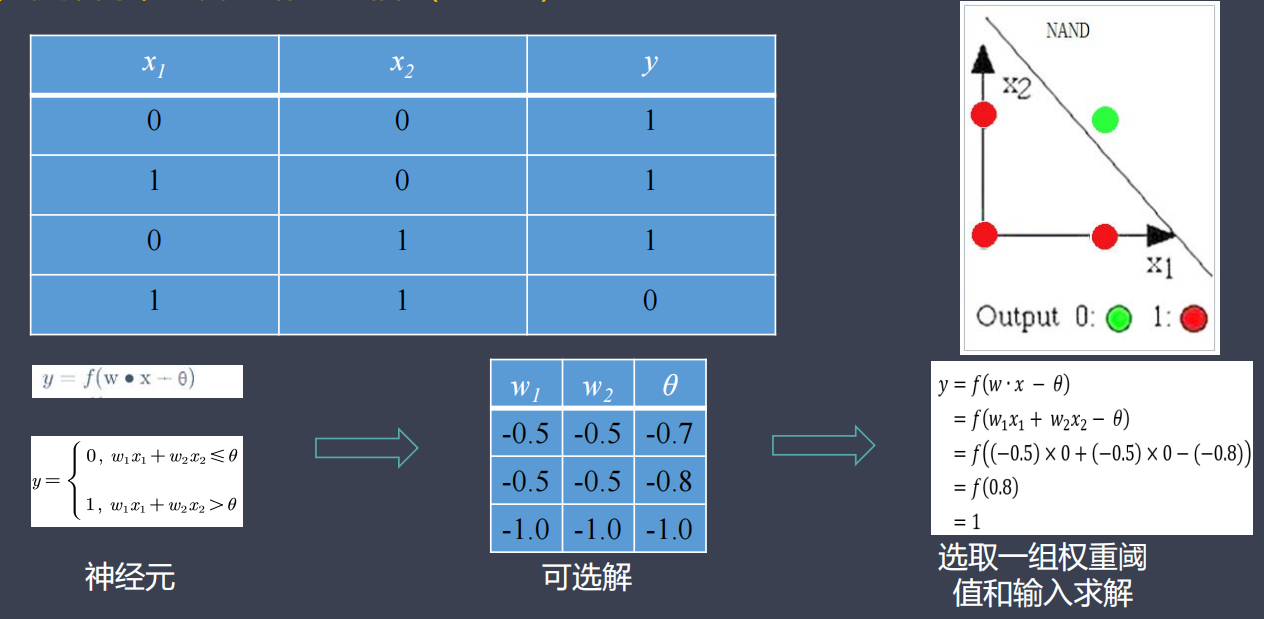
模拟简单逻辑电路:与非门(NAND)
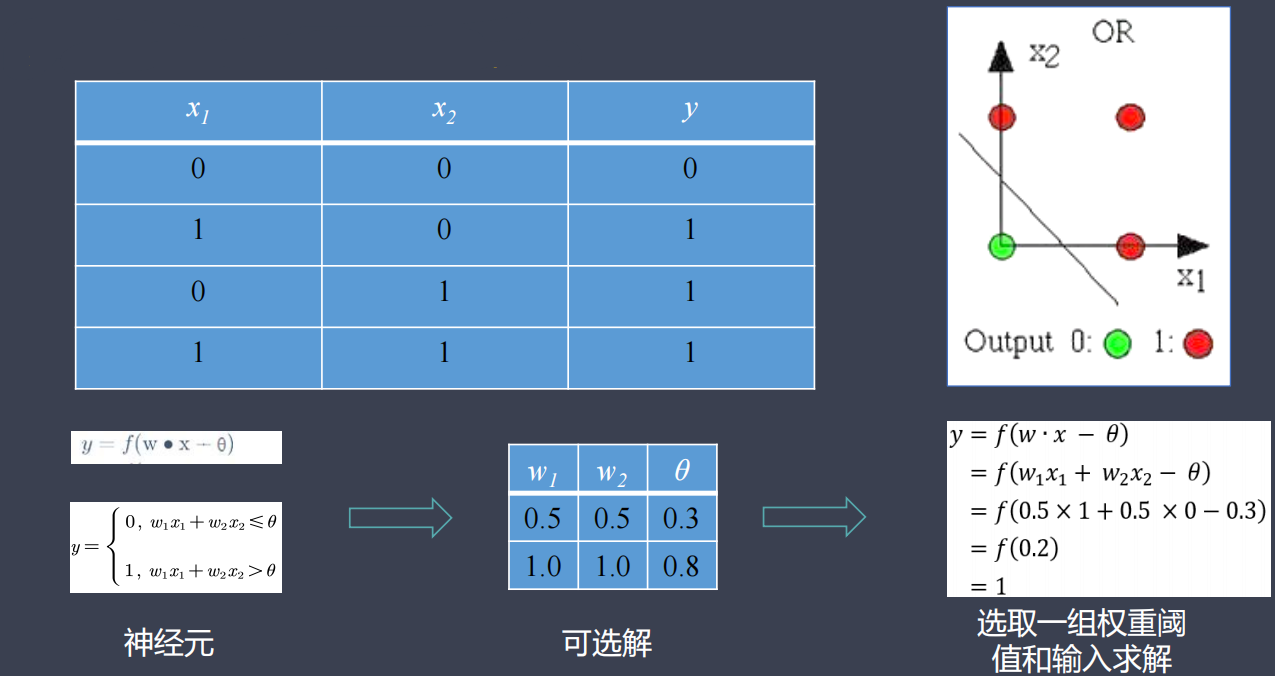
模拟简单逻辑电路:或门(OR)
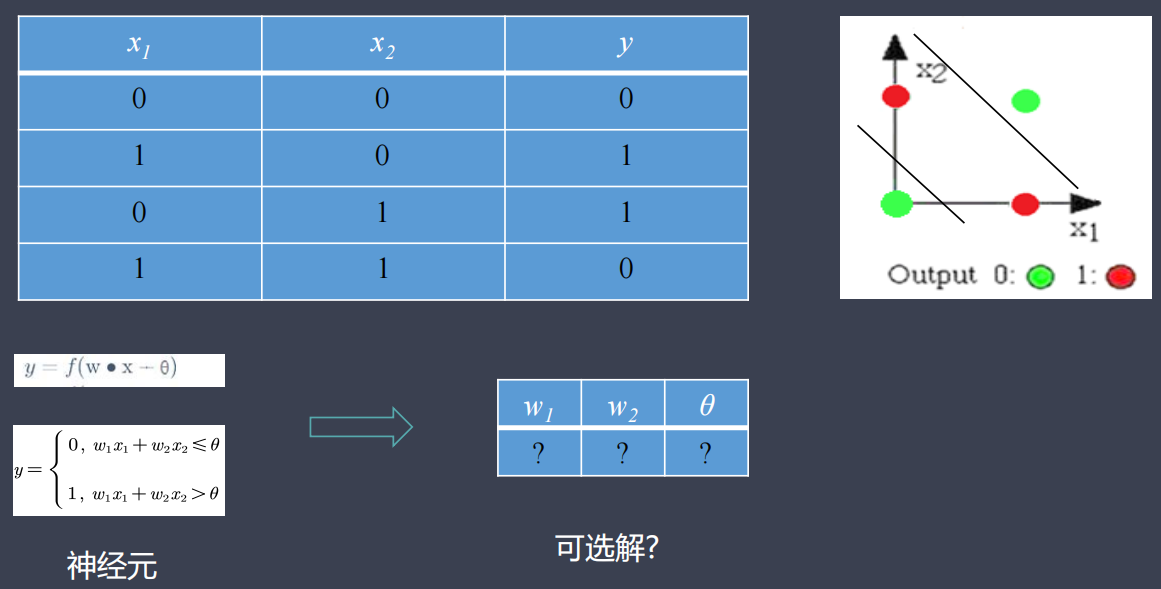
模拟简单逻辑电路:异或门(XOR)
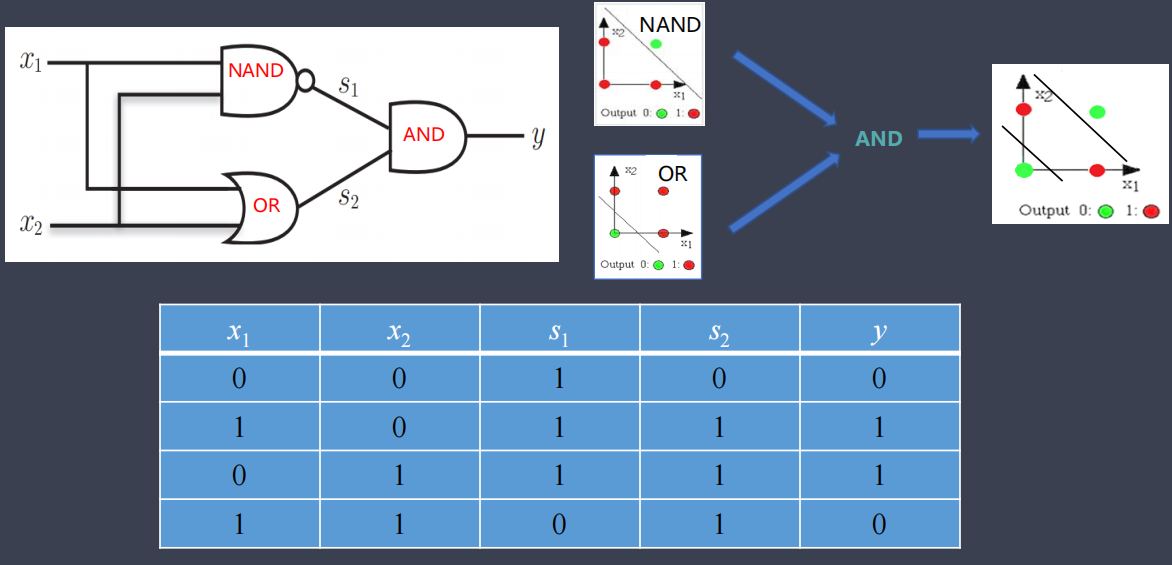
4.4. 多层感知机
- 优点:多层感知机能够进行复杂的表示。
-
- 理论上,2层感知机可以表示任意函数。
- 缺点:权重设定的工作需要由人工来执行。
- 解决方案:利用智能算法自动地从数据中学习到合适的权重参数。
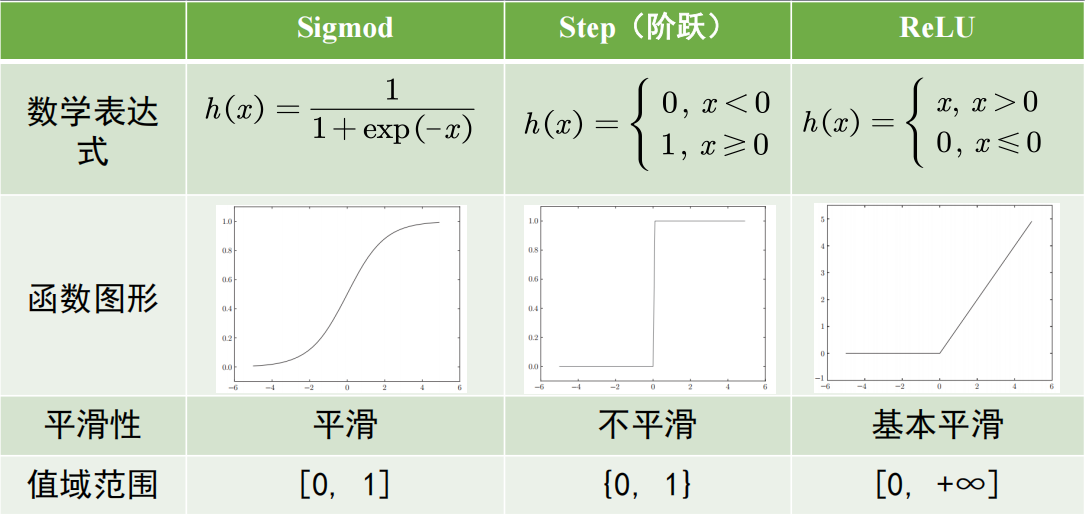
4.5. 激活函数
激活函数决定了神经元的不同输出特性,是连接感知机与神经网络的桥梁。
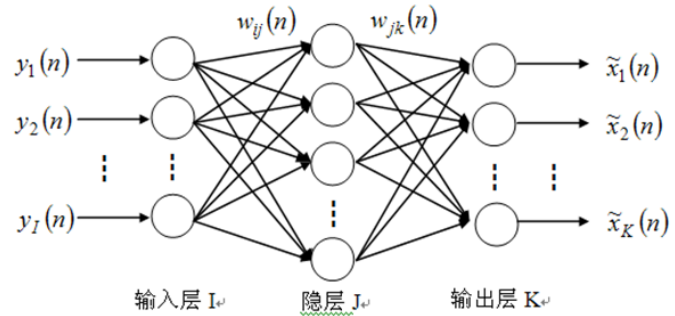
5. 神经网络的基本结构
神经网络一般输入层、隐层(隐含层)和输出层组成。
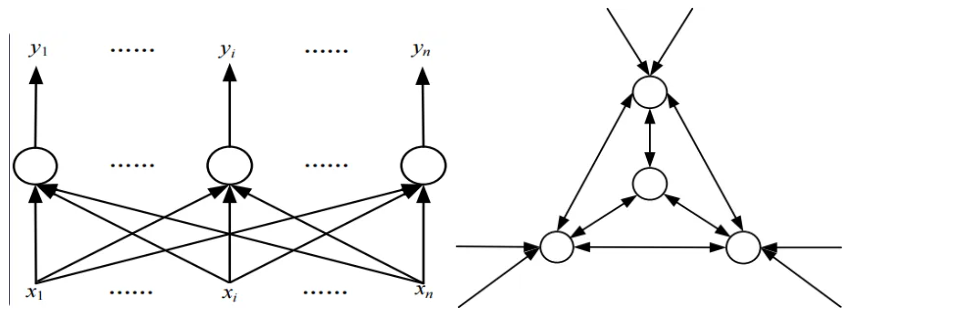
神经元之间的连接方式不同,网络的拓扑结构也不同,人工神经网络的拓扑结构是决定人工神经网络特征的第二要素。
6. 神经网络的分类
6.1. 根据神经网络的结构分类
- 层次型结构:按输入层、隐层、输出层结构组成。
- 互连型结构:任意两个节点之间都可能存在连接路径。根据节点的连接程度又可分为全互连型、局部互连型和稀疏连接型三类。
6.2. 根据神经网络信息流向分类
- 前馈神经网络:各神经元只接收前一层的输出作为自己的输入,并且输出给下一层,整个网络没有反馈。每一个神经元都可以有任意多个输入,但只有一个输出。从作用效果来看,前馈神经网络主要是函数映射,可用于函数的逼近。包括单层感知器,线性神经网络,BP神经网络、RBF神经网络、卷积神经网络等。
- 反馈神经网络:又称自联想记忆网络,神经元之间的信息传递关系不再是从一层到另一层,而是各层神经元之间均存在着联系,每个神经元都是处理单元,同时可接收输入并向外界输出。反馈神经网络是利用能量函数的极小点来求解最优化问题。其设计思想就是在初始输入下,使网络经过反馈计算最后到达能量函数的稳定状态,这时的输出即是用户需要的平衡点。包括Hopfield、Elman局部回归、BSB网络等。
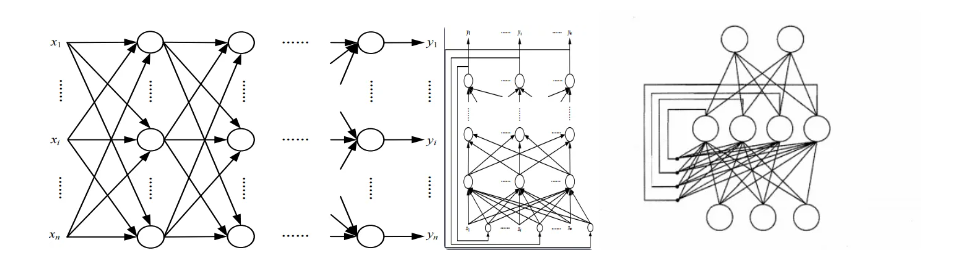
6.3. 根据神经网络的层数分类
- 三层神经网络:仅含有一个隐层的神经网络。
- 多层神经网络:含有两个或两个以上隐层的神经网络。
1989年,Robert Hecht Nielsen等人证明,对于任何在闭区间的一个连续函数都可以用一个隐层的BP神经网络(三层网络)来逼近。增加隐层可增加处理能力,减少误差和提高精度,但训练复杂化。
7. 神经网络的学习方法
7.1. 有监督学习
在有监督的学习方式中,网络的输出和期望的输出(即教师信号)进行比较,然后根据两者之间的差异调整网络的权重,最终使差异变小。BP网络是基于预测值与真实值的差距进行训练的。
7.2. 无监督学习
在无监督的学习方式中,输入模式进入网络后,网络按照一预先设定的规则(如竞争规则)自动调整权重,使网络最终具有模式分类等功能。SOM自组织网络就是基于竞争学习,让神经元有选择性地对自身重新组合来适应各种输入模式。
7.3. 再励学习(Reinforcement Learning)
把学习看作试探评价(奖或惩)过程,学习机选择一个动作(输出)作用于环境之后,使环境的状态改变,并产生一个再励信号(奖或惩)反馈至学习机,学习机依据再励信号与环境当前的状态,再选择下一动作作用于环境。选择的原则,是使受到奖励的可能性最大。
8. 神经网络的学习规则
