大模型应用开发1-认识大模型
摘要: 本文系统介绍了大模型的基础概念、本地部署及API调用方法。首先阐述了AI及神经网络的基本原理,重点解析了Transformer架构及其在大语言模型(LLM)中的应用。其次详细对比了三种模型使用方案(开放API/云部署/本地部署)的优缺点,并以Ollama为例演示了本地部署流程,包括模型管理、交互指令和GPU加速配置。最后说明了大模型API调用规范,列举了主流大模型产品及其应用场景,强调大模
1.基础概念
1.1 AI的概念:
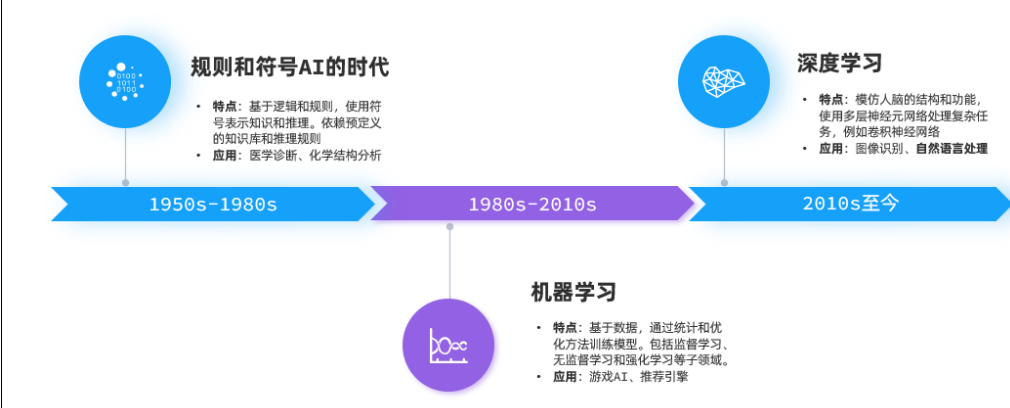
1.2 神经网络的基本概念
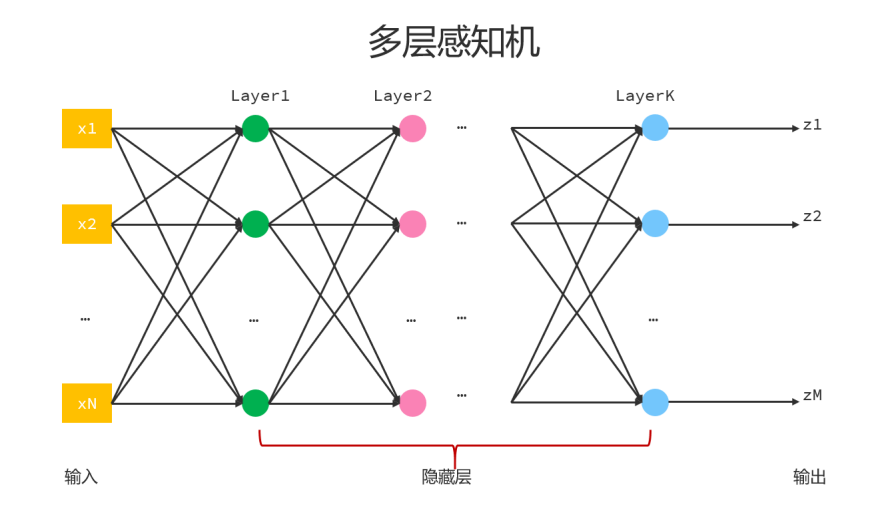
如果我们想通过模拟人脑的方式实现人工智能,首先就要模拟出一个神经元,于是人们提出感知机模型,用于模拟神经元,在感知机模型中,有输入,权重,激活函数,假设输入和激活函数都不变的情况下,我们可以通过调整权重值,得到不同输出。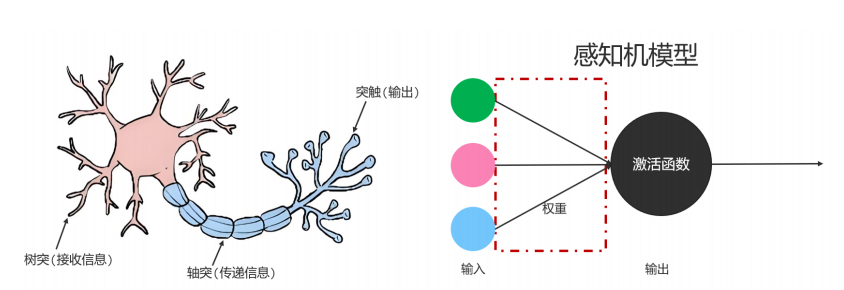
单个感知机模型只能模拟单个神经元,每个感知机上都有输入,输出,激活函数,将来会结合用户的输入和权重以及激活函数,再与阈值(偏置)比较,最终得到输出,每个神经元上使用的权重和阈值都称为参数,每个神经元上的参数数量=权重数量+1,这里的1指的是偏置。
大模型的大指参数规模,现在我们通常将参数规模在1000亿以上的模型称为大模型。
1.3 大模型的基本概念
