Zabbix 企业级监控系统实战指南(基础篇):从搭建、可视化到智能告警
🔔 本文是《Zabbix 企业级监控系统实战指南:从搭建、可视化到智能告警》系列的第一篇
本系列旨在手把手带领您从零开始,构建一套功能完备的企业级监控系统。
⚠️ 该系列所有涉及的软件包和项目都可以私信博主免费获取
-
第一篇:Zabbix 基础篇 —— 部署与核心概念实战,构建监控基石
核心:完成 Zabbix 服务端、客户端的部署与基础监控,并配置邮件告警。
-
第二篇:Zabbix 可视化篇 —— Zabbix 集成 Grafana,打造高颜值监控仪表盘
核心:解决 Zabbix 自带图表不够美观的问题,利用 Grafana 实现灵活、强大的数据可视化。
-
第三篇:Zabbix 告警篇 —— Zabbix 集成睿象云,实现多通道智能告警通知
核心:解决邮件告警可能被遗漏的问题,通过睿象云平台实现微信、短信、电话等多渠道告警推送与聚合管理。
🚀 系列目标:学完本系列,您将掌握 Zabbix + Grafana + 睿象云 CA 这一黄金组合,真正实现 “监控-展示-告警” 的全流程自动化。
一:入门
1)概述
Zabbix 是一个 开源企业级监控解决方案,用于监控 IT 基础设施(服务器、网络设备、虚拟化环境、应用、中间件等)的可用性和性能。它提供 数据采集、存储、可视化、告警 等全流程功能。
2)基础架构
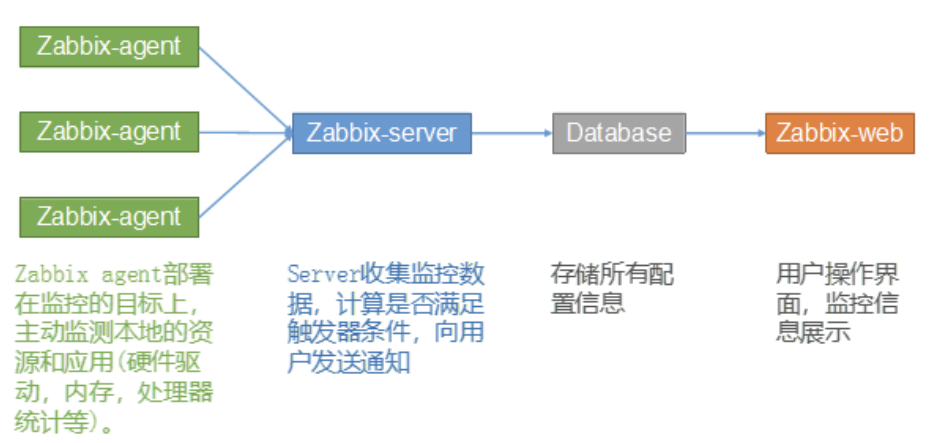
-
Zabbix Agent:安装在被监控主机上,收集系统和应用数据。
-
Zabbix Server:核心服务,负责接收数据、处理数据、生成告警。
-
Database:存储监控数据(如 MySQL、PostgreSQL 等)。
-
Zabbix Web:基于 PHP 的管理和展示平台,提供配置、报表、图形。
3)Zabbix VS Prometheus
| Zabbix | Prometheus | |
|---|---|---|
| 发行时间 | 2012 | 2016 |
| 开发语言 | C + PHP | Go |
| 性能 | 上限约 1 万节点;大规模需 Proxy 分布式扩展;对数据库依赖较重 | 单机高性能,支持百万级指标;扩展需 Thanos/VM 等方案 |
| 社区支持 | 历史悠久,文档和案例丰富;问题容易在社区找到答案 | 社区活跃,尤其在云原生和 Kubernetes 生态增长迅速 |
| 容器支持 | 出现较早,对容器支持不佳,但新版本逐步改善 | 原生支持 Kubernetes、Docker Swarm 等,是容器监控标准 |
| 企业使用 | 传统 IT 运维、服务器、网络设备、数据库、中间件监控为主 | 广泛用于互联网公司、云原生场景,尤其 Kubernetes 企业 |
| 部署难度 | 部署复杂(需 Server + DB + Web 前端),维护成本高 | 部署轻量,单一 Server 即可启动;但生产需 Alertmanager、Grafana、Thanos 等配合 |
| 监控方式 | 支持 Agent、SNMP、IPMI、JMX、API、自定义脚本,多样化 | 基于 Exporter 拉取 HTTP /metrics,支持 Pushgateway 主动推送 |