神经网络学习规则解析-CSDN博客![]() https://blog.csdn.net/qq_17517409/article/details/106027837
https://blog.csdn.net/qq_17517409/article/details/106027837
8.1. Hebb学习规则
Donald Hebb在1949年提出的。
他的基本规则可以简单归纳为:如果处理单元从另一个处理单元接受到一个输入,并且如果两个单元都处于高度活动状态,这时两单元间的连接权重就要被加强。
Hebb学习规则是一种没有指导的学习方法,它只根据神经元连接间的激活水平改变权重,因此此这种方法又称为相关学习或并联学习。
8.2. Delta(δ)学习规则
Delta规则是最常用的学习规则,其要点是改变单元间的连接权重来减小系统实际输出与应有的输出间的误差。
这个规则也叫Widrow-Hoff学习规则,首先在Adaline模型中应用,也可称为最小均方差规则。
BP网络的学习算法称为BP算法,是在Delta规则基础上发展起来的,可在多层网络上有效地学习。
8.3. 梯度下降学习规则
梯度下降学习规则的要点为在学习过程中,保持误差曲线的梯度下降。
误差曲线可能会出现局部的最小值,在网络学习时,应尽可能摆脱误差的局部最小值,而达到真正的误差最小值。
8.4. Kohonen学习规则
该规则是由Teuvo Kohonen在研究生物系统学习的基础上提出的,在处理单元竞争学习时,具有高输出的单位为胜利者,只有胜利者才有输出。只用于没有指导下训练的网络。
8.5. 后向传播学习规则
一般采用Delta规则,包括两步:
第一步是正反馈,当输入数据输入网络,网络从前往后计算每个单元的输出,将每个单元的输出与期望输出作比较,并计算误差;
第二步是向后传播,从后往前重新计算误差,并修改权重。
8.6. 概率式学习规则
从统计力学、分子热力学和概率论中关于系统稳态能量的标准出发,进行神经网络学习的方式称概率式学习。处于某一状态的概率主要取决于在此状态下的能量,能量越低的状态,出现的概率越大。
8.7. 竞争式学习规则
竞争式学习属于无监督学习方式。这种学习方式是利用不同层间的神经元发生兴奋性联接以及同一层内距离很近的神经元间发生同样的兴奋性联接,而距离较远的神经元产生抑制性联接。
竞争式学习规则的本质在于神经网络中高层次的神经元对低层次神经元的输入模式进行竞争识别。
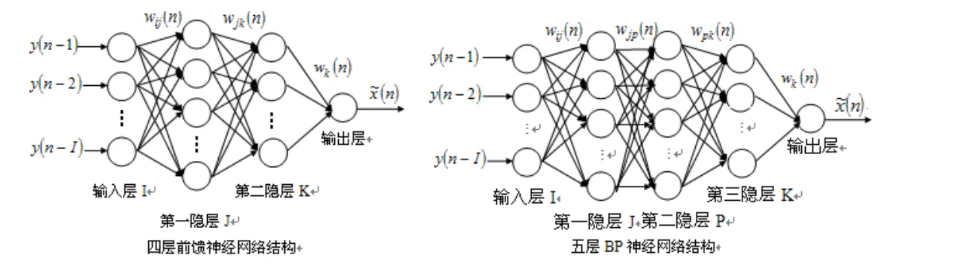
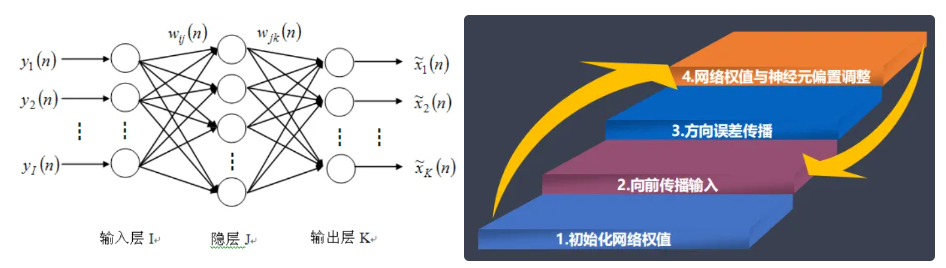
9. BP神经网络
9.1. BP算法的基本原理
BP算法是一种监督式学习算法,属于学习算法的推广。其目的是使网络输出层的误差平方和达到最小,由信息的正向传播与误差的反向传播两部分组成。
反向传播算法通过迭代处理的方式,采用广义delta学习规则,不断地调整连接神经元的网络权重,使得最终输出结果和预期结果的误差最小。
特点
- 前、后层之间各神经元实现全连接;
- 每层各神经元之间无联接。
9.2. BP算法权值的训练和学习功能的实现
三层BP神经网络的状态方程,即输入输出关系:

1. 训练样本——理想输入输出对的集合,样本来自客观对象,应具有真实性和完整性,经过训练的BP网络对于非样本集中的输入也能给出满足映射要求的输出(泛化功能)。
2. BP算法的误差函数一般定义为实际输出与期望输出的均方误差和。
- 设K个输出层的期望输出为dk(n),则单路输出的均方误差为
;
- 整个输出层的均方误差为
;
- 为了达到学习目的,要根据误差函数调整网络间的连接权值。BP 算法采用最速下降法调整权值,每次调整量为
;
- 式中 0 < μ < 1 为学习速率,或称为调整步长,迭代步长;
- 怎么理解这个式子呢?试想比如有个式子是