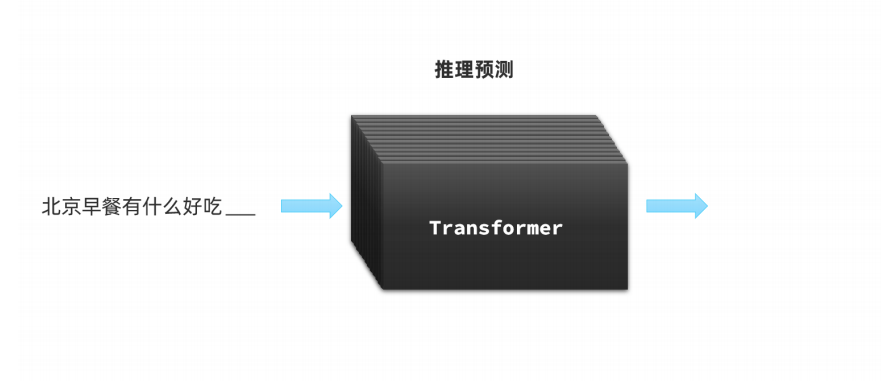
2.大模型基本使用
2.1 模型使用方案
我们要使用一个可访问的大模型通常有三种方案:
使用开放的API,在云平台部署私有大模型,在本地服务器部署私有大模型
开放API没有运维成本,按调用收费,但是长期使用成本较高且数据存在第三方,存在隐私和安全问题。云平台部署私有模型部署和运维方便,前期投入成本低,但是长期使用成本高,且同样存在安全问题。本地部署私有大模型数据完全自主掌控,安全性高,但硬件投入成本极高且维护困难。
2.2 Ollama本地部署
下载Ollama客户端并根据指令进行模型部署等操作
一、基础操作指令
| 指令 | 功能 | 示例 |
|---|---|---|
ollama run <模型名> |
运行指定模型(自动下载若不存在) | ollama run llama3 |
ollama list |
查看本地已下载的模型列表 | ollama list |
ollama pull <模型名> |
手动下载模型 | ollama pull mistral |
ollama rm <模型名> |
删除本地模型 | ollama rm llama2 |
ollama help |
查看帮助文档 | ollama help |
二、模型交互指令
1. 直接对话
ollama run llama3 "用中文写一首关于秋天的诗"2. 进入交互模式
ollama run llama3
