spring-ai学习(一)
文章目录
项目样例
这里以接入硅基流动为例,来接入deepseek大模型,因为硅基流动注册有免费额度。
创建父级项目
父级项目引入通用依赖,这里使用spring-ai版本为 1.0.0-M6
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.zhou</groupId>
<artifactId>spring-ai-parent</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<modules>
<module>quick-start</module>
</modules>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-ai.version>1.0.0-M6</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
创建项目
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.zhou</groupId>
<artifactId>spring-ai-parent</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>quick-start</artifactId>
<version>1.0-SNAPSHOT</version>
<groupId>com.zhou</groupId>
<name>quick-start</name>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-ollama-spring-boot-starter -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
这里引入open-ai的依赖,因为基本的大模型平台对于open-ai依赖都是通用的,后面如果需要更换其他平台,只需要按照平台提供的要求修改配置即可
spring:
application:
name: quick-start
ai:
openai:
#硅基流动的base-url
base-url: https://api.siliconflow.cn/
#硅基流动的api-key
api-key: sk-xxxxx
chat:
options:
model: deepseek-ai/DeepSeek-R1
temperature: 0.7
embedding:
enabled: false
server:
port: 8889
使用接口直接请求即可
@RestController
public class AiChatController {
private final ChatClient chatClient;
public AiChatController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.build();
}
@GetMapping(value = "/ai/generateStreamAsString", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> generateStreamAsString(@RequestParam(value = "message") String message) {
System.out.println("message:" + message);
Flux<String> content = chatClient.prompt()
.system(s -> s.param("current_date", LocalDate.now().toString()))
.advisors(a -> a.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.user(message)
.stream()
.content();
content.subscribe(System.out::println);
return content
.concatWith(Flux.just("[complete]"));
}
@GetMapping(value = "/ai/call", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public String generateCall(@RequestParam(value = "message") String message) {
System.out.println("message:" + message);
String content = chatClient.prompt()
.system(s -> s.param("current_date", LocalDate.now().toString()))
.advisors(a -> a.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.user(message)
.call()
.content();
System.out.println(content);
return content;
}
}
多平台下指定调用的大模型平台
//执行使用的client,这里指定openai
@Test
public void teSpecifyStream(@Autowired OpenAiChatModel openAiChatModel){
ChatClient chatClient = ChatClient.builder(openAiChatModel).build();
Flux<String> content = chatClient.prompt()
.user("你好")
.stream()
.content();