,y是由三个x决定的对吧?如果要计算
对
的影响,就可以对
就被舍弃掉了。把
看作
的偏导,然后乘上我们设定的学习率。
3. 对于输出层,其权值调整量为:
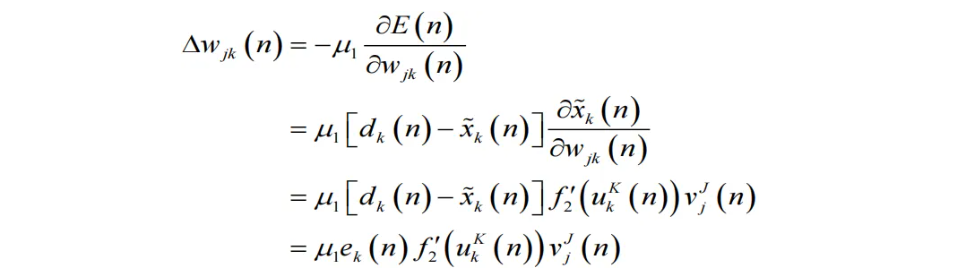
- 故得到输出层权值调整公式为:
4. 对于隐层,其权值调整量为:
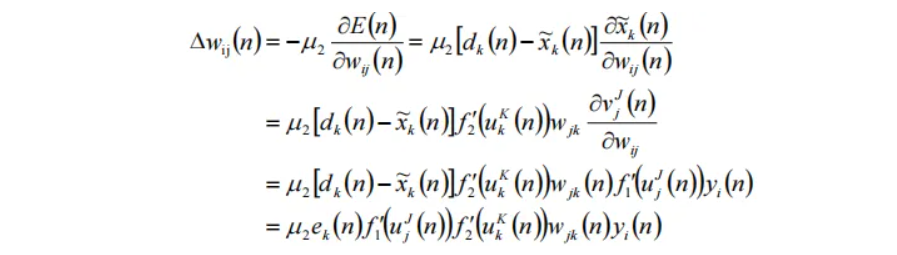
- 故得到隐层权值调整公式为:
- (式中
为隐层学习速率)
9.3. BP神经网络分类系统训练过程
BP神经网络训练过程(伪代码与流程图)
//功能:BP神经网络训练过程的伪代码
procedure BPNN
Initialization, include the ωij and θI
for each sample X
while not stop
//forwards propagation of the input
for each unit j in the hidden and output layer
//calculate the output Oj;
for each unit j in the output layer
//calculate the error Ej;
Ej=Oj(1–Oj)(Tj–Oj);
//back propagation of the error
for each unit j in the hidden layer
//calculate the error Ej;
//adjust the network parameters
for each network weight ωij
ωij=ωij+(l)EjOj;
for each biased θj
θj=θj+(l)Ej;
end of while not stop
end of for each sample X
end of procedure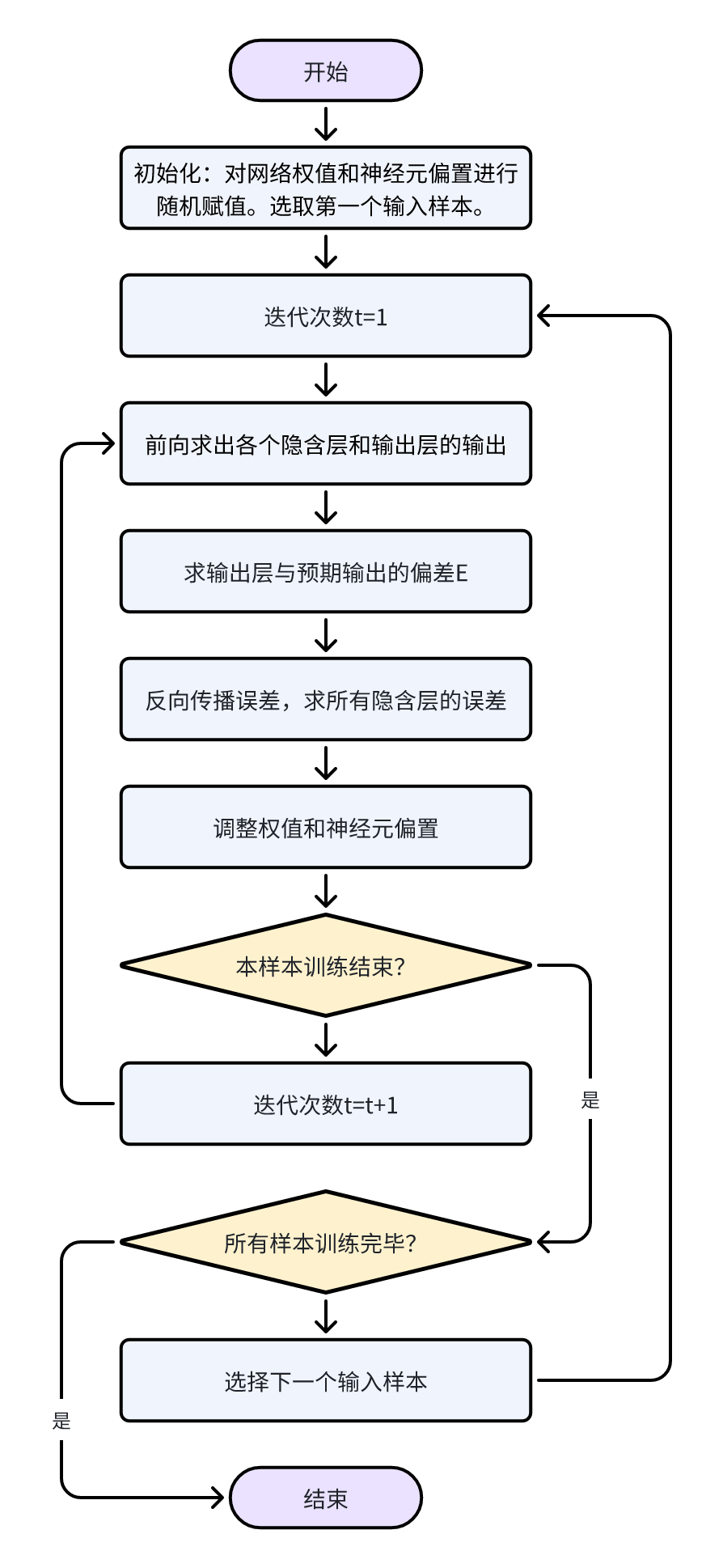
示例题:
已知一个前馈型神经网络例子如下图所示。设学习率l为0.9,当前的训练样本为x={1,0,1},而且预期分类标号为1,同时,下表给出了当前该网络的各个连接权值和神经元偏置。求该网络在当前训练样本下的训练过程 。

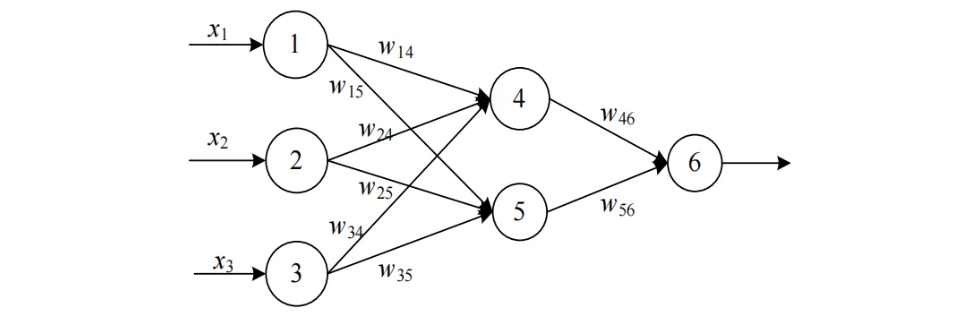
第二步:
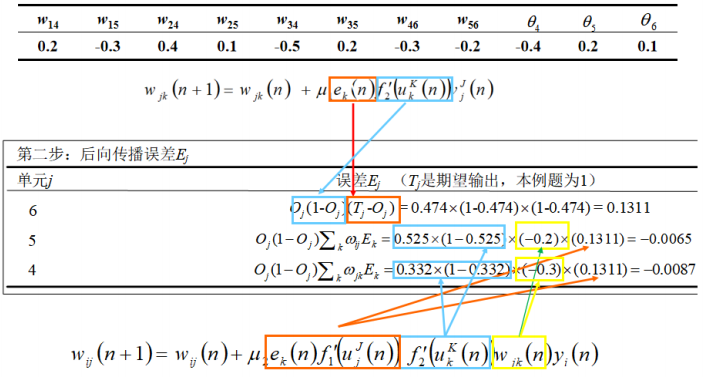
第三步:
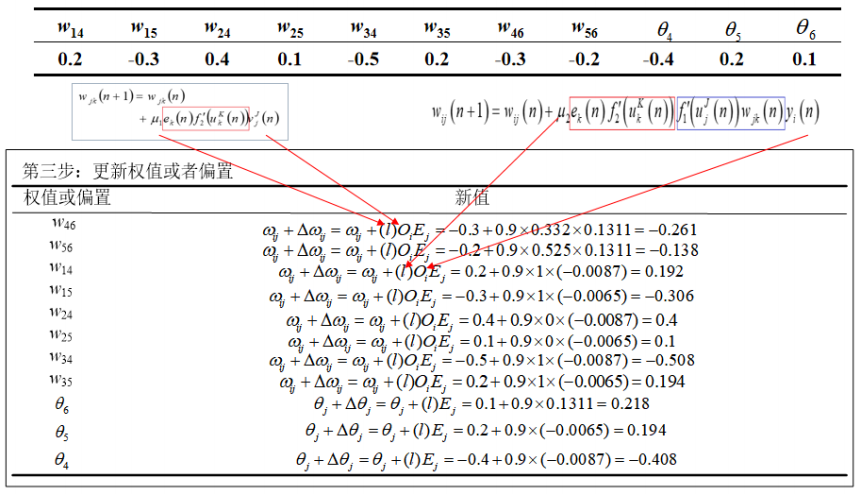
9.4. BP神经网络特点与改进
BP算法的核心是最速下降法,这是一种以梯度为基础的误差下降算法,具有原理简单、实现方便等特点,但也有许多不足之处:
- 收敛速度较慢
-
- 导致BP算法收敛速度慢的原因主要是固定的学习速率。为了保证算法收敛,学习速率必须小于某一上限值,一般要求学习速率不超过输入向量自相关矩阵的最大特征值,这就决定了算法的收敛速度不会太快。
- 学习速率通常是由经验确定的,且在训练过程中保持不变,这样网络权值每次调整的幅度都由误差函数对权值导数大小来决定。
- 在误差曲面较平坦处,由于偏导数较小,使得权值的调整幅度较小,以致于需要经过多次调整才能将误差函数曲面降低。在误差曲面曲率较大处,偏导数较大,权值调整幅度也较大,有可能在误差函数最小点附近发生过冲现象,使权值调节路径变为锯齿形,难以收敛到最小点,导致算法收敛速度慢。
- 易陷入局部极小点
-
- BP算法的训练是从某一起始点沿误差函数的曲面逐渐到达误差的最小点。由于误差曲面是一个复杂的多维曲面,有可能存在多个局部极小点,这就难免使得训练陷入局部极小。
- 从数学角度看,BP算法是一个非线性优化问题,这就不可避免地存在局部极小值问题。