# 进入后输入内容,按 Ctrl+D 或输入 `/bye` 退出3. 从文件输入
ollama run llama3 --file input.txt4. 流式输出控制
| 参数 | 功能 | 示例 |
|---|---|---|
--verbose |
显示详细日志 | ollama run llama3 --verbose |
--nowordwrap |
禁用自动换行 | ollama run llama3 --nowordwrap |
三、模型管理
1. 自定义模型配置(Modelfile)
创建 Modelfile 文件:
FROM llama3 # 基础模型
PARAMETER temperature 0.7 # 控制随机性(0-1)
PARAMETER num_ctx 4096 # 上下文长度
SYSTEM """ 你是一个严谨的学术助手,回答需引用论文来源。""" # 系统提示词构建自定义模型:
ollama create my-llama3 -f Modelfile
ollama run my-llama32. 查看模型信息
ollama show <模型名> --modelfile # 查看模型配置
ollama show <模型名> --parameters # 查看运行参数四、高级功能
1. API 调用
启动 API 服务
ollama serve通过 HTTP 调用
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "你好",
"stream": false
}'2. GPU 加速配置
# 指定显存分配比例(50%)
ollama run llama3 --num-gpu 502.3 API调用大模型接口
目前大多数大模型都遵循OpenAI的接口规范,是给予http协议的接口,具体规范可查看相关大模型官方API文档。
大模型接口规范:
这是DeepSeek官方文档给出的调用示例:
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
# 1.初始化OpenAI客⼾端,要指定两个参数:api_key、base_url
client = OpenAI(api_key="<DeepSeek API Key>",
base_url="https://api.deepseek.com")
# 2.发送http请求到⼤模型,参数⽐较多
response = client.chat.completions.create(
model="deepseek-chat", # 2.1.选择要访问的模型
messages=[ # 2.2.发送给⼤模型的消息
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False # 2.3.是否以流式返回结果
)
print(response.choices[0].message.content)接口说明:
请求路径:与平台有关
安全校验:开放平台提供API_KEY校验权限,Ollama不需要
请求参数:
model(访问模型名称)
message(发送给大模型的消息,是一个数组)