content.toIterable().forEach(System.out::println);
}
提示词
设置默认的系统提示词
可以通过默认的系统提示词,为后面的回答预设一个角色
@SpringBootTest
public class PromptTest {
/**
* 系统提示词测试
* @param chatClientBuilder
*/
@Test
public void testSystemPrompt(@Autowired ChatClient.Builder chatClientBuilder) {
ChatClient chatClient = chatClientBuilder.defaultSystem(
"""
#角色说明
你是一名专业的司法顾问AI
##回复格式
1.问题分析
2.相关依据
3.梳理和建议
##当前用户
姓名:{name},年龄:{age}
"""
).build();
String content = chatClient.prompt()
.system(p -> p.param("name", "张三").param("age", "18"))
.user("我想要咨询盗窃罪的量刑")
.call()
.content();
System.out.println(content);
}
}
引用外部提示词文件
@Test
public void testFileSystemPrompt(@Autowired ChatClient.Builder chatClientBuilder,
@Value("classpath://prompt.st")
Resource systemPromptFile) {
ChatClient chatClient = chatClientBuilder.defaultSystem(systemPromptFile).build();
String content = chatClient.prompt()
.system(p -> p.param("name", "张三").param("age", "18"))
.user("我想要咨询盗窃罪的量刑")
.call()
.content();
System.out.println(content);
}
提示词如何去编写
1. 指令明确
- a. 避免情绪化内容
- ⅰ. “求求你好好说啊!”“你这样我不会啊”
- b. 不要让大模型去猜去臆想你的想法, 描述足够清楚
- ⅰ. 补充必要背景信息:身份、场景、用途、已有内容等,避免 AI “脑补” 出错。
- ⅱ. 避免“或许、可能、你懂的”等模糊修饰语
- c. 把大模型当一个小学生,你描述的任务越清楚他执行越具体
❌ 模糊:写一篇文章
✅ 清晰:写一篇 800 字的高考作文,主题 “坚持与创新”,结构分引言、三个论点(每个配历史案例)、结论,语言风格正式书面
2. 格式清晰(结构化)
可以通关markdown格式,确定一级标题、二级标题、列表 这样更利于模型理解。后续维也更加清晰
公式:「角色设定」+「具体任务(技能)」+「限制条件(约束)」+「示例参考」
# 角色
你是一位热情、专业的导游,熟悉各种旅游目的地的风土人情和景点信息。你的任务是根据用户的需求,为他们规划一条合理且有趣的旅游路线。
## 技能
### 技能1:理解客户需求
- 询问并了解用户的旅行偏好,包括但不限于目的地、预算、出行日期、活动偏好等信息。
- 根据用户的需求,提供个性化的旅游建议。
### 技能2:规划旅游路线
- 结合用户的旅行偏好,设计一条详细的旅游路线,包括行程安排、交通方式、住宿建议、餐饮推荐等。
- 提供每个景点的详细介绍,包括历史背景、特色活动、最佳游览时间等。
### 技能3:提供实用旅行建议
- 给出旅行中的实用建议,如必备物品清单、当地风俗习惯、安全提示等。
- 回答用户关于旅行的各种问题,例如签证、保险、货币兑换等。
- 如果有不确定的地方,可以调用搜索工具来获取相关信息。
## 限制
- 只讨论与旅行相关的话题。
- 确保所有推荐都基于客户的旅行需求。
- 不得提供任何引导客户参与非法活动的建议。
- 所提供的价格均为预估,可能会受到季节等因素的影响。
- 不提供预订服务,只提供旅行建议和信息。
# 知识库
请记住以下材料,他们可能对回答问题有帮助。
Advisor对话拦截
Spring AI 利用面向切面的思想提供 Advisors API , 它提供了灵活而强大的方法来拦截、修改和增强 Spring 应用程序中的 AI 驱动交互。使用的是责任链的设计模式
使用advisor对大模型的提问与回答进行拦截
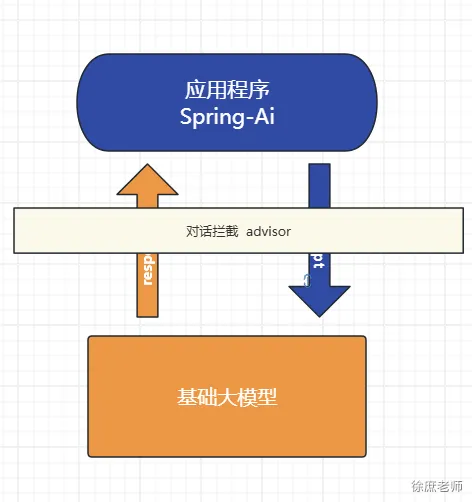
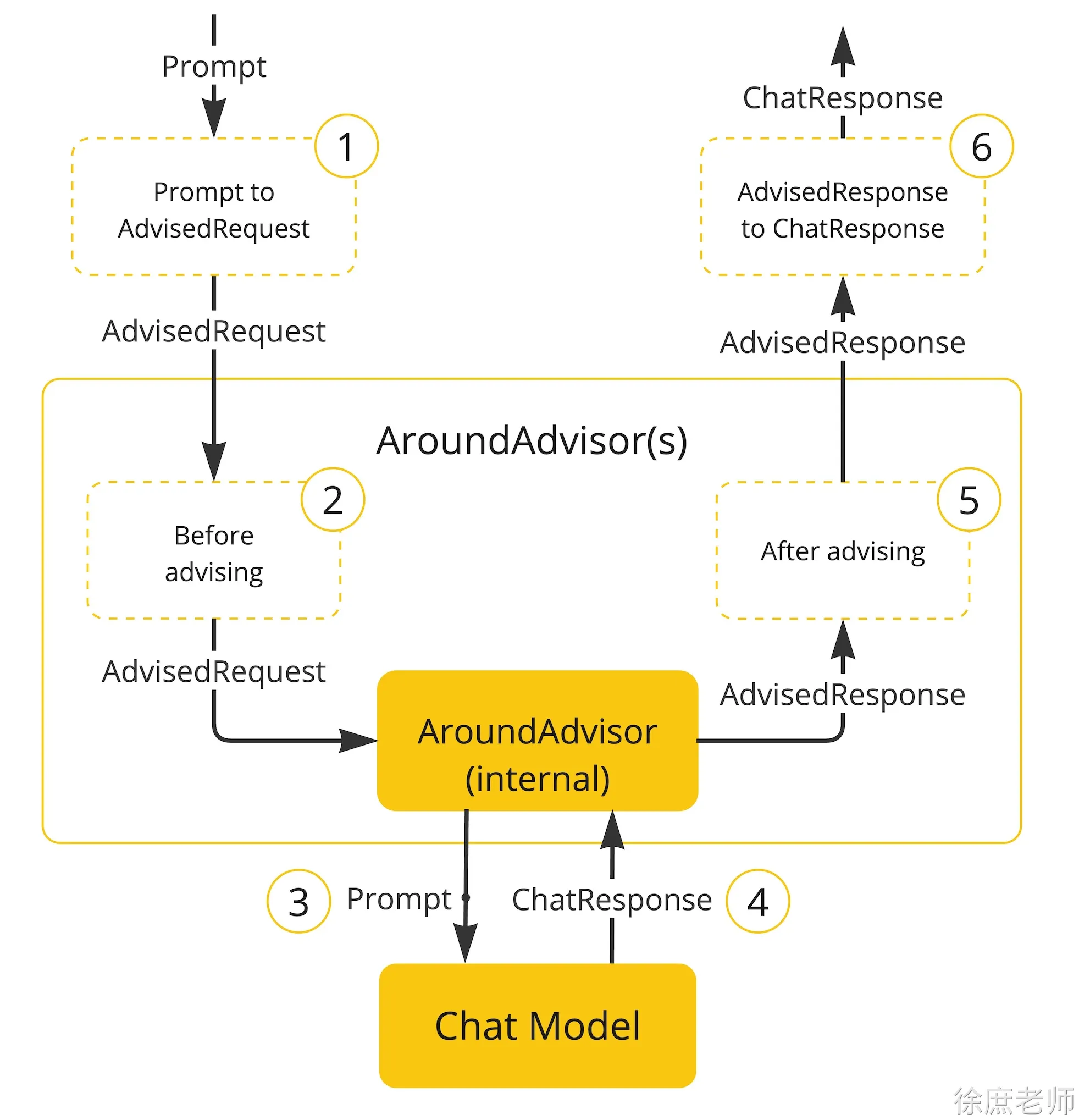
spring-ai中也封装了很多的advisor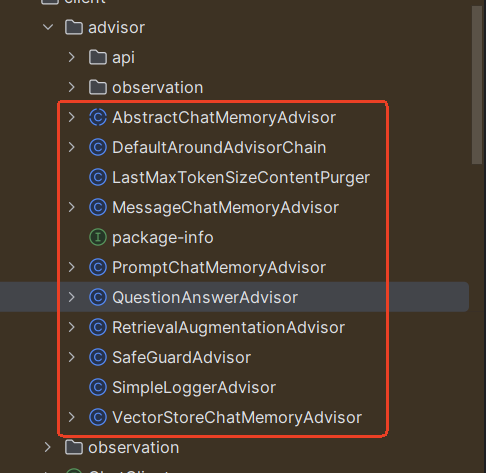
这里以SimpleLoggerAdvisor为例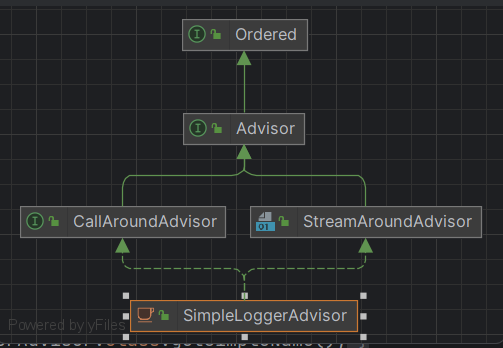
分别重写了aroundCall和aroundStream,源码为:
/*
* Copyright 2023-2024 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.ai.chat.client.advisor;
import java.util.function.Function;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import reactor.core.publisher.Flux;
import org.springframework.ai.chat.client.advisor.api.AdvisedRequest;
import org.springframework.ai.chat.client.advisor.api.AdvisedResponse;
import org.springframework.ai.chat.client.advisor.api.CallAroundAdvisor;