| 数据存储 | 依赖外部数据库(MySQL/PostgreSQL/Oracle 等),大数据量需调优 | 内置 TSDB,默认 15 天,长期存储需外部方案 |
| 可视化展示 | 内置 Web 界面,功能完整(拓扑、报表、仪表盘),但风格传统 | 自带简单 UI,调试用;常与 Grafana 搭配实现复杂可视化 |
| 告警机制 | 内置告警引擎,支持邮件、短信、Webhook、脚本 | 依赖 Alertmanager,支持分组、静默、路由、多渠道通知 |
| 适用场景 | 传统数据中心、大型企业 IT 运维,一站式监控 | 云原生、容器、微服务监控,DevOps 场 |
二:部署
1)集群准备
-
基础环境
基本十一项 + SSH免密
机器 IP 角色 hadoop102 192.168.2.102 | 172.16.1.102 Zabbix Server + Zabbix Agent + MySQL + Zabbix Web hadoop103 192.168.2.103 | 172.16.1.103 Zabbix Agent hadoop104 192.168.2.104 | 172.16.1.104 Zabbix Agent -
Hadoop 搭建
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
-
安装
JDK该操作在三台机器上都要操作一遍
# 1. 卸载系统自带 JDK rpm -qa | grep -i jdk | grep -i java | xargs -n1 rpm -e --nodeps # 2. 上传 jdk-8u212-linux-x64.tar.gz 到 /opt/software rz # 3. 解压缩 tar -xzvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module # 4. 配置环境变量 vim /etc/profile #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin # 5. 加载环境变量 source /etc/profile -
安装
Hadoop该操作在三台机器上都要操作一遍
# 1. 上传 hadoop-3.1.3.tar.gz 到 /opt/software rz # 2. 解压缩 tar -xzvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module # 3. 配置环境变量 vim /etc/profile # HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath` export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 4. 加载环境变量 source /etc/profile -
集群配置
该操作在三台机器上都要操作一遍