stream(true代表响应结果流式返回,false代表响应结果一次性返回,但需要等待)
temperature(取值范围[0,2),代表大模型生成结果的随机性,值越小随机性越低,deepseek-r1不支持此参数)
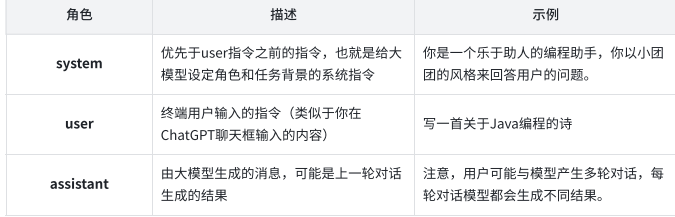
message数组中两个属性:role和content,通常,role有三种:
3.大模型应用
大模型应用是基于大模型的推理,分析,生成能力,结合传统编程能力,开发出的各种应用。
大模型是基于数据驱动的概率推理,擅长处理模糊性和不确定性,如自然语言处理(文本翻译),非结构化数据处理(医学影像诊断),创造性内容生成(生成图片),复杂模式预测(股票预测)等,而上述内容正式我们传统应用所不擅长处理的部分,因此,可以将传统编程和大模型整合起来,开发智能化的大模型应用。
大模型本身只是具备生成文本的能力,基本推理能力,我们平时使用的ChatGPT等对话产品除了生成和推理外,还有会话记忆,联网等功能,这些是大模型本身所不具备的,是需要额外程序去完成的,也就是基于大模型的应用。
常见的一些大模型产品及其模型关系:
| 大模型 | 对话产品 | 公司 | 地址 |
|---|---|---|---|
| GPT-3.5、GPT-4o | ChatGPT | OpenAI | https://chatgpt.com/ |
| Claude 4.0 | Claude AI | Anthropic | App unavailable \ Anthropic |
