DanceGRPO:释放 GRPO 在视觉生成上的潜能
25年8月来自字节 Seed 和香港大学的论文“DanceGRPO: Unleashing GRPO on Visual Generation”。生成式人工智能 (GenAI) 的最新进展彻底改变了视觉内容的创作,然而,如何使模型输出与人类偏好相一致仍然是一项关键挑战。虽然强化学习 (RL) 已成为一种颇具前景的生成式模型微调方法,但现有方法(例如 DDPO 和 DPOK)仍面临一些根本性的局限性
25年8月来自字节 Seed 和香港大学的论文“DanceGRPO: Unleashing GRPO on Visual Generation”。
生成式人工智能 (GenAI) 的最新进展彻底改变了视觉内容的创作,然而,如何使模型输出与人类偏好相一致仍然是一项关键挑战。虽然强化学习 (RL) 已成为一种颇具前景的生成式模型微调方法,但现有方法(例如 DDPO 和 DPOK)仍面临一些根本性的局限性——尤其是在扩展到庞大且多样化的提示集时,它们无法保持稳定的优化,这严重限制了它们的实际应用。本文的 DanceGRPO 框架,通过对组相对策略优化 (GRPO) 进行创新性调整,以解决视觉生成任务中的这些局限性。其关键见解是,GRPO 固有的稳定性机制使其能够克服困扰先前基于 RL 视觉生成方法的优化挑战。DanceGRPO 的进步在于:首先,它在多个现代生成范式(包括扩散模型和矫正流)中展示了一致且稳定的策略优化。其次,它在扩展到包含三个关键任务和四个基础模型的复杂真实场景时仍保持了稳健的性能。第三,它在针对人类多样化偏好进行优化方面展现出卓越的多功能性,这体现在五种不同的奖励模型中,这些模型分别评估图像/视频的美观度、文本-图像对齐、视频运动质量和二值反馈。实验表明,DanceGRPO 在多个已建立的基准测试(包括 HPS-v2.1、CLIP Score、VideoAlign 和 GenEval)上的表现比基线方法高出高达 181%。
理论初步
扩散模型 [1]。扩散过程通过将数据与噪声混合,在时间步长 t 内逐渐破坏观察的数据点 x,并且扩散模型的前向过程可以轻松定义如下:
z_t = α_t x + σ_t ε,其中 ε ∼ N(0,I) (1)
其中 α_t 和 σ_t 表示噪声方案。噪声方案的设计使得 z_0 接近于干净数据,z_1 接近于高斯噪声。为了生成新的样本,初始化样本 z_1,并定义扩散模型的样本方程,给定时间步 t 的去噪模型输出 εˆ:
z_s =α_s xˆ + σ_s εˆ, (2)
其中 xˆ 可以通过公式 (1) 导出,然后可以达到较低的噪声水平 s。这也是一个 DDIM 采样器 [28]。
矫正流 [6]。在矫正流中,将前向过程视为数据 x 和噪声项 ε 之间的线性插值:
z_t = (1−t) x + t ε, (3)
其中 ε 始终定义为高斯噪声。将 u = ε − x 定义为“速度”或“矢量场”。与扩散模型类似,给定时间步长 t 的去噪模型输出 uˆ,可以通过以下方式达到更低的噪声水平 s:
z_s = z_t + uˆ · (s − t)。 (4)