针对BP算法的上述缺陷,近年来学者们提出了多种改进算法。主要有采用启发式信息技术的BP算法,加入数值优化技术的BP算法和基于现代优化理论的BP算法三大类。
1. 采用启发式信息技术的BP算法:
采用启发式信息技术的BP算法实质就是在误差梯度变化缓慢时加大学习速率,而在变化剧烈时减小学习速率。主要有可变学习速率法,加入动量项法等。
2. 加入数值优化技术的BP算法:
BP学习过程实质上是一个数值优化问题,可以利用数值优化技术来进行改进,如牛顿法、共轭梯度法等等。
3. 基于现代优化理论的BP算法:
基于现代优化理论的BP算法是将遗传算法(简称GA)、蚁群算法(简称CA)、模拟退火算法(简称SA算法)等与神经网络相结合,改善BP算法的缺陷,提高算法的全局收敛能力。
9.5. 基于BP神经网络的遥感影像分类
数据集介绍:

from torch import nn
class MLP(nn.Module):
#类的初始化
def _init_(self, in_channel, out_channel):
super(MLP, self)._init_()
self.layer1 = nn.Sequential(nn.Linear(in_channel, 16),nn.BatchNorm1d(16), nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(16, 32),nn.BatchNorm1d(32), nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(32, 64),nn.BatchNorm1d(64), nn.ReLU(True))
self.1ayer4 = nn.Sequential(nn.Linear(64, 128),nn.BatchNorm1d(128), nn.ReLU(True))
self.layer5 = nn.Sequential(nn.Linear(128, out_channel))
#BP网络前向传播
def forward(self, x):
X = self.layer1(x)
x = self.layer2(x)
X = self.layer3(x)
x = self.layer4(x)
X = self.layer5(x)
return x进行训练准备
#导入相应包
import torch
from models.unet import UNet
from data.DataSet import SingleImageDataset, RawImageDataset
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import numpy as np
from models.unet import UNet
from models.MLP import MLP
import osgeo.gdal as gdal
import argparse
#初始化准备
parser = argparse.ArgumentParser()
parser.add_argument('--save_path', type=str)
parser.add_argument('--img_path', type=str)
parser.add_argument('-—mask_path', type=str)
parser.add_argument('--step_num', type=int)
parser.add_argument('--batch_size', type=int)
args = parser.parse_args()
save_path = args.save_path
img_path = args.img_path
mask_path = args.mask_path
