Mem0 | Mem0g | 长期记忆 | 可扩展 | AI代理
摘要:Mem0提出了一种可扩展的以内存为中心的算法,通过动态提取和检索关键对话信息,解决大语言模型固定上下文窗口的限制问题。其增强版Mem0g引入图结构记忆,捕捉对话元素间的复杂关系。实验表明,在LOCOMO基准测试中,相比OpenAI,该方法准确度提高26%,延迟降低91%,令牌使用减少90%。Mem0采用两阶段架构(提取+更新),通过轻量化上下文提取关键记忆;Mem0g则通过图结构增强记忆表示
它一种可扩展的以内存为中心的算法,可动态提取和检索关键对话。
LLM存在固定上下文窗口的局限,无法跨会话持久化信息;人类记忆对比,动态整合信息,支持长期连贯交流;提出Mem0及增强版Mem0g
- Mem0 通过动态提取、整合和检索对话中的关键信息,构建可扩展记忆架构
- Mem0g 则引入图结构记忆,捕捉对话元素间的复杂关系
在LOCOMO基准上,比OpenAI的相对准确度提高了26%,p95 延迟降低 91%,令牌减少了 90%
论文地址:Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
代码地址:https://github.com/mem0ai/mem0
一、Mem0 框架思路
如下图所示,展示了Mem0(基础记忆架构)的核心工作流程,分为提取阶段和更新阶段,通过 LLM 与数据库的协作,实现对话记忆的动态提取与持久化更新。
- 通过 “轻量化上下文提取关键记忆 + 相似记忆检索 + LLM 智能更新” 的流程
- 既突破 LLM “固定上下文窗口” 的局限(无需塞入全部历史),又保证记忆的跨会话持久化与一致性,让 AI 能长期连贯地理解对话
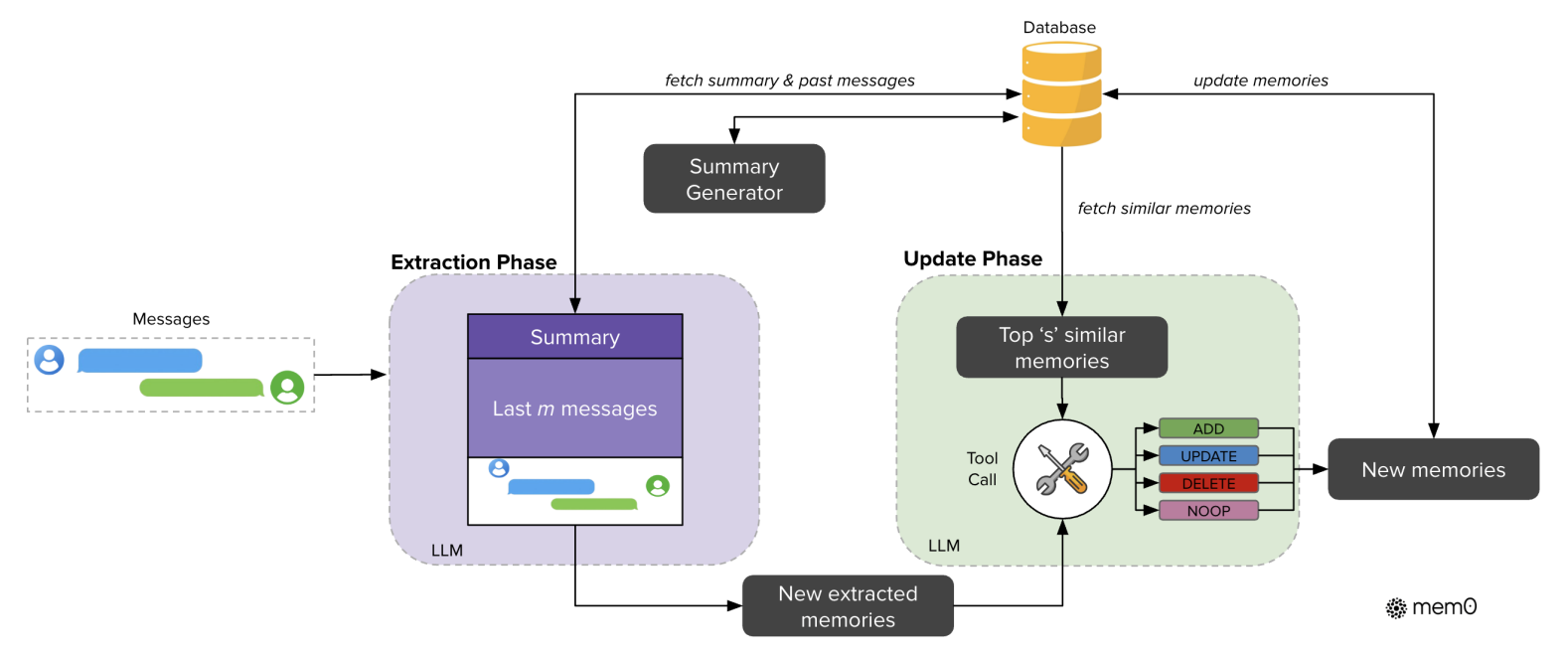
1. 输入与前置准备
对话消息(Messages)作为原始输入,同时从数据库中获取两部分上下文信息:
- 由 “Summary Generator” 生成的对话摘要(Summary)(全局语义层面的历史总结);
- 最近 m 条消息(Last m messages)(细粒度的时序对话内容)。
2. 提取阶段(Extraction Phase)
结合 “对话摘要 + 最近 m 条消息”,通过LLM分析新对话内容,提取关键信息,生成 “新提取的记忆(New extracted memories)”。
→ 核心:不依赖完整对话历史,而是通过 “摘要 + 近期消息” 的轻量化上下文,让 LLM 精准捕捉当前对话的关键记忆。
3. 更新阶段(Update Phase)
为避免记忆冗余 / 矛盾,需与已有记忆交互:
- 检索相似记忆:从数据库中获取最相似的 s 条记忆(Top's' similar memories);
- 智能决策操作:LLM 通过 “工具调用(Tool Call)” 机制,对比 “新提取的记忆” 与 “相似记忆”,执行 4 种操作之一:
ADD:新增无相似的记忆;UPDATE:补充 / 替换可完善的记忆;DELETE:移除矛盾的记忆;NOOP:记忆已存在 / 无关,不操作;
- 持久化新记忆:生成 “新记忆(New memories)” 后,回写到数据库(
update memories),完成记忆的更新循环。
二、Mem0g 框架思路
如下图所示,展示了Mem0g(图基记忆架构)的核心工作流程,也是分为提取阶段和更新阶段
全程由LLM驱动,实现对话信息到图结构记忆的转化与维护:
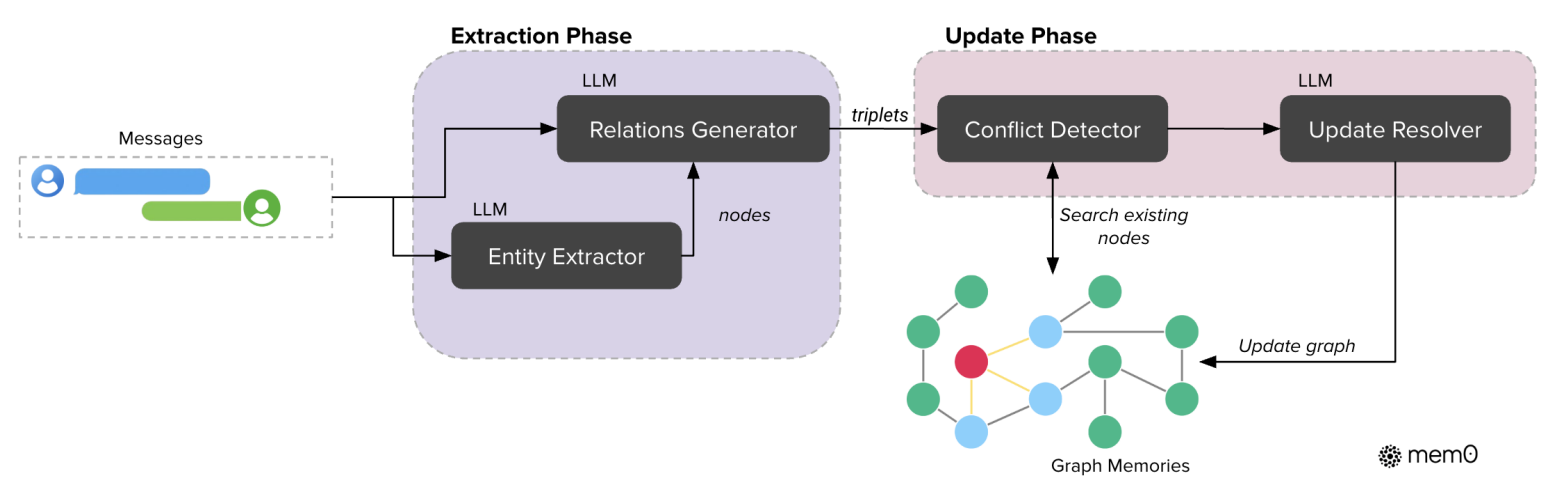
- 输入层:接收对话消息(Messages),作为后续处理的原始数据。
- 提取阶段(Extraction Phase):
- 实体提取:通过 LLM 驱动的 “Entity Extractor” 模块,从对话消息中提取关键实体(nodes)(如人物、地点、事件等)。
