稠密模型 和稀疏模型一文解答
稠密模型与稀疏模型的核心区别在于参数激活方式:稠密模型每次计算激活全部参数(如BERT、GPT-3),适合资源受限场景;稀疏模型(如MoE架构的Mixtral 8x7B)则按需激活部分参数,能高效扩展至万亿规模,但需更高显存。稠密模型优势是低延迟和易部署(≤70B参数),而稀疏模型适合追求极致性能的超大模型(≥100B参数),以更低计算成本获得更强能力。技术选型需权衡硬件资源、延迟需求与模型性能目
·
我们来详细解析稠密模型 和稀疏模型 的定义、核心区别以及各自的适用场景。这是理解现代大语言模型(尤其是像Mixtral、DeepSeek-V2这类模型)的关键。
一、定义
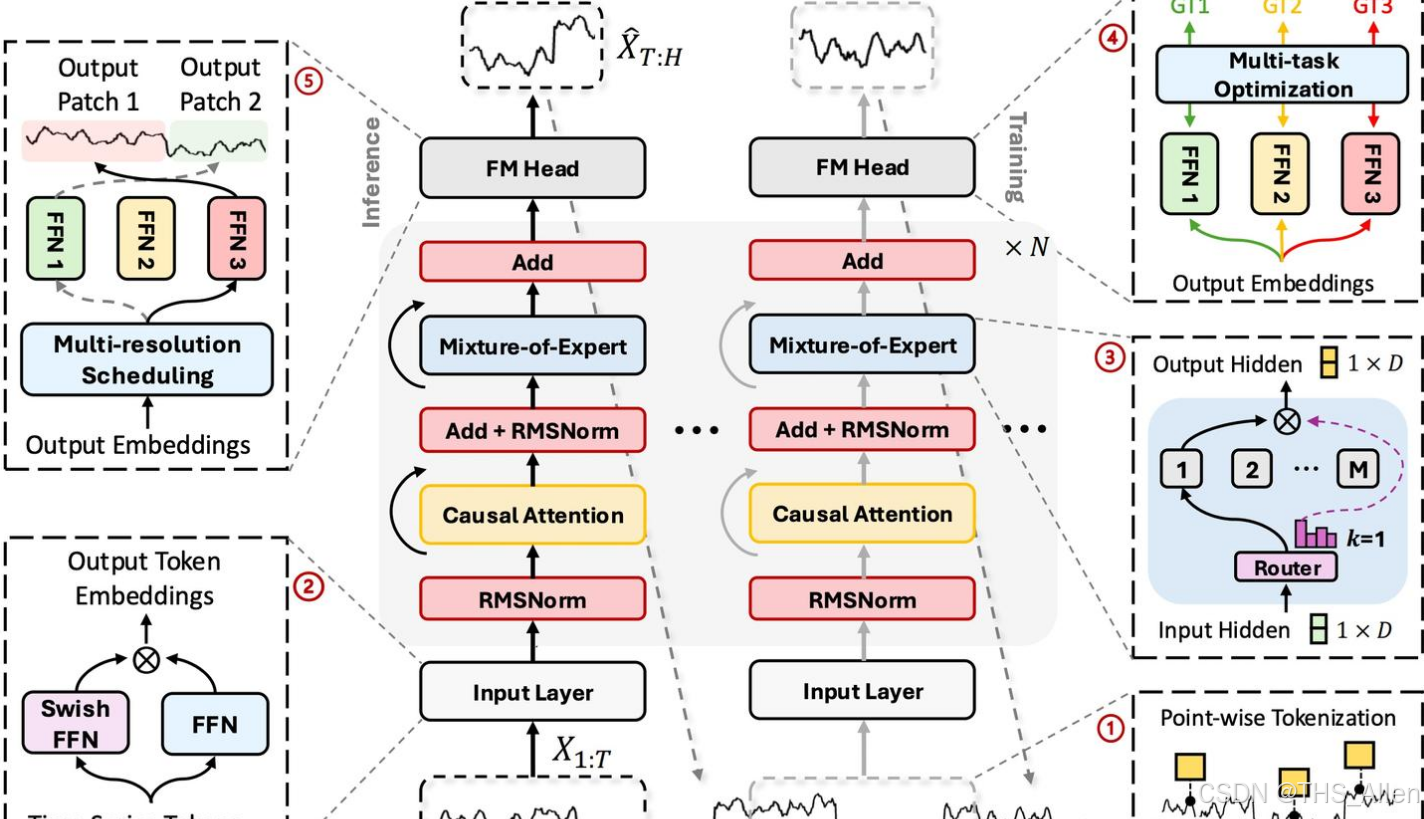
1. 稠密模型
- 定义:在稠密模型中,整个网络的每一个参数都会参与对每一个输入数据的计算。
- 核心特征:是一种“全员上岗”的模式。模型的全部知识分布式地存储在所有的权重中,每次前向传播都会激活整个网络。
- 类比:就像一个全能的天才,无论你问他什么问题(数学、文学、历史),他都需要动用自己全部的脑力来思考和解答。
- 经典代表:
- BERT、早期的GPT(如GPT-2, GPT-3)
- Llama 2(7B, 13B, 70B等非MoE版本)
- ResNet、VGG(计算机视觉领域)
2. 稀疏模型
- 定义:在稀疏模型中,对于每一个输入数据,只激活和使用整个网络中的一部分参数,其他参数则处于“休眠”状态。
- 核心特征:是一种“按需调用”的模式。模型的知识被模块化地存储在不同的子网络中,路由机制会根据输入决定调用哪些子网络。
- 类比:就像一个专家团队,团队里有数学家、文学家、历史学家等。当你提出一个问题时,一个智能路由会先判断问题类型,然后只叫醒最相关的一两位专家来解答,其他专家继续休息。
- 核心实现技术:混合专家系统(Mixture of Experts, MoE)。
- 著名代表:
- Switch Transformer(Google)
- Mixtral 8x7B(Mistral AI):总参数量约46.7B,但每次推理只激活12.9B参数。
- DeepSeek-V2:采用MLA架构,将MoE同时用于FFN和Attention层。
- Grok-1(xAI)
二、核心区别对比
为了更直观地理解,我们通过一个表格来对比它们的核心特性:
| 特性维度 | 稠密模型 | 稀疏模型 (以MoE为例) |
|---|---|---|
| 参数使用方式 | 全部激活 | 条件激活(每次只激活一部分专家) |
| 总参数量 | 相对较小 | 可以极其巨大(如万亿参数) |
| 激活参数量 | 等于总参数量 | 远小于总参数量(如1T总参数,只激活20B) |
| 计算成本 (FLOPs) | 高(与总参数量成正比) | 低(只与激活的参数量成正比) |
| 显存占用 | 相对较低(只需加载一份参数) | 极高(必须将所有专家参数全部加载到显存中,尽管不用) |
| 知识存储 | 分布式(知识混合在所有参数中) | 模块化(知识更集中地存储在特定专家中) |
| 训练稳定性 | 相对简单、稳定 | 更复杂,需要负载均衡防止专家极化 |