imgl_path = r"13ss.img"
mask_path=r"2020106ssFT_trainlabel0.1" # 训练样本
save_path=r"guangzhou_ft.pth" #保存路径
batch_size = args.batch_size
step_num = args.step_num # 迭代次数进行训练
#开始训练
model = MLP(3, 10) #设置模型
criterion = nn.CrossEntropyLoss(ignore_index=0, reduction='mean') # 损失函数
optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9,weight_decay=0.0001) #优化器
model.train()
#设置参数
step = 0
running_loss = 0.0
total_loss = 0.0
train_correct = torch.tensor(0.0)
train_count = torch.tensor(0.0)
# 准备输入数据
img = gdal.Open(img1_path).ReadAsArray() # 输入影像
label= gdal.Open(mask_path).ReadAsArray() # 输入训练样本
img = img[:,label!=0]
label = label[label!=0]
idxs= list(range(label.shape[0]))
#进行迭代训练
while True:
if step > step_num:
break
step += 1
if step > step_num:
break
#获得输入数据,进行初步处理
idx = np.random.choice(idxs,batch_size)
inputs = imgl:,idx]
labels = label[idx]
inputs,labels = torch.tensor(inputs).type(torch.FloatTensor),torch.tensor(labels).type(torch.LongTensor)
inputs = inputs.permute(1,0)
optimizer.zero_grad()
outputs= model(inputs) #前向传播
loss = criterion(outputs,labels)# 构建loss项
loss.backward()#误差反向传播
optimizer. step()#误差优化
#得到训练结果
torch.save(model.state_dict(), save_path)
print('Model save at ', save_path)进行预测准备
#导入相应包
import torch.nn as nn
import torch
from osgeo import gdal
import numpy as np
import matplotlib.pyplot as plt
from models.unet import UNet
from models.simple_CNN import CNNnet
from models.MLP import MLP
import os
import torch.nn.functional as F
from collections import OrderedDict
import argparse
# 初始化准备
parser = argparse.ArgumentParser()
parser.add_argument("--model_path", default='resunet.pth', type=str)
