ManiFlow:一致性流训练实现的通用机器人操作策略
25年9月来自西雅图华盛顿大学、UCSD、Nvidia 和 AI2 的论文“ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training”。本文介绍一种用于通用机器人操作的视觉运动模仿学习策略 ManiFlow,它能够根据不同的视觉、语言和本体感受输入,生成精确的高维动作。利用流匹配和一致性训练,仅需 1-2
25年9月来自西雅图华盛顿大学、UCSD、Nvidia 和 AI2 的论文“ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training”。
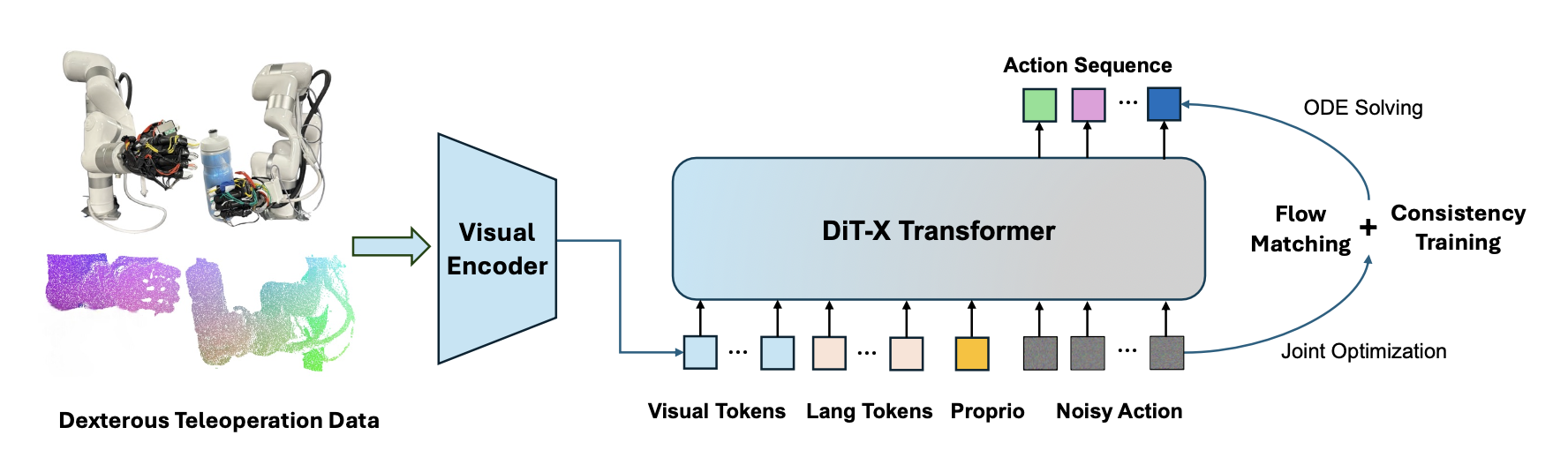
本文介绍一种用于通用机器人操作的视觉运动模仿学习策略 ManiFlow,它能够根据不同的视觉、语言和本体感受输入,生成精确的高维动作。利用流匹配和一致性训练,仅需 1-2 个推理步骤即可生成高质量的灵巧动作。为了高效处理不同的输入模态,提出 DiT-X,一种具有自适应交叉注意和 AdaLN-Zero 条件的扩散 transformer 架构,可实现动作 token 和多模态观测之间的细粒度特征交互。ManiFlow 在不同的模拟基准上表现出持续的改进,并且随灵巧性的提高,在单臂、双手和人形机器人设置的实际任务中成功率几乎翻一番。
最近,一种替代的生成式建模方法——流匹配 [2],与基于扩散的方法相比,在策略学习中表现出了更高的性能和训练效率 [3, 4]。尽管取得了这些进展,现有的流匹配策略 [3, 4, 5, 6] 在现实环境中执行复杂的灵巧操作任务时,在效率、鲁棒性和泛化性方面仍然受到限制。它们面临的挑战包括:如何捕捉多指交互的全部复杂性、保持动作序列之间的时间一致性、如何泛化到未见过的场景,以及架构约束不足以对各种现实世界任务(例如视觉、语言、本体感觉等)中固有的多个数据源进行建模。