| 通信开销 | 低(通常在单设备或纯数据并行下) | 高(在模型并行下,Token需要在专家间路由,需要NVLink/IB等高速互联) |
| 可解释性 | 难以解释特定参数的作用 | 稍好,可尝试分析不同专家的“擅长领域” |
| 典型代表 | GPT-3, Llama 2, ResNet | Mixtral 8x7B, DeepSeek-V2, Switch Transformer |
三、适用场景
稠密模型的适用场景
-
资源受限的边缘设备:
- 场景:手机、嵌入式设备、IoT设备。
- 原因:显存有限,无法承载巨大的MoE模型参数。稠密小模型(如1B-7B参数)是更现实的选择。
-
低延迟、高吞吐量的推理服务:
- 场景:对响应速度要求极高的在线服务,如实时翻译、聊天机器人。
- 原因:虽然MoE计算量小,但其路由决策和专家间通信可能引入额外开销。一个参数更少的稠密模型可能延迟更低、吞吐更高。
-
微调任务:
- 场景:需要针对特定下游任务(如法律、医疗文本)适配模型。
- 原因:稠密模型结构稳定,微调行为更可预测。微调MoE模型容易破坏训练时精心平衡的专家负载。
-
研究和实验:
- 场景:算法开发、模型结构探索。
- 原因:结构简单,训练稳定,更容易调试和收敛。
稀疏模型(MoE)的适用场景
-
超大规模预训练:
- 场景:训练千亿乃至万亿参数的基础大模型。
- 原因:核心优势领域。MoE能以可承受的计算成本,极大地扩展模型的知识容量,从而获得更强大的涌现能力。
-
计算成本敏感的高性能推理:
- 场景:需要运行超大模型(如70B+),但希望控制单次推理的计算成本。
- 原因:用户可以用接近小模型(如13B)的计算开销,获得接近大模型(如70B)的性能表现。例如,Mixtral 8x7B的性能接近Llama 2 70B,但推理速度更快。
-
多模态或混合任务:
- 场景:一个模型需要处理多种不同类型的任务(如文本、代码、图像)。
- 原因:MoE的结构天然适合让不同的专家“专业化”于不同模态或任务,通过路由来组合调用。
-
作为“模型操作系统”:
- 场景:未来可能的发展方向,一个MoE主模型作为调度器,动态调用外部更专业的模型或工具(专家)。
- 原因:其路由机制可以扩展为调用外部API或模型。
四、总结与选型建议
| 选择稠密模型 | 选择稀疏模型 (MoE) | |
|---|---|---|
| 首要考虑因素 | 延迟、显存占用、部署简便性 | 模型能力上限、训练/推理的计算效率 |
| 参数规模 | ≤ 70B | ≥ 100B |
| 硬件资源 | 有限(单卡或边缘设备) | 充沛(多卡集群,且有高速互联) |
| 关键指标 | 响应速度、稳定性 | 模型性能、任务多样性 |
简单来说:
- 如果你的首要目标是低延迟、易部署,且模型大小在70B参数以下,稠密模型是更可靠的选择。
- 如果你追求极致的模型能力,希望以更优的计算效率训练或运行超大规模模型(70B+),并且拥有足够的硬件(尤其是显存),那么稀疏模型(MoE) 是通往更强大AI的必经之路。
MoE技术正在快速发展,随着硬件能力的提升和算法的优化(如更高效的路由、降低显存占用),它正逐渐从“尖端技术”走向“主流应用”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)