parser.add_argument('--save_path', type=str)
parser.add_argument('--image_path', type=str)
args = parser.parse_args()
model_path = args.model_path
model = MLP(3, 10)
img1_path=r"15ss.img" #输入图片路径
save_path=r"guangzhou_t2.tif" #保存图片路径
model_path=r"guangzhou_t2.pth" #模型路径进行预测
#获取输入数据
original = gdal.Open(img1_path, gdal.GA_ReadOnly)
img = original.ReadAsArray()
#得到地理变换和投影信息
transform = original.GetGeoTransform()
projection = original.GetProjection()
#进行预测
row = img.shape[1]
col = img.shape[2]
result = torch.zeros([row, col])
softmax= nn.Softmax(dim=1) #设置softmax
with torch.no_grad():
for r in range(O, row):
tem = np.moveaxis(imgl:, rl, 0, 1)
inputs = torch.Tensor(tem)
#通过softmax得到分类结果
cls = model(inputs).softmax(dim=1).argmax(dim=1)
result[rl=cls
#得到最终结果
result = result.cpu().detach().numpy().astype(np.uint8)
result = result.reshape(row, col)影像分类结果

10. Hopfield神经网络
10.1. Hopfield神经网络
Hopfield模型是霍普菲尔德提出的,有离散型(DHNN)和连续型(CHNN)两个全连接神经网络模型。
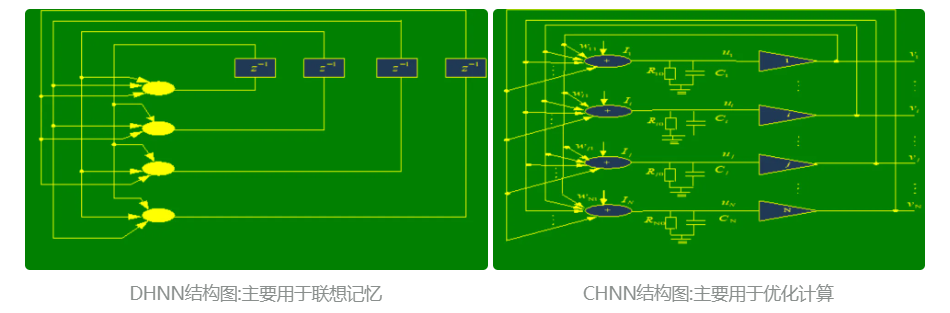
Hopfield神经网络模型是一种循环神经网络,从输出到输入有反馈连接。在输入的激励下,会产生不断的状态变化。对于一个Hopfield网络来说,关键是设计能量函数判断系统的稳定性并确定它在稳定条件下的权系数。
Hopfield 网络特点
- 在一定的条件下,赋予网络某个初值,系统将迅速演化到某个静止状态,即所谓稳态。
- 稳态由各个神经元的连接权值确定,并不唯一。
- 从不同的初值出发会演化到不同的稳态。
- 可以构造一个状态的能量函数,并证明稳态对应的能量函数取极小。
设用X(t)表示网络在时刻t的状态,如果从t=0的任一初态X(0)开始,存在一个有限的时刻t,使得从此时刻开始神经网络的状态不再发生变化,即X(t+△t)=X(t) △t>0,就称此网络是稳定的。
10.2. DHNN
离散网络模型是一个离散时间系统,每个神经元只有两个状态,可以用1和0来表示。它的计算公式如下:
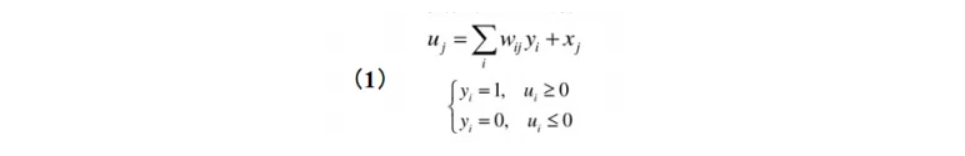
如果用Y(t)表示整个网络在时刻t的状态,则Y是一个向量,它包含了网络中每个人工神经元的状态。所以,状态向量Y中的分量个数就是网络中人工神经元的个数。
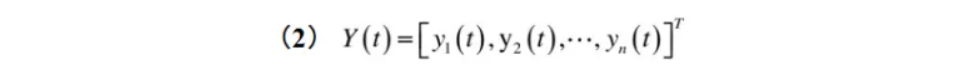
在满足一定的参数条件下,Hopfield网络能量函数的能量在网络运行过程中应不断降低,最后趋于稳定的平衡状态。
引入一个Lyapunov函数,即能量函数:
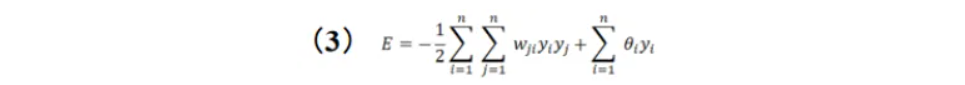