为了应对这些挑战,ManiFlow,一个视觉运动模仿模型,旨在学习稳健且可推广的操控技能,以完成高度灵巧的复杂现实世界任务。ManiFlow 通过两项技术显著改进之前的流匹配策略 [6]。首先,将一致性训练目标合并到标准流匹配损失中,以鼓励从噪声样本到目标分布的更一致映射,从而有效地“理顺”流路径。正如实验所示,ManiFlow 可以在更少的推理步骤中生成准确而灵巧的动作。与之前为减少推理步骤所做的努力 [7] 相比,ManiFlow 不依赖任何预训练的教师模型,从而展示了更高的训练效率。其次,通过全面的消融,为流匹配模型提供有价值的见解和基线,揭示不同时间采样选择的意义,表明 beta 和连续时间采样对于流匹配和一致性训练的优势。
ManiFlow 如图所示:

除了一致性流训练过程之外,ManiFlow 还通过富有表现力的 Transformer 架构 DiT-X 改进模型架构,使其能够更有效地处理多样化的输入模态。DiT-X 模块基于图像生成 [8] 中的 DiT 模块构建,并使用更有效的 AdaLN-Zero 条件反射进行策略学习。具体而言,用交叉注意层处理高维视觉和语言输入,并使用 AdaLN-Zero 条件反射处理时间步长等低维输入。从 AdaLN-Zero 条件反射中学习的尺度和平移参数用于选择性地调整交叉注意的输入和输出特征,从而能够更高效、更灵活地对多模态输入进行条件反射。实验表明,一些简单而有效的修改,例如将 AdaLN-Zero 条件反射应用于交叉注意层以实现更具自适应性的条件反射,与 MDT [9] 等先前的研究相比,显著提高了策略性能。
本文在两种设置中开展评估:(1)模拟:单任务设置中的 3 个灵巧基准中的 12 个任务,多任务设置中的 48 个语言条件任务,以及在单任务设置中进行稳健性和泛化测试的 4 个双手灵巧任务。(2)现实世界:三种机器人设置中的 8 个具有挑战性的任务,随着灵活性的提高,包括单臂、双手和人形灵巧任务。