- 关系生成:LLM 驱动的 “Relations Generator” 模块,结合对话消息和提取出的实体,生成实体间的关系三元组(triplets,如 <实体 A, 关系类型,实体 B>)。
- 更新阶段(Update Phase):
- 冲突检测:“Conflict Detector” 模块利用生成的关系三元组,检索已有的 “Graph Memories(图记忆)”,检测新信息与现有图结构是否存在冲突(如关系矛盾、实体重复但属性不一致)。
- 图记忆更新:LLM 驱动的 “Update Resolver” 模块,根据冲突检测结果,对图记忆执行更新操作(如添加新节点、调整关系边、解决冲突等),最终维护图结构的一致性与丰富性。
三、Mem0 与 Mem0g 的联系
简单来说,Mem0g 是Mem0的增强版本~
Mem0g 是对 Mem0 的 “结构化升级”,继承核心流程,用 “图结构” 替代 “轻量记忆单元”,以更好地捕捉对话中实体与关系的复杂关联。
1. 架构基础:继承核心流程
Mem0g 基于 Mem0 的 **“提取阶段 + 更新阶段” 两阶段架构 ** 构建,保留了 Mem0 的核心逻辑:
- 都依赖大语言模型(LLM) 驱动记忆的 “提取” 与 “更新”;
- 都通过 “与已有记忆交互”(检索相似记忆 / 图节点),保证记忆的一致性与持久化,解决 LLM 固定上下文窗口的局限。
2. 增强方向:记忆表示的结构化升级
Mem0 采用 “无结构化 / 轻结构化” 的记忆单元 (可理解为关键信息的集合),而 Mem0g 对记忆表示进行了 “图结构增强”:
- 将 Mem0 中提取的 “关键信息” 转化为图的 “实体节点(Nodes)”;
- 将信息间的 “关联” 转化为图的 “关系边(Edges)”,以三元组(如
<实体A, 关系类型, 实体B>)显式建模。