对于神经元 j,其在时刻 t 的能量函数可以表示为:
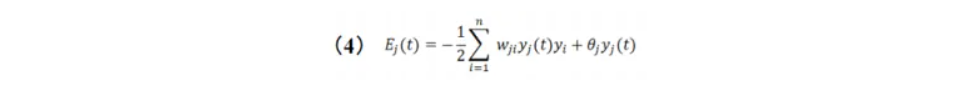
Coben和Grossberg在1983年给出了关于Hopfield网络稳定的充分条件:如果Hopfield网络的权系数矩阵W是一个对称矩阵,并且对角元素为0,则这个网络是稳定的。
10.3. CHNN
CHNN是在DHNN的基础上提出的,它的原理和DHNN相似。不同的是,CHNN作用函数为S型函数,以模拟量作为网络的输入输出量,各神经元采用并行方式工作,所以它在信息处理的并行性、联想性、实时性、分布存储、协同性等方面比DHNN更接近于生物神经网络。
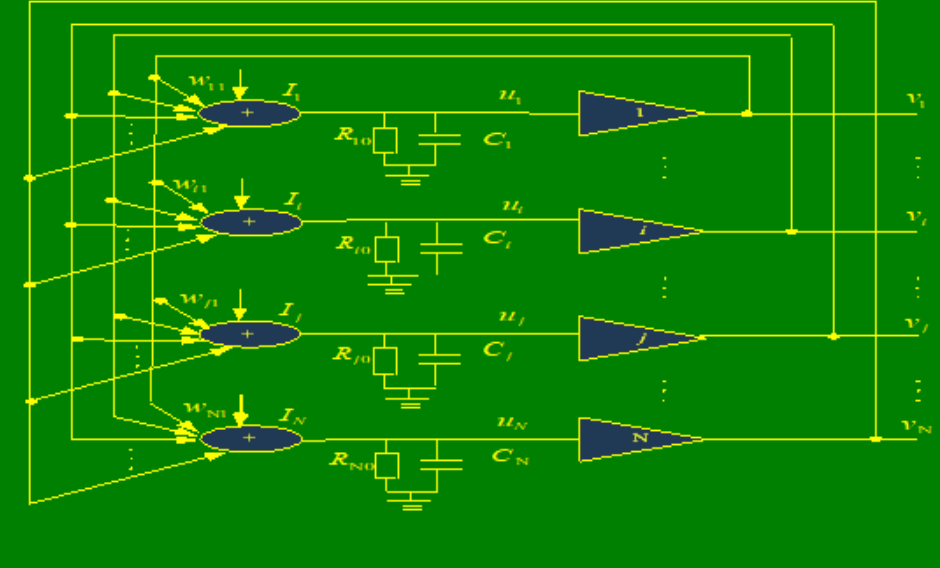
10.4. Hopfield网络求解TSP问题
Hopfield神经网络解决TSP问题的基本步骤:
- 将TSP问题的每一条可能路径用一个置换矩阵表示,并给出相应的距离表示式。
- 将TSP问题的置换矩阵集合与由N个神经元构成的神经元阵列相应,每条路径对应的置换矩阵的各元素与相应的神经元稳态输出相应。
- 找出一个反映TSP的约束优化问题的能量函数E。
- 迭代更新网络,使能量函数E取最小值。
任一城市在最终路径上的次序可用N维矢量表示。以 ABCDE 5个城市为例,如果城市A是第3个访问,则可以用00100,即只有第3个神经元的输出为1,其余都是0。为了表示所有城市,就需要N×N的矩阵。例如某一条路径访问顺序是CAEBD,那么可以用如下方阵表示。
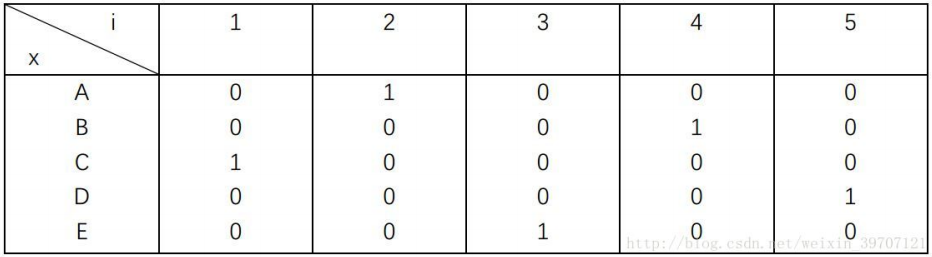
该路径的访问距离为:。
对于N个城市的TSP问题,其目标函数可以表示为如下形式:
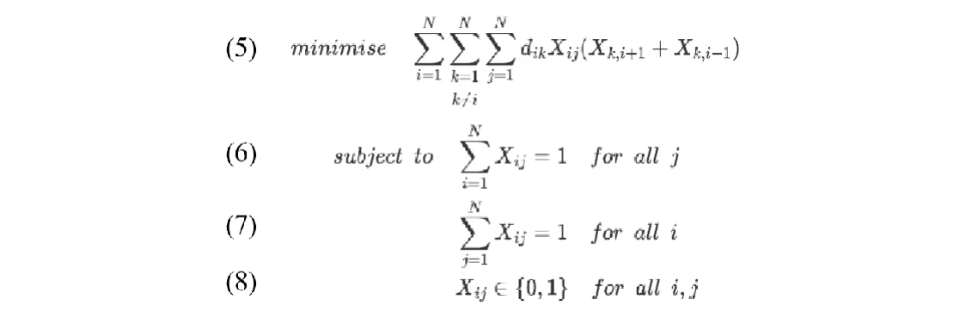
其中, 为二元决策变量,其取值如式(9),即当城市 i 在位置 j 时,
,否则
;
表示城市 i 和 k 之间的距离。

约束(6)要求对于所有的列,每一列中有且只有一个Xij=1;
约束(7)要求对于所有的行,每一行中有且只有一个Xij=1。
式(6)对于列的约束可以通过最小化式(10)实现,即通过最小化每列中成对元素的乘积之和来实现对每列中有且只有一个Xij=1的约束。如果列中不存在或只存在一个Xij=1,则(10)项处于最小值0;如果该列中存在大于一个Xij=1,则此项将大于0。
式(7)对于行的约束可以构造类似的项来实现。
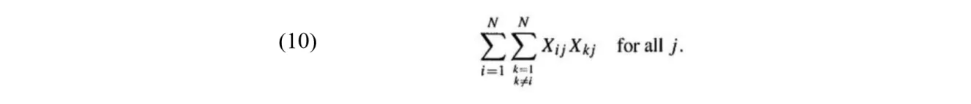
由于每行和每列必须至少存在一个Xij=1,还需要一个附加项来强制矩阵X的N个元素为1。因此,需要将最小化的目标函数和作为惩罚项的约束共同组成能量函数方程,得到TSP问题的能量函数如下:
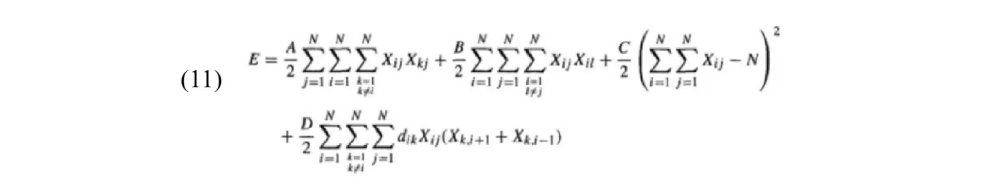
其中,前两项分别是对每列和每行不超过一个Xij=1的约束,第三项确保解矩阵中有N个值为1的元素,最后一项为目标函数(即路径长度);
惩罚参数A,B,C和D反映了这几项在最小化过程中的相对重要性。在前人经验基础上用A=B=D=500,C=200这组参数来平衡这些项。如果A,B和C相对于D不够大,解决方案可能是不可行的。如果D不够大,解决方案可能是可行的,但旅行商行走路径长度可能会大于最佳值。
其在能量函数(11)的基础上,相关学者对能量函数E进行改进(Abe. Theories on the Hopfield neural networks[C],International 1989 Joint Conference on Neural Networks. IEEE, 1989.),改进后的能量函数:
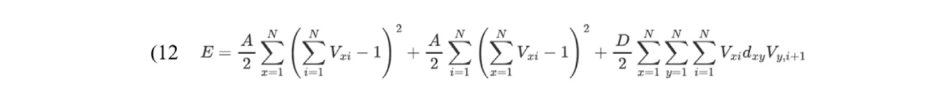