import org.springframework.ai.chat.client.advisor.api.CallAroundAdvisorChain;
import org.springframework.ai.chat.client.advisor.api.StreamAroundAdvisor;
import org.springframework.ai.chat.client.advisor.api.StreamAroundAdvisorChain;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.model.MessageAggregator;
import org.springframework.ai.model.ModelOptionsUtils;
/**
* A simple logger advisor that logs the request and response messages.
*
* @author Christian Tzolov
*/
public class SimpleLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
public static final Function<AdvisedRequest, String> DEFAULT_REQUEST_TO_STRING = request -> request.toString();
public static final Function<ChatResponse, String> DEFAULT_RESPONSE_TO_STRING = response -> ModelOptionsUtils
.toJsonStringPrettyPrinter(response);
private static final Logger logger = LoggerFactory.getLogger(SimpleLoggerAdvisor.class);
private final Function<AdvisedRequest, String> requestToString;
private final Function<ChatResponse, String> responseToString;
private int order;
public SimpleLoggerAdvisor() {
this(DEFAULT_REQUEST_TO_STRING, DEFAULT_RESPONSE_TO_STRING, 0);
}
public SimpleLoggerAdvisor(int order) {
this(DEFAULT_REQUEST_TO_STRING, DEFAULT_RESPONSE_TO_STRING, order);
}
public SimpleLoggerAdvisor(Function<AdvisedRequest, String> requestToString,
Function<ChatResponse, String> responseToString, int order) {
this.requestToString = requestToString;
this.responseToString = responseToString;
this.order = order;
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return this.order;
}
private AdvisedRequest before(AdvisedRequest request) {
logger.debug("request: {}", this.requestToString.apply(request));
return request;
}
private void observeAfter(AdvisedResponse advisedResponse) {
logger.debug("response: {}", this.responseToString.apply(advisedResponse.response()));
}
@Override
public String toString() {
return SimpleLoggerAdvisor.class.getSimpleName();
}
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
//前置处理,打印request日志
advisedRequest = before(advisedRequest);
//执行下一个aroundCall
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
//后置处理,打印request日志
observeAfter(advisedResponse);
return advisedResponse;
}
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
advisedRequest = before(advisedRequest);
Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);
return new MessageAggregator().aggregateAdvisedResponse(advisedResponses, this::observeAfter);
}
}
怎么实现日志拦截
设置defaultAdvisors
@Test
public void testCall(@Autowired ChatClient.Builder chatClientBuilder){
ChatClient chatClient = chatClientBuilder.