3. 能力拓展:支持更复杂推理
通过 “图结构” 的引入,Mem0g 在 Mem0 的基础上,进一步支持复杂关系与时序推理(如多跳问答、时间依赖型任务),而 Mem0 更擅长简单单跳 / 多跳查询。
二者形成 “基础记忆(Mem0)+ 关系增强记忆(Mem0g)” 的分层能力,适配不同复杂度的对话场景。
四、解决的核心问题
LLMs 虽能生成上下文连贯的响应,但受固定上下文窗口限制,无法在长期、跨会话的多轮交流中维持信息一致性(如用户偏好、历史交互细节易 “遗忘”)。
对比人类记忆 “动态整合信息、支持长期连贯交流” 的机制,LLMs 缺乏对对话信息的长期结构化记忆能力,导致 AI 代理易出现 “重复提问、回复矛盾” 等问题,严重破坏用户体验与信任。
为缓解该问题,现有技术策略存在明显不足:
- 扩展上下文长度(如 GPT-4 128K、Gemini 10M token):仅 “延迟” 了遗忘问题,未解决 “无关信息淹没关键内容”“注意力随 token 距离衰减” 的核心痛点;
- 检索增强生成(RAG):依赖 “静态文本分块” 进行检索,难以捕捉对话中动态变化的语义关联;
- 全上下文输入:将完整对话历史直接塞入 LLM 上下文,导致延迟极高、Token 成本陡增,无法满足生产级 AI 代理的效率需求。
五、重点分析更新阶段
“更新阶段” 是 Mem0 和 Mem0g 架构中保证记忆一致性、实现跨会话持久化的核心环节
5.1、Mem0(轻量动态记忆)的更新阶段
围绕「向量数据库 + LLM 工具调用」,实现 “轻量化记忆的迭代与一致性维护”,流程如下:
1. 相似记忆检索
- 输入:从 “提取阶段” 得到的「新提取的记忆(New extracted memories)」。
- 操作:将新记忆输入向量数据库(基于语义嵌入的相似性检索),获取最相似的(s=10)条历史记忆(Top 's' similar memories)。