ManiFlow 的主要贡献体现在以下三个方面:
• 高质量高效的动作生成:ManiFlow 将流匹配与连续时间一致性训练目标相结合进行优化,以增强已学习流轨迹的自洽性和直线性。该方法仅需几个去噪步骤即可使策略生成高质量的高维、灵巧动作,从而提高推理速度。
• 高效的多模态条件反射:ManiFlow 集成了 DiT-X,这是一种 Transformer 架构,它通过自适应交叉注意层(具有学习的尺度和移位参数)来增强多模态条件反射。这使得能够跨不同输入模态进行选择性特征调制。
• 实际鲁棒性和泛化能力:在 3 种灵巧度不断提升的机器人设置上对 ManiFlow 进行评估,包括具有挑战性的双手和类人灵巧操作任务。 ManiFlow 在从有限的人类演示中建模复杂灵巧行为方面始终表现出卓越的鲁棒性,并显著提高对各种新物体和环境变化的泛化能力。
如图所示 ManiFlow 的策略架构:系统将二维或三维视觉观测、机器人状态或语言作为输入,并输出一系列动作。用 DiT-X Transformer 架构,高效优化具有连续时间一致性训练目标的流匹配模型,确保为具有挑战性的灵巧任务生成高质量的动作。
准备工作:流匹配
遵循 [11],将流常微分方程 (ODE) 正向过程定义为数据分布和噪声之间的直线路径。给定数据点 x_1 ∼ D、噪声点 x_0 ∼ N(0, I) 和时间步长 t ∼ U[0, 1],将 x_t 定义为 x_0 和 x_1 之间的线性插值,即 x_t = (1 − t) x_0 + t x_1,速度 v_t 表示从噪声到数据点的方向:v_t = x_1 − x_0。优化这个流模型 θ,以预测给定时间点 t 的噪声样本 x_t 时的速度。
ManiFlow 训练
ManiFlow 超越基本的流匹配模型,结合连续时间一致性训练目标和改进的时空采样策略。
连续时间一致性训练