分析。虽然扩散模型和整流流的理论基础不同,但在实践中,它们是同一事物的两面,如下式所示:
z ̃_s = z ̃_t + 网络输出 · (η_s − η_t)。 (5)
对于ε-预测(又称扩散模型),根据公式(2),有z ̃_s = z_s/α_s,z ̃_t = z_t/α_t,η_s = σ_s/α_s,η_t = σ_t/α_t。对于整流流,根据公式(4),有z ̃_s = z_s,z ̃_t = z_t,η_s = s,η_t = t。
DanceGRPO
将去噪表示为马尔可夫决策过程。遵循 DDPO [18],扩散模型和矫正流的去噪过程表示为马尔可夫决策过程 (MDP):
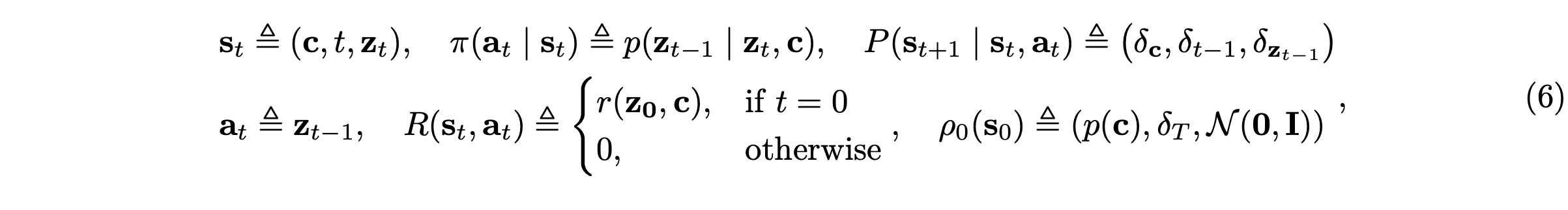
采样随机微分方程 (SDE) 的公式化。由于 GRPO 需要通过多个轨迹样本进行随机探索,其中策略更新取决于轨迹概率分布及其相关的奖励信号,因此将扩散模型和整流流的采样过程统一为 SDE 的形式。对于扩散模型,如 [30, 31] 所示,前向 SDE 由下式给出:dz_t = f_t z_t d_t + g_t dw。对应地,可以给出这个逆 SDE 方程:
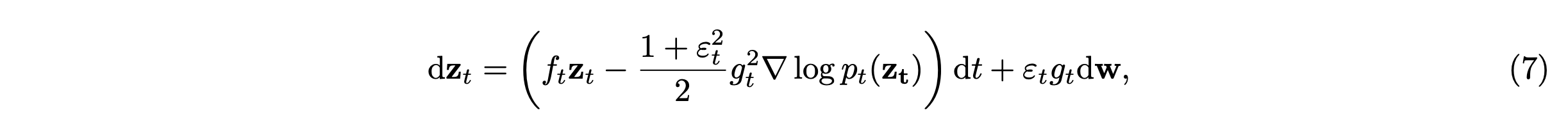
类似地,矫正流的前向微分方程为:dz_t = u_t dt。生成过程在时间上反转该微分方程。然而,这种确定性公式无法提供 GRPO 所需的随机探索。受 [32–34] 的启发,本文在逆过程中引入一个 SDE 情况:
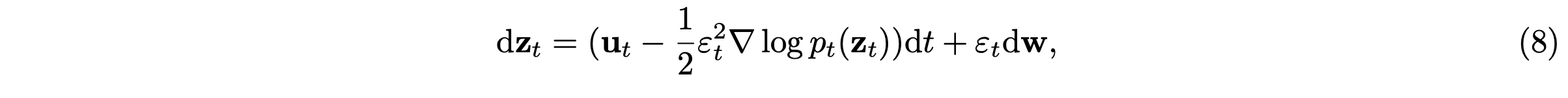
算法。受 Deepseek-R1 [20] 启发,给定提示 c,生成模型将从模型 π_θ_old 中采样一组输出 {o_1,o_2,…,o_G},并通过最大化如下定义的目标函数来优化策略模型 π_θ:
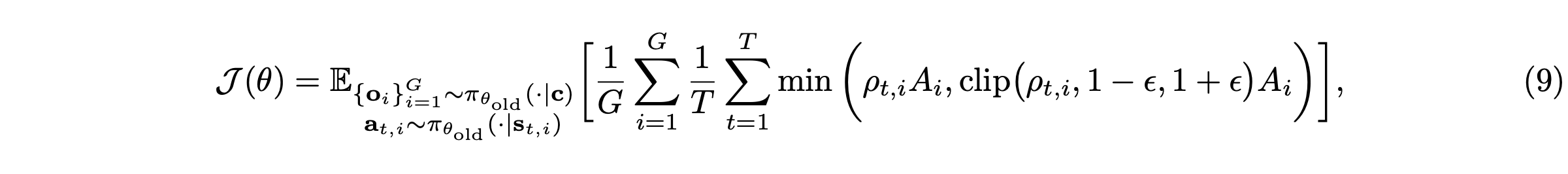
其中关键是 A_i 优势函数,使用一组奖励 {r_1,r_2,…,r_G} 计算得出,这些奖励对应于每组内的输出:
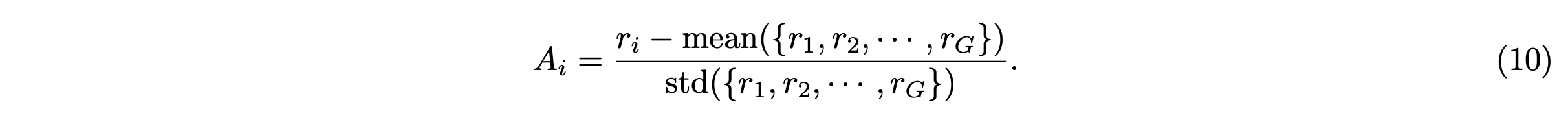
由于实际应用中的奖励稀疏性,在优化过程中对所有时间步应用相同的奖励信号。虽然传统的 GRPO 公式采用 KL 正则化来防止奖励过度优化,但根据经验观察到,省略此组件时性能差异极小。因此默认省略 KL 正则化项。完整算法可在算法 1 中找到。另外使用无分类器指导 (CFG) [35] 可以进行训练。

总而言之,将扩散模型和矫正流的采样过程公式化为 MDP,使用 SDE 采样方程,采用 GRPO 风格的目标函数,并将其推广到文本-转-图像、文本-转-视频和图像-转-视频的生成任务。
初始化噪声。在 DanceGRPO 框架中,初始化噪声至关重要。先前基于强化学习的方法(例如 DDPO)使用不同的噪声向量来初始化训练样本。然而,为具有相同提示的样本分配不同的噪声向量总是会导致视频生成中的奖励黑客现象,包括训练不稳定。因此,在本文框架中,为源自相同文本提示的样本分配共享的初始化噪声。