# 1. 配置 core-site.xml 文件 vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml<configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为 root --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration># 2. 配置 hdfs-site.xml 文件 vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml<configuration> <!-- namenode web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- SecondaryNameNode web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> <!-- 指定 HDFS 副本的数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 关闭 HDFS 检查 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> </configuration># 3. 配置 yarn-site.xml 文件 vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml<configuration> <!-- 指定 MR 走 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 ResourceManager 的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration># 4. 配置 mapred-site.xml 文件 vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml<configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration># 4. 配置 workers 文件 vim /opt/module/hadoop-3.1.3/etc/hadoop/workershadoop102 hadoop103 hadoop104# 5. 配置 hadoop-env.sh 文件 vim /opt/module/hadoop-3.1.3/etc/hadoop/hadoop-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_212 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root# 6. 创建 logs 文件夹 mkdir /opt/module/hadoop-3.1.3/logs -
初始化
# 1. 在 NameNode 节点进行格式化 [root@hadoop102 hadoop-3.1.3]# ./bin/hdfs namenode -format
-
-
部署
MySQL只在 hadoop102 上部署
# 1. 删除系统相关软件包 [root@hadoop102 ~]# rpm -qa | grep -i mariadb-server | xargs rpm -e --nodeps # 2. 安装 Mariadb [root@hadoop102 ~]# yum install -y mariadb-server # 3. 启动 Mariadb [root@hadoop102 ~]# systemctl start mariadb.service [root@hadoop102 ~]# systemctl enable mariadb.service # 4. 数据库安全配置 [root@hadoop102 ~]# mysql_secure_installation Enter current password for root (enter for none): 回车 Set root password? \[Y/n\] y # 设置密码 New password: 123456 # 输入密码 Re-enter new password: 123456 # 再次输入密码 Remove anonymous users? \[Y/n\] y # 删除数据库中的匿名用户(没有用户名的用户,容易导致安全问题) Disallow root login remotely? \[Y/n\] y # 是否禁止 root 远程登录 Remove test database and access to it? \[Y/n\] y # 是否删除test测试用的数据库 Reload privilege tables now? \[Y/n\] y # 是否更新权限信息表
2)配置 Zabbix yum源
三台机器都要操作一遍
# 1. 安装 Zabbix 的软件仓库配置包
rpm -Uvh https://mirrors.aliyun.com/zabbix/zabbix/5.0/rhel/7/x86_64/zabbix-release-5.0-1.el7.noarch.rpm
# 2. 配置 SCLo 源
vim /etc/yum.repos.d/centos-sclo-scl.repo
[centos-sclo-rh]
name=CentOS-7 - SCLo rh
baseurl=https://mirrors.aliyun.com/centos-vault/7.9.2009/sclo/$basearch/rh/
enabled=1
gpgcheck=0
[centos-sclo-sclo]
name=CentOS-7 - SCLo sclo
baseurl=https://mirrors.aliyun.com/centos-vault/7.9.2009/sclo/$basearch/sclo/
enabled=1
gpgcheck=0
# 3. 更新缓存
yum clean all
yum makecache
3)修改 Zabbix 仓库配置文件
三台机器都要操作一遍
# 1. 修改为阿里云镜像
sed -i 's/http:\/\/repo.zabbix.com/https:\/\/mirrors.aliyun.com\/zabbix/g' /etc/yum.repos.d/zabbix.repo
# 2. 启用zabbix-web仓库
vim /etc/yum.repos.d/zabbix.repo
[zabbix-frontend]
enabled=1
4)安装 Zabbix
# hadoop102
yum install -y zabbix-server-mysql zabbix-agent zabbix-web-mysql-scl zabbix-apache-conf-scl