与在推理过程中需要大量去噪步骤的标准扩散和流匹配模型 [1, 4] 相比,一致性训练 [12] 提供一种优雅的方法来提高生成质量,并实现无需依赖预训练教师模型的几步生成。其关键在于确保部分噪声数据点沿着常微分方程 (ODE) 轨迹与最终目标数据点保持一致。利用这一原理联合优化流匹配模型和一致性训练目标,以增强学习的流一致性,从而生成高质量的动作轨迹,如图所示。与 Shortcut 模型 [13] 类似,向流模型 v_t(x_t, t, ∆t) 添加另一个参数 ∆t,其中 ∆t 反映朝着下一个目标点的步长。
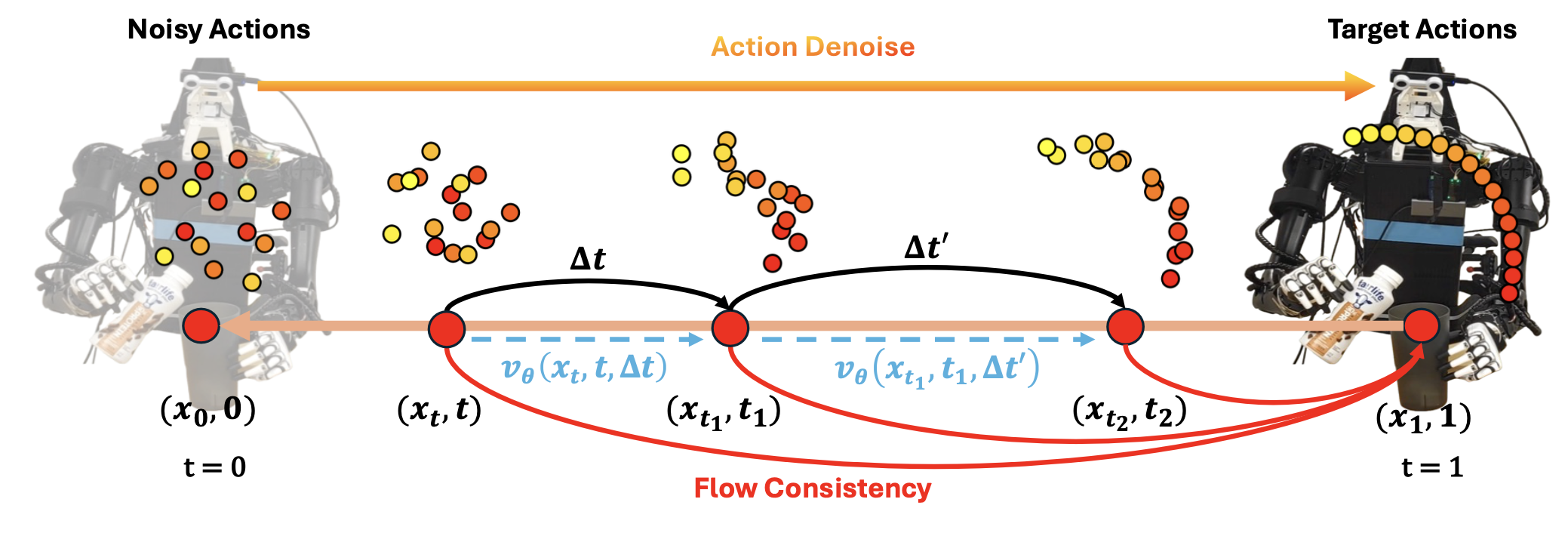
从离散化的 [0,1] 区间中采样一个时间步长 t,并从 U[0, 1] 中采样一个步长 ∆t。将下一个时间步长 t_1 定义为 t + ∆t,确保通过裁剪使其在 [0, 1] 内有界。在点 x_t_1 处朝向另一个时间步长 t_2(设为 t_1 + ∆t′)的速度 v_t_1 预测为 v_θ−(x_t_1, t_1, ∆t′),其中 θ− 是流模型的指数移动平均值 (EMA)。
为了增强点 x_t 和 x_t_1 之间的一致性,首先近似目标数据点 x ̃_1 =x_t_1 +(1−t_1)·v_t_1。然后,进一步估计从点 x_t 到 x ̃_1 的平均速度目标 v ̃_target,即 v ̃_target = (x ̃_1 − x_t) / (1 − t)。通过约束流模型来预测估计的速度目标,并使用一致性损失 L_CT 来增强一致性。
在 ManiFlow 训练中,将流匹配 L_FM 和一致性训练损失 L_CT 合并为 L(θ),其中流模型中的第三个参数 (∆t) 对于 L_FM 设置为 0,因为它估计的是局部瞬时速度 [13]。需要注意的是,与以离散时间步长 ∆t 进行的一致性训练 [12] 不同,这里从连续分布中采样 ∆t,以消除与离散时间目标相关的不良偏差,并确保更灵活的生成。注:EMA 模型提供了必要的稳定性 [12]。
时域空间采样策略
