AI 代码赋能历史短视频:人物独白全流程制作指南
本文聚焦 AI 技术在历史人物独白短视频制作中的应用,围绕 “前期素材梳理 - AI 工具实操 - 剪辑节奏把控 - 爆款优化” 四大模块,结合具体历史人物案例,详细讲解如何用 AI 工具完成从画面生成、声音克隆到视频合成的全流程制作。文中不涉及具体工具版本号,仅聚焦功能应用与实操技巧,适合短视频创作者、历史内容爱好者及想降低视频制作门槛的从业者阅读,掌握后可快速上手制作出符合平台传播规律的历史人

在短视频内容同质化严重的当下,历史类题材往往因呈现形式枯燥、制作门槛高,难以突破流量瓶颈。不少创作者想通过历史人物故事吸引观众,却受困于 “不会画历史场景”“配不出贴合人物的声音”“剪辑节奏抓不住重点” 等问题,最终产出的内容要么缺乏代入感,要么沦为 “知识灌输” 式的流水账,难以打动用户。而 AI 工具的出现,恰好为解决这些痛点提供了新思路 —— 无需专业绘画、配音和剪辑功底,也能制作出兼具历史厚重感与传播力的人物独白短视频。本文将以 “孝庄文皇后辅佐顺治” 的历史场景为例,拆解从 AI 生图、配音到剪辑的全流程,教你打造出有温度、有流量的历史类短视频。
一、前期准备:锚定历史人物,明确创作核心
制作历史人物独白视频,核心是让 “人物立得住、故事有共鸣”,前期准备需围绕 “素材梳理” 和 “工具选型” 两大方向展开。
首先是历史人物素材梳理。选择历史人物时,既要明确其核心身份与关键事件,更要抓住能引发情感共鸣的 “细节锚点”。以 “孝庄文皇后辅佐顺治” 为例,需先厘清人物核心信息:作为辅佐顺治帝稳固大清根基的关键人物,30 岁左右时面临幼子初登帝位、朝局动荡的局面,其独白需传递出 “沉稳中带着坚韧” 的情感基调。据此梳理出关键素材:身份定位为 “大清太后,顺治帝生母”,核心事件是 “以幼子之名稳定朝局,奠定清朝统治根基”,情感锚点则是 “30 岁女性在权力与母职中的担当”—— 这些信息将直接决定后续 AI 生图、配音的风格走向,避免内容偏离历史内核。

其次是 AI 工具选型。无需追求 “大而全” 的工具,只需根据需求匹配核心功能:生图工具需支持 “历史场景与服饰精准还原”,能通过文字描述生成符合朝代特征的服饰、妆容及场景画面;配音工具需具备 “声音克隆” 功能,可模仿贴合人物身份的音色(如孝庄需 “庄重且温和” 的中年女性嗓音),同时支持语速、语调调节;剪辑工具则需满足 “多轨道编辑” 需求,能同步处理画面、配音、背景音乐及字幕,操作门槛不宜过高,适合非专业用户快速上手。
二、AI 生图:让历史人物 “可视化”
生图是视频的 “门面”,需兼顾历史真实性与视觉吸引力,关键在于 “精准的提示词” 和 “合理的参数调整”。

提示词撰写要避免笼统表述,需拆解人物身份、服饰、场景、神态等细节。以孝庄文皇后的核心画面为例,提示词可这样设计:“清代孝庄文皇后,30 岁左右,身着顺治时期皇后朝服(石青色缎地,绣五爪金龙,缀东珠配饰),立于紫禁城太和殿偏殿,手持奏折,神态沉稳,眼神中带着忧虑与坚定,背景为清代宫殿内景,光线柔和,画面风格贴合历史纪录片质感,避免现代元素”。这样的提示词既明确了人物的时代特征,又限定了神态与场景,能让 AI 生成的画面更贴合 “辅佐幼帝、稳固朝局” 的核心设定。
参数调整则需兼顾 “清晰度” 与 “视频适配性”。分辨率建议设置为 1080P 及以上,保证画面在手机端观看时不失真;风格强度需根据需求调节,若想突出 “纪录片感”,可适当降低风格化参数,避免画面过于卡通;同时注意画面比例,短视频平台多为 9:16 竖屏,生图时需提前设置对应比例,减少后期裁剪导致的画面缺失。生成后若存在细节偏差(如服饰纹样错误),可在提示词中补充 “严格还原清代顺治朝皇后朝服纹样” 等具体要求,重新生成直至符合预期。
三、配音与声音处理:赋予人物 “专属嗓音”
声音是人物情感的 “传递者”,历史人物独白的配音需做到 “音色贴合身份,情感匹配场景”,核心在于 “声音克隆” 与 “细节调优”。
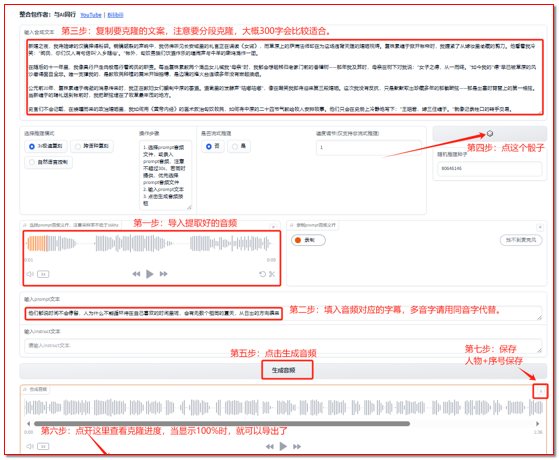
第一步是参考音采集。若想让配音更具独特性,可先采集一段贴合人物音色的参考音(如选取影视剧中沉稳大气的中年女性配音片段),时长控制在 30 秒左右,保证发音清晰、无背景噪音。将参考音导入具备声音克隆功能的 AI 工具,工具会分析音色、语调、语速等特征,生成专属 “声音模型”—— 这里需注意,参考音需符合历史人物的身份定位,避免用过于年轻化或音色夸张的声音,比如孝庄的配音应避开 “甜美”“尖锐” 的音色,以 “庄重、温和且略带威严” 为主。