| DeepSeek-R1 | DeepSeek | 深度求索 | DeepSeek | 深度求索 |
| 文心大模型 3.5 | 文心一言 | 百度 | 文心一言 |
| 星火 3.5 | 讯飞星火 | 科大讯飞 | 讯飞星火-懂我的AI助手 |
| Qwen-Max | 通义千问 | 阿里巴巴 | 通义 - 你的实用AI助手 |
| Moonshoot | Kimi | 月之暗面 | Kimi - 会推理解析,能深度思考的AI助手 |
| Yi-Large | 零一万物 | 零一万物 | 零一万物-大模型开放平台 |
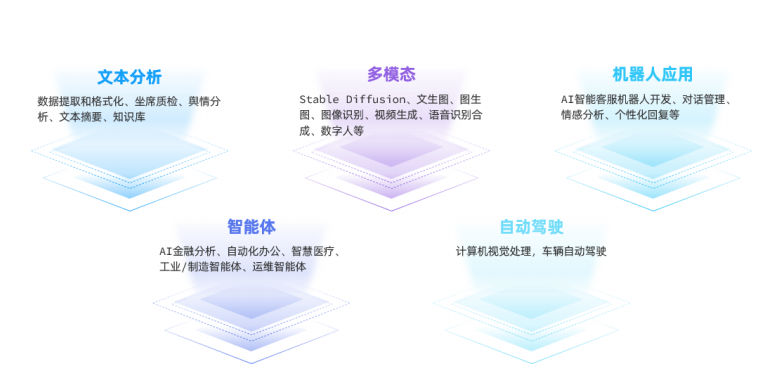
大模型应用的常见领域:
4. 大模型应用开发技术架构
4.1 技术架构
目前,大模型应用开发的技术架构主要有四种:
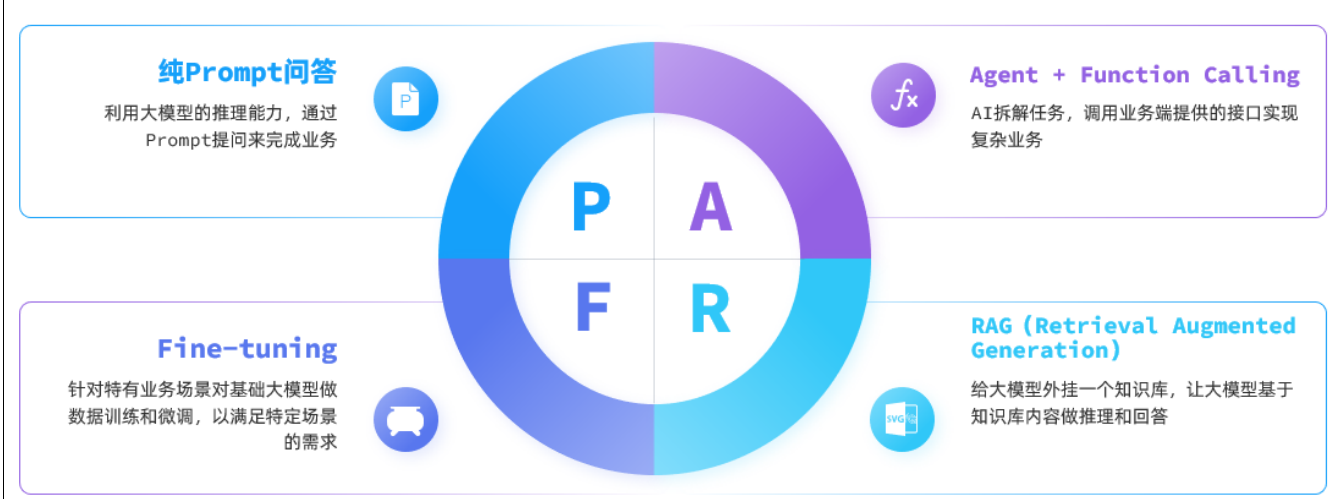
纯Prompt模式:
不断雕琢提示词,使得大模型能给出最理想的答案,这个过程叫做提示词工程,很多简单的AI应用仅靠一段足够好的提示词就能实现。
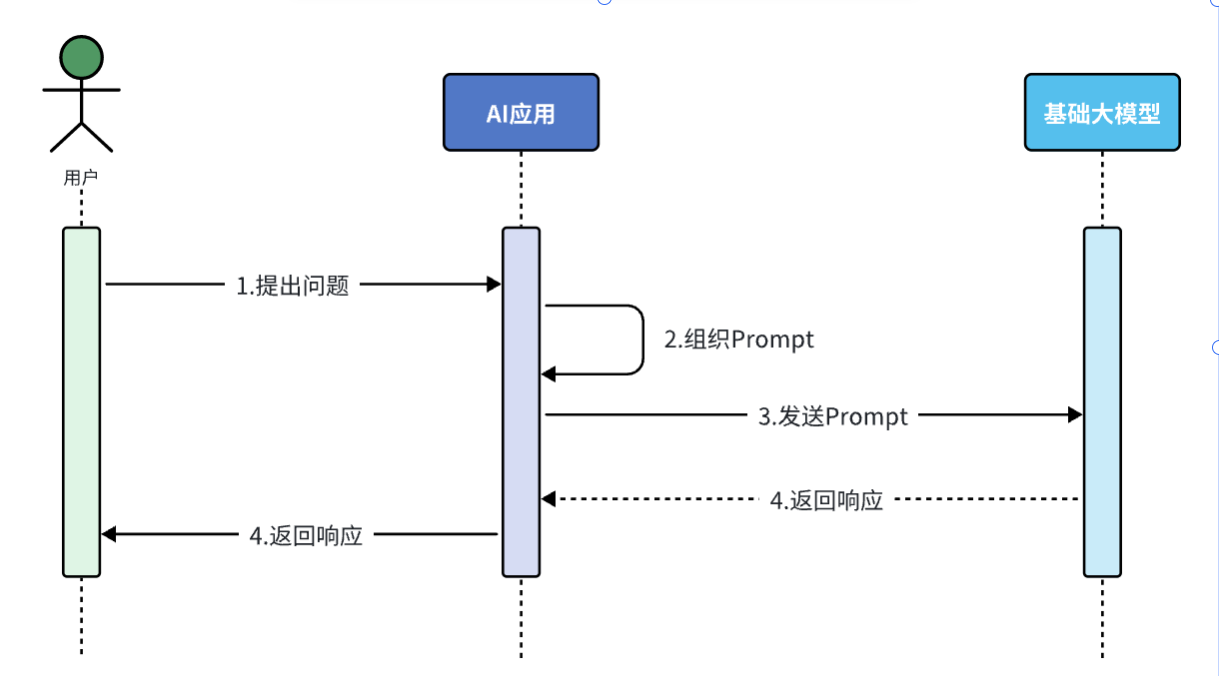
FunctionCalling:
赋予大模型执行业务规则的逻辑,分为以下几个步骤:
1.把传统应用中的功能逻辑封装为一个个函数(Function)
2.在提示词中描述用户需求,并说明每个函数的作用,使得大模型理解用户需求,能根据提示词判断什么时候需要调用哪些函数,并且将任务拆分为多个步骤。