- 目的:找到与新记忆相关的历史信息,为 “是否新增 / 更新 / 删除” 提供参考,避免记忆冗余或矛盾。
2. LLM 驱动的智能操作决策(Tool Call)
- 输入:新提取的记忆 + 检索到的相似历史记忆。
- LLM 角色:通过 “工具调用” 机制,分析新记忆与历史记忆的关系,执行 4 类操作(解决冗余、矛盾):
ADD:无语义相似的历史记忆时,新增新记忆到数据库;UPDATE:历史记忆可被新记忆补充 / 完善时,更新已有记忆;DELETE:新记忆与历史记忆矛盾时,删除冲突的历史记忆;NOOP(无操作):新记忆已存在或无关时,不执行操作。
3. 持久化存储
- 操作:经 LLM 决策后,生成「新记忆(New memories)」,并回写到数据库(执行
update memories)。 - 结果:数据库中的记忆实现 “最新、一致、无冗余”,为后续对话提供可靠历史信息。
5.2、Mem0g(图基增强记忆)的更新阶段
因 “图结构(节点 - 边)” 的引入,更关注 “实体 - 关系的一致性维护”,围绕图数据库(如 Neo4j) + LLM 冲突解决展开:
1. 冲突检测
- 输入:从 “提取阶段” 得到的「新实体节点(Nodes)」和「关系三元组(Triplets,即边 Edges)」。
- 操作:“Conflict Detector” 模块检索已有图记忆(Graph Memories),检测新 “节点 - 边” 与现有图结构的冲突。
- 冲突类型:
- 实体冲突:新实体与已有实体重复,但属性(类型、关联关系)不一致;
- 关系冲突:新关系三元组(如
<Alice, lives_in, SF>)与已有关系(如<Alice, lives_in, NY>)矛盾。
2. LLM 驱动的图记忆更新(Update Resolver)
- 输入:冲突检测结果 + 新的 “节点 - 边”。
- LLM 角色:根据冲突类型,决策并执行图的更新操作,例如:
- 新增节点 / 边:添加图中未有的有效 “实体 - 关系”;
- 调整边(关系):修正矛盾的关系类型或连接;
- 合并 / 删除实体:解决重复实体的属性冲突。
3. 图数据库的存储与检索优化
- 存储:采用Neo4j 图数据库,持久化更新后的 “节点 - 边” 结构,利用图数据库特性高效管理 “实体 - 关系”。
- 检索支持:为后续对话提供两种策略:
- 实体中心检索:锚定单个实体,探索关联节点与关系(适合多跳推理);
- 语义三元组检索:匹配关系三元组的嵌入向量,快速定位相关 “实体 - 关系”(适合关系型查询)。
5.3、共性与差异
| 维度 | Mem0 的更新阶段 | Mem0g 的更新阶段 |
|---|---|---|
| 核心目标 | 轻量记忆的一致性、持久化 | 图结构(实体 - 关系)的一致性维护 |
| 记忆形式 | 无固定结构的轻量单元 | 节点 - 边 - 标签的图结构 |
| 数据库类型 | 向量数据库(语义相似性检索) | 图数据库(结构 + 语义检索) |
| LLM 作用 | 决策 “增 / 删 / 改 / 不操作” | 决策图结构的冲突解决与更新 |
| 适用场景 | 简单单跳 / 多跳对话,追求轻量化 | 复杂时序推理、多跳关联任务 |
但是,论文中没有详细介绍Mem0g的冲突检测、LLM 驱动的图记忆更新、 图数据库的存储与检索优化,具体的实现细节。
六、实验分析
聚焦长期对话记忆的 LOCOMO数据集
实验采用LOCOMO 数据集(Maharana et al., 2024),该数据集专门为评估对话系统的 “长期会话记忆能力” 设计,其核心特征与实验适配性如下:
- 数据规模与结构:包含 10 组 “跨多会话的扩展对话”,每组对话平均含约 600 轮交互、26000 个 token,模拟人类间 “持续多日 / 多周的日常交流” 场景(如讨论日常经历、过往事件),完美匹配 Mem0/Mem0g “解决长期跨会话记忆” 的核心目标。