第二步是配音生成与优化。将撰写好的独白文案导入工具,选择已生成的 “声音模型”,同时根据文案情感调整参数:对于 “三十岁,我抱着幼子,稳住了大清的根基” 这类承载厚重情感的台词,将语速调至稍缓(约 120-130 字 / 分钟),语调设置为 “前半段低沉,后半段略微上扬”,突出人物的坚定;对于叙述朝局动荡的内容,可适当提高语调起伏,增强画面代入感。生成配音后,需用音频处理工具去除背景杂音,将音量统一调整至 - 6dB 至 - 3dB 之间,确保后续与背景音乐搭配时,人声清晰不模糊。
四、剪辑与爆款优化:让内容 “有节奏、有记忆点”
剪辑是将素材 “串联成故事” 的关键,需兼顾逻辑流畅性与平台传播规律,同时通过细节优化提升爆款潜力。

剪辑逻辑需围绕 “情感递进” 展开。以孝庄独白视频为例,可按 “场景铺垫 - 情感爆发 - 主题升华” 的节奏设计:开头用 1-2 秒的宫殿空镜 + 低沉背景音乐铺垫氛围;接着切入孝庄手持奏折的画面,配合 “三十岁,我抱着幼子,稳住了大清的根基” 的台词,用特写镜头聚焦人物神态;中间部分按 “朝局危机 - 应对举措 - 根基稳固” 的顺序,切换对应的历史场景画面(如朝堂议事、深夜批阅奏折等),每段画面时长控制在 3-5 秒,避免用户视觉疲劳;结尾用人物远眺宫殿的远景镜头,搭配 “守业更比创业难” 的台词,引发观众共鸣。剪辑时需注意转场自然,优先选择 “淡入淡出”“划像” 等贴合历史氛围的转场效果,避免使用过于花哨的特效破坏整体质感。

字幕与背景音乐的搭配也需细节把控。字幕需提炼核心台词,字体选择 “宋体”“楷体” 等具有传统韵味的样式,字号以手机端清晰可见为宜(建议 24-28 号字),颜色用白色搭配黑色描边,确保在不同画面背景下都能清晰识别。背景音乐需选择贴合历史题材的纯音乐(如古筝、二胡伴奏的曲目),音量控制在人声的 1/3 左右,在情感爆发的台词处(如 “稳住了大清的根基”)适当降低音量,突出人声;在空镜或转场段落可略微提高音量,增强氛围。
最后是爆款优化的三个核心技巧。其一,内容差异化:避开大众熟知的历史人物(如康熙、乾隆),选择有故事性但曝光度低的人物(如孝庄、长孙皇后),挖掘其 “非权力层面” 的故事(如母职、情感),让内容更具新鲜感;其二,细节真实性:制作前查阅历史资料,确保服饰、场景、称谓符合对应朝代(如顺治时期皇后朝服的纹样、清代宫殿的布局),避免出现 “穿越” 错误,增强用户信任感;其三,平台适配性:针对抖音等平台的推荐机制,优化开头 3 秒(如用 “30 岁女性如何掌控一个王朝?” 的悬念式台词 + 人物特写画面),结尾引导互动(如 “你还知道哪些被低估的历史女性?评论区留言”),提升视频的完播率与互动率。
import os
import json
from datetime import datetime
from moviepy.editor import ImageSequenceClip, AudioFileClip, CompositeAudioClip
import pyttsx3 # 本地文本转语音库,无需联网
# --------------------------
# 1. 历史人物素材管理模块
# 功能:存储/读取历史人物核心信息(对应文章“前期准备-素材梳理”)
# --------------------------
class HistoricalFigureManager:
def __init__(self, data_path="historical_figures.json"):
self.data_path = data_path
# 初始化素材文件(若不存在则创建)
if not os.path.exists(self.data_path):
with open(self.data_path, "w", encoding="utf-8") as f:
json.dump({}, f, ensure_ascii=False, indent=2)
def save_figure_data(self, figure_name, data):
"""
保存历史人物信息
:param figure_name: 人物名称(如“孝庄文皇后”)
:param data: 人物核心数据(字典格式,含身份、事件、情感锚点等)
"""
with open(self.data_path, "r", encoding="utf-8") as f:
all_data = json.load(f)
# 按文章要求,数据需包含:身份定位、核心事件、情感锚点、时代特征
all_data[figure_name] = {
"identity": data.get("identity", ""), # 身份定位
"key_events": data.get("key_events", []), # 核心事件
"emotion_anchor": data.get("emotion_anchor", ""), # 情感锚点
"era_features": data.get("era_features", ""), # 时代特征(服饰、场景等)