生成模型中的时间调度显著影响着学习动态和最终性能。评估流匹配中五种具有代表性的时间步长 t 采样策略,可视化结果如下图所示,而其伪代码和算法 1 所示:
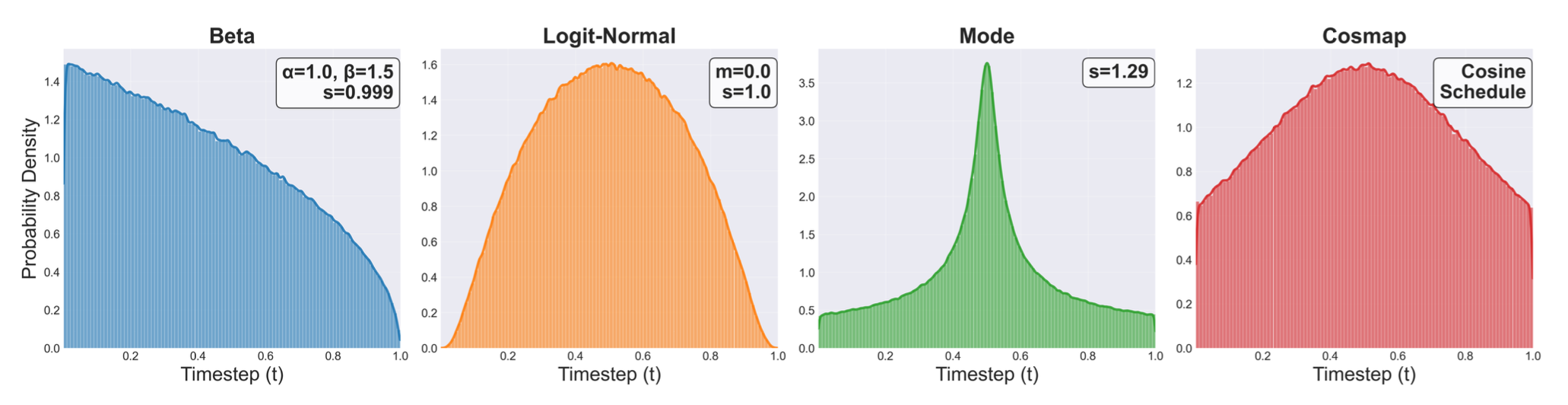

(1)均匀采样 [11],从 [0,1] 均匀地抽取时间步长,作为直接基线;(2)对数正态采样(对数范数)[14],通过位置和尺度参数可调的对数正态分布强调中间时间步长;(3)模式采样 [15],通过尺度参数 s 明确控制在训练期间是偏向中点还是端点;(4)CosMap 采样 [16],通过专门的映射函数将扩散模型的余弦调度调整到流匹配设置; (5) Beta 分布采样 [17],它对与噪声较大动作相对应的较低时间步长赋予更多权重,并设置截止阈值 s = 0.999,以避免对学习价值贡献最小的时间步长进行采样。
虽然对数范数采样表现出色,但 Beta 分布对高噪声状态的关注对于机器人控制任务尤其有效,在不同操作场景中优于其他调度策略。进一步在一致性训练中减小步长选择 ∆t,连续时间表现出更好的性能。
ManiFLow 模型采用单阶段训练方法,联合优化流匹配和一致性目标,而无需预训练的教师模型。不会直接将中间点的速度约束为沿流路径的相同速度(这通常会导致简单的解和不稳定的训练),而是学习从任何部分噪声数据点到最终目标数据点的映射,从而确保整个 ODE 轨迹的自洽性。如下算法 2 中提供 ManiFlow 训练的伪代码:

联合训练策略。为了降低 ManiFlow 的训练成本,训练批次由两个具有不同批次比率的部分组成:75% 用于流匹配训练,25% 用于一致性训练。在流匹配训练期间,设置 ∆t = 0 来预测时间步 t 的瞬时速度,而一致性训练使用从连续均匀分布中采样的 ∆t 来强制同一轨迹上不同点之间的一致性。此外,对 t 使用不同的时间采样策略:流匹配采用 Beta 分布来强调高噪声区域,一致性训练采用离散均匀采样来覆盖整个去噪轨迹。