- 问题设计与分类:每组对话配套约 200 个测试问题,且提供对应的 ground truth(标准答案),问题被划分为 4 类核心类型,覆盖不同记忆推理难度:
- 单跳问题:仅需定位单轮对话中的单个事实;
- 多跳问题:需整合多轮 / 多会话中的离散信息;
- temporal(时序)问题:需基于事件的时间顺序推理;
- 开放域问题:需结合对话外常识或泛化信息回答。
如下表所示,LOCOMO数据集中不同题型的记忆化系统性能比较。
评估指标包括 F1 分数 (F1)、BLEU-1 分数 (B1) 和 LLM-as-a-Judge 分数 (J),数值越高表示性能越好。
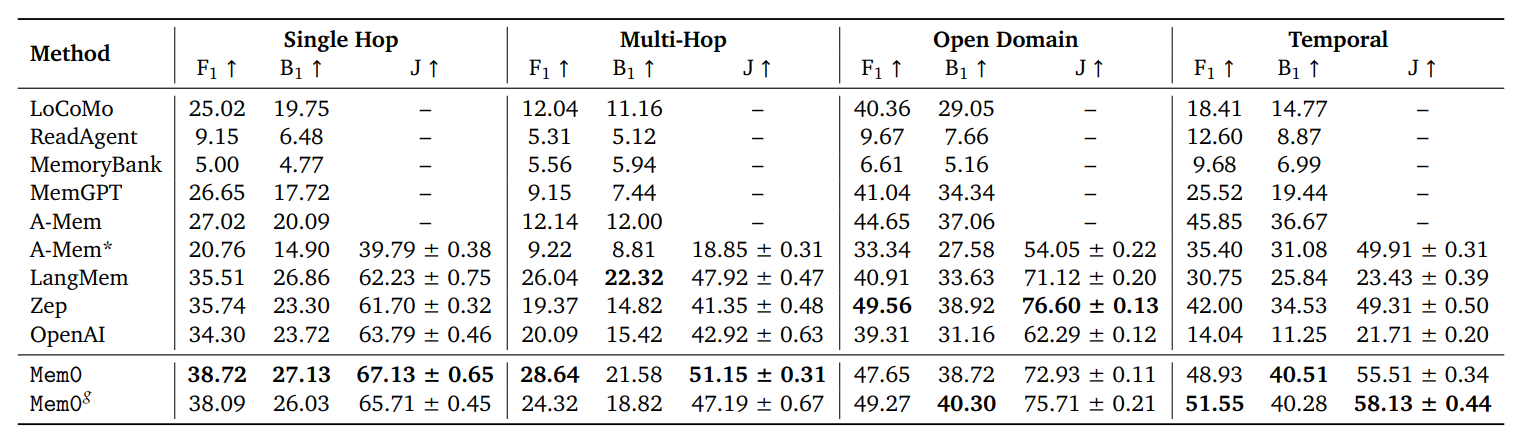
- A-Mem∗表示重新运行 A-Mem 生成 LLM-as-a-Judge 分数的结果,并将温度设置为 0。
- Mem0g 表示提出的架构已通过图记忆增强。
- 粗体表示所有方法中每个指标的最佳性能。
- (↑) 表示分数越高越好。
如下表所示,各种基线方法与所提方法的性能比较。
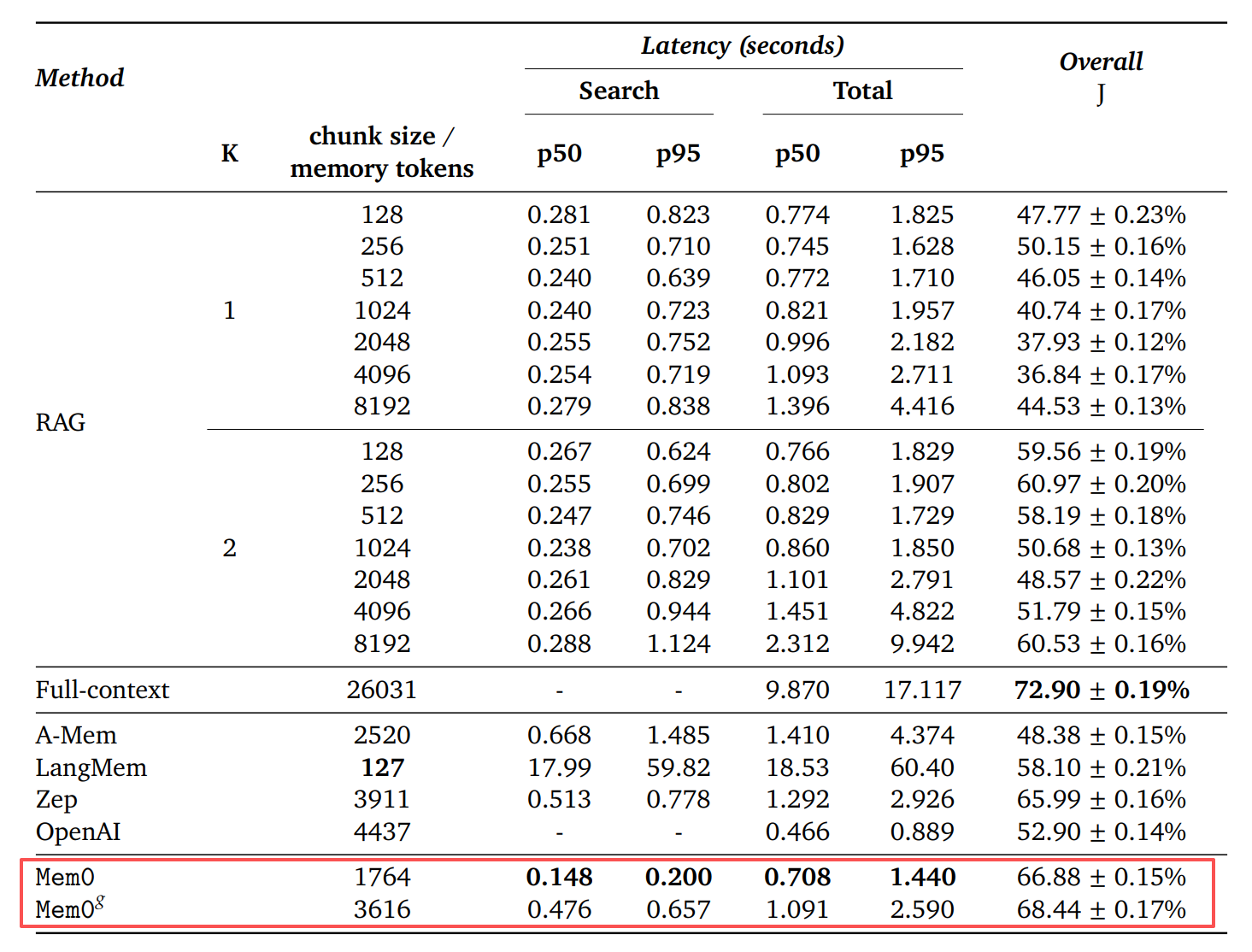
- 延迟测量显示了搜索时间(获取记忆/块所需的时间)和总时间(生成完整响应的时间)的 p50(中位数)和 p95(第 95 个百分位)值(以秒为单位)。
- LLM-as-a-Judge 的总体得分 (J) 表示在整个 LOCOMO 数据集上生成的响应的质量指标。
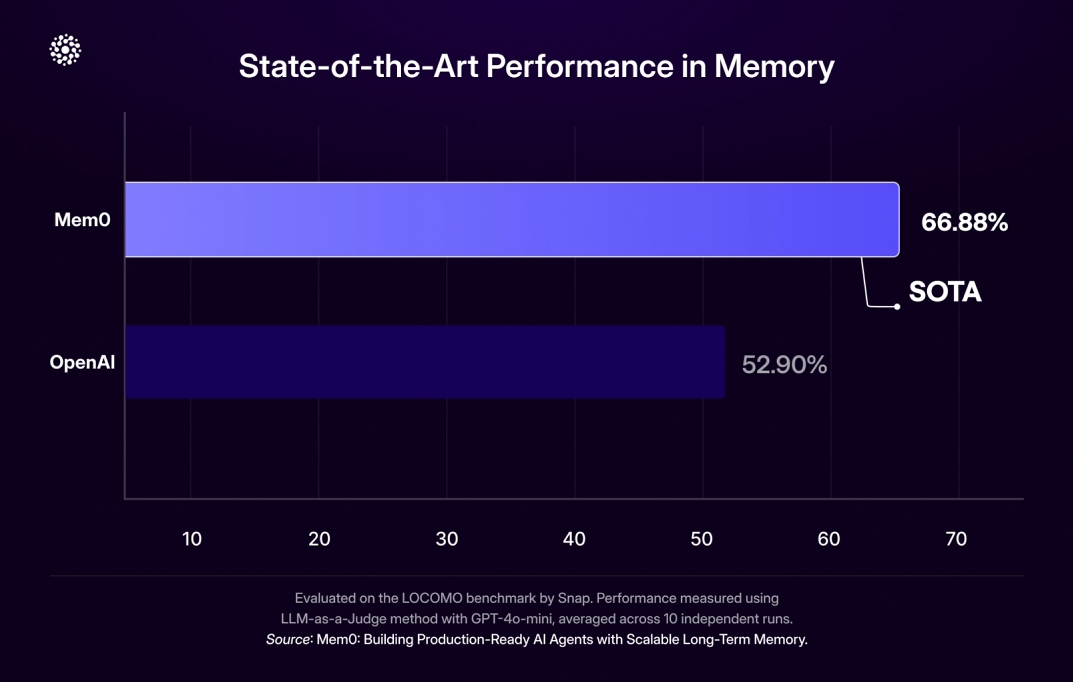
Mem0和OpenAI对比:
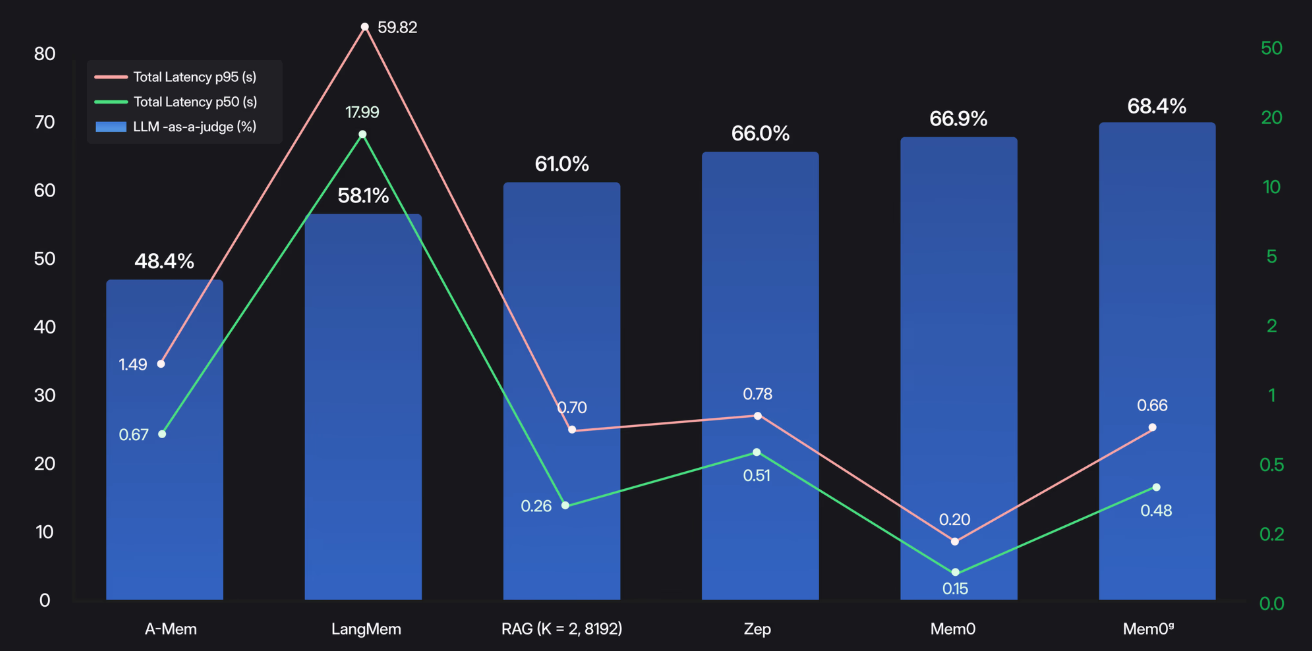
下面表比较了每种方法的搜索延迟(粉色表示中位数 p50,绿色表示尾部 p95)与其推理准确度(蓝色条)。