"update_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
with open(self.data_path, "w", encoding="utf-8") as f:
json.dump(all_data, f, ensure_ascii=False, indent=2)
print(f"✅ 已保存「{figure_name}」素材数据")
def get_figure_data(self, figure_name):
"""读取历史人物信息"""
with open(self.data_path, "r", encoding="utf-8") as f:
all_data = json.load(f)
return all_data.get(figure_name, None)
# --------------------------
# 2. AI生图提示词生成模块
# 功能:根据人物素材自动生成精准生图提示词(对应文章“AI生图-提示词撰写”)
# --------------------------
def generate_image_prompt(figure_data, scene_desc):
"""
生成AI生图提示词
:param figure_data: 人物素材数据(从HistoricalFigureManager获取)
:param scene_desc: 具体场景描述(如“立于紫禁城太和殿偏殿,手持奏折”)
:return: 结构化提示词字符串
"""
if not figure_data:
return "错误:未获取到人物素材数据"
# 按文章要求拆解提示词要素:人物信息+服饰+场景+神态+风格
prompt = (
f"清代历史人物:{figure_data['identity']},{figure_data['emotion_anchor']},"
f"服饰符合{figure_data['era_features']}(严格还原对应朝代纹样与配色),"
f"场景:{scene_desc},"
f"神态:沉稳且贴合历史人物气质,避免现代元素,"
f"画面风格:历史纪录片质感,光线柔和,分辨率1080P以上,竖屏9:16比例"
)
return prompt
# --------------------------
# 3. 本地配音生成模块
# 功能:将独白文本转为语音(对应文章“配音与声音处理”)
# --------------------------
def generate_voiceover(text, output_path="voiceover.mp3", rate=125, volume=1.0):
"""
本地生成配音(无需调用云API)
:param text: 独白文本内容
:param output_path: 输出音频路径
:param rate: 语速(默认125字/分钟,对应文章“120-130字/分钟”建议)
:param volume: 音量(0.0-1.0)
"""
# 初始化语音引擎
engine = pyttsx3.init()
# 调整参数(贴合文章“配音优化”要求)
engine.setProperty('rate', rate) # 语速
engine.setProperty('volume', volume) # 音量
# 保存音频
engine.save_to_file(text, output_path)
engine.runAndWait()
print(f"✅ 已生成配音文件:{output_path}")
# --------------------------
# 4. 视频合成预处理模块
# 功能:将生图、配音、背景音乐合成短视频(对应文章“剪辑与优化”)
# --------------------------
def compose_short_video(image_folder, voiceover_path, bgm_path, output_path="output.mp4", duration_per_image=4):
"""
合成历史短视频
:param image_folder: 生图文件夹(需按播放顺序命名图片,如01.jpg、02.jpg)
:param voiceover_path: 配音文件路径
:param bgm_path: 背景音乐路径
:param output_path: 输出视频路径
:param duration_per_image: 每张图片显示时长(默认4秒,避免用户视觉疲劳)
"""
# 1. 读取生图并按顺序排序
image_files = sorted([f for f in os.listdir(image_folder) if f.endswith(('.jpg', '.png'))])