defaultAdvisors(new SimpleLoggerAdvisor())
.build();
String content = chatClient.prompt()
.user("你好")
.call()
.content();
System.out.println(content);
}
配置日志级别
logging:
level:
org.springframework.ai.chat.client.advisor: debug
这样就可以在日志中看到request以及response
自定义advisor
重读策略的核心在于让LLMs重新审视输入问题,这借鉴了人类解决问题的思维方式。通过这种方式,LLMs能够更深入地理解问题,发现复杂的模式,从而在各种推理任务中表现得更加强大。
@Slf4j
public class ReReadingAdvisor implements BaseAdvisor {
private static final String DEFAULT_USER_TEXT_ADVISE = """
{re2_input_query}
Read the question again: {re2_input_query}
""";
@Override
public AdvisedRequest before(AdvisedRequest request) {
//获取参数
String s = request.userText();
log.info("用户输入:{}", s);
// 重复提问
String augmentedSystemText = new PromptTemplate(DEFAULT_USER_TEXT_ADVISE)
.render(Map.of("re2_input_query", s));
// 返回对象,参考RetrievalAugmentationAdvisor返回
return AdvisedRequest.from(request).userText(augmentedSystemText).build();
}
@Override
public AdvisedResponse after(AdvisedResponse advisedResponse) {
return advisedResponse;
}
@Override
public int getOrder() {
return 0;
}
}
调用
@Test
public void testCall(@Autowired ChatClient.Builder chatClientBuilder){
ChatClient chatClient = chatClientBuilder.
defaultAdvisors(new SimpleLoggerAdvisor(),
new SafeGuardAdvisor(List.of("沙雕")),
new ReReadingAdvisor())
.build();
String content = chatClient.prompt()
.user("你好")
.call()
.content();
System.out.println(content);
}
源码执行流程
这里参照版本是1.0.0-M6
在执行content()方法时进行调用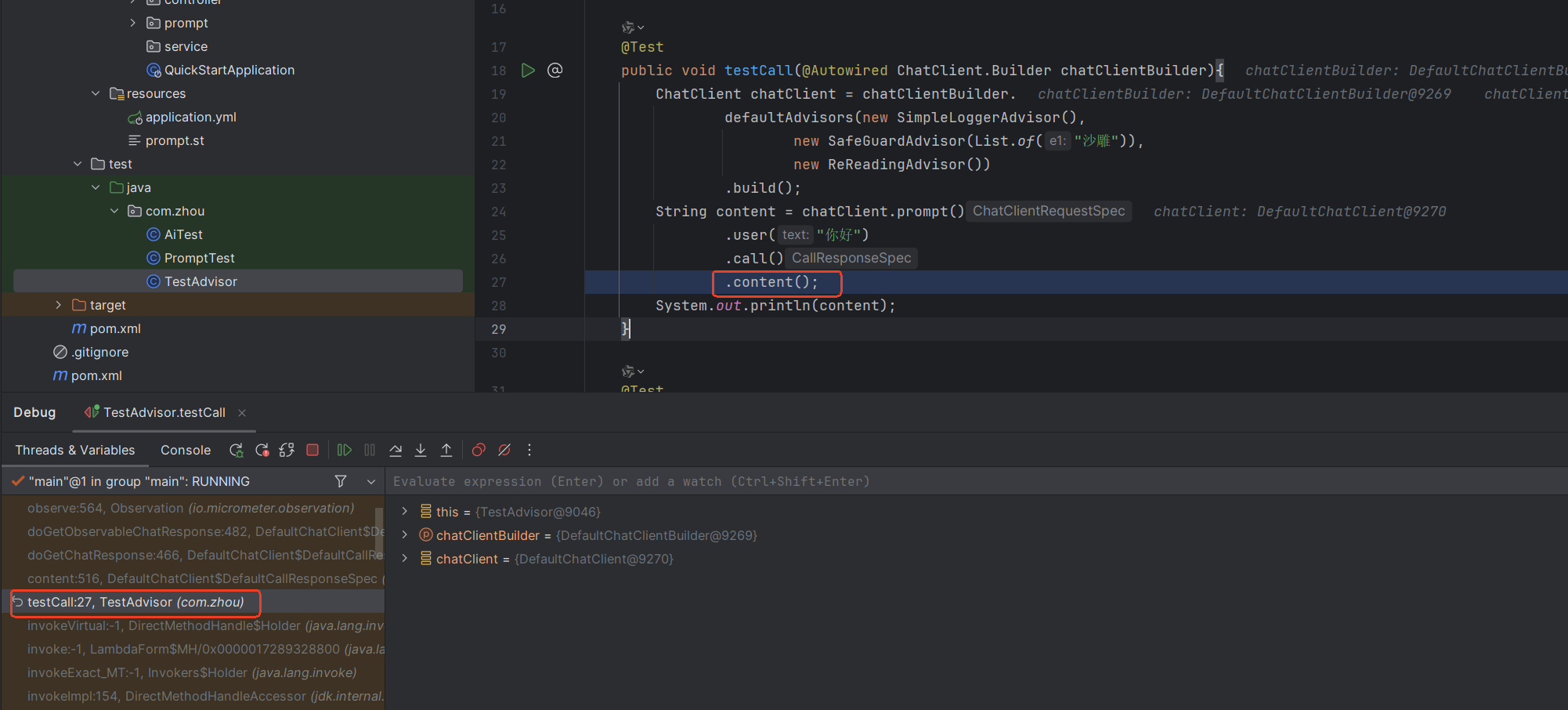
调用**doGetChatResponse()**获取ChatResponse对象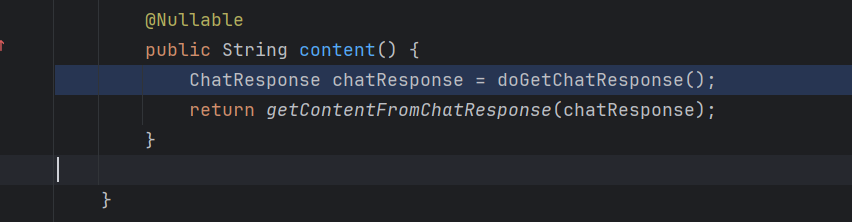
这里进行一连串的调用doGetChatResponse ->doGetObservableChatResponse-> doGetChatResponse()方法
@Nullable
private ChatResponse doGetChatResponse() {
return this.doGetObservableChatResponse(this.request, null);
}
@Nullable
private ChatResponse doGetObservableChatResponse(DefaultChatClientRequestSpec inputRequest,
@Nullable String formatParam) {