# hadoop103、hadoop104
yum install -y zabbix-agent
5)配置 Zabbix
-
Zabbix Server
-
创建
Zabbix存储数据库[root@hadoop102 ~]# mysql -u'root' -p'123456' -e 'create database zabbix character set utf8 collate utf8_bin' -
导入
Zabbix建表语句把 Zabbix 官方提供的数据库初始化脚本解压后,直接导入到 MySQL 的
zabbix数据库中。[root@hadoop102 ~]# zcat /usr/share/doc/zabbix-server-mysql-5.0.47/create.sql.gz | mysql -u'root' -p'123456' zabbix -
数据库用户授权
mysql -u'root' -p'123456' MariaDB [(none)]> GRANT ALL PRIVILEGES ON zabbix.* TO 'root'@'192.168.2.102' IDENTIFIED BY '123456'; MariaDB [(none)]> FLUSH PRIVILEGES; -
修改
zabbix_server.conf[root@hadoop102 ~]# vim /etc/zabbix/zabbix_server.confDBHost=192.168.2.102 DBName=zabbix DBUser=root DBPassword=123456 -
配置
Zabbix Web时区[root@hadoop102 ~]# vim /etc/opt/rh/rh-php72/php-fpm.d/zabbix.confphp_value[date.timezone] = Asia/Shanghai
-
-
Zabbix Agent
三台机器都要配置一遍
-
修改
zabbix-serve.confvim /etc/zabbix/zabbix_agentd.confServer=hadoop102 #ServerActive=127.0.0.1 #Hostname=Zabbix server
-
6)启动 Zabbix
# hadoop102
systemctl start zabbix-server zabbix-agent httpd rh-php72-php-fpm
systemctl enable zabbix-server zabbix-agent httpd rh-php72-php-fpm
# hadoop103、hadoop104
systemctl start zabbix-agent
systemctl enable zabbix-agent
7)连接 Zabbix Web 数据库
-
浏览器访问 http://192.168.2.102/zabbix/setup.php
-
检测配置

-
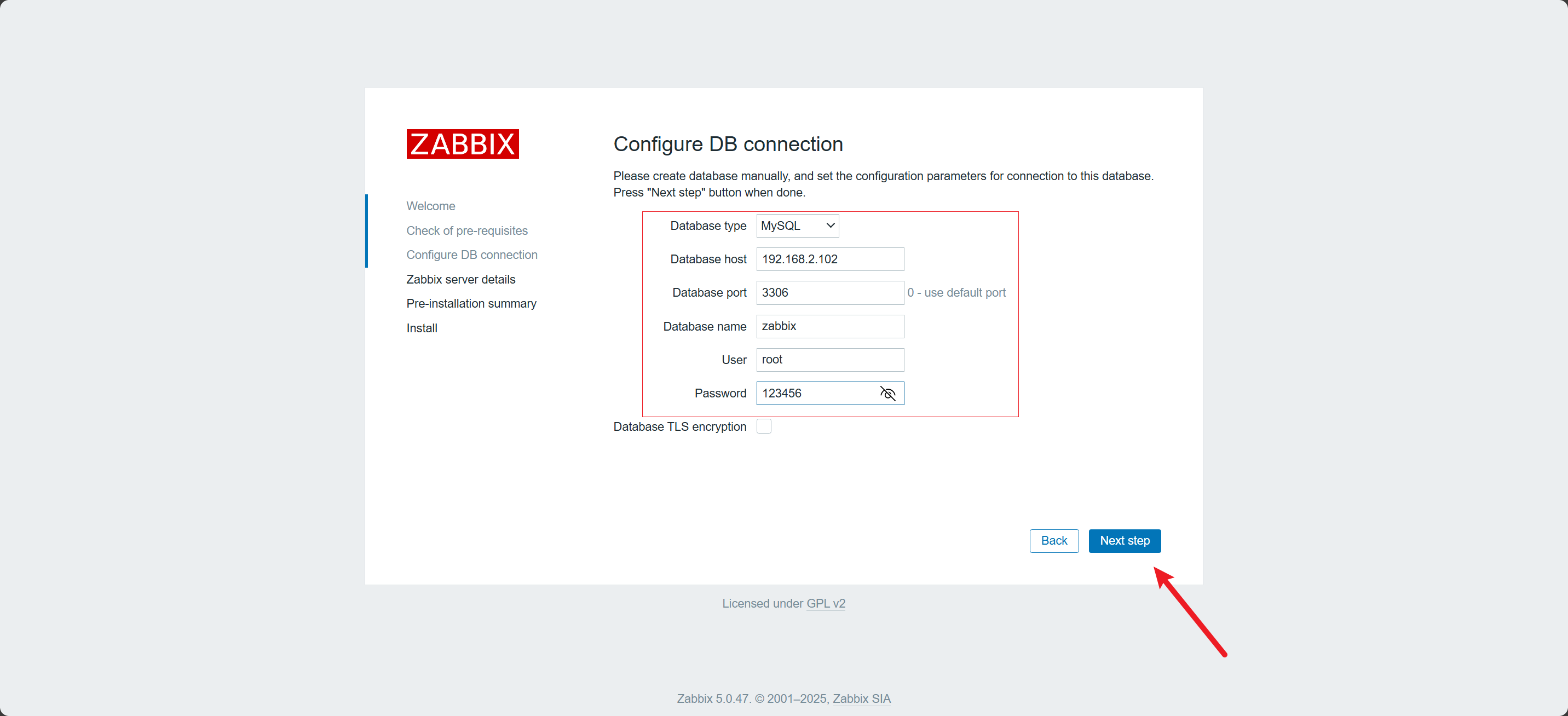
配置数据库
-
配置
Zabbix Server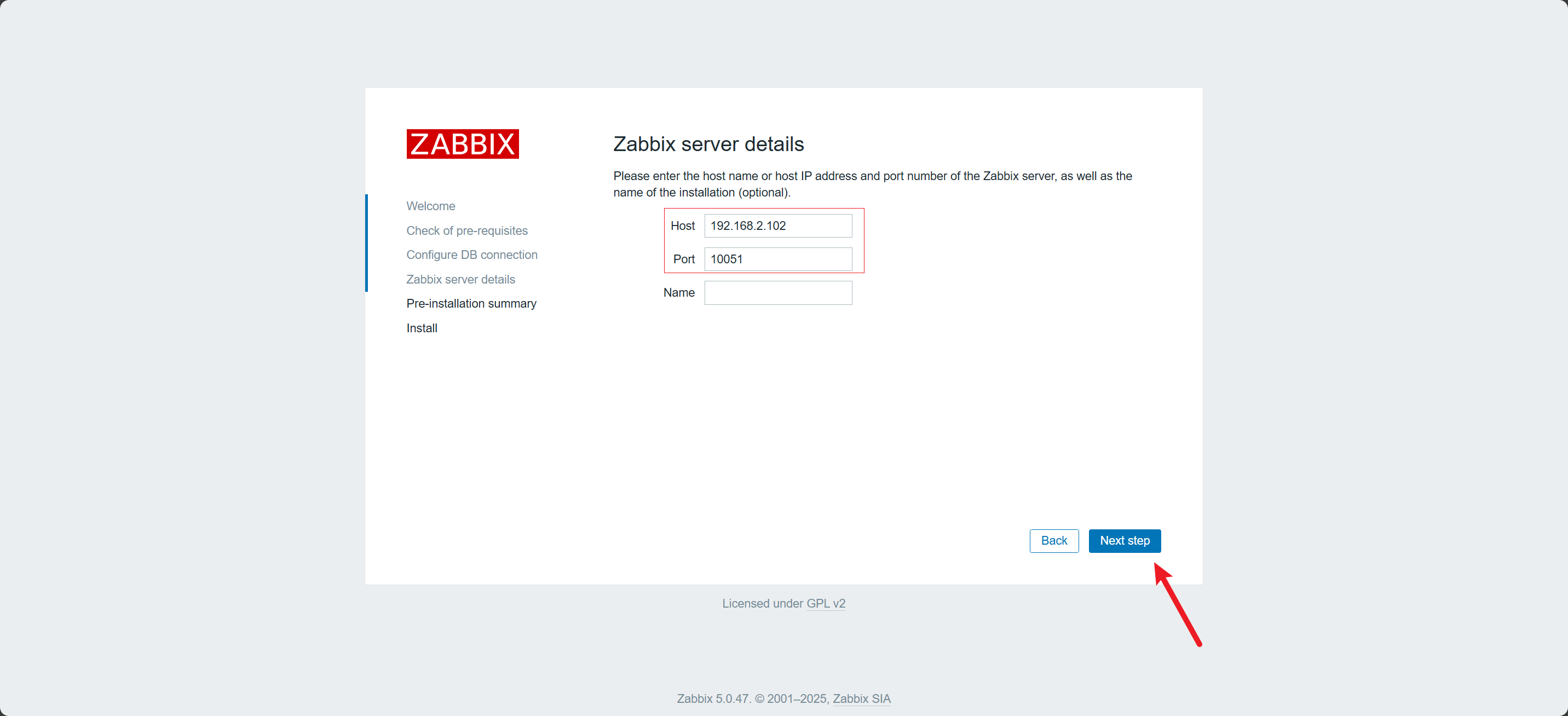
-
预览配置
-
完成
8)登录 Zabbix