目标时间调节。速度预测中的一个关键设计选择是目标时间步长的调节。评估两种模式:绝对模式,其中模型预测朝向 t + ∆t 的速度;以及相对模式,其中模型预测步长 ∆t 的速度。根据经验,相对模式(∆t 调节)比绝对模式性能更佳,因为它为模型提供了更直接的步长信息,以学习合适的速度大小。
EMA 稳定性。指数移动平均 (EMA) 模型在稳定一致性训练中起着至关重要的作用 [12]。在一致性训练期间,需要在未来时间步长上进行可靠的速度预测以计算一致性目标,但使用当前模型(正在更新)可能会由于预测的快速变化而导致训练不稳定。相反,保留 EMA 版本的模型参数 θ− = μθ− + (1 − μ)θ,其中 μ 是动量系数。该 EMA 模型通过在中间时间步提供缓慢演化、更可靠的速度预测,为一致性训练提供稳定的目标生成。EMA 机制确保一致性目标在训练迭代过程中保持相对稳定,从而防止震荡,并实现流匹配和一致性目标的平滑收敛。
感知
3D 视觉编码器在 [10] 的基础上进行了改进,优先保留 3D 点云表示中的细粒度几何信息。关键在于,在整个编码过程中保持详细的空间关系对于精确的操作任务至关重要。虽然 [10] 等先前的研究使用最大池化操作将点云特征压缩为紧凑的表示,但这种压缩会导致重要的几何细节丢失。本文架构刻意避免此类池化操作,而是在整个网络中保留逐点特征。这种设计选择使编码器能够保留输入点云更丰富的空间关系和详细的几何信息,这对于需要精确目标交互和空间推理的任务尤其有益。
经验观察表明,场景配置显著影响表示效率的最佳点密度。在经过良好标定且裁剪点的场景中,ManiFlow 在 128 个点的稀疏点云中实现了强劲的性能,证明了网络的高效性。对于未标定的自我中心视图,4096 个点的更密集表示就足够了,这表明在结构化程度较低的环境中增加点密度是有好处的。
ManiFlow 策略架构
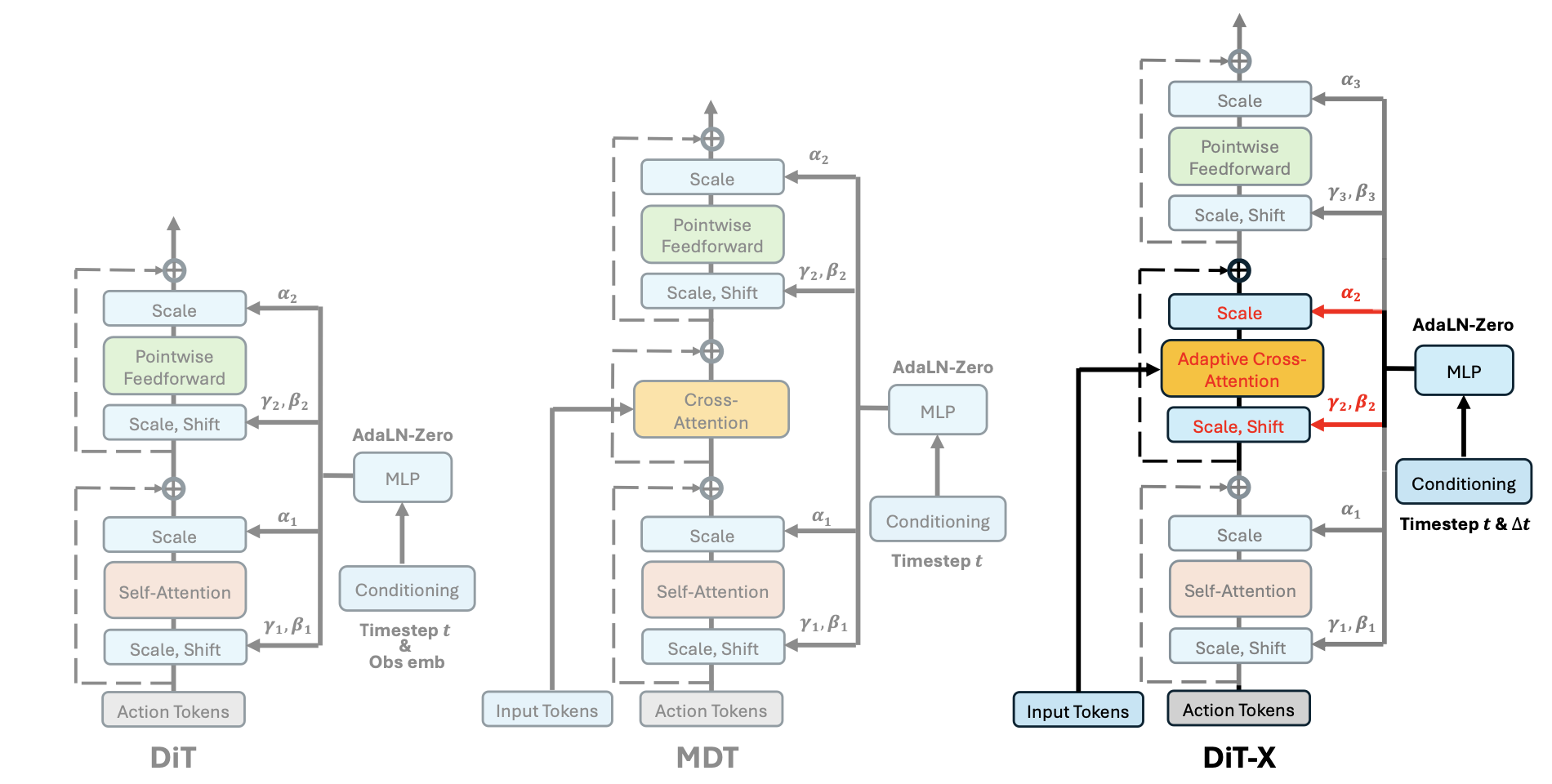