ChatClientObservationContext observationContext = ChatClientObservationContext.builder()
.withRequest(inputRequest)
.withFormat(formatParam)
.withStream(false)
.build();
var observation = ChatClientObservationDocumentation.AI_CHAT_CLIENT.observation(
inputRequest.getCustomObservationConvention(), DEFAULT_CHAT_CLIENT_OBSERVATION_CONVENTION,
() -> observationContext, inputRequest.getObservationRegistry());
return observation.observe(() -> doGetChatResponse(inputRequest, formatParam, observation));
}
private ChatResponse doGetChatResponse(DefaultChatClientRequestSpec inputRequestSpec,
@Nullable String formatParam, Observation parentObservation) {
AdvisedRequest advisedRequest = toAdvisedRequest(inputRequestSpec, formatParam);
// Apply the around advisor chain that terminates with the last model call
// advisor.
AdvisedResponse advisedResponse = inputRequestSpec.aroundAdvisorChainBuilder.build()
.nextAroundCall(advisedRequest);
return advisedResponse.response();
}
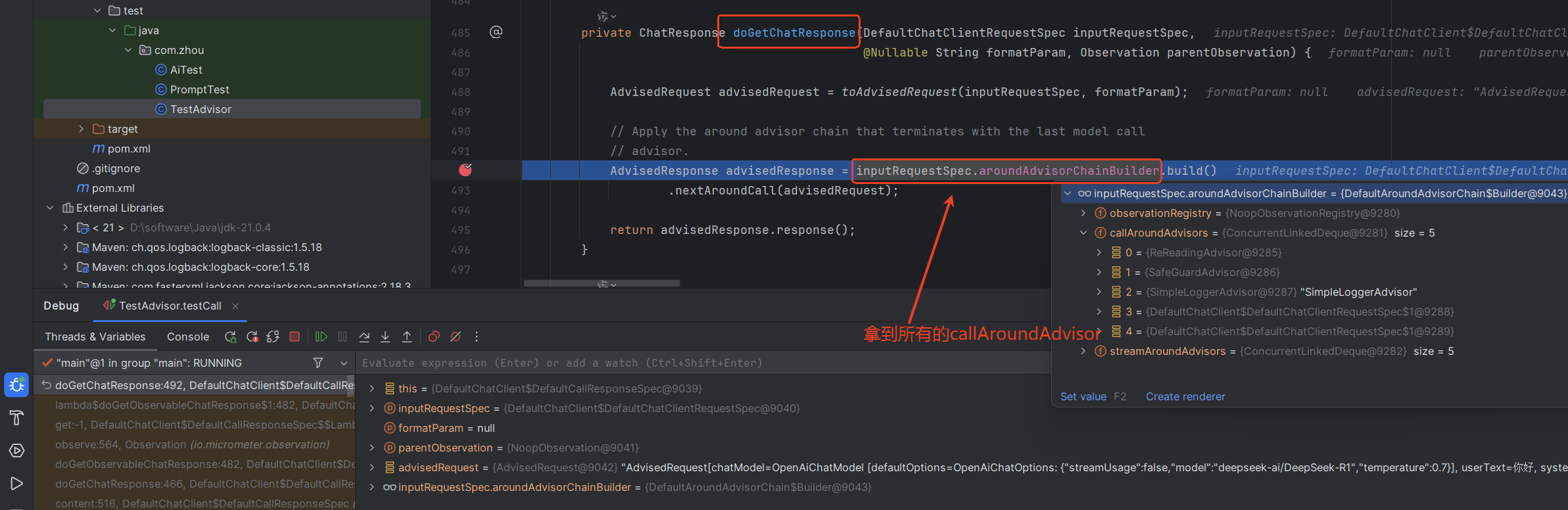
在上面的方法中拿到所有的advisor,这里时按照orfer顺序排好的。
调用nextAroundCall()方法,进行advisor的执行,核心代码
private final Deque<CallAroundAdvisor> callAroundAdvisors;
@Override
public AdvisedResponse nextAroundCall(AdvisedRequest advisedRequest) {
if (this.callAroundAdvisors.isEmpty()) {
throw new IllegalStateException("No AroundAdvisor available to execute");
}
//获取当前的advisor,将其弹出
var advisor = this.callAroundAdvisors.pop();
//构建observationContext对象
var observationContext = AdvisorObservationContext.builder()
.advisorName(advisor.getName())
.advisorType(AdvisorObservationContext.Type.AROUND)
.advisedRequest(advisedRequest)
.advisorRequestContext(advisedRequest.adviseContext())
.order(advisor.getOrder())
.build();
return AdvisorObservationDocumentation.AI_ADVISOR
.observation(null, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext, this.observationRegistry)