-
登录
Username: Admin
Password: zabbix
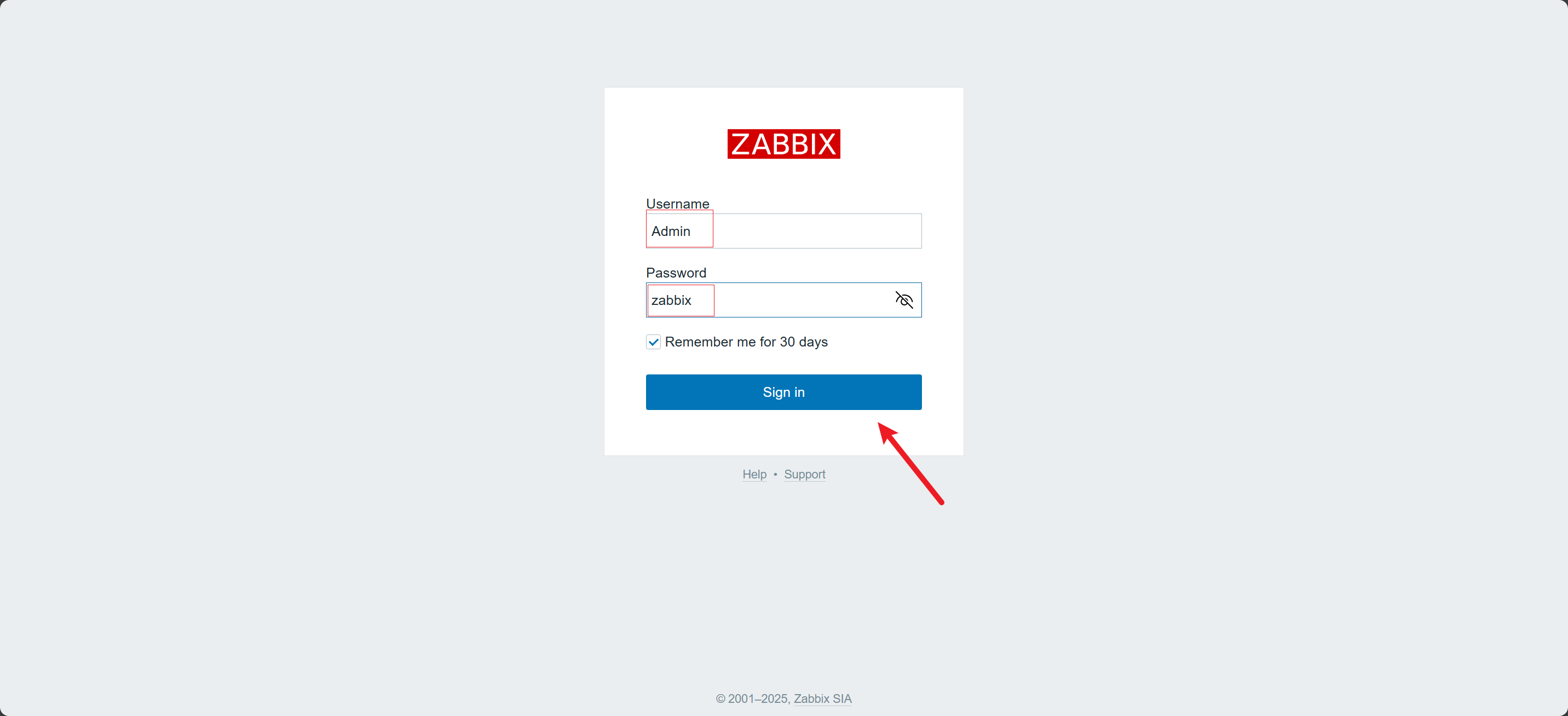
-
首页
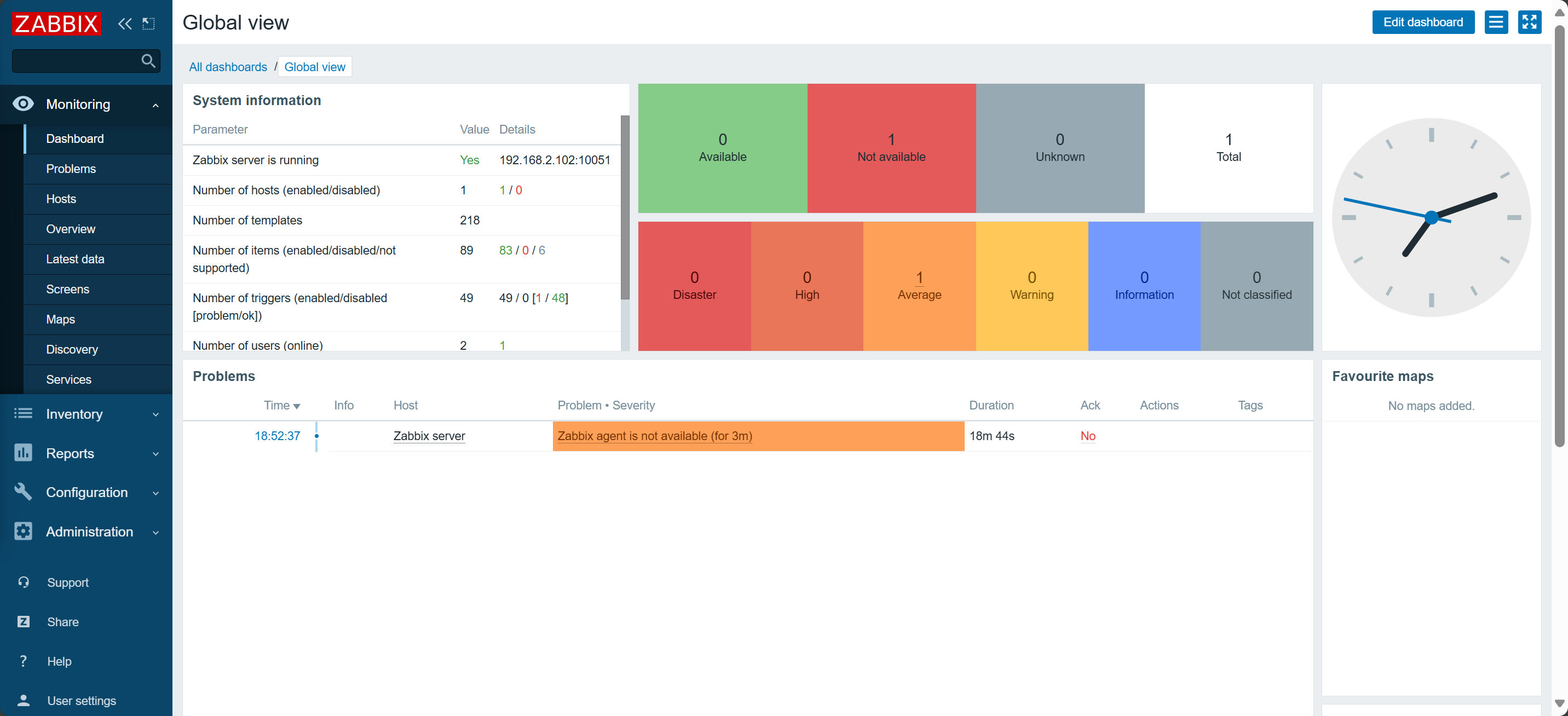
-
点击 User settings
-
修改 Language
-
查看
注意:这里默认会对Zabbix Server进行监控,但是我们可以看到目前该主机是红色,不可用的状态,原因是主机的地址不能使用
127.0.0.1需要后续我们单独配置。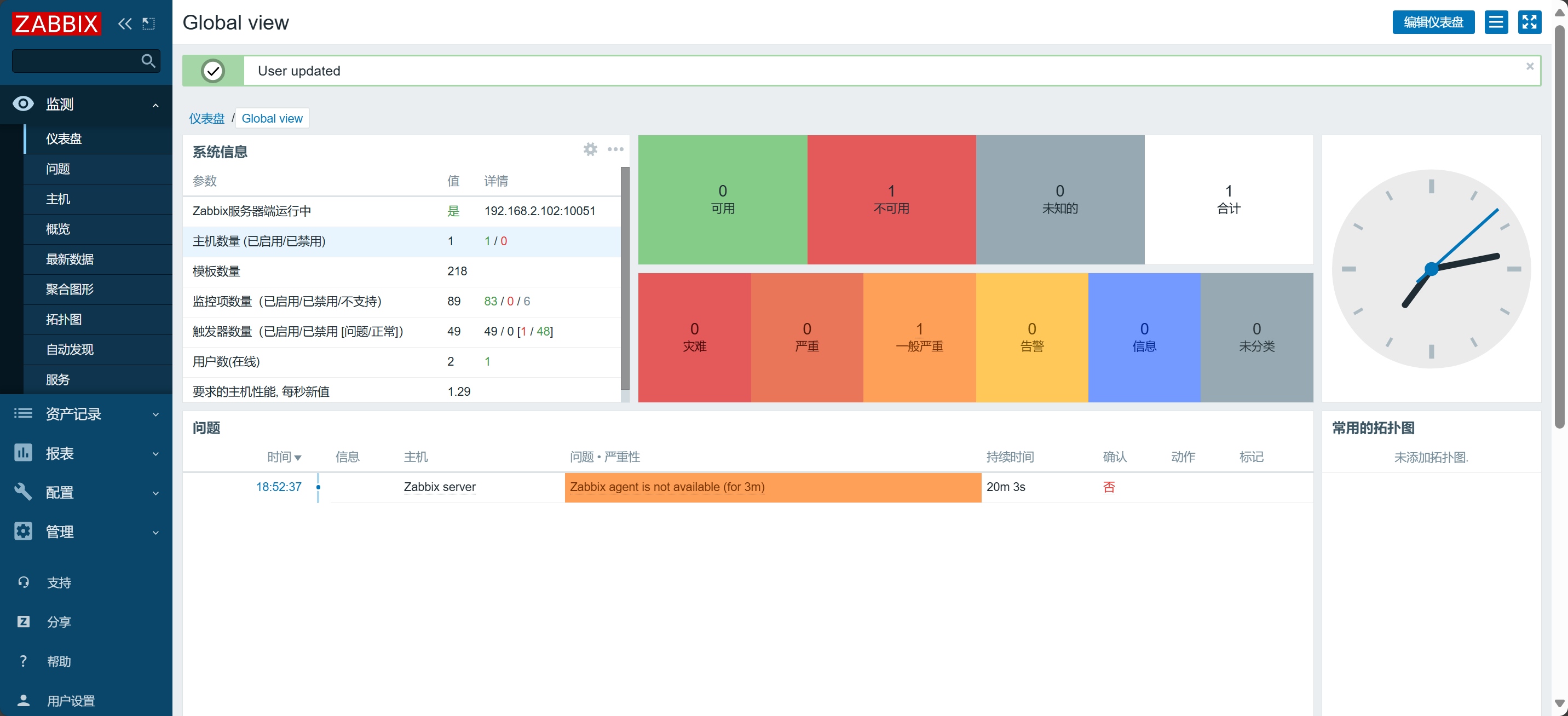
三:使用
1)术语
- 主机(Host)
- 代表一台被监控的设备。
- 使用 IP 地址 或 域名 来标识。
- 监控项(Item)
- 定义要收集的具体数据指标。
- 比如:CPU 使用率、内存占用、磁盘空间等。
- 触发器(Trigger)
- 通过逻辑表达式设定 阈值条件。
- 用于判断监控项数据是否异常,并生成告警事件。
- 动作(Action)
- 对触发器产生的事件执行的自动响应。
- 例如:发送邮件通知、短信告警、调用脚本。
2)实战
这里我们以监控 HDFS 集群为例
1. 启动 HDFS
[root@hadoop102 hadoop-3.1.3]# ./sbin/start-dfs.sh
[root@hadoop102 hadoop-3.1.3]# xcall.sh jps
================ 脚本作用 =================
批量执行命令: 'jps'
节点区间: 102 - 104
当前用户: root
============================================
--- root@hadoop104 ---
118241 DataNode
118619 SecondaryNameNode
119003 Jps
--- root@hadoop103 ---
119702 DataNode
120429 Jps
--- root@hadoop102 ---
124162 DataNode
123940 NameNode
125079 Jps
2. 创建主机
有个默认的
127.0.0.1的主机,该主机不可用可以直接删除
三:使用
1)术语
- 主机(Host)
- 代表一台被监控的设备。
- 使用 IP 地址 或 域名 来标识。
- 监控项(Item)
- 定义要收集的具体数据指标。
- 比如:CPU 使用率、内存占用、磁盘空间等。
- 触发器(Trigger)
- 通过逻辑表达式设定 阈值条件。
- 用于判断监控项数据是否异常,并生成告警事件。
- 动作(Action)
- 对触发器产生的事件执行的自动响应。
- 例如:发送邮件通知、短信告警、调用脚本。
2)实战
这里我们以监控 HDFS 集群为例
1. 启动 HDFS
[root@hadoop102 hadoop-3.1.3]# ./sbin/start-dfs.sh
[root@hadoop102 hadoop-3.1.3]# xcall.sh jps
================ 脚本作用 =================
批量执行命令: 'jps'
节点区间: 102 - 104
当前用户: root
