comfyUI实战——使用openArt的工作流
想要由一张照片生成简笔画,要不是使用醒图之类的工具手动描边,也试了豆包等ai去处理,但是结果还是不如人意。小红书发现有好心人bole分享了他搭建的。可以认为模块是一些python脚本,可以使用Manager安装,模型是别人训练好的模型,一般在huggingface网站可以找到。在运行工作流时,有问题的位置会以红色框显示,也可以在左边菜单栏点击终端看代码到底是哪里报错的。
想要由一张照片生成简笔画,要不是使用醒图之类的工具手动描边,也试了豆包等ai去处理,但是结果还是不如人意。小红书发现有好心人bole分享了他搭建的工作流。
可以认为模块是一些python脚本,可以使用Manager安装,模型是别人训练好的模型,一般在huggingface网站可以找到。在运行工作流时,有问题的位置会以红色框显示,也可以在左边菜单栏点击终端看代码到底是哪里报错的。
模块安装
工作流就是json文件,导入json文件到comfUI中可以看到还是比较复杂的。同时也看到了提示缺少一些节点。工作流中异常的节点会以红色框表示。可以打开Manager安装: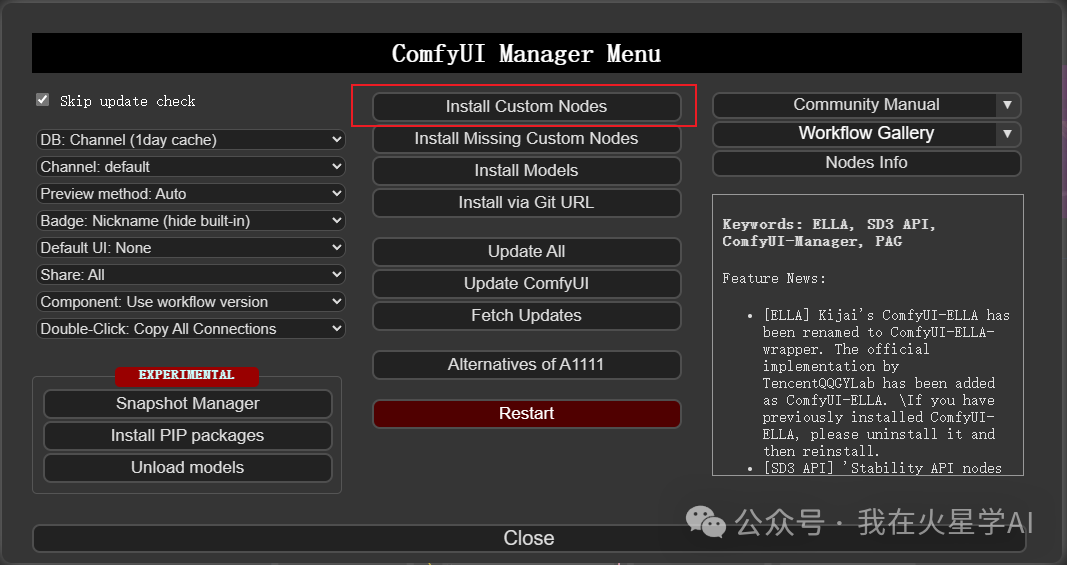
上面可以看到,除了安装,还可以对已经有的节点进行update。
安装完之后会提示Restart Required,意味着重启才会comfUI生效。发现文件夹中对应的节点:
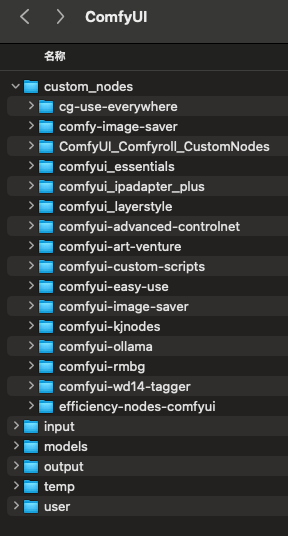
在我使用的这个workflow中,AV_IPAdapter还是找不到。文心一言说AV_IPAdapter 可能是某个自定义节点(如 ComfyUI_IPAdapter_plus 或其变体)的一部分。但是安装ComfyUI_IPAdapter_plus也会报错:
Installation Error:
Install(git-clone) error[2]: https://github.com/cubiq/ComfyUI_IPAdapter_plus / Cmd('git') failed due to: exit code(128)
cmdline: git clone -v --recursive --progress -- https://github.com/cubiq/ComfyUI_IPAdapter_plus /Users/zcg/Documents/ComfyUI/custom_nodes/ComfyUI_IPAdapter_plus这时可以从github中手动下载代码,然后放在custom_nodes文件夹中。我发现其实原来也有ComfyUI_IPAdapter_plus文件夹,只不过文件名是小写,可能是这个有影响。
在models文件夹中则存储的是不同功能的模型文件。
| 模型类型 | 本地文件夹路径 | 用途说明 |
|---|---|---|
| 大模型 | ComfyUI/models/checkpoints |
存放SDXL、Flux等主模型文件(如.ckpt、.safetensors格式)。 |
| LoRA模型 | ComfyUI/models/loras |