image_paths = [os.path.join(image_folder, f) for f in image_files]
if not image_paths:
print("❌ 未找到图片文件")
return
# 2. 创建图片序列剪辑(竖屏9:16比例)
clip = ImageSequenceClip(image_paths, durations=[duration_per_image]*len(image_paths))
clip = clip.resize((1080, 1920)) # 适配手机端竖屏
# 3. 处理音频(配音+背景音乐,贴合文章“音量搭配”要求)
voiceover_clip = AudioFileClip(voiceover_path)
bgm_clip = AudioFileClip(bgm_path).volumex(0.3) # 背景音乐音量为配音的30%
# 确保音频时长与视频匹配
audio_clip = CompositeAudioClip([voiceover_clip.set_duration(clip.duration),
bgm_clip.set_duration(clip.duration)])
# 4. 合成视频
final_clip = clip.set_audio(audio_clip)
final_clip.write_videofile(output_path, codec="libx264", audio_codec="aac")
print(f"✅ 已生成短视频:{output_path}")
# --------------------------
# 代码运行示例(按“孝庄文皇后”案例演示)
# --------------------------
if __name__ == "__main__":
# 1. 初始化素材管理器并保存人物数据
figure_manager = HistoricalFigureManager()
xiaozhuang_data = {
"identity": "大清太后,顺治帝生母",
"key_events": ["辅佐顺治帝稳固朝局", "奠定清朝统治根基"],
"emotion_anchor": "30岁女性在权力与母职中的沉稳与坚韧",
"era_features": "顺治时期皇后朝服(石青色缎地,绣五爪金龙,缀东珠配饰),紫禁城宫殿内景"
}
figure_manager.save_figure_data("孝庄文皇后", xiaozhuang_data)
# 2. 生成AI生图提示词
xiaozhuang_info = figure_manager.get_figure_data("孝庄文皇后")
image_prompt = generate_image_prompt(xiaozhuang_info, "立于紫禁城太和殿偏殿,手持奏折,眼神带忧虑与坚定")
print("\n📝 AI生图提示词:")
print(image_prompt)
# 3. 生成独白配音(示例文本)
monologue_text = "三十岁,我抱着年幼的顺治,站在紫禁城的宫墙下。朝局动荡,权臣环伺,可我知道,我不仅是母亲,更是大清的太后。每一份奏折,每一次决策,都是为了让这江山,能稳稳交到幼子手中。守业,从来比创业更难啊。"
generate_voiceover(monologue_text, output_path="xiaozhuang_voiceover.mp3", rate=120)
# 4. 合成短视频(需提前准备:1. image文件夹存放生图 2. bgm.mp3背景音乐文件)
# 注:实际使用时,需先通过AI工具生成图片并存入image文件夹
if os.path.exists("image") and os.path.exists("bgm.mp3"):
compose_short_video(
image_folder="image",
voiceover_path="xiaozhuang_voiceover.mp3",
bgm_path="bgm.mp3",
output_path="xiaozhuang_shortvideo.mp4"
)
else:
print("\n⚠️ 请先创建「image」文件夹并放入生图,同时准备「bgm.mp3」背景音乐文件")通过以上流程,无需专业的美术、配音和剪辑技能,只需借助 AI 工具将历史素材与技术手段结合,就能制作出兼具历史厚重感与传播力的人物独白短视频。核心在于 “以人物情感为核心,用 AI 工具做支撑”,让历史不再是冰冷的文字,而是能引发观众共鸣的 “鲜活故事”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)