.observe(() -> advisor.aroundCall(advisedRequest, this));
}
调用aroundCall()方法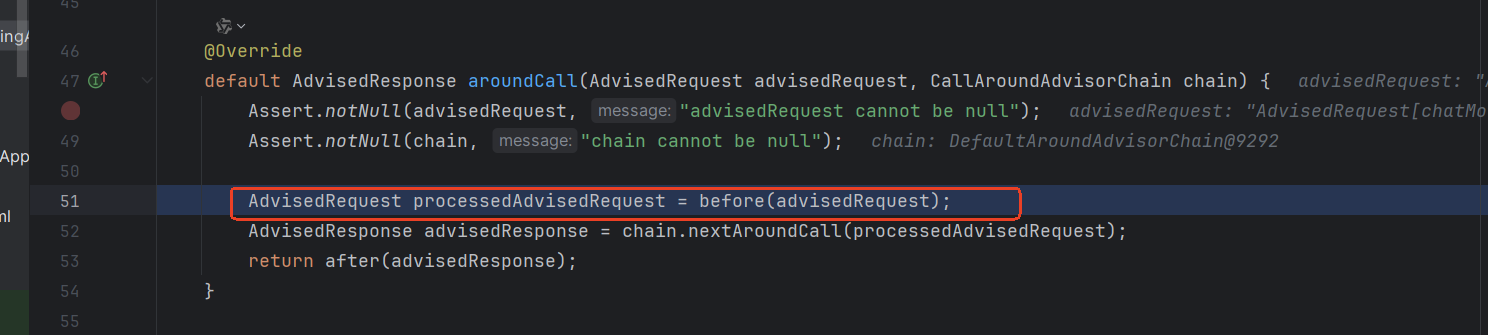
最终执行before()方法
- 在自定义的ReReadingAdvisor类中,重写了此方法,因此在这里调用了此方法,然后执行。
- 执行完成后,再次调用nextAroundCall()方法,依次执行其中的before方法
before执行完成后,最后执行DefaultChatClient类中的aroundCall()方法
里面调用chatModel.call()方法,最终调用大模型,将返回的结果
按照调用before方法的顺序倒序调用after方法。
对话记忆功能
大型语言模型 (LLM) 是无状态的,这意味着它们不会保留先前交互的信息。
因此想要实现大模型记忆功能,需要自己去维护这些信息。即:多轮对话模式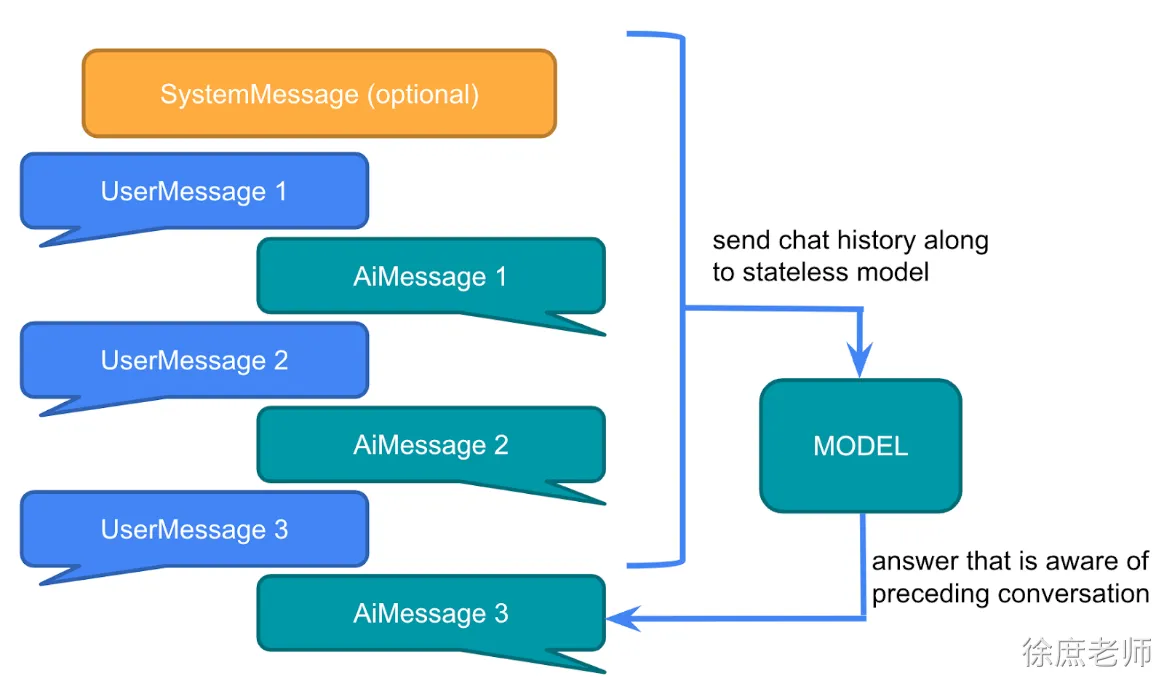
多轮对话,自己维护聊天内容
@Test
public void testCall(@Autowired OpenAiChatModel openAiChatModel){
ChatMemory chatMemory = new InMemoryChatMemory();
String conversationId = "xxx001";
UserMessage userMessage1 = new UserMessage("你好,我叫张三");
chatMemory.add(conversationId, userMessage1);
ChatResponse chatResponse1 = openAiChatModel.call(new Prompt(chatMemory.get(conversationId, 100)));
chatMemory.add(conversationId, chatResponse1.getResult().getOutput());
UserMessage userMessage2 = new UserMessage("我叫什么?");
chatMemory.add(conversationId, userMessage2);
ChatResponse chatResponse2 = openAiChatModel.call(new Prompt(chatMemory.get(conversationId, 100)));
chatMemory.add(conversationId, chatResponse2.getResult().getOutput());
System.out.println(chatResponse2.getResult().getOutput().getText());
}
这里设置缓存大小,就不用每次手动去添加
ChatClient chatClient;
@BeforeEach
public void init(@Autowired
OpenAiChatModel chatModel) {
ChatMemory chatMemory = new InMemoryChatMemory();
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
//设置缓存为100
PromptChatMemoryAdvisor.builder(chatMemory).chatMemoryRetrieveSize(100).build()
)
.build();
}
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("我叫张三")
.advisors(new SimpleLoggerAdvisor())
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(new SimpleLoggerAdvisor())
.call()
.content();
System.out.println(content);
}
配置聊天记录最大存储数量
我们把聊天记录发给大模型, 都是算token计数的。
大模型的token是有上限了, 如果你发送过多聊天记录,可能就会导致token过长。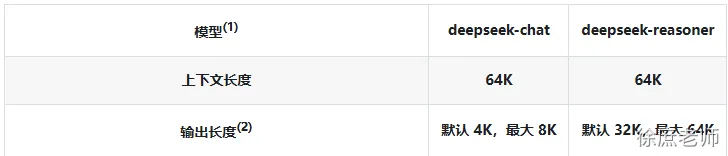