============================================
--- root@hadoop104 ---
118241 DataNode
118619 SecondaryNameNode
119003 Jps
--- root@hadoop103 ---
119702 DataNode
120429 Jps
--- root@hadoop102 ---
124162 DataNode
123940 NameNode
125079 Jps
2. 创建主机
有个默认的
127.0.0.1的主机,该主机不可用可以直接删除
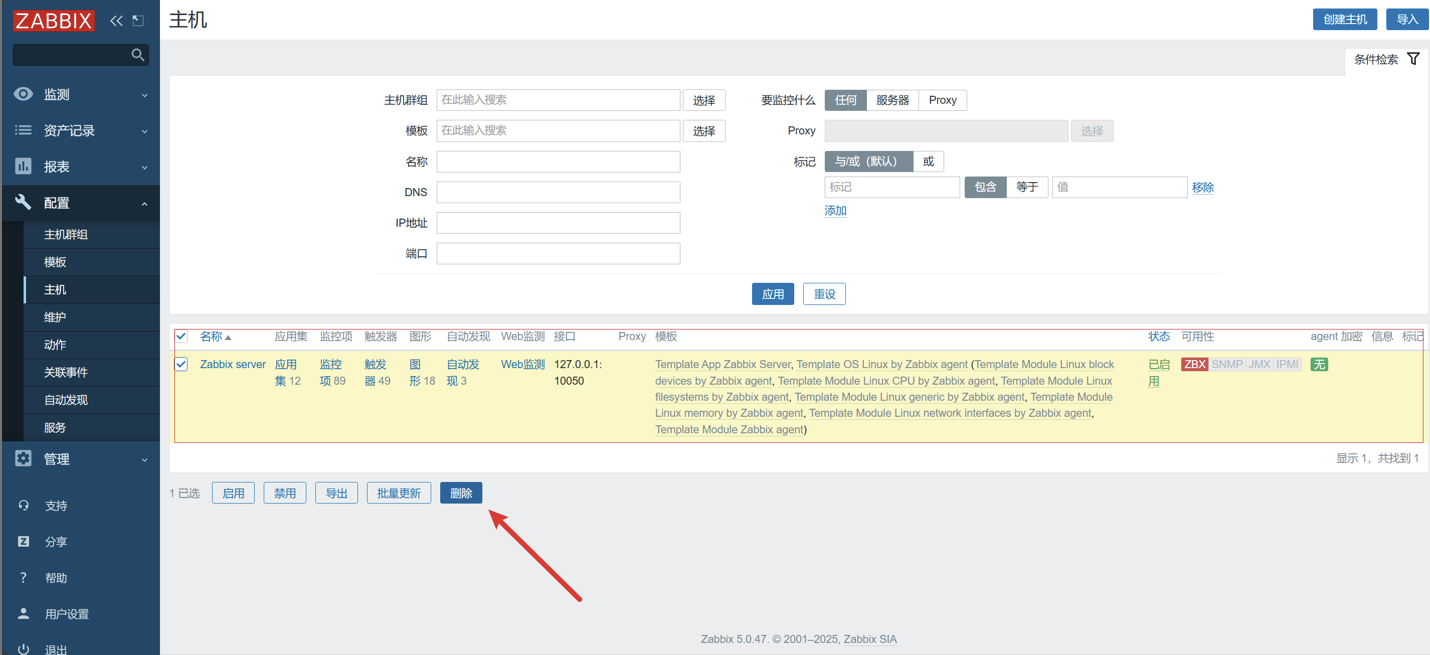
-
点击配置 -> 主机 -> 创建主机
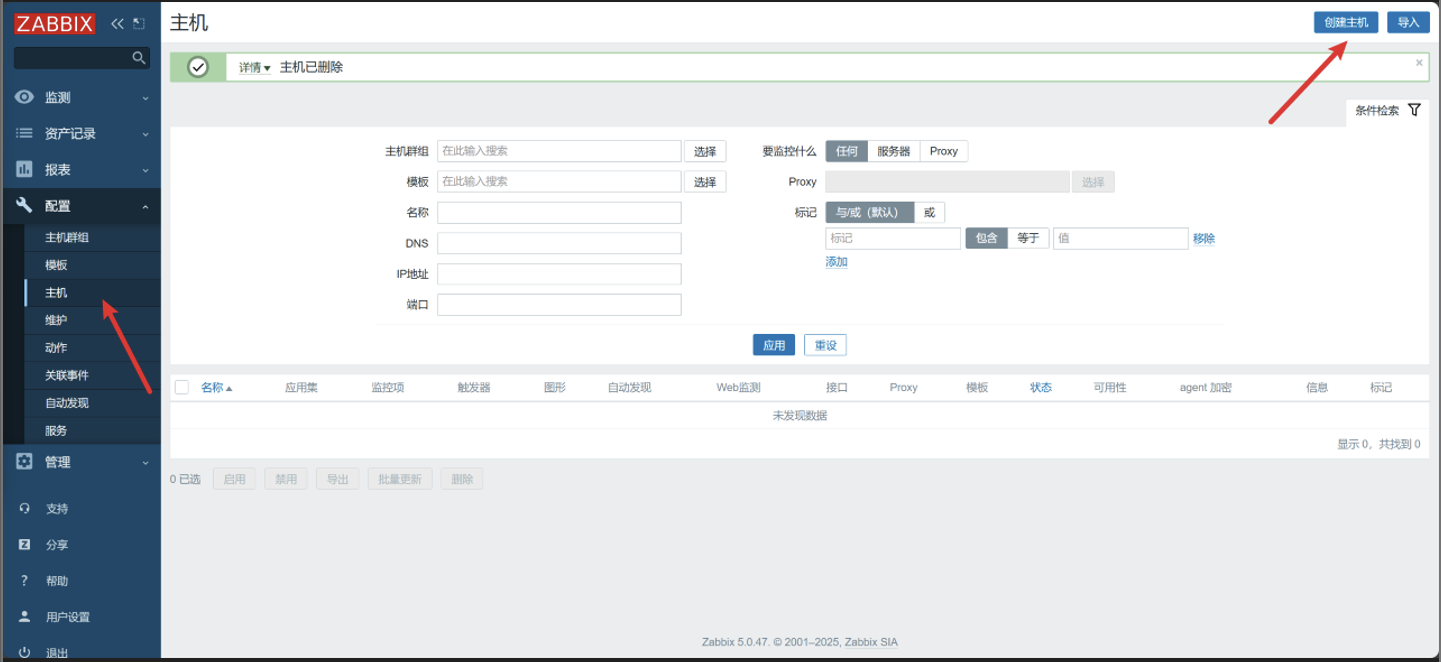
-
配置主机
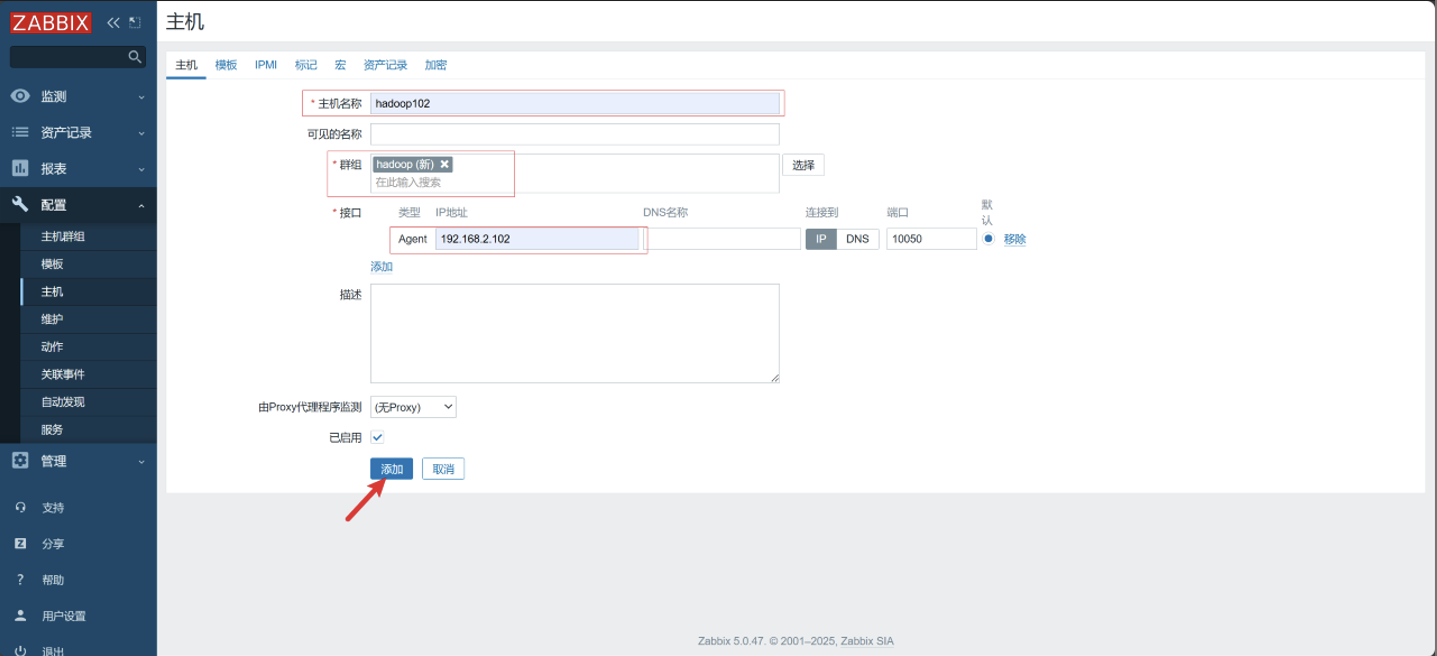
-
配置三台主机
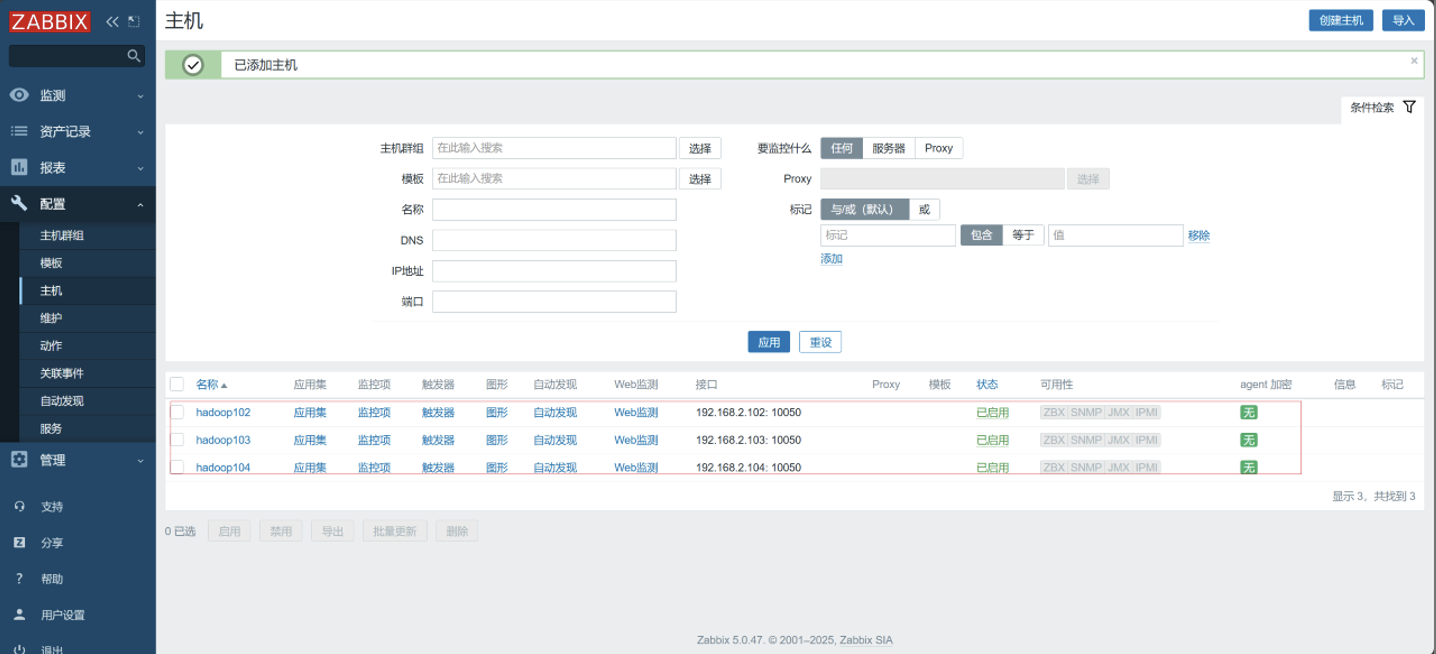
3. 创建监控项
-
点击监控项
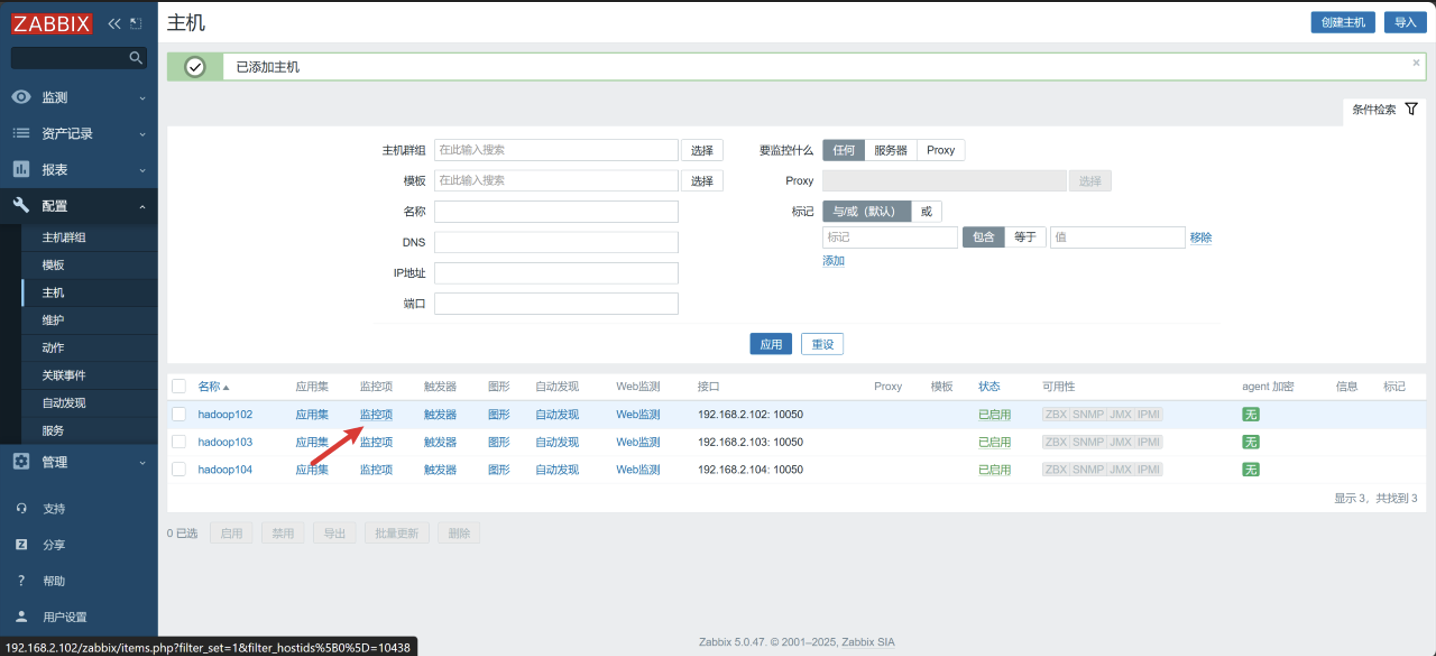
-
点击创建监控项
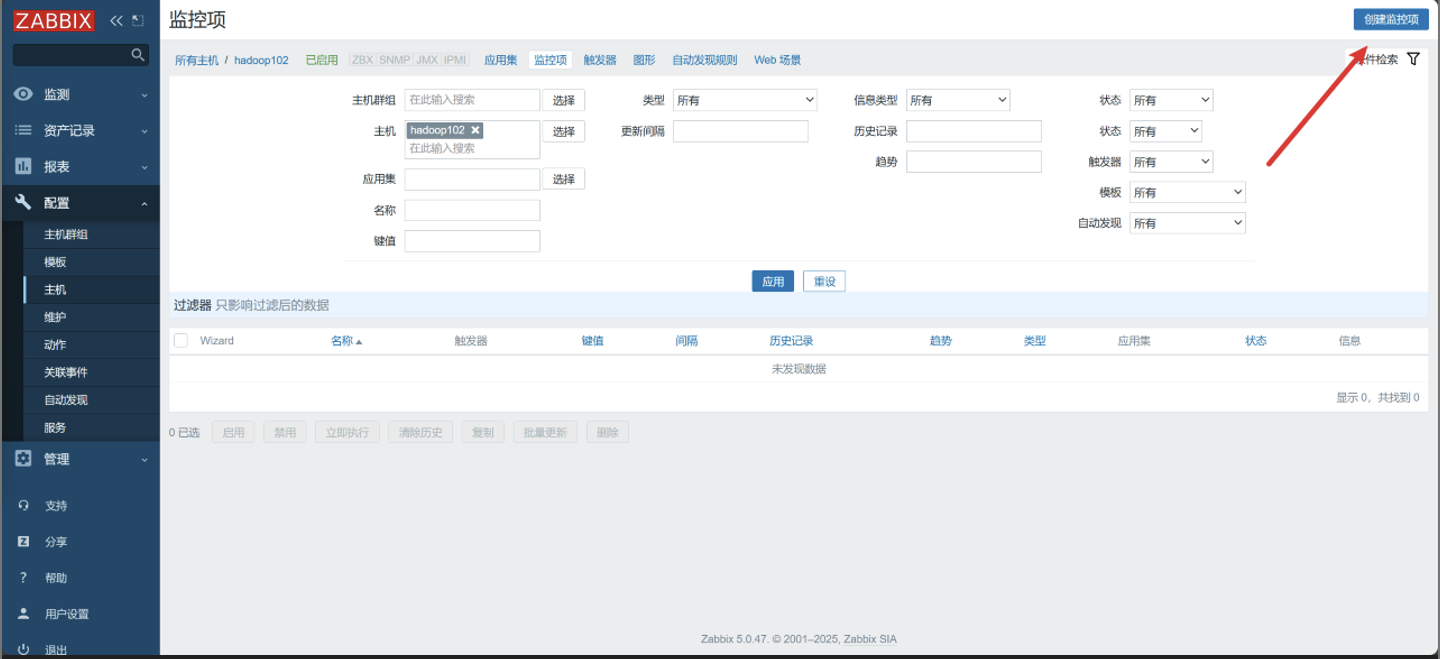
-
配置监控项
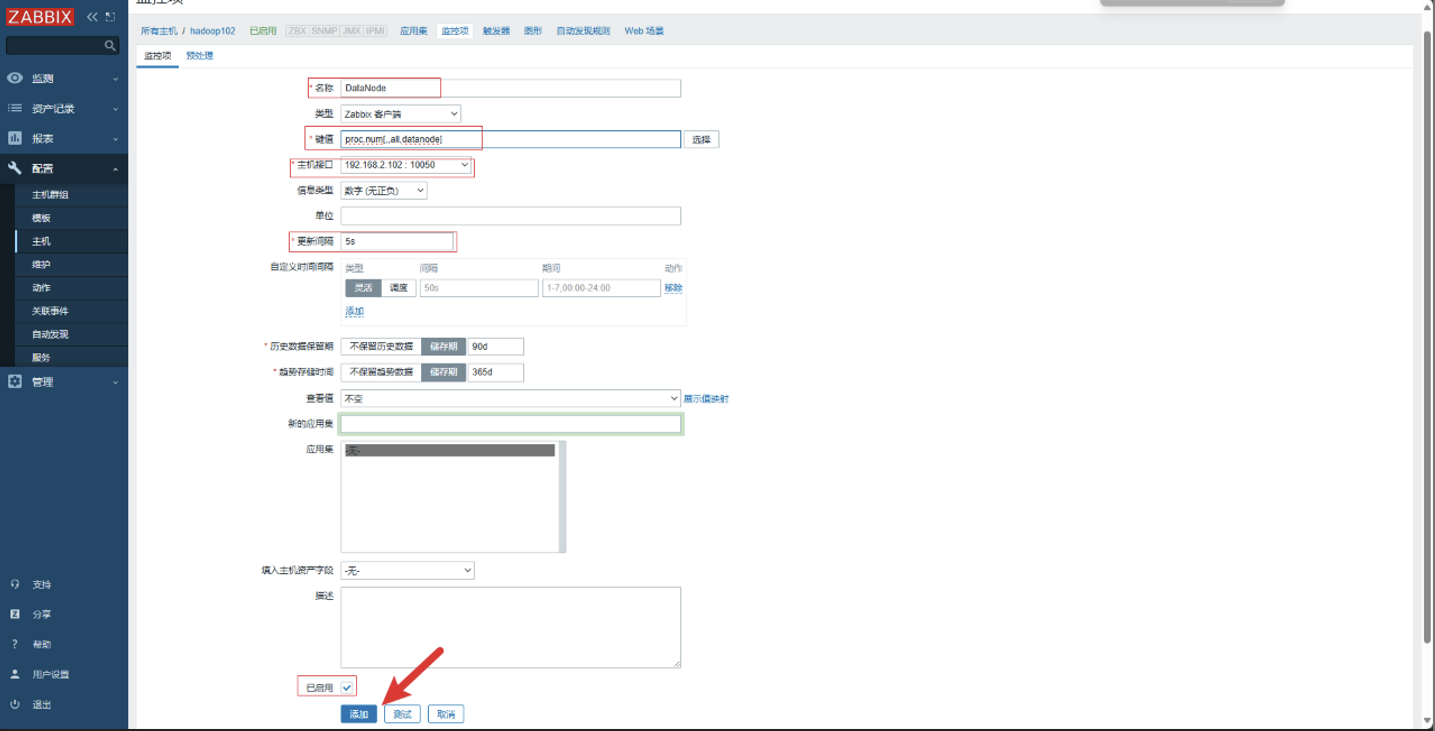
-
配置三台主机的监控项
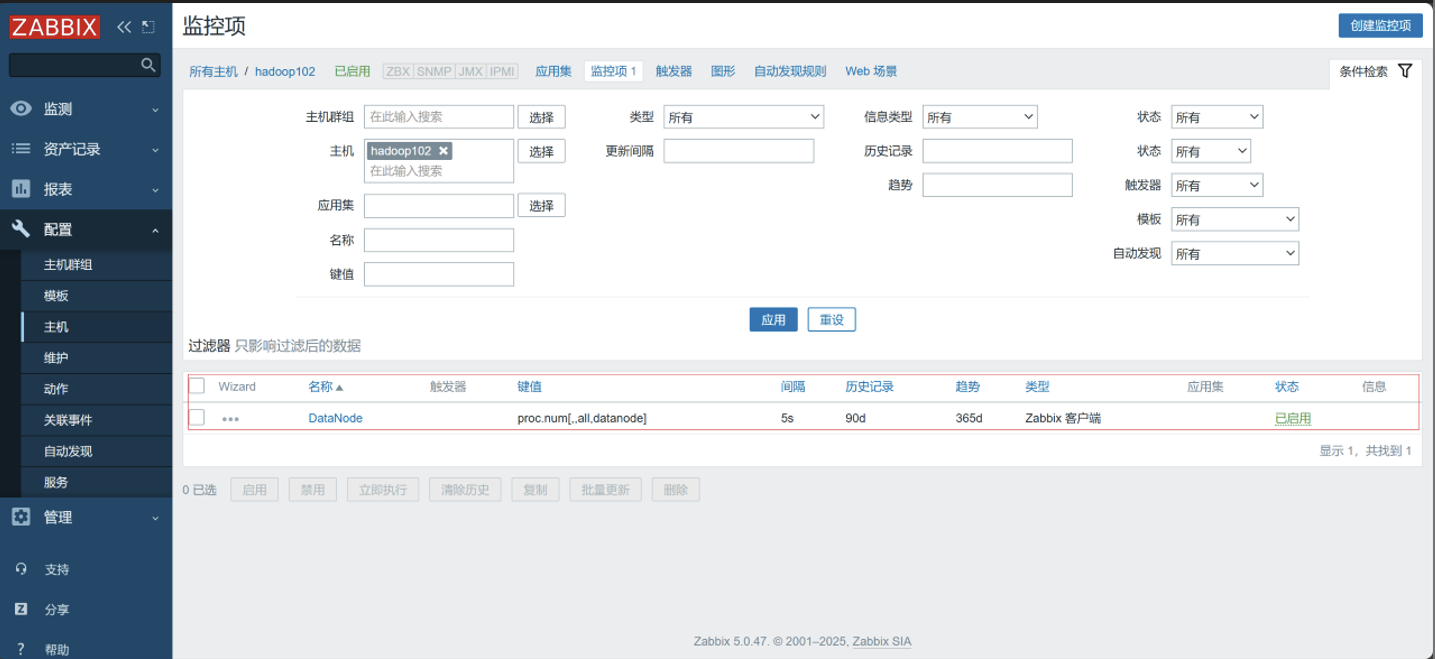
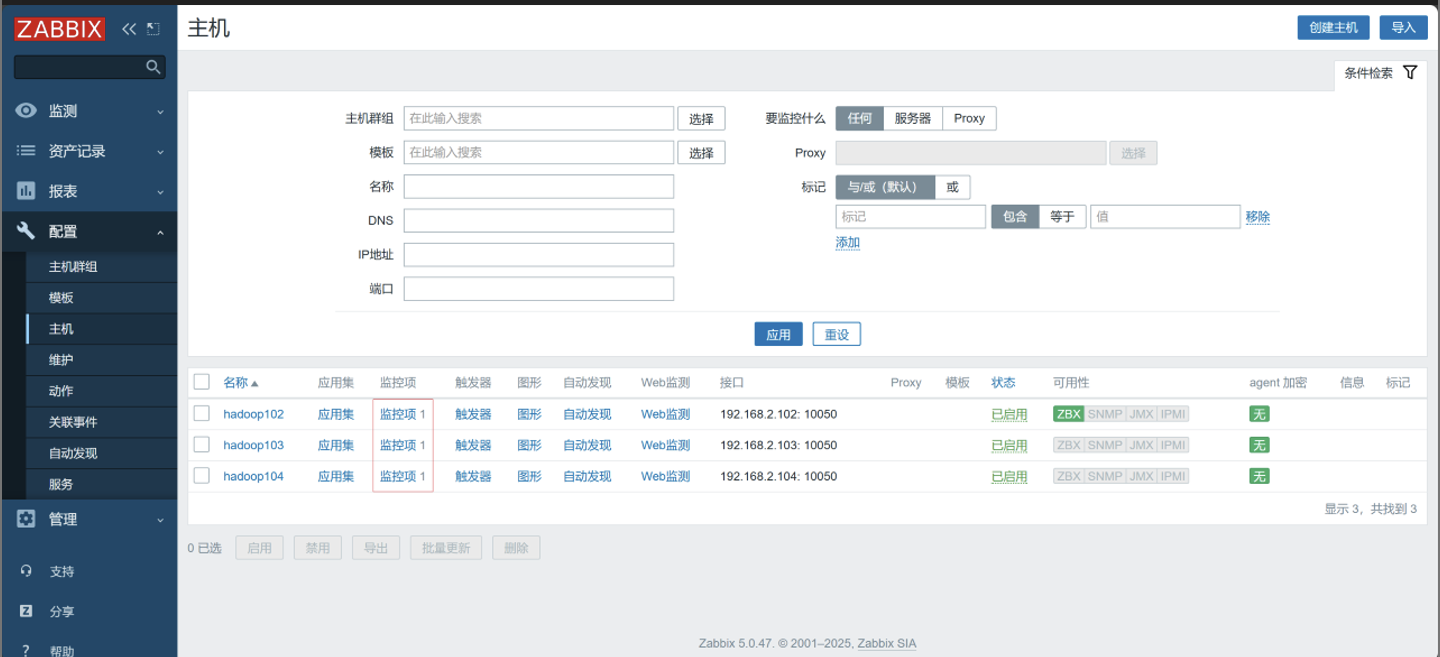
-
查看最新数据
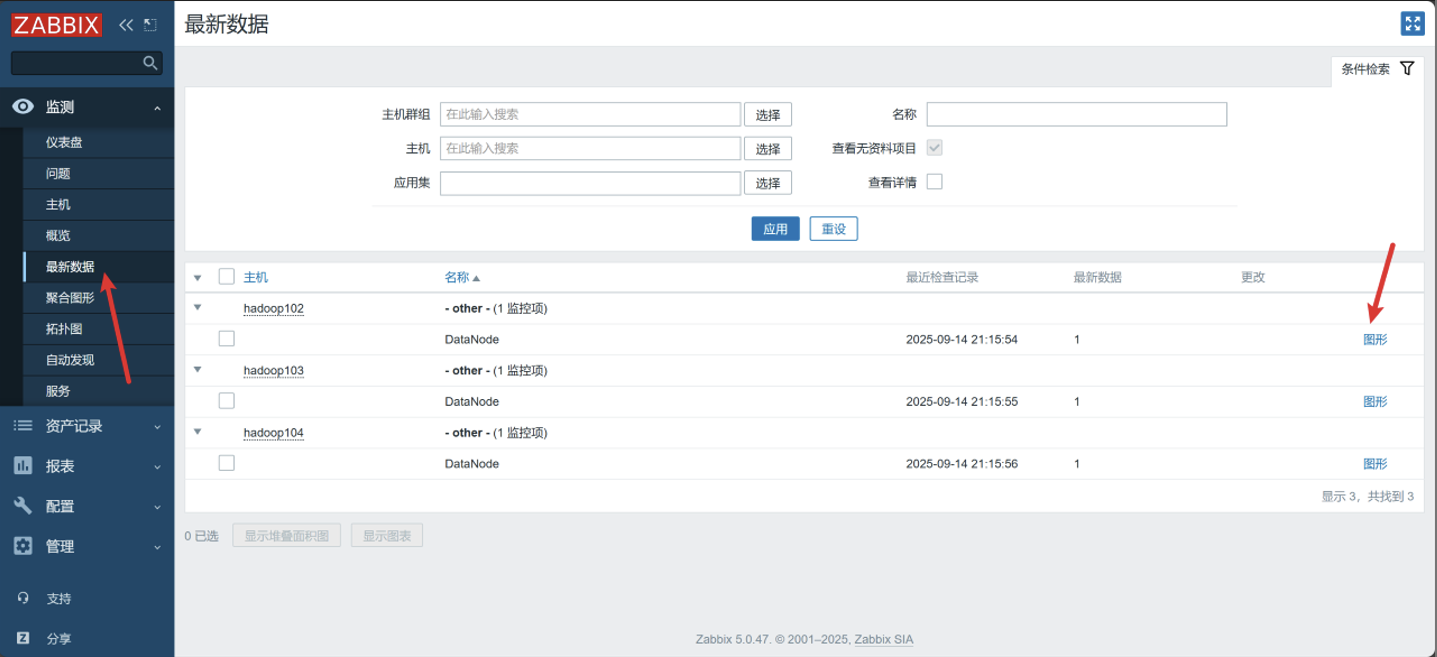
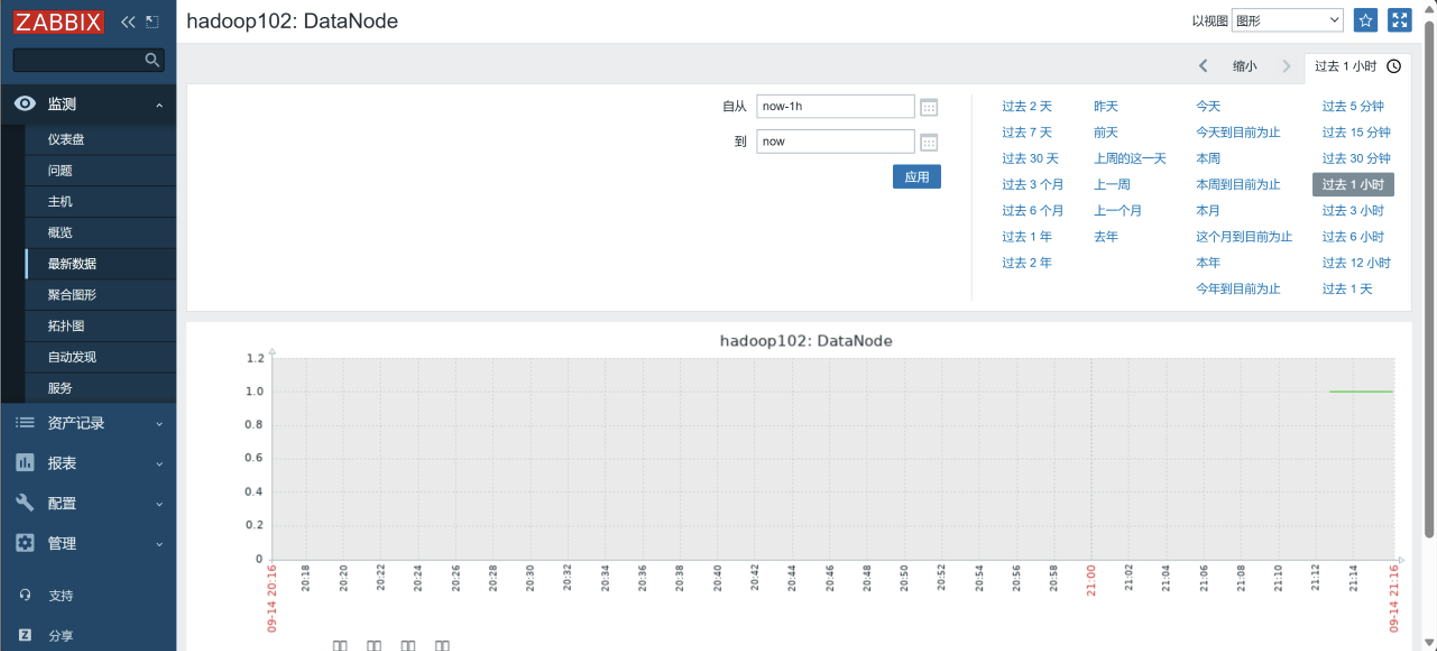
4. 创建触发器
-
点击触发器
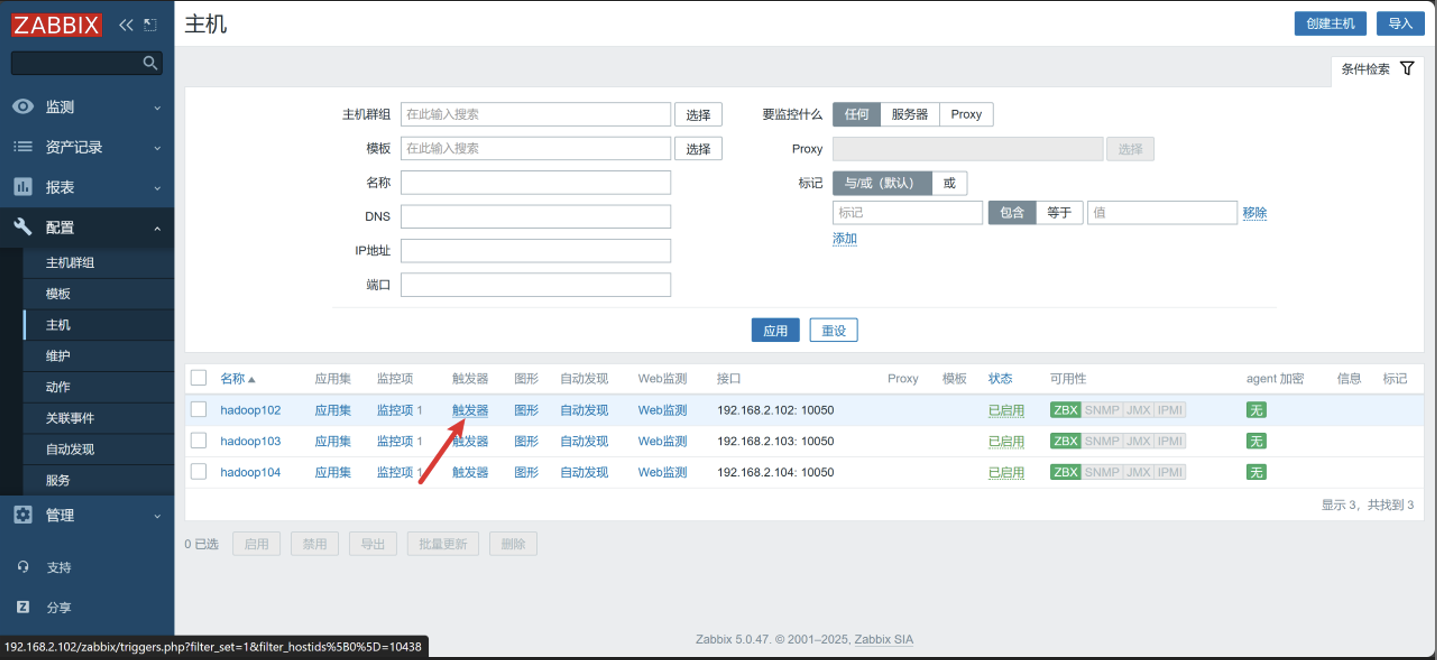
-
点击创建触发器
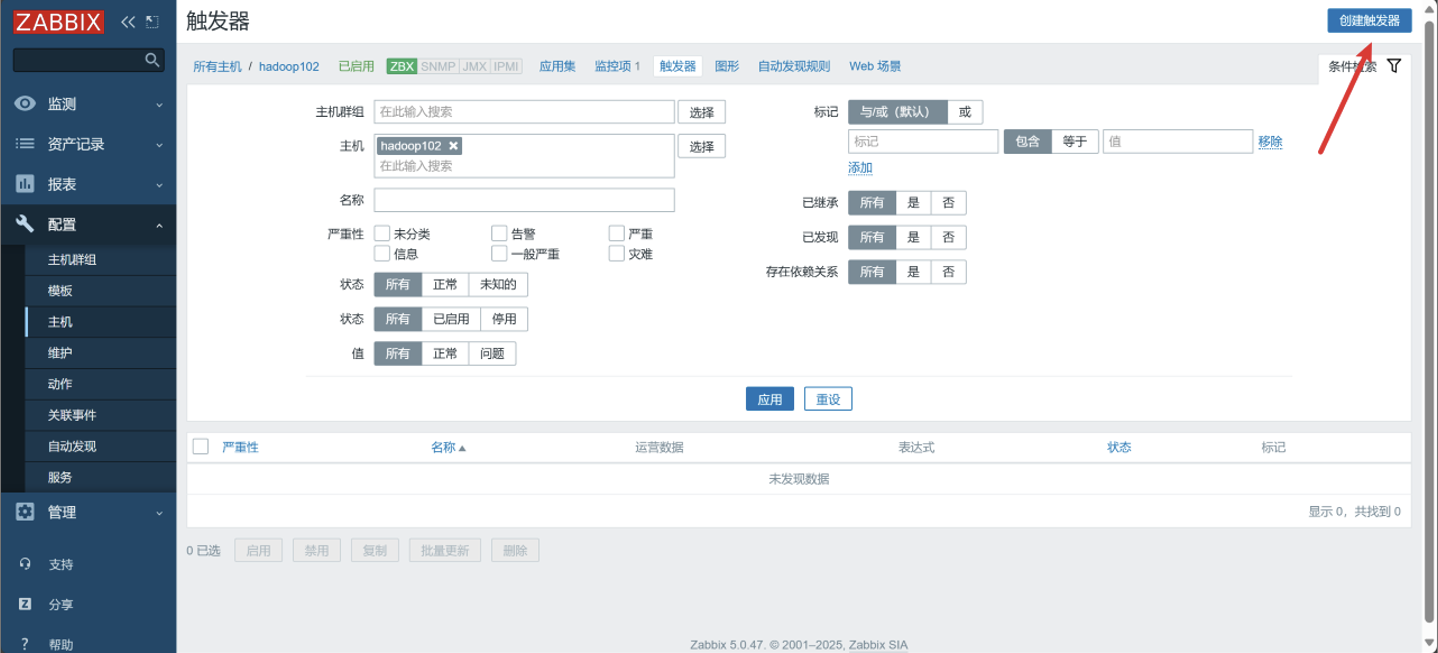
-
配置触发器
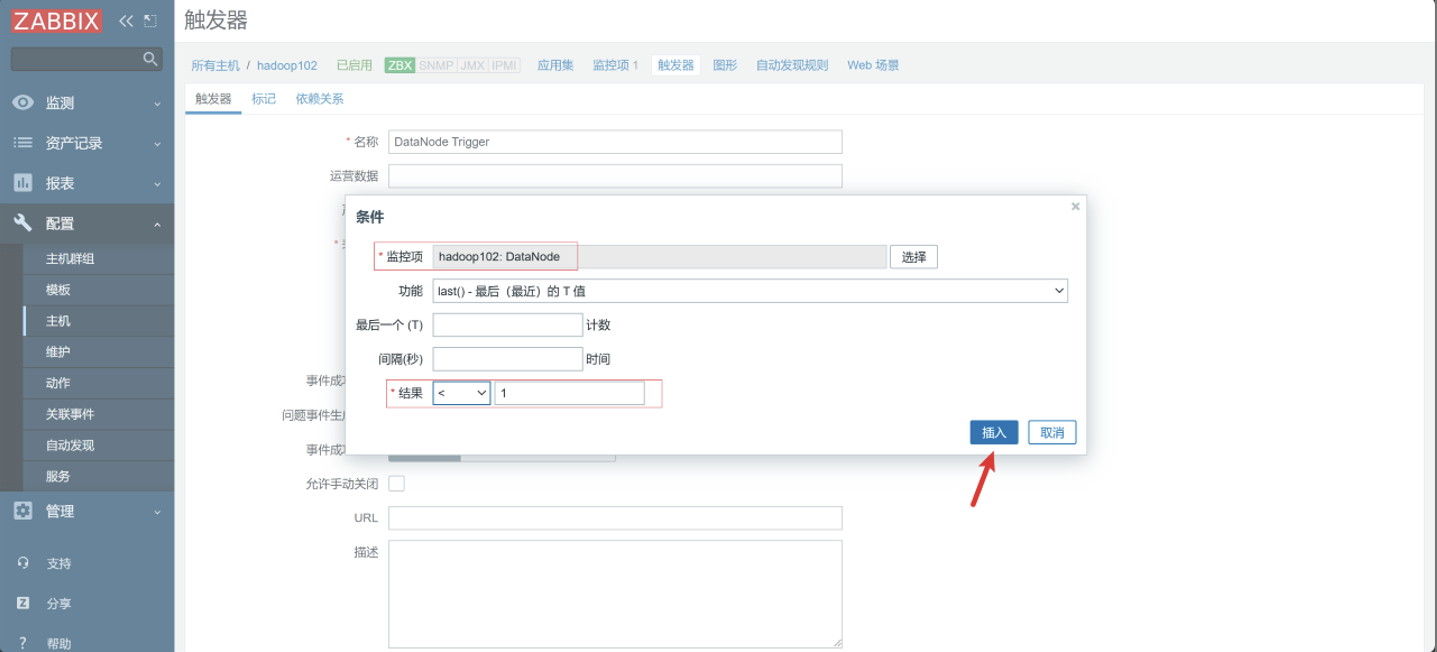
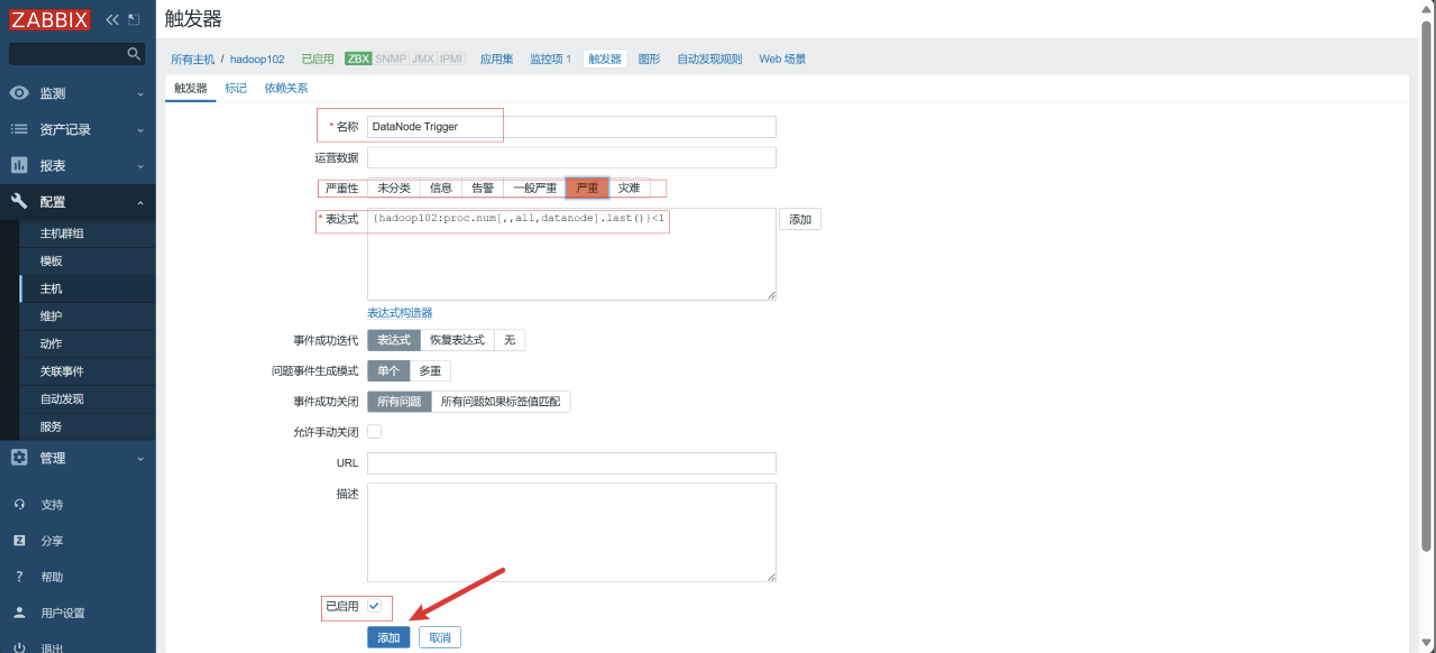
-
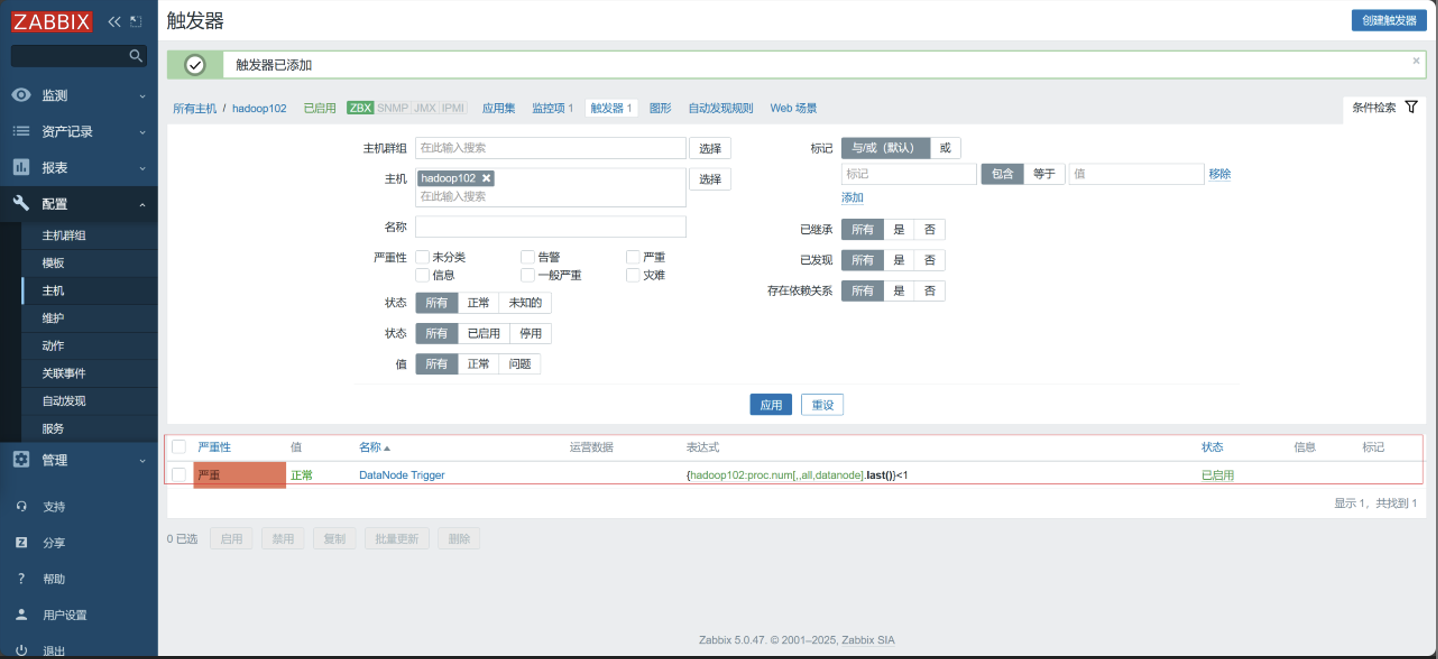
配置三台主机的触发器
5. 创建动作
-
点击动作
-
点击创建动作
-
配置动作&操作
-
动作
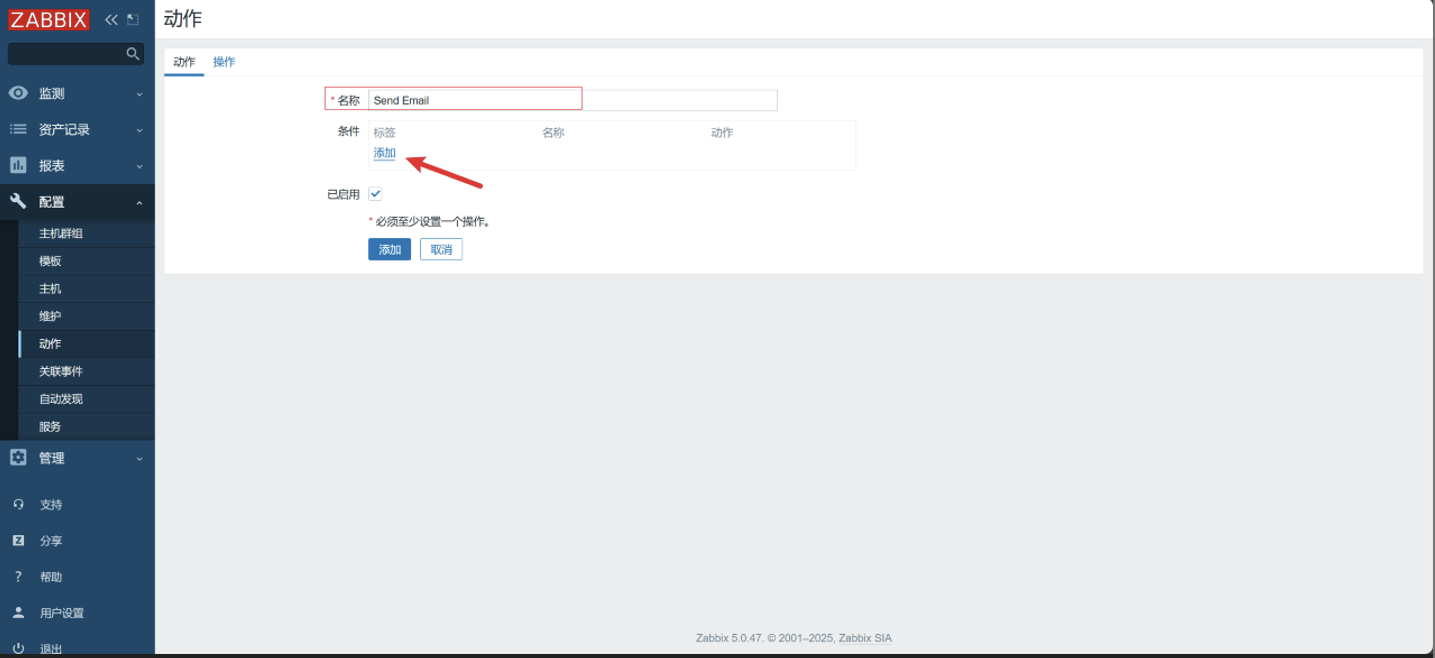
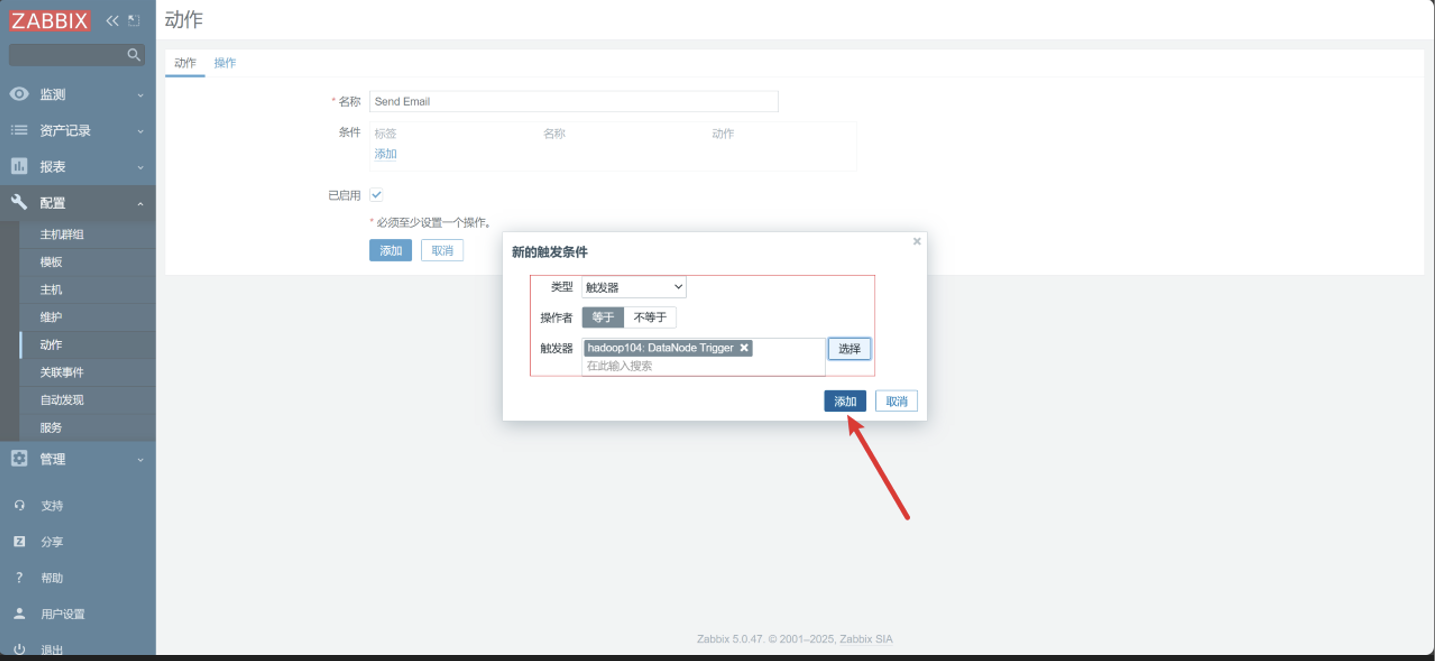
-
操作
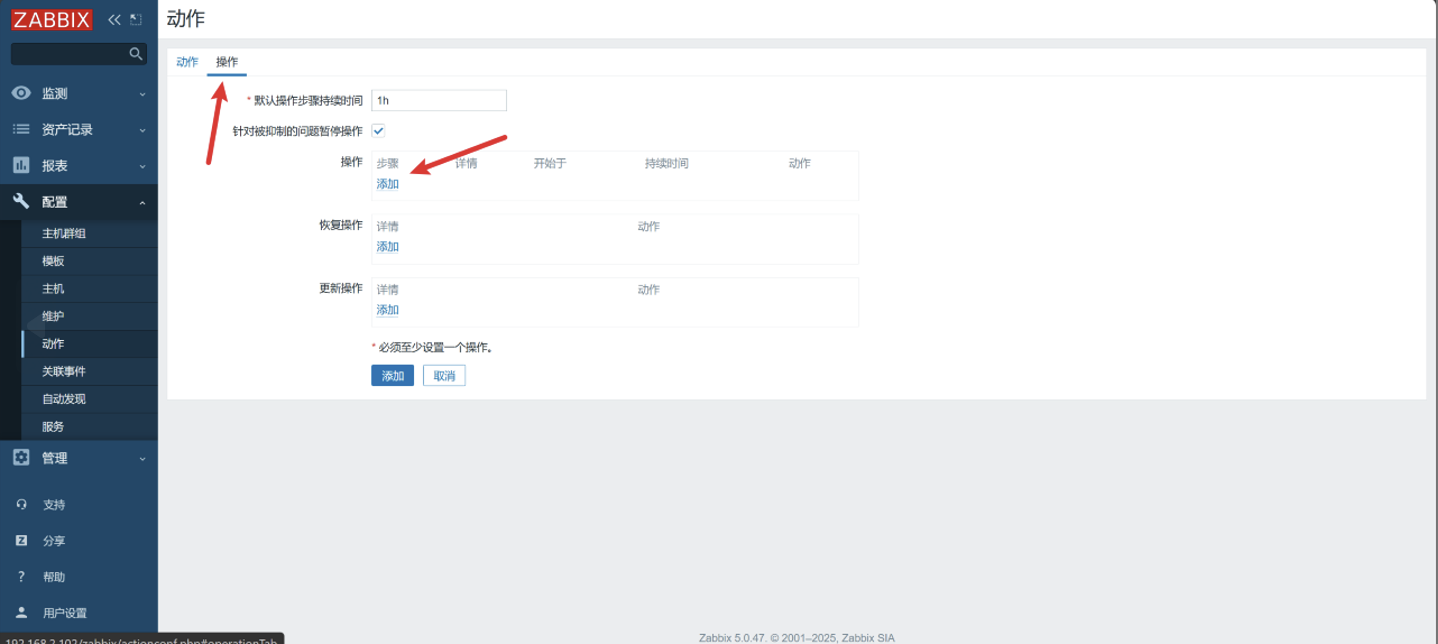
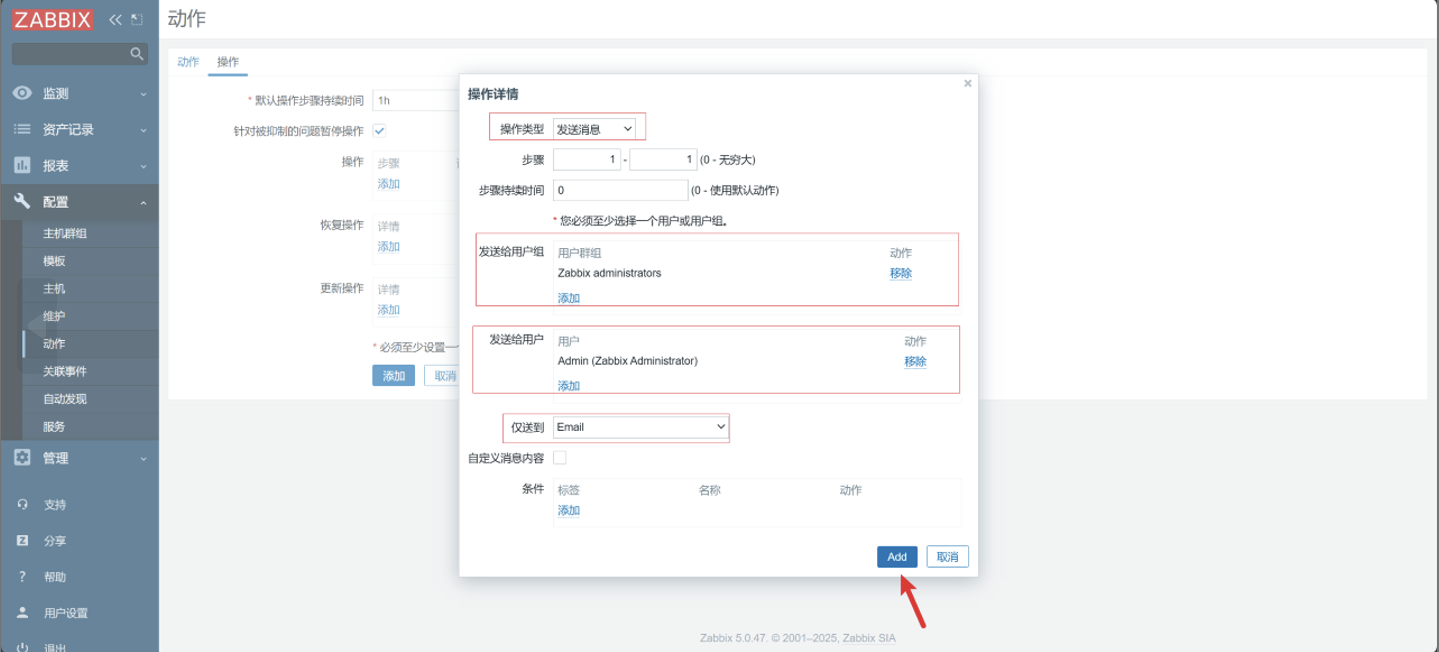
-
点击添加
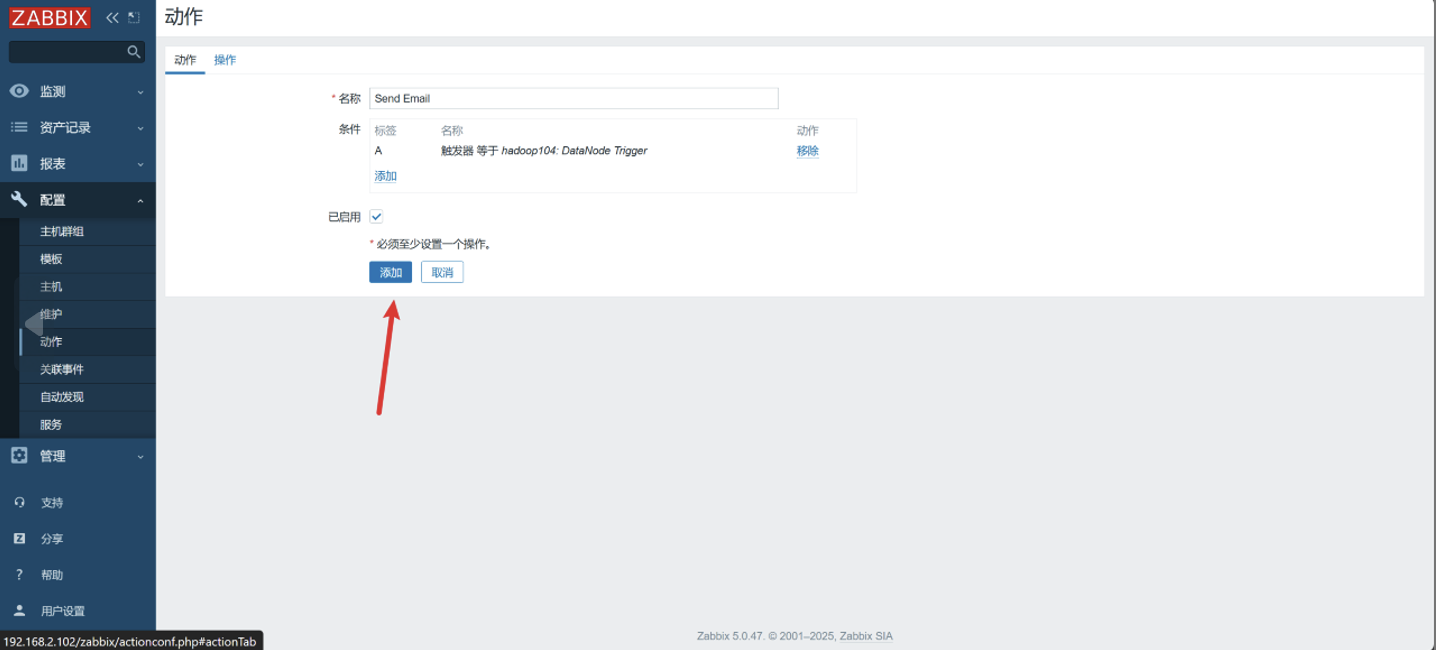
-
-
查看
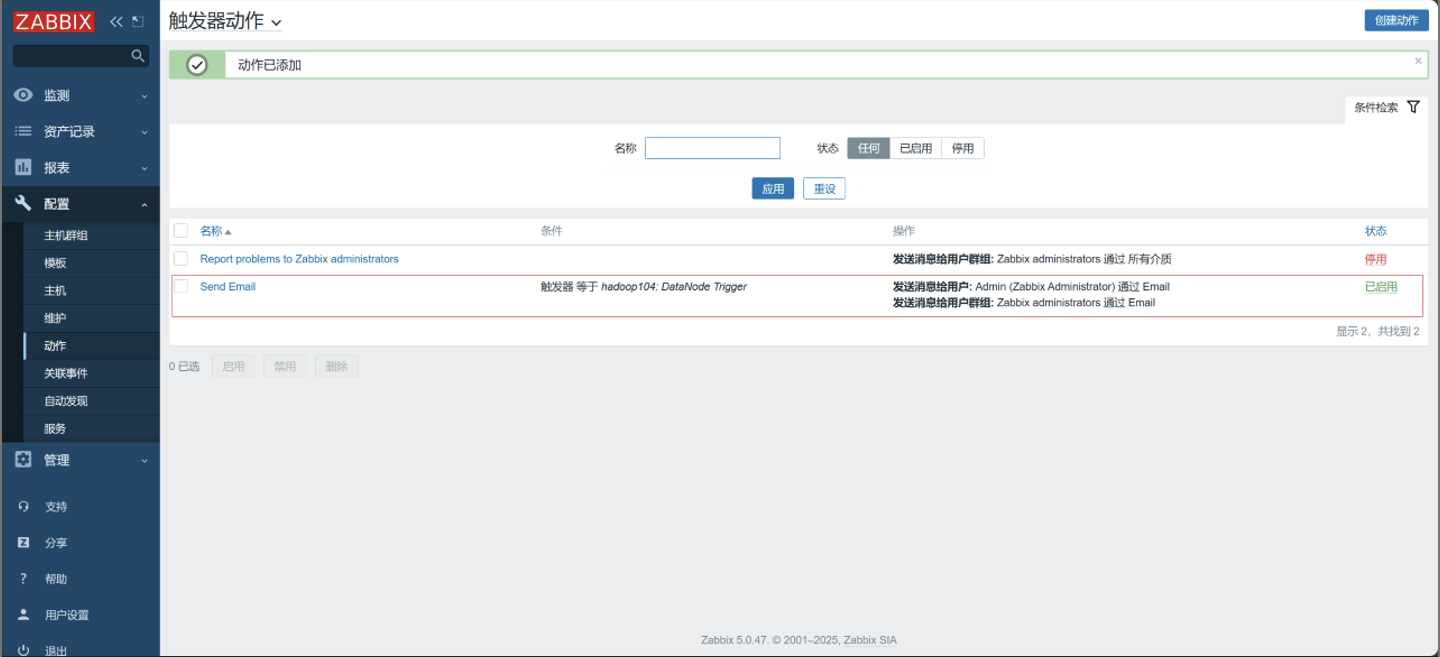
6. 申请邮箱
本案例采用邮件报警,可以使用126、163、QQ 等邮箱。下面以QQ邮箱为例。
-