- Mem0 实现了66.9% 的准确度,中位数搜索延迟为 0.20 秒,p95 延迟为 0.15 秒,使记忆检索牢牢保持在实时范围内。
- 相比之下,标准 RAG 设置在中位数0.70 秒、 p95 搜索时间为0.26 秒的情况下仅能达到61.0% 的准确度。
- 图形增强变体 Mem0ᵍ 进一步将准确度提升至68.4%,中位数为0.66 秒, p95 搜索延迟为0.48 秒。
- 通过仅提取和索引最显著的事实,Mem0 提供了近乎最先进的长期推理能力,同时最大限度地降低了搜索开销。
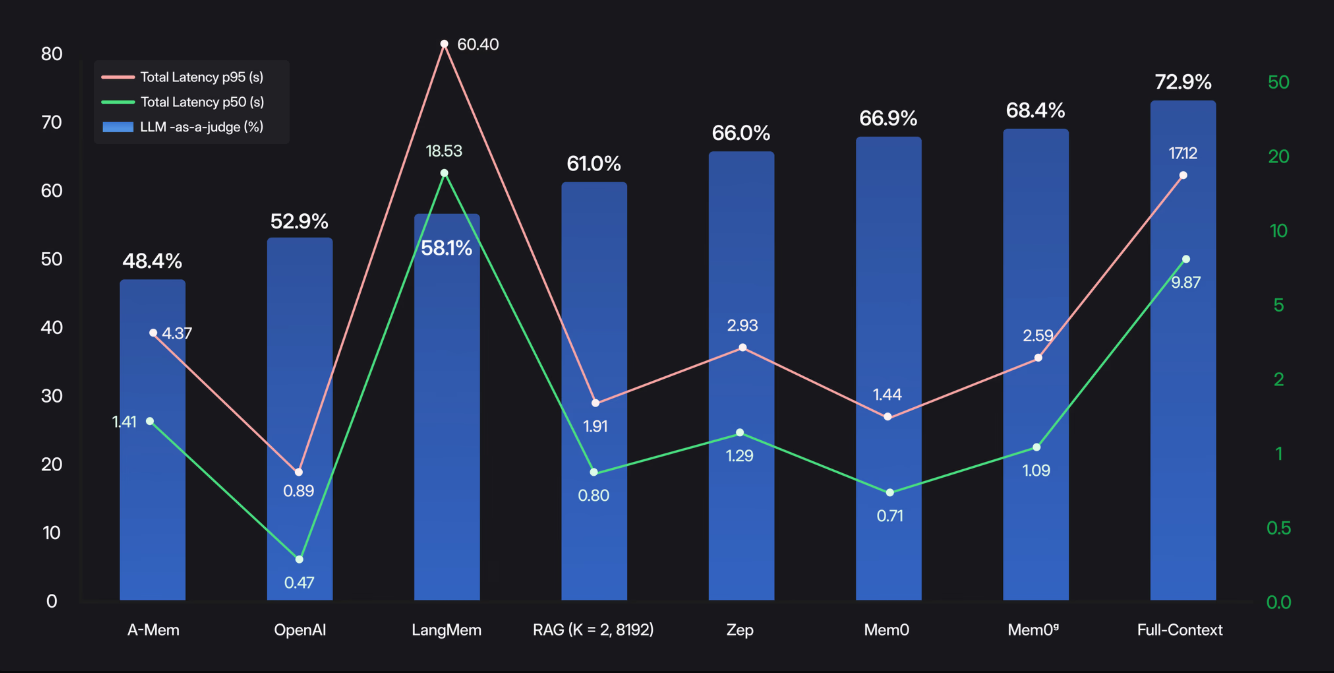
下面表是 端到端测量(内存检索 + 答案生成)展示了 Mem0 的效果。
- 全上下文方法可以达到 72.9% 的准确率,但中位数为 9.87 秒,p95延迟为 17.12 秒。
- 相比之下,Mem0 的准确率达到了66.9%,中位数仅为0.71 秒,p95端到端响应时间为 1.44 秒。
- 其图增强变体Mem0ᵍ将准确率提升至68.4%,同时保持了1.09 秒的中位数和2.59 秒的 p95延迟。
- 通过仅提取和索引最相关的事实,Mem0 能够以真正的生产速度提供近乎最先进的长期推理能力。
Mem0实现了26% 的准确率提升、91% 的 p95 延迟降低以及90% 的令牌节省,证明了持久化结构化内存在规模化应用下既强大又实用。
这些成果开启了一个未来:AI 代理不仅能做出反应,还能真正记住用户:在数周内保存用户偏好,适应不断变化的环境,并在医疗保健、教育和企业支持等领域保持连贯的个性化交互。
在此基础上,下一代内存系统可以探索分层和多模态表示、设备内存和动态整合机制,为真正与用户共同成长和发展的 AI 铺平道路。
分享完成~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)