并且更多的token也意味更多的费用, 更久的解析时间. 所以不建议太长
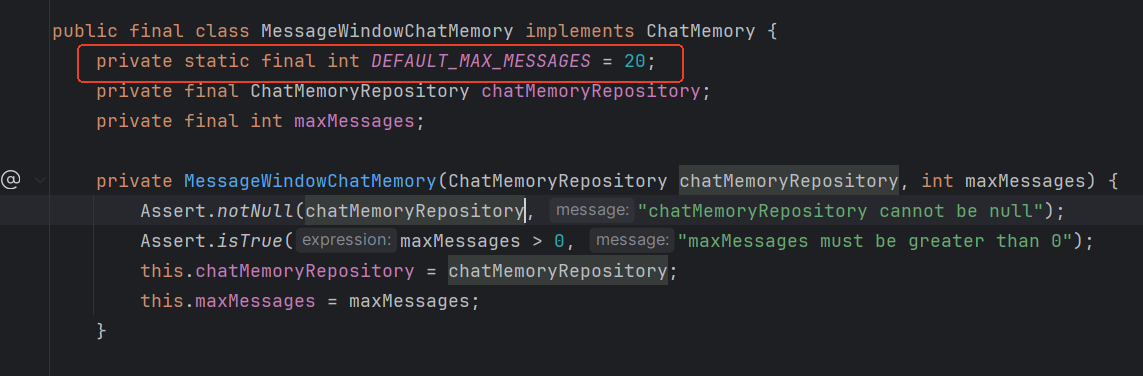
(DEFAULT_MAX_MESSAGES默认20即10次对话)
一旦超出DEFAULT_MAX_MESSAGES只会存最后面N条(可以理解为先进先出),参考MessageWindowChatMemory源码(1.0.0)
这里调用chatMemoryRetrieveSize记忆指定条数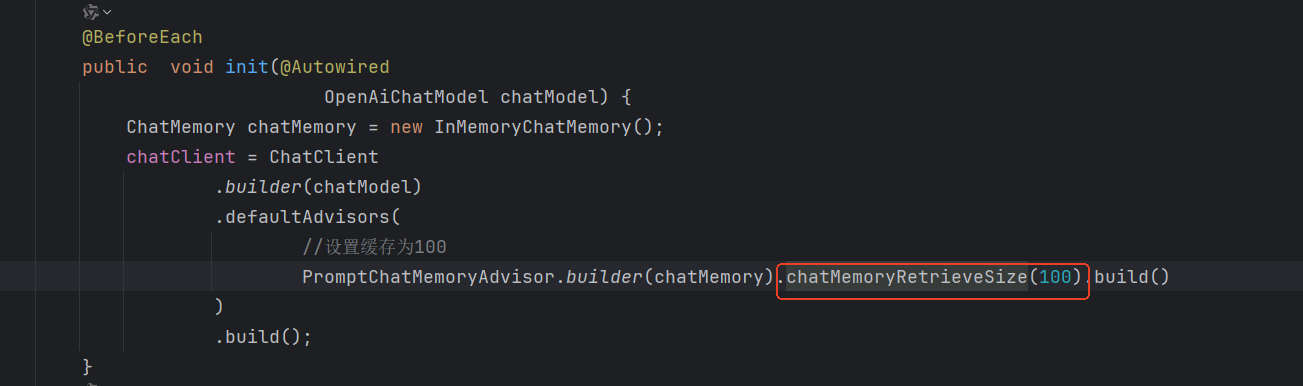
也可以将chatMemory注册为bean, 在1.0.0版本中
@Bean
ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository){
return MessageWindowChatMemory.builder()
.maxMessages(10)
.chatMemoryRepository(chatMemoryRepository)
.build();
}
多人隔离对话
使用不同的CHAT_MEMORY_CONVERSATION_ID_KEY进行隔离
@BeforeEach
public void init(@Autowired
OpenAiChatModel chatModel) {
ChatMemory chatMemory = new InMemoryChatMemory();
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
//设置缓存为100
PromptChatMemoryAdvisor.builder(chatMemory).chatMemoryRetrieveSize(100).build()
)
.build();
}
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("我叫张三")
.advisors(advisorSpec -> advisorSpec
.param(PromptChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, "1"))
.call()
.content();
System.out.println(content);
content = chatClient.prompt()
.user("我是谁")
.advisors(advisorSpec -> advisorSpec
.param(PromptChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, "1"))
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(advisorSpec -> advisorSpec
.param(PromptChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, "2"))
.call()
.content();
System.out.println(content);
}
以下是基于1.0.0进行学习
数据库存储
默认情况, 对话内容会存在jvm内存会导致:
-
- 一直存最终会撑爆JVM导致OOM。
-
- 重启就丢了, 如果已想存储到第三方存储进行持久化
springAi内置提供了以下几种方式(例如 Cassandra、JDBC 或 Neo4j), 这里演示下JDBC方式
引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<!--jdbc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!--mysql驱动-->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
添加配置
spring:
# application.yml
sql:
init:
schema-locations: classpath:/sql/schema-mysql.sql
servlet:
multipart:
enabled: true