3.当大模型执行到某一步,需要调用某个函数时,会返回要调用的函数名称,函数所需要的参数信息。
4.传统应用接收到这些数据以后,就可以调用本地函数,再把函数执行结果封装为提示词,再次发送给大模型继续与大模型进行交互。
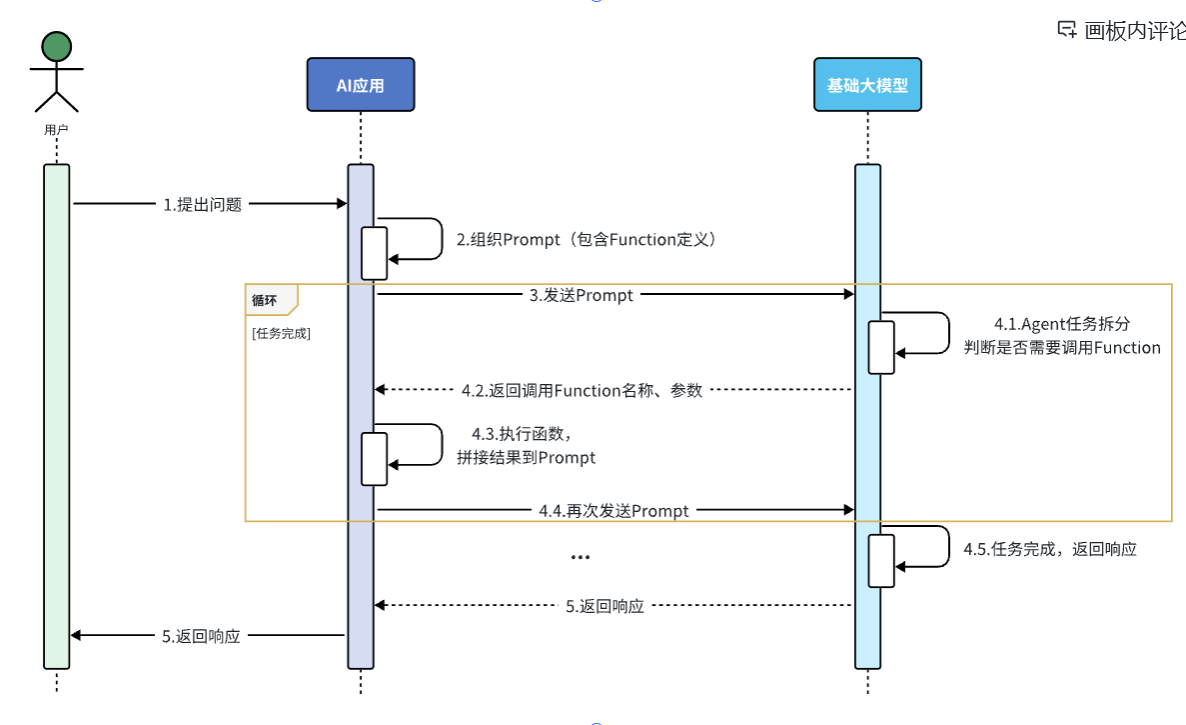
并不是所有大模型都支持Function Calling,比如DeepSeek-R1模型就不支持。
RAG:
RAG叫做检索增强生成,就是把信息检索技术和大模型结合的方案。
大模型从知识角度存在一些限制:
时效性差:大模型训练耗时,且训练数据无法保证实时更新。
缺少专业领域知识,大模型训练都是采集通用数据,缺少专业领域数据
RAG利用信息检索技术来扩展大模型的知识库,解决大模型的知识限制,RAG分为两个模块:
检索模块:负责存储和检索扩展的数据库
文本拆分:将文本按某种规则拆分成很多片段
文本嵌入(Embedding):根据文本片段中的内容,将文本片段归类存储
文本检索:根据用于提问的问题,找出最相关的文本片段
生成模块:
组合提示词:将检索到的片段与用于提问组成提示词,形成更丰富的上下文信息
生成结果:调用生成式大模型,根据提示词,生成更准确的回答
由于每次都是从向量库中找出与用户问题相关的数据,而不是整个知识库,所以上下文就不会超出大模型的tokens数量限制,同时又保证大模型回答问题基于知识库中的内容。
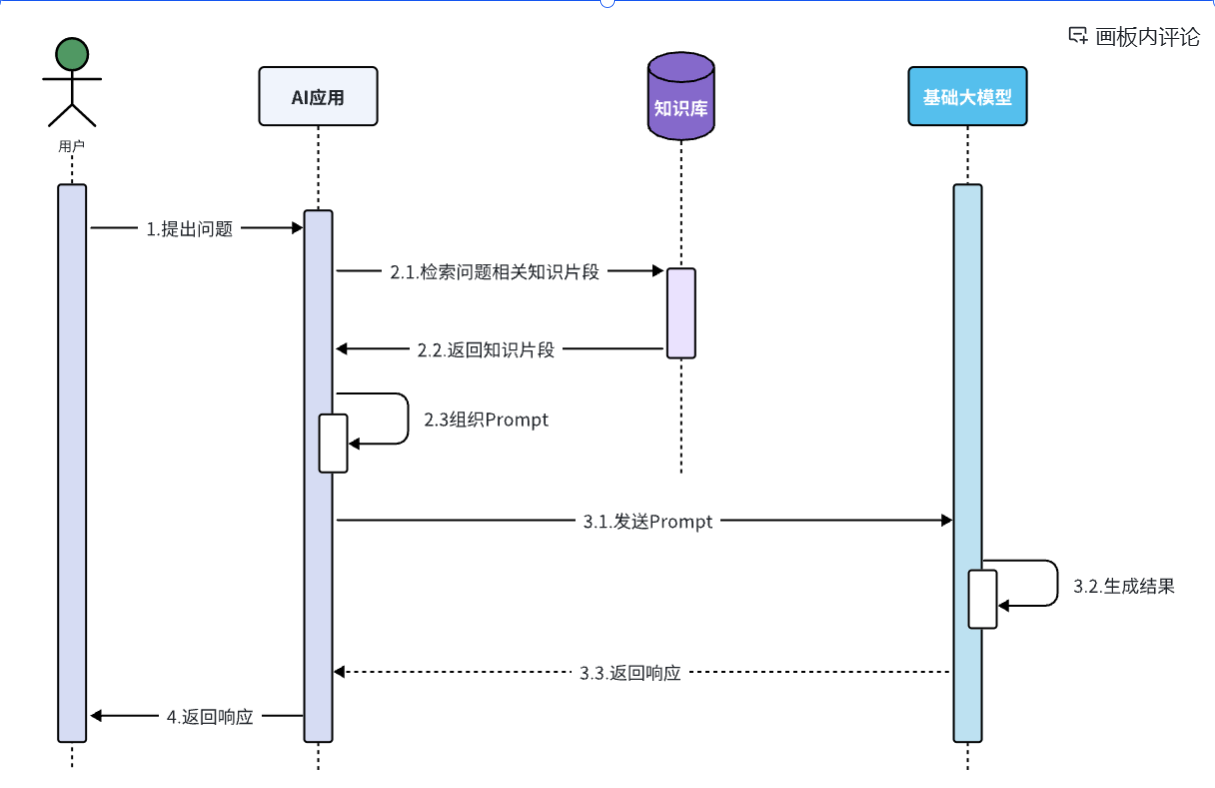
Fine-tuning:
模型微调,就是在预训练大模型的基础上,通过企业自己的数据做进一步训练,使得大模型的回答更符合企业的业务需求,这个过程通常要在参数上进行细微的修改,以达到最佳的性能表现。
在进行微调时,通常会保留模型的大部分结构和参数,只对其中的一小部分进行调整,这样做的好处是利用预训练大模型已经学到的知识,同时减少训练时间和资源的消耗,微调的过程分为以下几个关键步骤:
选择合适的预训练模型:根据任务的需求,选择一个已经在大量数据上进行过预训练的模型
准备特定领域的数据集:收集和准备与任务相关的数据集,这些数据将用于微调模型
设置超参数:调整学习率,批次大小,训练轮次等超参数,以确保模型能够有效学习新任务特征
训练和优化:使用特定任务的数据对模型进行训练,通过前向传播、损失计算、反向传播和权重更新等步骤,不断优化模型的性能。
模型微调虽然更加灵活、强大,但是也存在一些问题:
-
需要大量的计算资源
-
调参复杂性高
-
过拟合风险
Fine-tuning成本较高,难度较大,并不适合大多数企业。而且前面三种技术方案已经能够解决常见问题了。
4.2 技术选型:
从开发成本由低到高来看,四种方案排序如下:
Prompt < Function Calling < RAG < Fine-tuning
所以我们在选择技术时通常也应该遵循"在达成目标效果的前提,尽量降低开发成本"这一首要原则。然后可以参考以下流程来思考: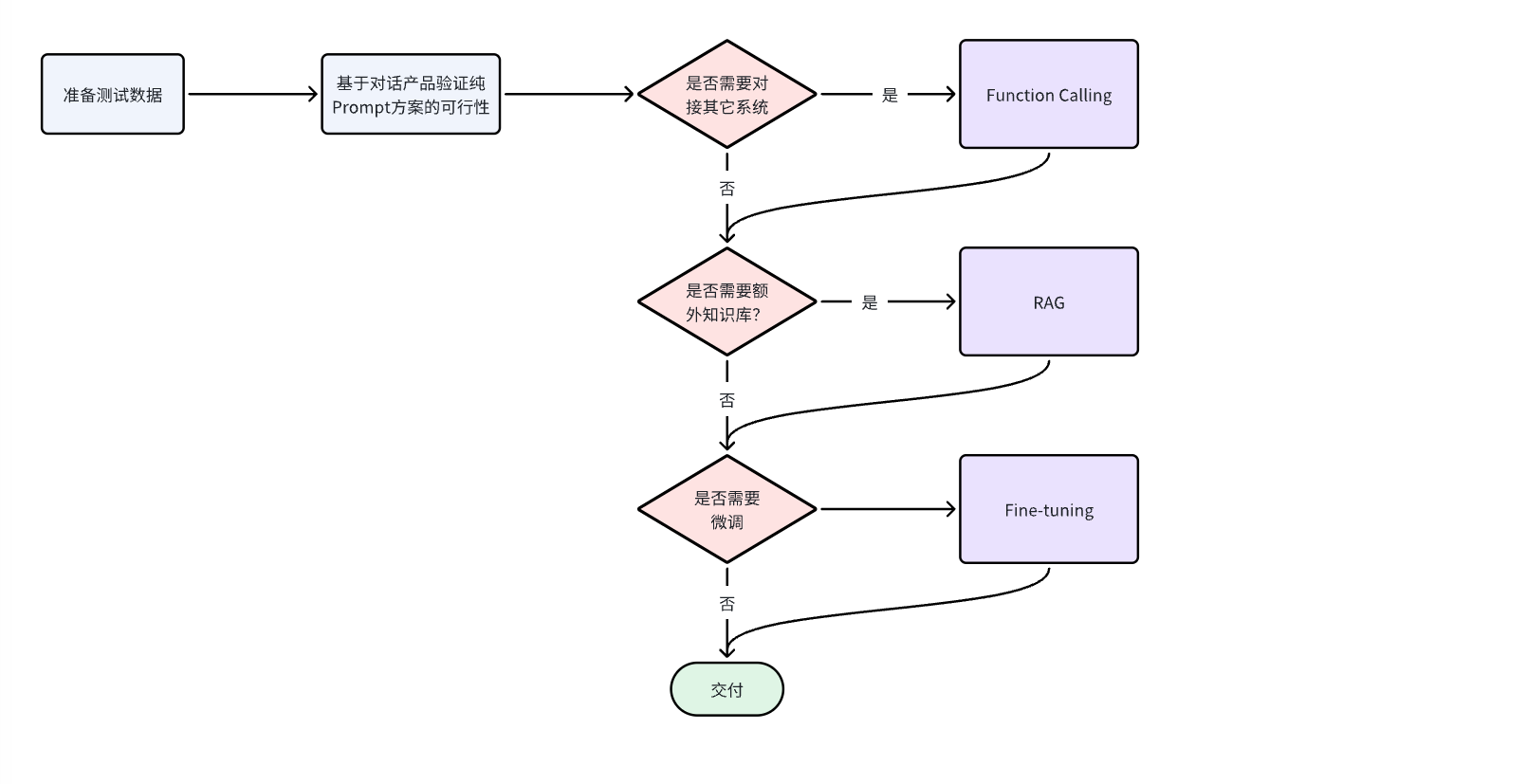

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)