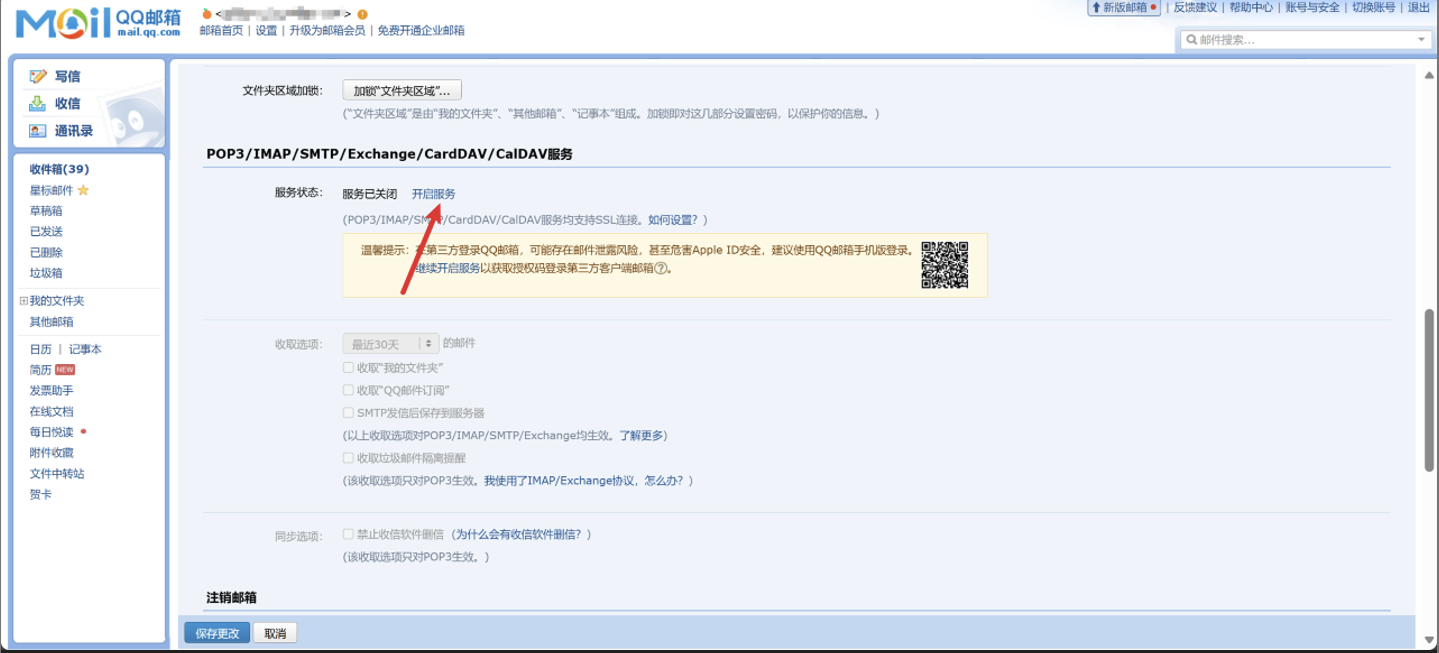
开启
POP3/IMAP/SMTP服务
-
获取授权码
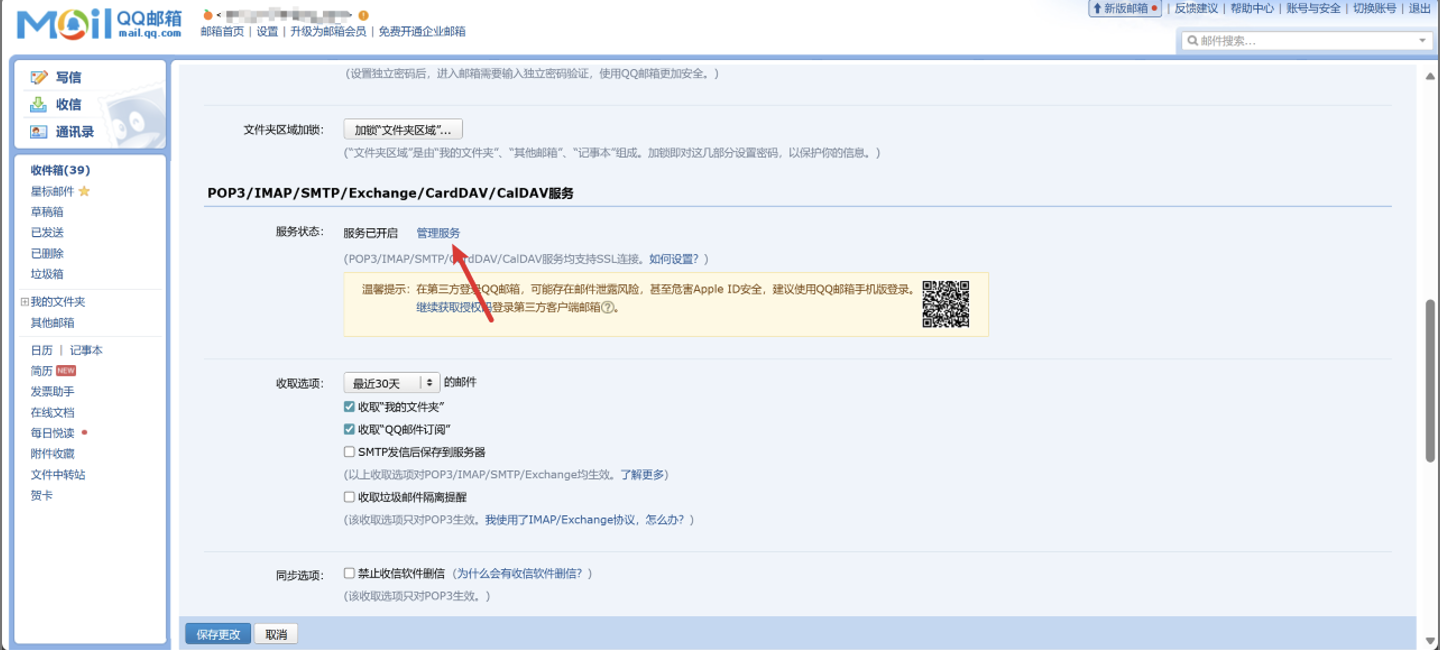
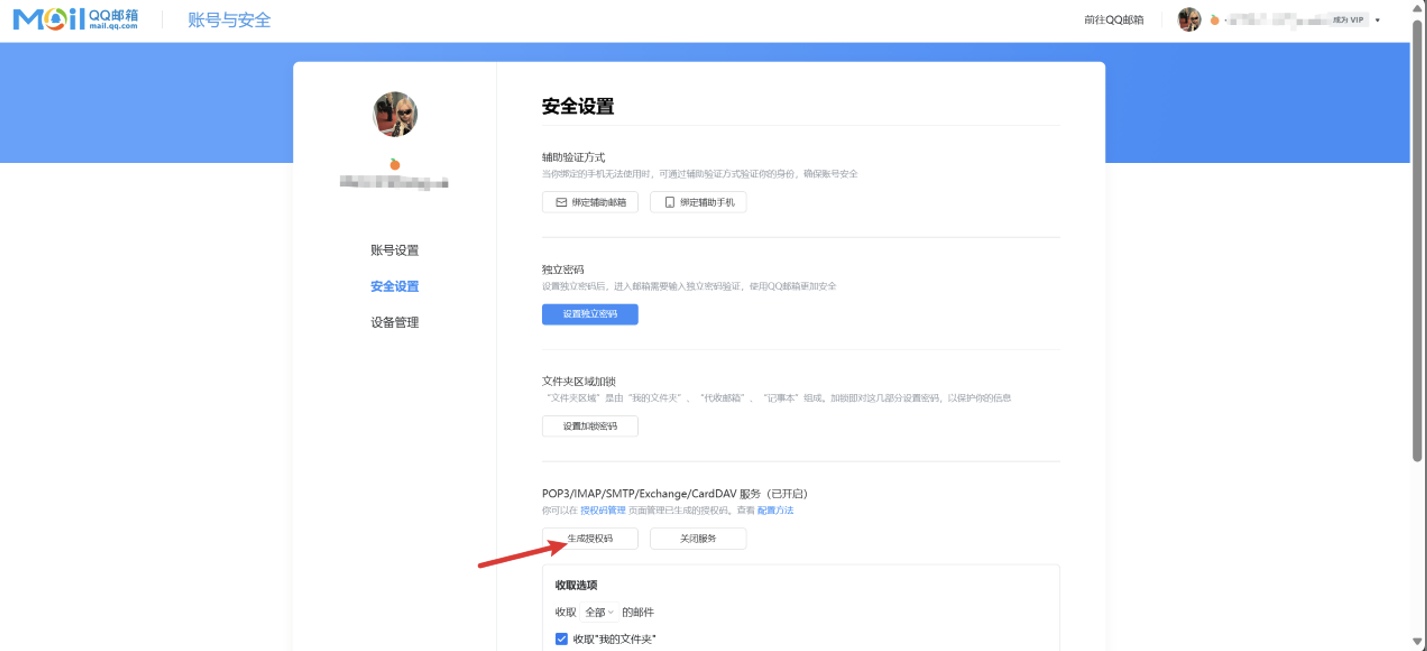
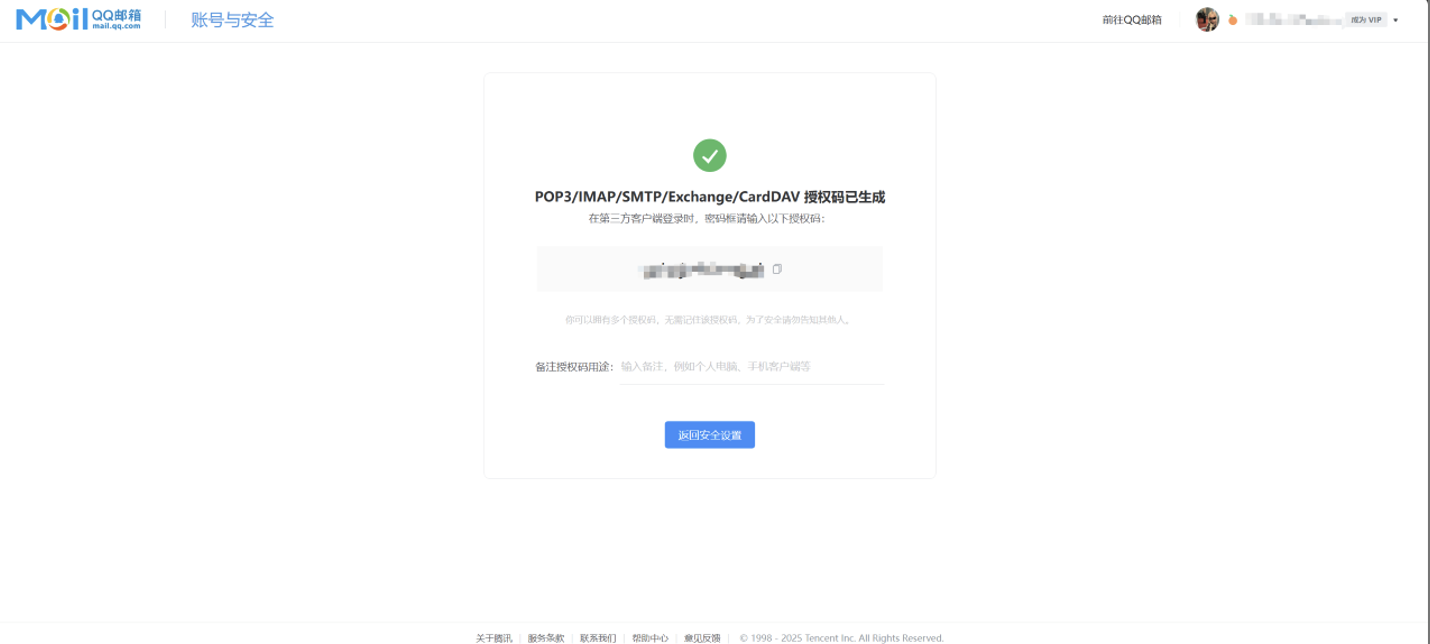
-
IMAP/SMTP 设置方法
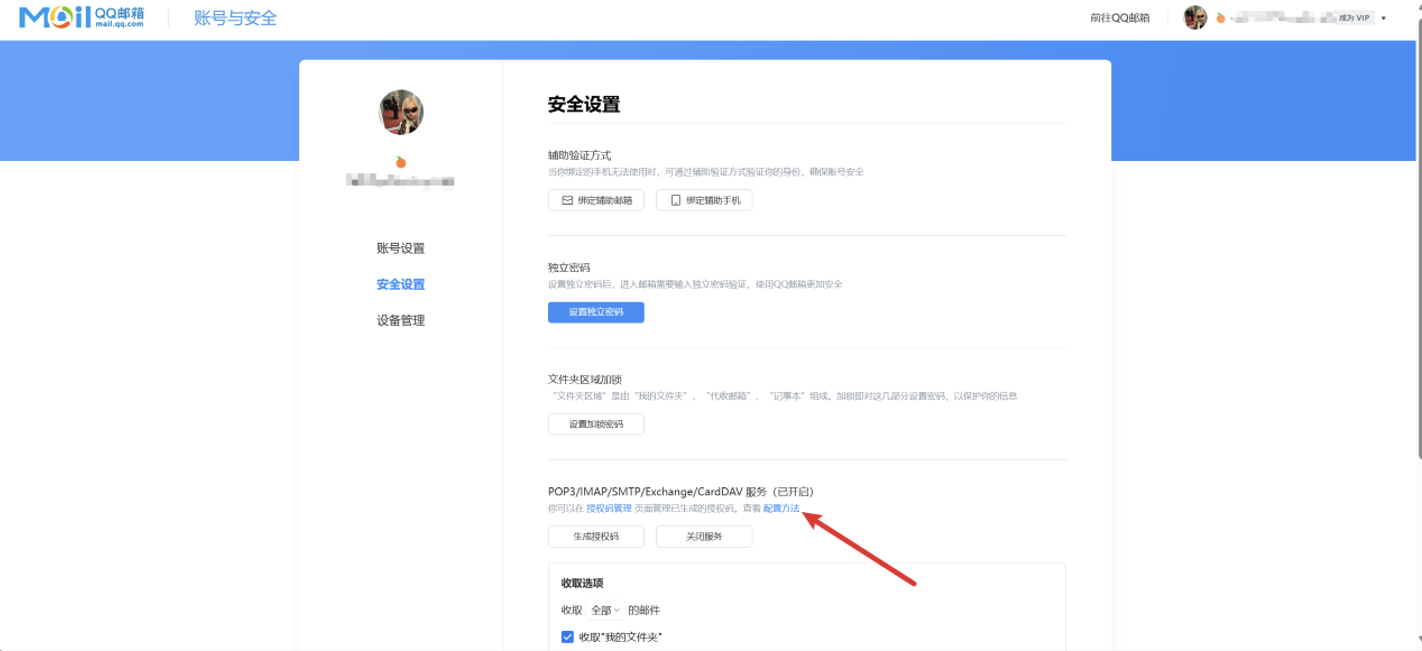

7. 编辑报警媒介
在 媒介类型 里配置的是 怎么发邮件(发件人、SMTP、认证方式)
-
点击媒介
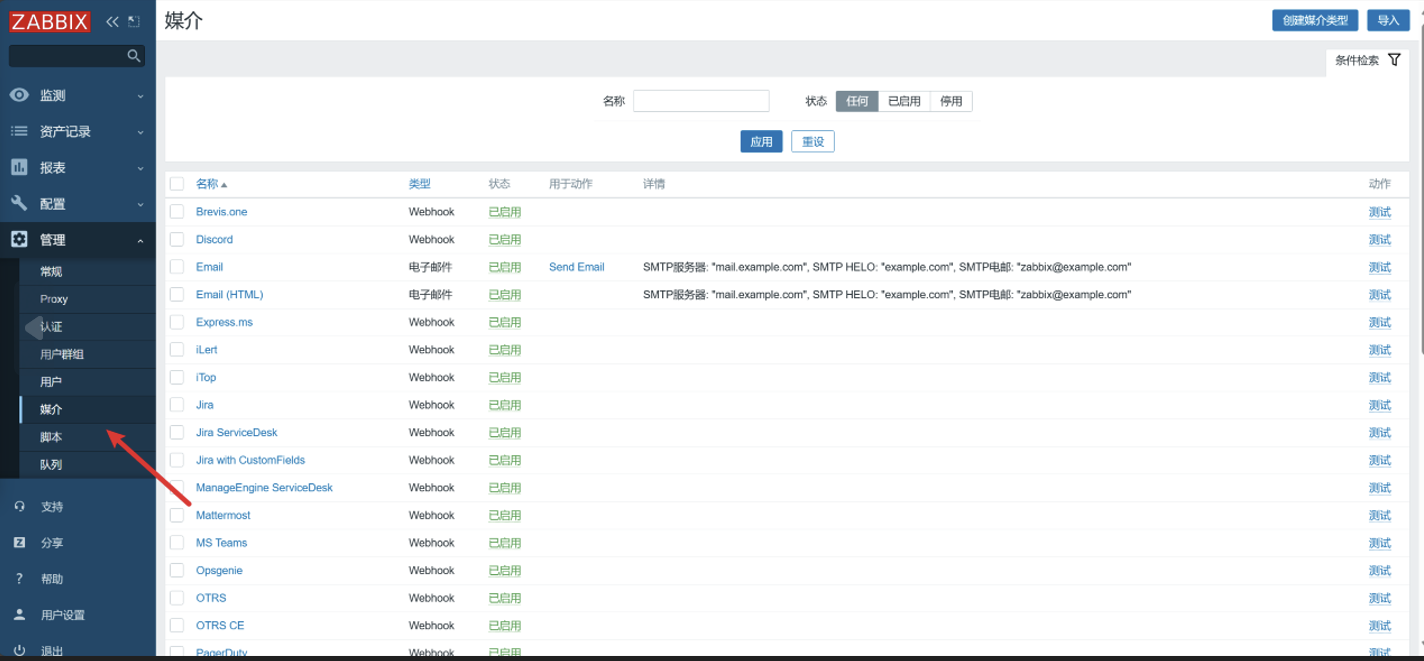
-
点击 Email
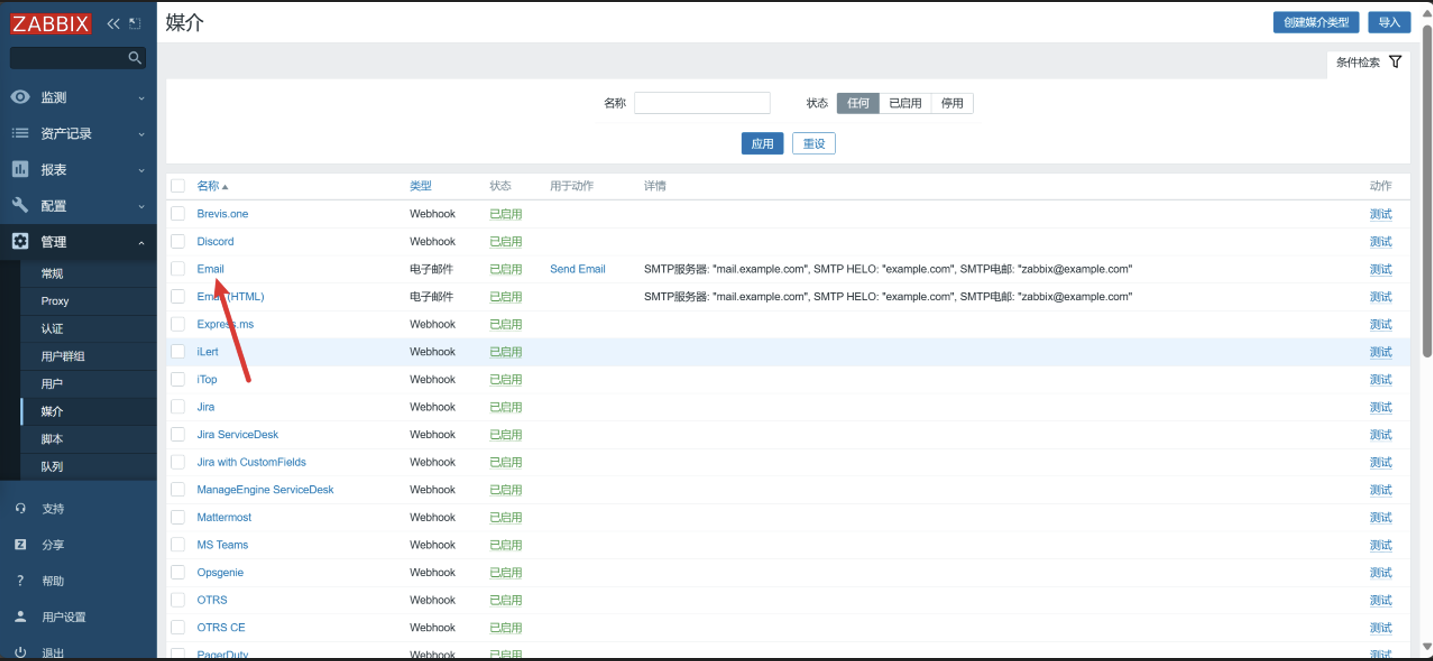
-
编辑
SMTP服务器:smtp.qq.com
SMTP HELO:smtp.qq.com
SMTP 电邮:发件人邮箱
用户名称:发件人邮箱
密码:发件人邮箱的授权码
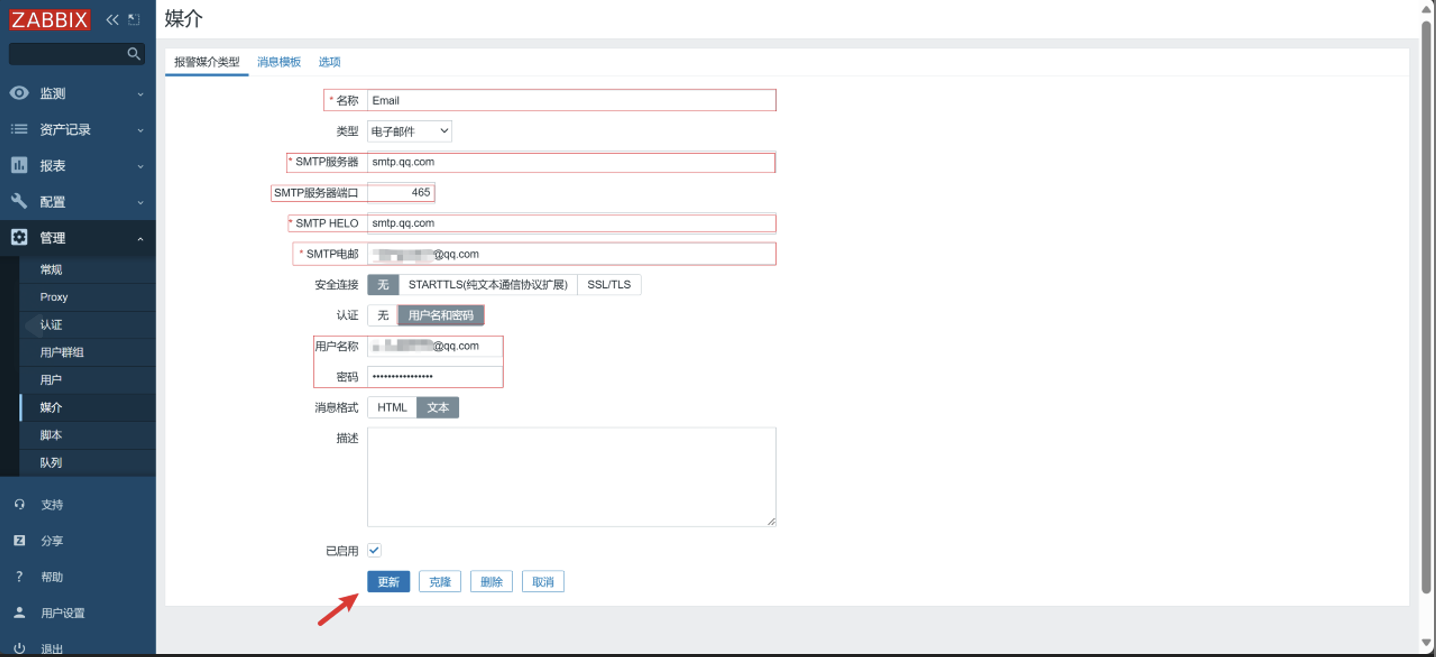
-
测试
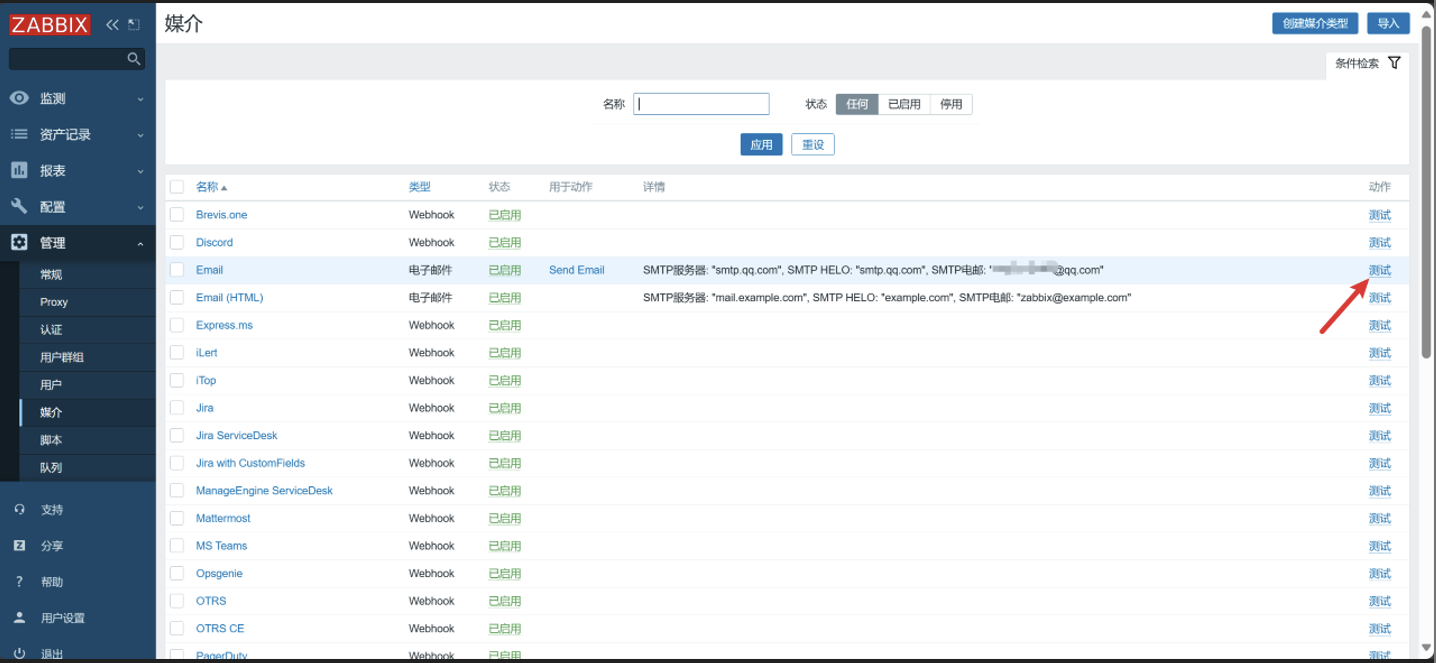
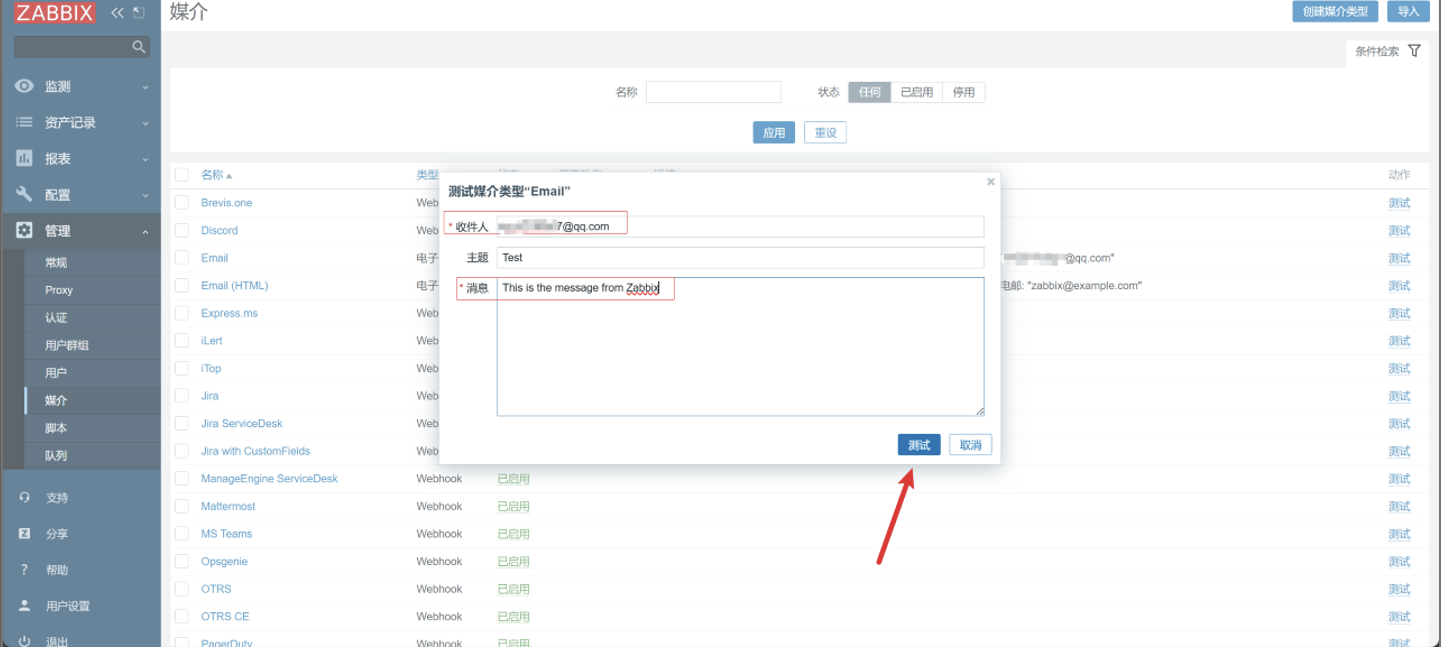
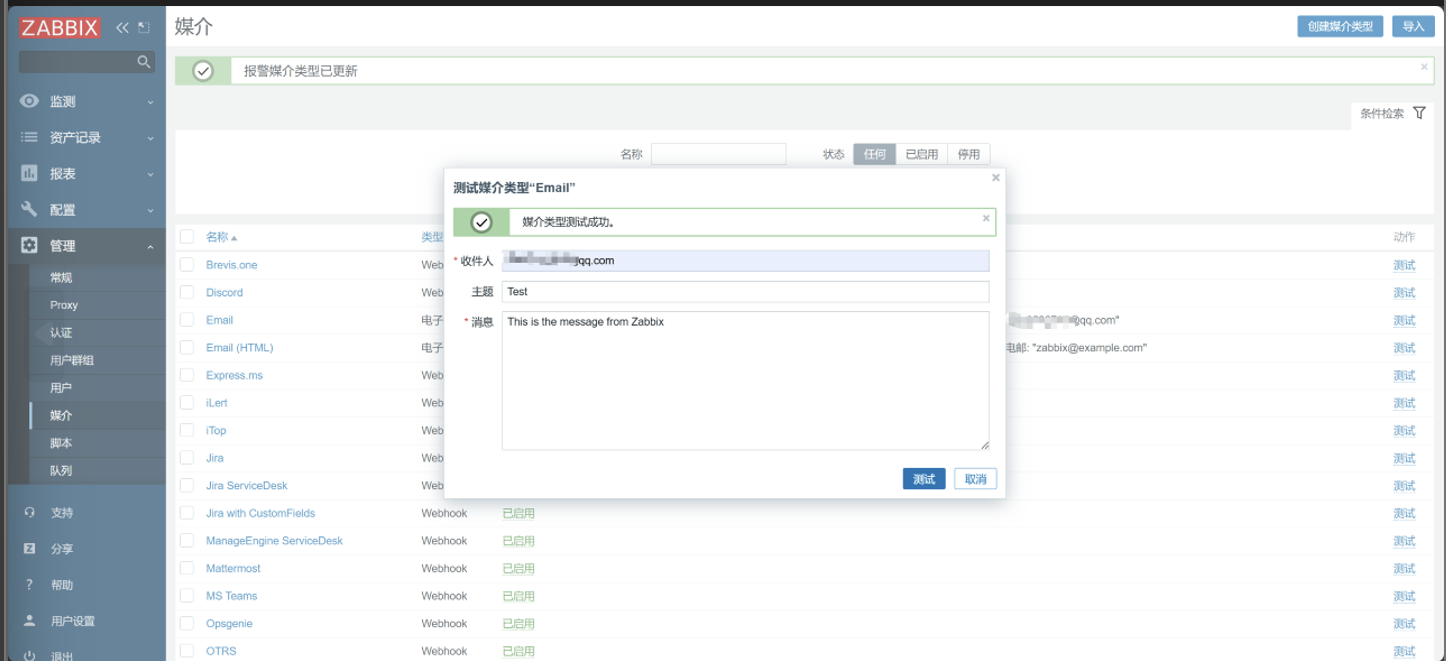
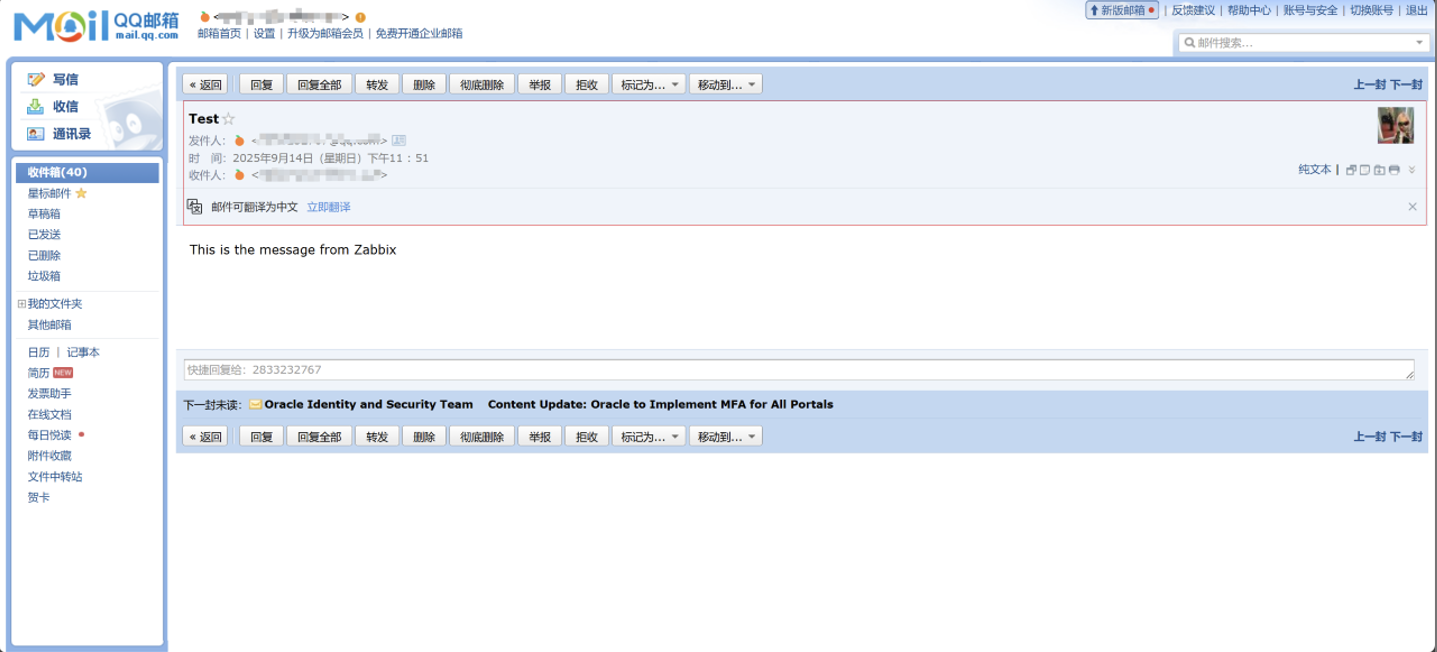
8. 用户配置
给动作中配置的用户配置 Email,设置收件人地址
-
点击用户
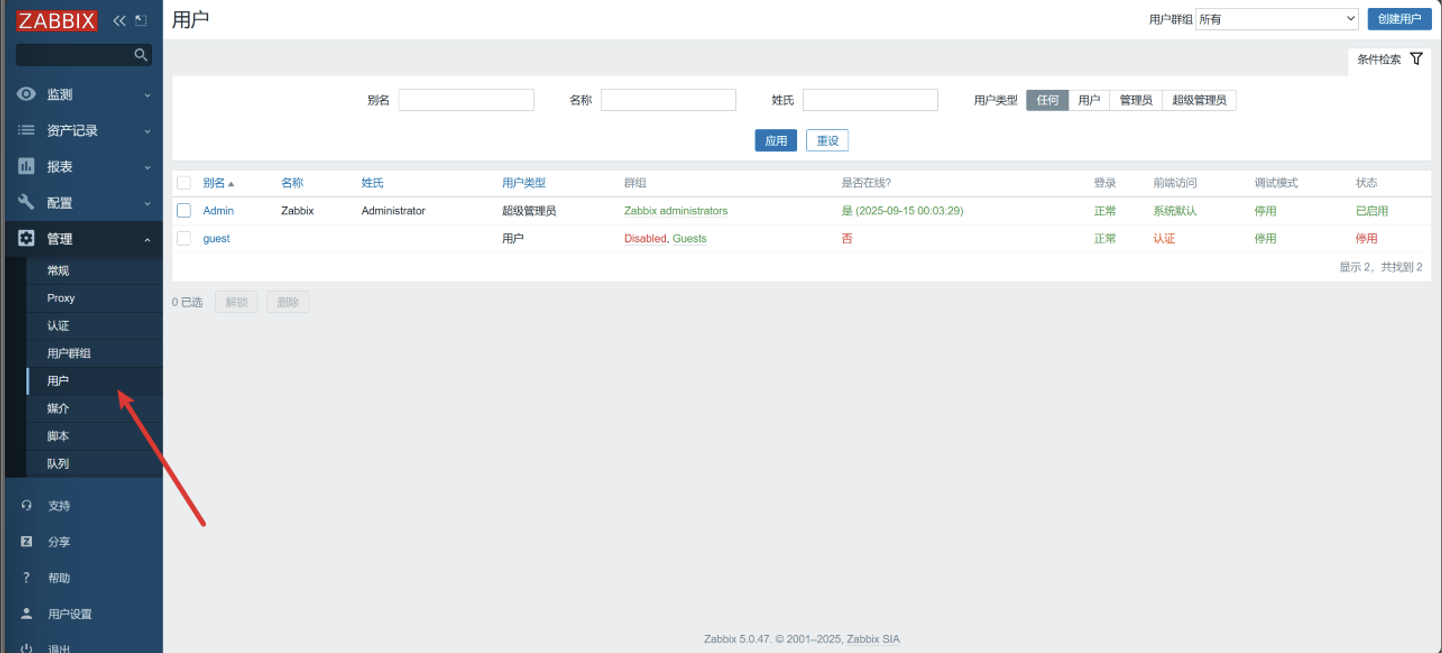
-
选择用户
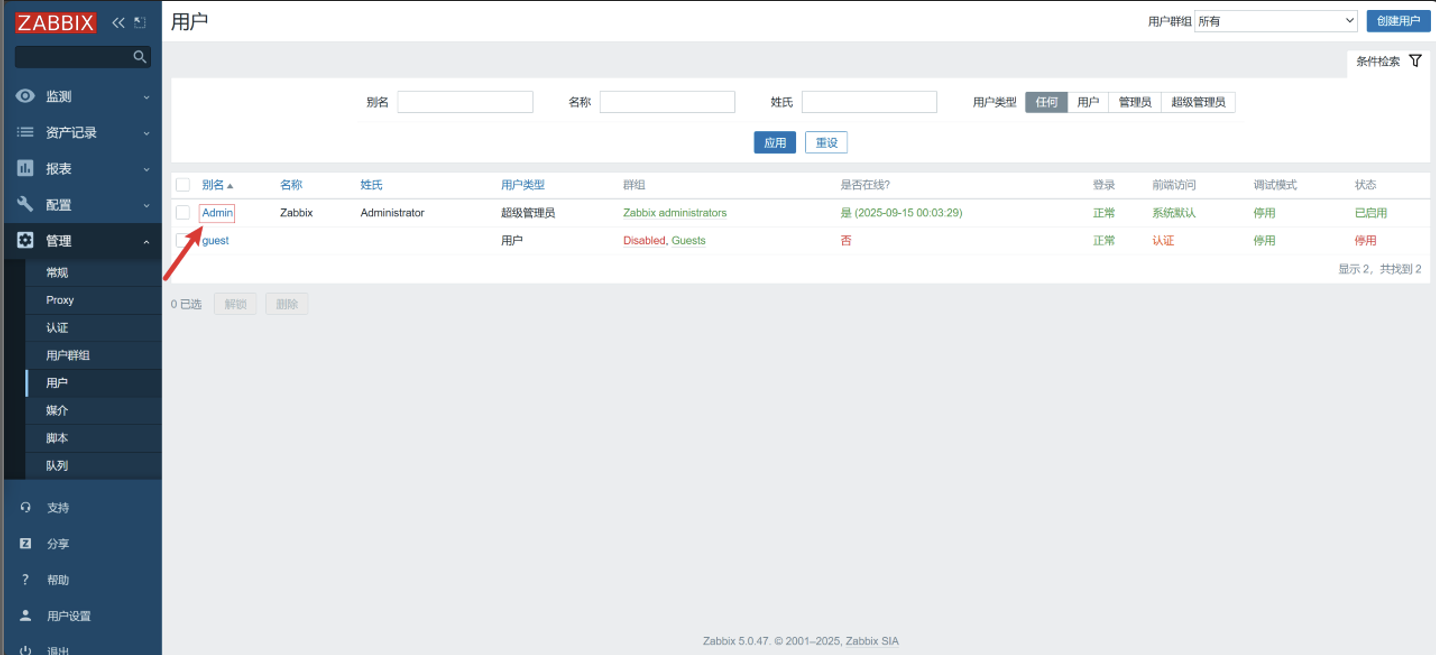
-
点击报警媒介
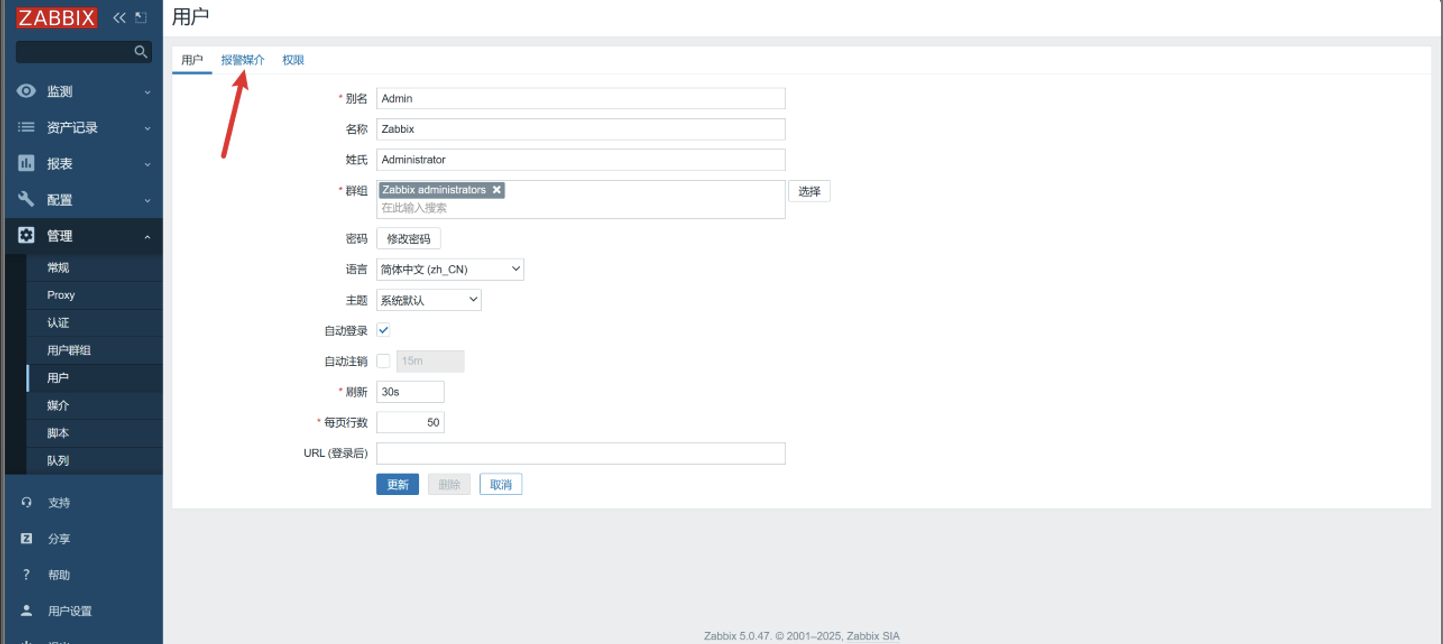
-
点击添加
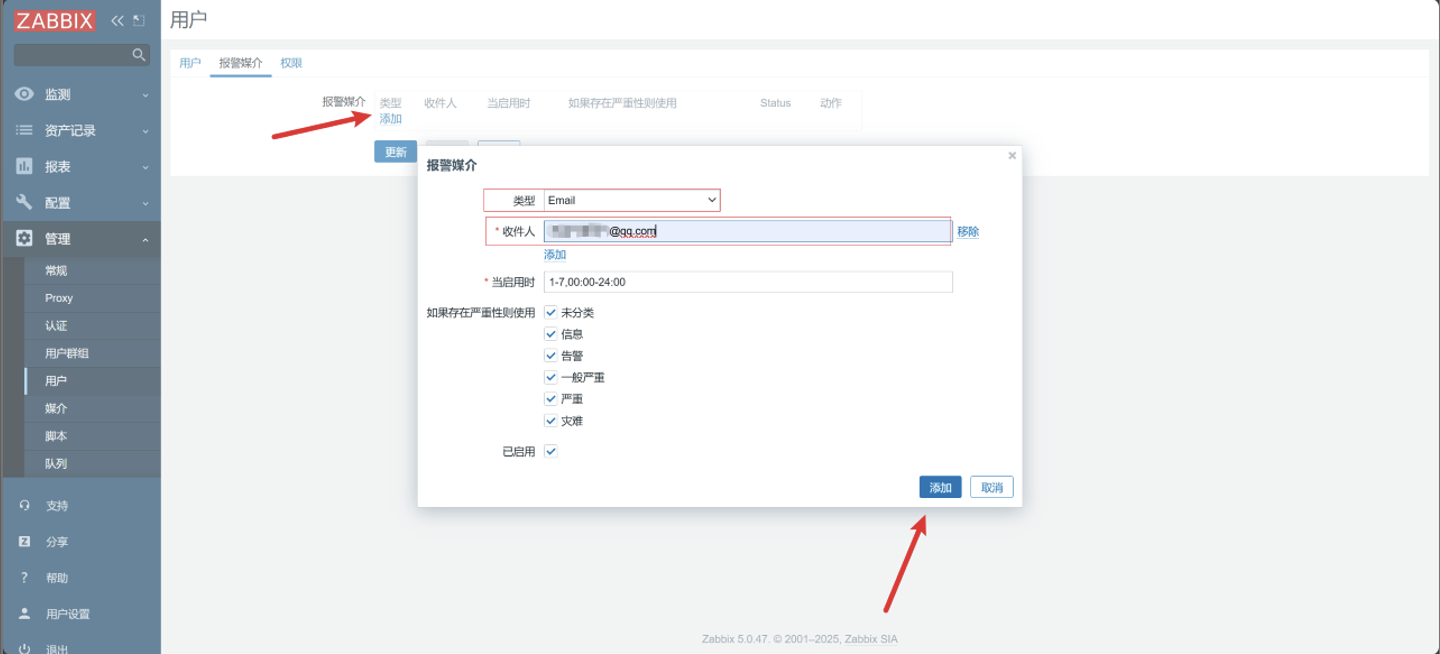
-
查看
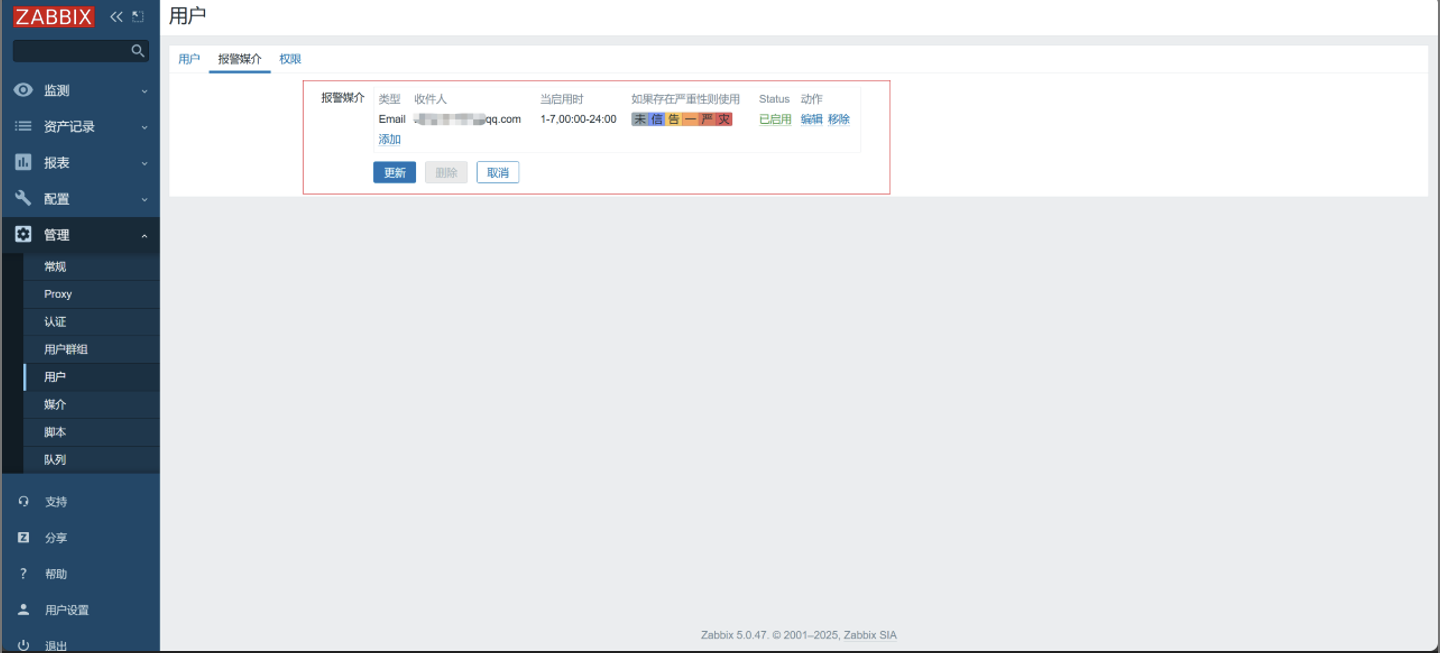
9. 测试
-
关闭 HDFS
[root@hadoop102 hadoop-3.1.3]# ./sbin/stop-dfs.sh -
查看
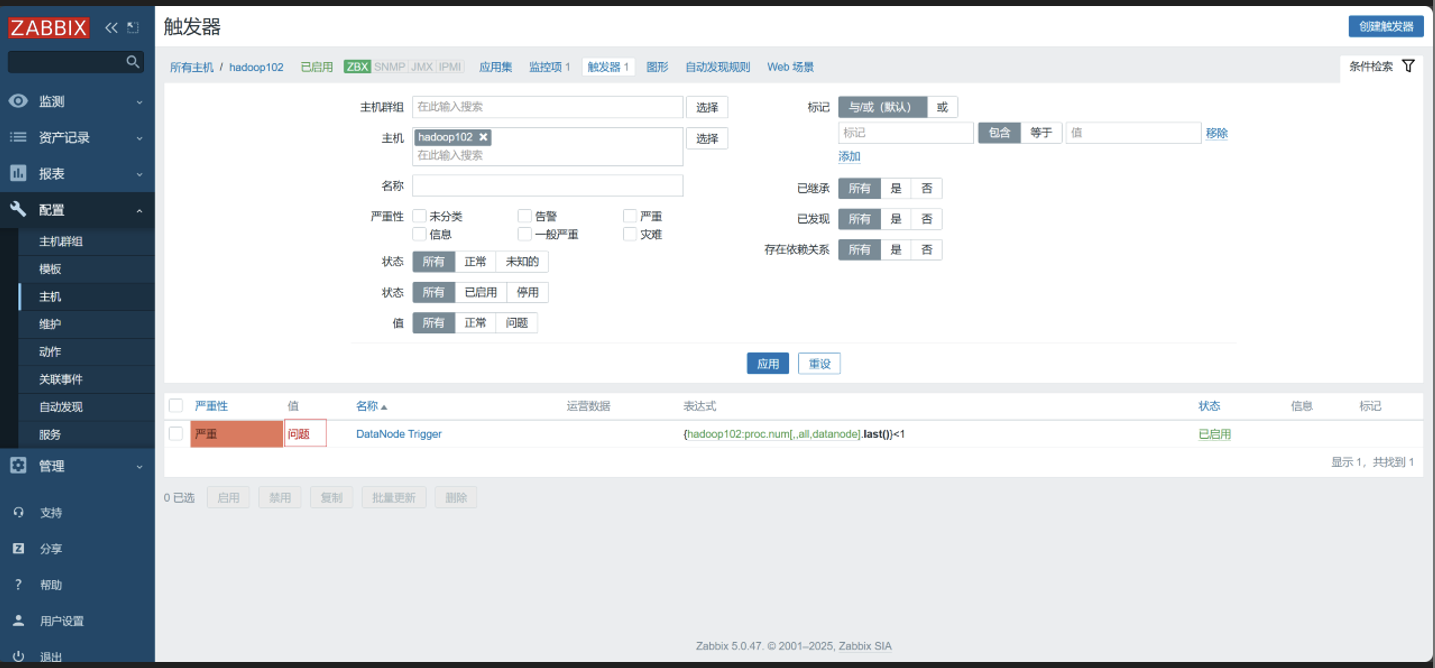
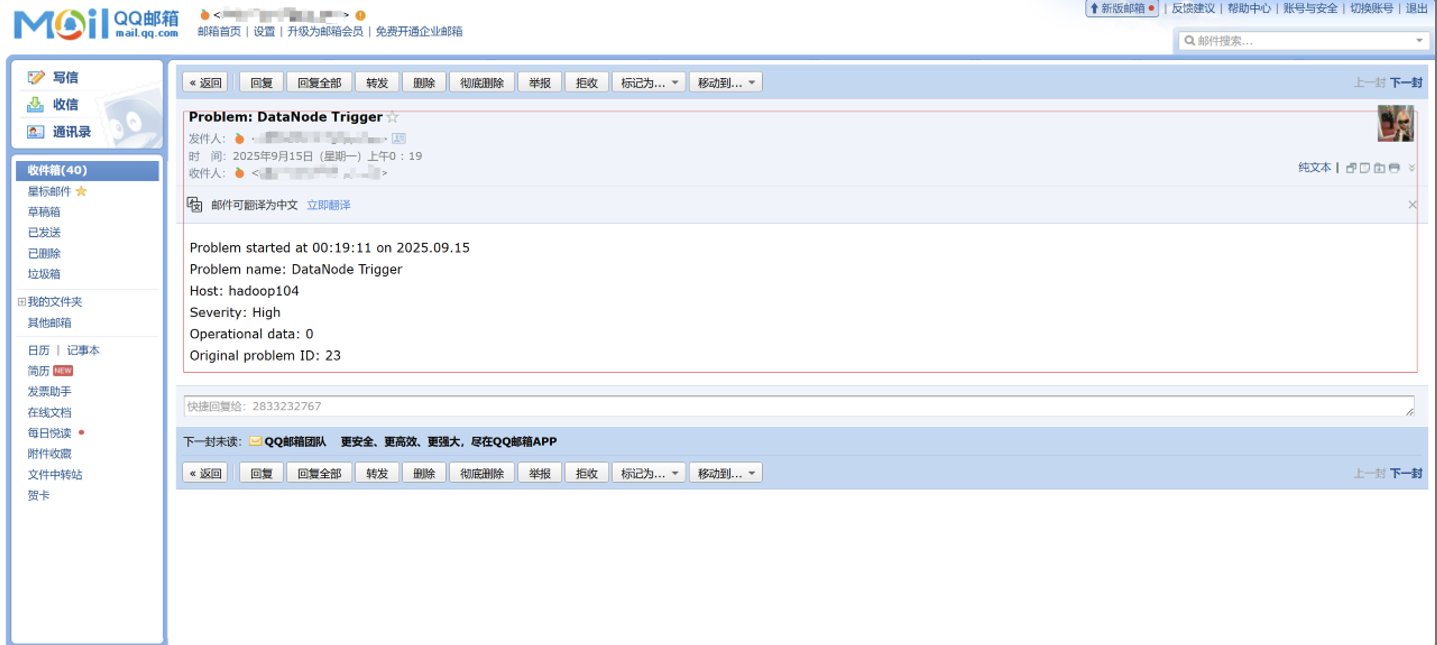
总结
本篇文章全面介绍了Zabbix企业级监控系统的核心概念、部署方法和实战应用。通过搭建三节点集群和配置HDFS监控案例,展示了Zabbix在传统IT基础设施监控中的强大能力:
✅ 核心优势:功能全面、历史悠久、社区支持好,适合传统企业环境
✅ 监控流程:主机→监控项→触发器→动作的完整监控流水线
✅ 报警集成:支持多种报警方式,本文详细演示了邮件报警配置
✅ 实战价值:通过HDFS监控案例,可扩展到其他服务监控场景
Zabbix作为成熟的企业级监控解决方案,在传统IT环境中仍然具有不可替代的价值,特别适合需要对服务器、网络设备、数据库等进行全面监控的企业环境。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)