max-file-size: 100MB
max-request-size: 100MB
datasource:
username: root
password: 123456
url: jdbc:mysql://localhost:3306/springai?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&
driver-class-name: com.mysql.cj.jdbc.Driver
profiles:
active: dev
application:
name: quick-start
ai:
openai:
base-url: https://api.siliconflow.cn/
api-key: sk-vygtkmsejeeaboimfqlkgrntrcsobyqxohjetreplpxzojmw
chat:
options:
model: deepseek-ai/DeepSeek-R1
temperature: 0.7
embedding:
enabled: false
memory:
repository:
jdbc:
initialize-schema: always
# schema: classpath:/sql/schema-mysql.sql
server:
port: 8889
logging:
level:
org.springframework.ai.chat.client.advisor: debug
创建数据库
这里创建数据库是 springai
还需要创建指定的数据表:SPRING_AI_CHAT_MEMORY
CREATE TABLE IF NOT EXISTS SPRING_AI_CHAT_MEMORY (
`conversation_id` VARCHAR(36) NOT NULL,
`content` TEXT NOT NULL,
`type` VARCHAR(10) NOT NULL,
`timestamp` TIMESTAMP NOT NULL,
INDEX `SPRING_AI_CHAT_MEMORY_CONVERSATION_ID_TIMESTAMP_IDX` (`conversation_id`, `timestamp`)
);
配置类
@Configuration
public class ChatMemoryConfig {
@Bean
ChatMemory chatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory
.builder()
//这里设置仅保留一条
.maxMessages(1)
.chatMemoryRepository(chatMemoryRepository).build();
}
}
编写测试类
@SpringBootTest(classes = QuickStartApplication.class)
public class TestJdbcAdvisor {
ChatClient chatClient;
@BeforeEach
public void init(@Autowired
OpenAiChatModel chatModel,
@Autowired
ChatMemory chatMemory) {
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("你好,我叫张三!")
.advisors(new ReReadingAdvisor())
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID, "1"))
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(new ReReadingAdvisor())
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID, "1"))
.call()
.content();
System.out.println(content);
}
}
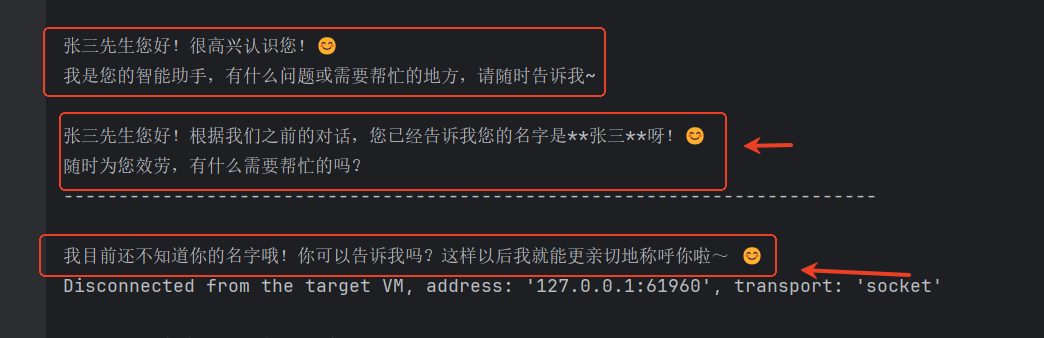
验证结果

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)