时间步长选择。虽然降噪过程可以在 MDP 框架内严格形式化,但经验观察表明,可以在不影响性能的情况下省略降噪轨迹中的部分时间步长子集。计算步骤的减少提高了效率,同时保持了输出质量。
融合多种奖励模型。在实践中,采用多种奖励模型,以确保更稳定的训练和更高质量的视觉结果。仅使用 HPS-v2.1 奖励 [25] 训练的模型往往会生成不自然/“油腻(oily)”的输出,而结合 CLIP 分数则有助于保留更真实的图像特征。没有直接组合奖励,而是聚合优势函数,因为不同的奖励模型通常在不同的尺度上运行。这种方法可以稳定优化并实现更均衡的生成。
N-中-最佳推理规模化的扩展。本文方法优先使用高效样本,具体来说,是与最佳 N 采样方法选出的前 k 个和后 k 个候选样本相关的样本。这种选择性采样策略通过关注解空间中的高奖励区域和关键的低奖励区域来优化训练效果。用暴力搜索来生成这些样本。当然树搜索或贪婪搜索等替代方法仍然是有希望进一步探索的途径。
应用于不同奖励的不同任务
在两种生成范式(扩散/矫正流)和三种任务(文本转图像、文本转视频、图像转视频)中验证算法的有效性。为此,选择四种基本模型(SD [2]、HunyuanVideo [22]、FLUX [23] 和 SkyReels-I2V [24])进行实验。所有这些方法都可以在采样过程中在 MDP 框架内精确构建。这样能够统一这些任务的理论基础,并通过 DanceGRPO 对其进行改进。
用五种奖励模型来优化视觉生成质量:(1) 图像美学模型使用基于人工评分数据进行微调的预训练模型来量化视觉吸引力 [25];(2) 文本-图像对齐模型采用 CLIP [26] 来最大化提示和输出之间的跨模态一致性; (3) 视频美学质量 (Video Aesthetics Quality) 使用视觉语言模型 (VLM) [14, 29] 将图像评估扩展到时域,评估帧质量和连贯性;(4) 视频运动质量 (Video Motion Quality) 通过基于物理感知的 VLM [14] 分析轨迹和变形来评估运动的真实度;(5) 阈值二元奖励 (Thresholding Binary Reward) 采用一种受 [20] 启发的二元机制,其中奖励通过固定阈值离散化(超过阈值的值取 1,其他取 0),专门用于评估生成模型在基于阈值的优化下学习突发奖励分布的能力。
DDPO、DPOK、ReFL 和 DPO 的比较
如表中全面的能力矩阵所示,DanceGRPO 为扩散模型对齐设立新的标准。该方法在所有评估维度上都实现了全方位的优势:(1)无缝视频生成;(2)大规模数据集可扩展性;(3)显著的奖励提升;(4)与校正流的原生兼容性;以及(5)不依赖于可微分奖励。这种集成能力——任何单一基准方法(DDPO/DPOK/ReFL/DPO)都无法实现——能够在保持训练稳定性的同时,跨多个生成域进行优化。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献121条内容
已为社区贡献121条内容

所有评论(0)