存放风格化、细节增强等微调模型(如动漫、写实风格LoRA)。 |
| VAE模型 | ComfyUI/models/vae |
控制图像色彩、细节的编码器-解码器模型(如ae.safetensors)。 |
| CLIP模型 | ComfyUI/models/clip |
处理文本提示的文本编码器(如t5xxl_fp8_e4m3fn.safetensors)。 |
| ControlNet模型 | ComfyUI/models/controlnet |
控制图像结构、姿势的预处理模型(需手动调整路径以兼容WebUI)。 |
| UNet模型 | ComfyUI/models/unet |
存放Flux等模型的去噪网络(如flux1-fp8-dev.safetensors)。 |
| 扩散模型 | ComfyUI/models/diffusion_models |
特殊模型类型(如Qwen-Image-Edit的主模型)。 |
| 文本编码器 | ComfyUI/models/text_encoders |
专用文本处理模型(如Qwen-Image的qwen_2.5_vl_7b_fp8_scaled.safetensors)。 |
在这个工作流中使用了LayerMask,该模型属于图像分层与遮罩处理类,节点右上角可以看到它属于comfui_layerstyle类,在custom_nodes中也有同名的文件夹。具体对应models/layerstyle或models/layers子文件夹。
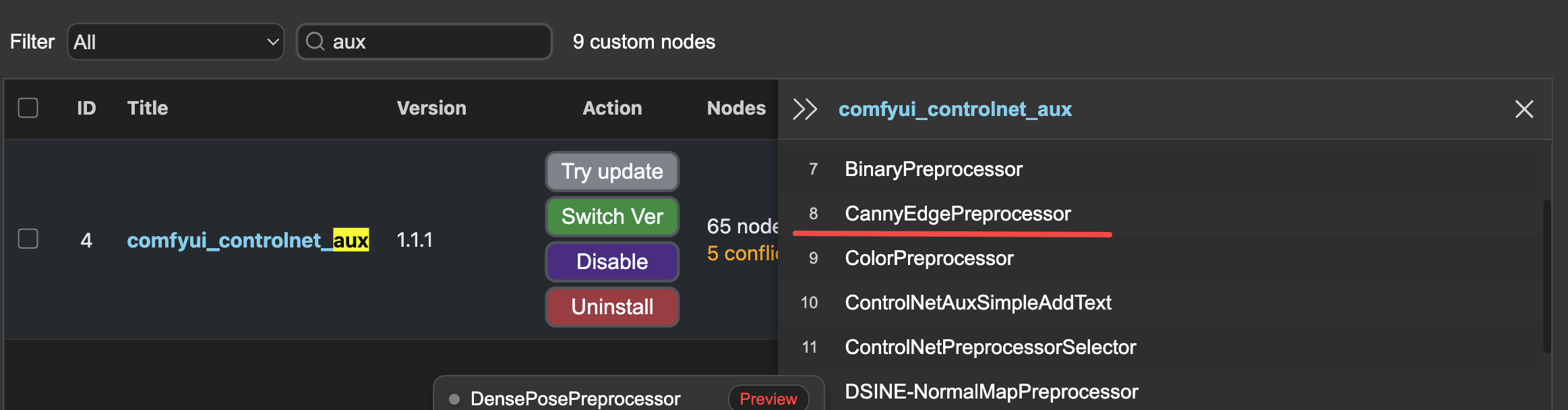
下一个遇到的是cotrolnet的预处理器,它依赖于comfyui_controlnet_aux,使用ComfyUI Manager安装。它有65个节点,其中一个就是canny算子:
模型下载
一般基础模型都在models文件夹下,在models文件夹中存储的是不同功能的模型文件。
| 模型类型 | 本地文件夹路径 | 用途说明 |
|---|---|---|
| 大模型 | ComfyUI/models/checkpoints |
存放SDXL、Flux等主模型文件(如.ckpt、.safetensors格式)。 |
| LoRA模型 | ComfyUI/models/loras |
存放风格化、细节增强等微调模型(如动漫、写实风格LoRA)。 |
| VAE模型 | ComfyUI/models/vae |
控制图像色彩、细节的编码器-解码器模型(如ae.safetensors)。 |
| CLIP模型 | ComfyUI/models/clip |
处理文本提示的文本编码器(如t5xxl_fp8_e4m3fn.safetensors)。 |
| ControlNet模型 | ComfyUI/models/controlnet |
控制图像结构、姿势的预处理模型(需手动调整路径以兼容WebUI)。 |
| UNet模型 | ComfyUI/models/unet |
存放Flux等模型的去噪网络(如flux1-fp8-dev.safetensors)。 |
| 扩散模型 | ComfyUI/models/diffusion_models |
特殊模型类型(如Qwen-Image-Edit的主模型)。 |