鉴于标准交叉注意机制(例如 MDT [9])缺乏自适应调节,引入 DiT-X,一种 Transformer 架构,能够有效处理低维信号和高维多模态输入,以实现通用机器人控制。其设计源于生成模型在处理多种输入模态方面所面临的固有挑战:低维信号需要对高频动态进行精确编码,视觉输入包含丰富的空间语义信息,而语言指令则需要细粒度的语言理解。遵循以下原则设计一种用于多模态调节的富有表现力架构。
适应性和粒度:能够生成高度自适应的动作对于动态环境中的机器人操控至关重要,这需要进行精确的反应式调整。此外,高维视觉和语言特征与低维信号的融合需要细粒度理解和自适应交互。通过一种专用的自适应交叉注意机制来解决这个问题,该机制支持动作与多模态输入之间进行直接的 token 级交互,从而实现精确的空间和语义对齐。
具有自适应交叉注意条件的 DiT-X 模块:引入自适应交叉注意层来处理具有低维输入的视觉和语言 tokens。具体而言,给定时间步长等低维输入,采用 AdaLN-Zero 条件 [8] 来生成缩放和平移参数 (α, γ, β),以动态调整网络行为,同时通过零初始化确保训练稳定性。具体而言,不仅将缩放和平移参数应用于自注意层和前馈层,还以相同的调制方式调整交叉注意层的输入和输出。这种设计使网络能够通过选择性地按比例缩小或放大来操纵细粒度的视觉和语言 token,这对于需要精确理解视觉线索和语言指令的任务至关重要。虽然这会引入适度的计算开销,但增强的表征能力对于复杂的操纵任务而言非常有价值。
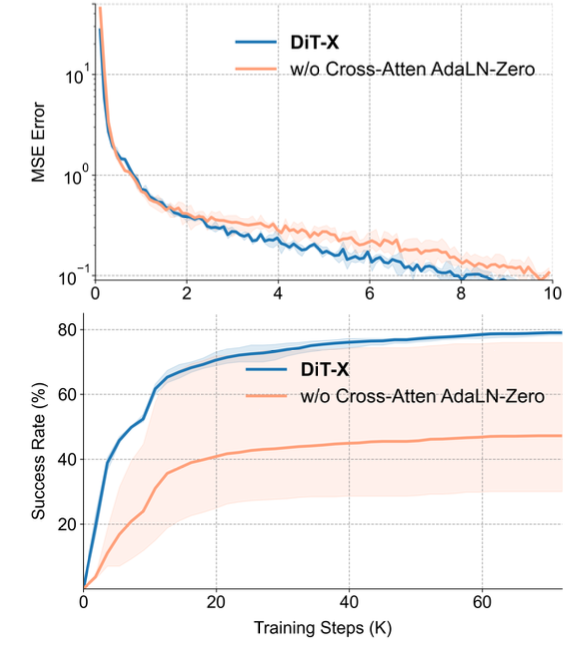
如图所示,DiT-X 模块在训练过程中表现出比无交叉注意的 AdaLN-Zero 条件作用更快的收敛速度和更好的性能。
此外,如图提供 DiT 和 MDT 架构基线的详细说明。
仿真实验
基准:选择三个不同的灵巧操作基准(Adroit [18]、Dexart [19] 和 RoboTwin 1.0 [20]),在 12 个灵巧任务中全面评估 ManiFlow,这些任务评估了广泛的操作能力。此外,利用包含 48 个任务的 MetaWorld 基准 [21],专注于具有挑战性的语言条件多任务学习场景,以全面评估模型在以视觉和语言输入为条件时的性能。进一步使用 RoboTwin 2.0 基准 [22] 来全面测试策略的鲁棒性和泛化能力。