其中,x,y∈{1,2,…,N}为城市编号,i∈{1,2,…,N}为遍历顺,Vxi表示节点输出状态,满足0≦Vxi ≦1。
改进后的能量函数中,前两项保证每行每列逐渐逼近只有一个1,第三项为目标函数。
实际求解中,首先可以按照以下规则初始化网络输入。其中,U0为超参数,δxi为介于[-1,1]之间的随机值。
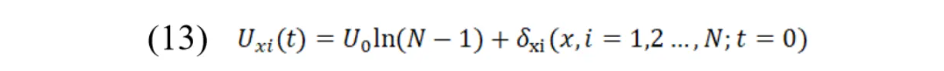
根据改进后的能量函数(12),网络更新公式如下:
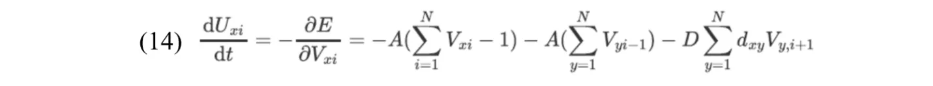
根据一阶欧拉法计算下一代神经网络输入(Abe. Theories on the Hopfield neural networks[C],International 1989 Joint Conference on Neural Networks. IEEE, 1989.) 。
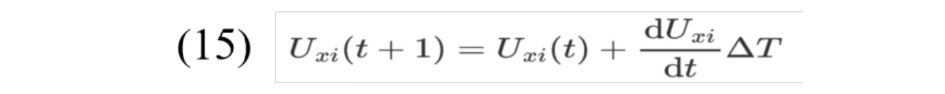
利用sigmoid激活函数计算神经网络的输出:
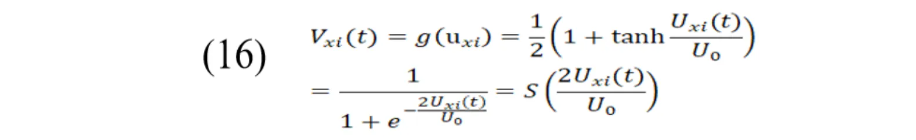
最后将Vxi(t)代入式(12)求得第t代能量函数值,如果符合收敛条件则结束迭代,否则继续求解新一代 并更新U、V值。
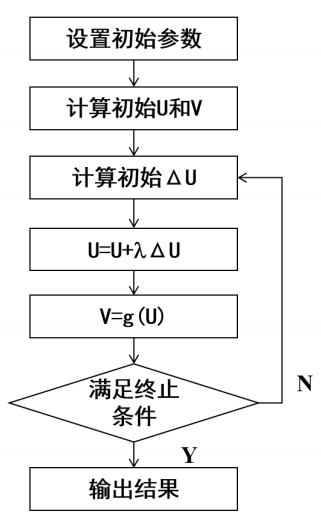
程序流程
- 初始化:城市个数、城市坐标、网络参数A=1.5,D=1;
- 用随机数初始化输入U及输出V状态阵;
- 计算动态方程ΔU,更新输入U及输出V状态阵;
- 判断所得V的合法性,若为合法解并达到最大迭代次数1000,给出访问次序路线图及路线总长度, 程序结束;否则,转到第3步。
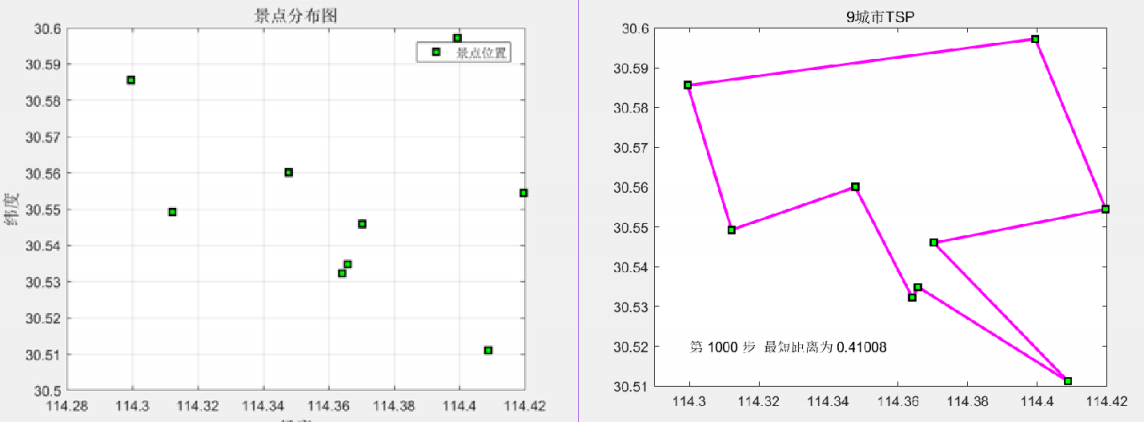
1. 导入9个景点的位置坐标并计算之间的距离;
2. 神经网络输入U和输出V的初始化:
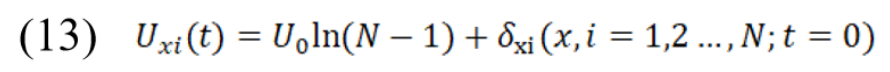

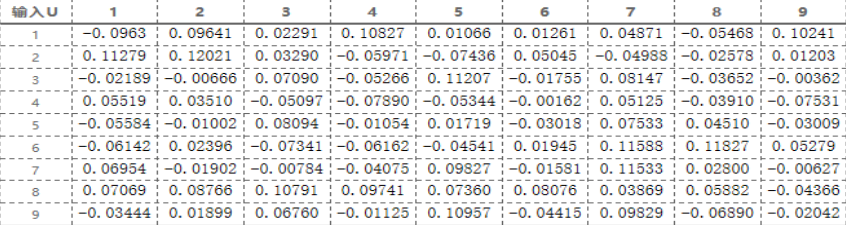
计算神经网络的输出状态:
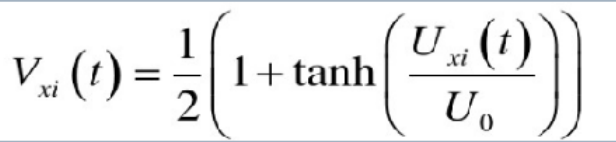

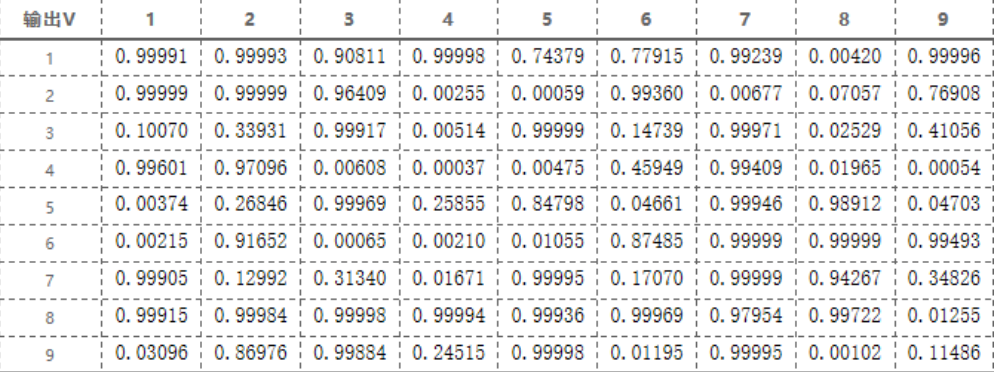
3. 计算输入状态增量,并更新下一时刻状态:
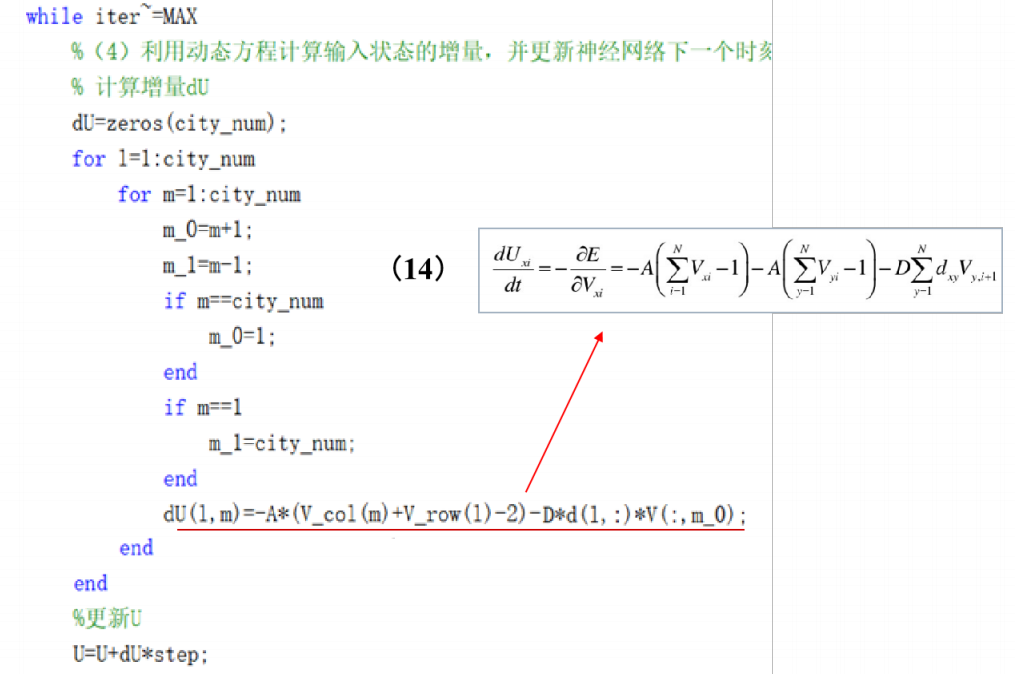
则一次循环后,对于Δu(1,1)有

一次迭代后ΔU 存储情况:
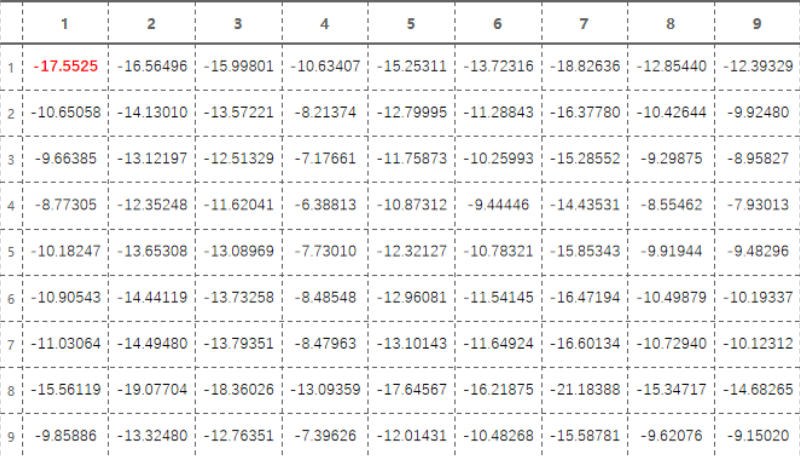
4. 用ΔU更新神经网络的输入和输出状态:
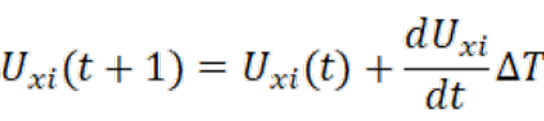
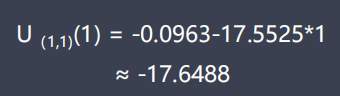
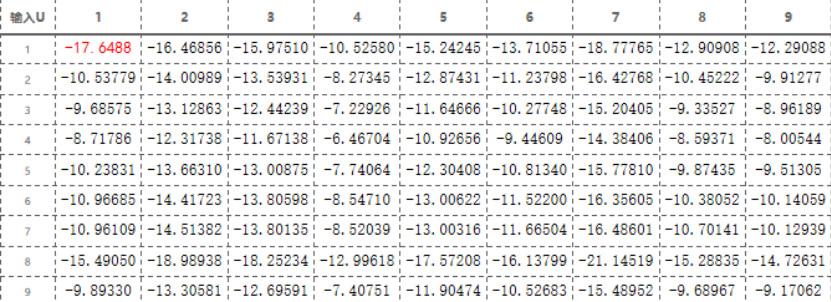
按下式计算新一代输出状态:
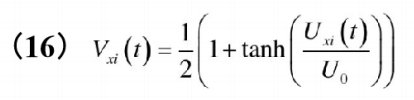

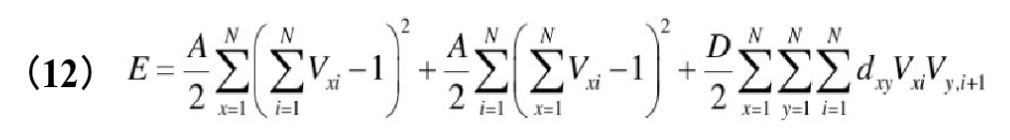

5. 判断输出路径合法性:
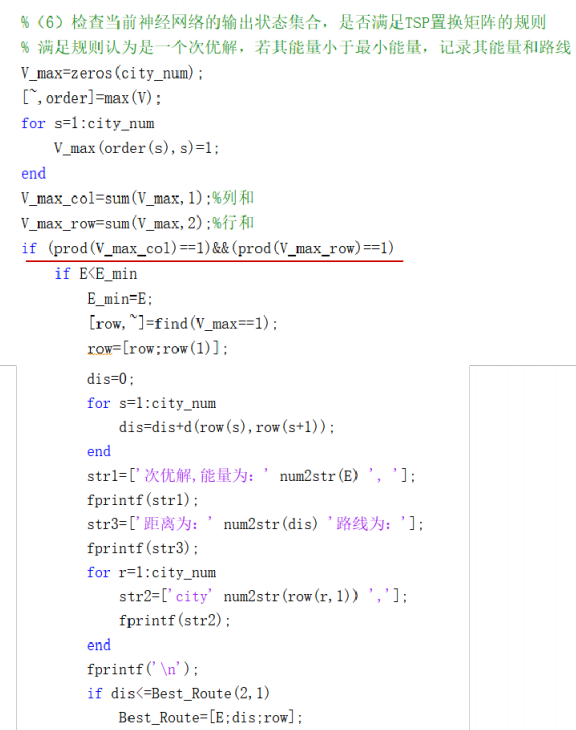
通过检查当前神经网络的输出状态集合是否满足TSP置换矩阵的规则( 没有重复城市,即置换矩阵行和与列和均为1), 如果满足规则认为是一个次优解,如果其能量小于当前最小能量,则记录其能量和路线,到最大迭代次j数跳出循环。
6. 运行结果:
最优解:4→3→1→2→9→8→7→6→5→4
总距离:0.41008*111≈45.52km

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)