| 文本编码器 | ComfyUI/models/text_encoders |
专用文本处理模型(如Qwen-Image的qwen_2.5_vl_7b_fp8_scaled.safetensors)。 |
也有一些放在用户节点的文件夹下。下面是这个工作流使用的一些模型:
| 模型 | 位置 | 说明 |
|
BiRefNet-general-epoch_244.pth 这是最新发布的通用版本模型,训练数据包含了肖像分割数据,在更广泛的应用场景下表现更优,大小有800多MB。 如果报错:Torch not compiled with CUDA enabled. cpu,可以在界面的device选项中选择cpu。 |
ComfyUI/models/BiRefNet/ |
分割主体,得到mask作为遮罩
|
|
leosamsHelloworldXL_helloworldXL70.safetensors |
ComfyUI/models/checkpoints/ |
最基础的大模型,6.9GB,会输出模型,CLIP,VAE |
|
araminta_k_midsommar_cartoon.safetensors |
ComfyUI/models/loras/ |
lora模型 会接受checkpoint输出的模型和CLIP,输出新的CLIP和新的模型。 CLIP去编码正反向的提示词,模型去参与构成art-venture |
|
SmilingWolf/wd-v1-4-vit-tagger-v2 |
ComfyUI/custom_nodes/comfyui-wd14-tagger/models/ |
生成图像的描述文本,作为正面生成提示词,需要下载同名的onnx和csv文件 |
|
ip-adapter_sdxl_vit-h.safetensors https://huggingface.co/h94/IP-Adapter/blob/main/sdxl_models/ip-adapter_sdxl_vit-h.safetensors |
ComfyUI/models/ipadapter/ |
和下面的clip,还有lora输出的模型,一起构成art-venture |
| CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors |
ComfyUI/models/clip_vision |
和上面的clip,还有lora输出的模型,一起构成art-venture。clip-vit的作用是对图像进行编码 |
| comfyui_controlnet_aux | 使用ComfyUI Manager安装,comfyui_controlnet_aux |  |

连接和运行
下载的工作流其实是有问题的,比如这个酒一直提示缺少model和vae,我暂时也不知道anythingAnywhere怎么使用,所以改成直接连接。这里分享一下我修改后的工作流,可以在文章标题处看到。
没有问题后点击运行,一般会话费几分钟时间。
| 输入图 | 输出图 |
 |
 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)