基线方法:对于 2D 图像输入,将 ManiFlow 与扩散策略 [1] 和流匹配策略 [6] 进行比较,并使用相同的 ResNet-18 编码器 [23]。对于基于 3D 点云的方法,主要与 3D 扩散策略 (DP3) [10] 进行比较,后者已证明其性能优于 2D 扩散策略跨多种模拟环境的策略。由于原始论文中提到的流匹配策略 [6] 仅基于图像,为其添加 [10] 中相同的 3D 编码器,从而为基于 3D 的流匹配模型构建基准,并将其记为 3D 流匹配策略*。在 RoboTwin 2.0 基准测试中,将其与 π0 模型进行比较,该模型以多视角图像为输入,并针对域随机化数据进行了微调。
真实世界实验
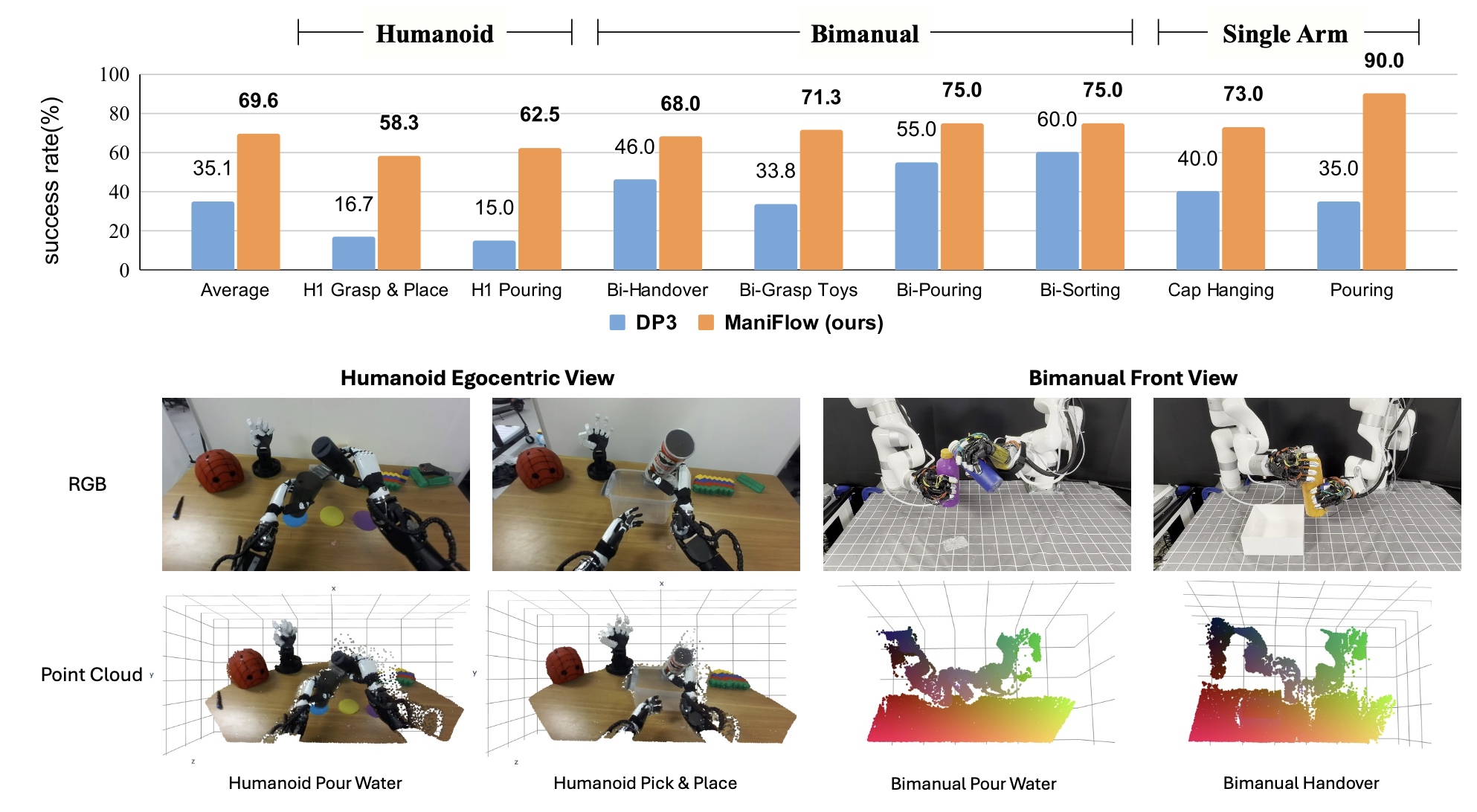
如图所示真实世界设置。实验设置包括三种配置:(1)双手 Unitree H1 人形机器人,配备 7 自由度手臂、拟人手和万向架立体摄像头;(2)双手 7 自由度 xArm 设置,配备 PSYONIC Ability Hands 和英特尔 RealSense L515 摄像头;(3)Franka Emika Panda 机器人,配备 Robotiq 夹持器和静态定位的英特尔 RealSense D455 摄像头。

利用 3 种机器人设置,在 8 个真实机器人任务上对 ManiFlow 进行评估,这些机器人设置的灵活性逐渐增强,如图所示。每种设置都基于一组独特的任务进行评估,旨在评估 ManiFlow 在不同场景下的性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 43
43 0
0- 0



 已为社区贡献121条内容
已为社区贡献121条内容

所有评论(0)