【阿里大模型2面】大模型算法面经:损失函数没答上来,复盘!
这是阿里的一份大模型算法面经,可以看到,面试官避开了 rag,agent 这些热门考点,转而对大模型训练中的损失函数进行了深挖,很好的考察到了候选人的基本功。
简介
这是阿里的一份大模型算法面经,可以看到,面试官避开了 rag,agent 这些热门考点,转而对大模型训练中的损失函数进行了深挖,很好的考察到了候选人的基本功。
这篇文章,我们就来挖一挖有关大模型损失函数的高频面试题,如果你在面试中被问到类似问题,应该如何作答?
一、GPT预训练采用了什么损失函数?
我们知道,大语言模型本质上是一个深度学习模型,而深度学习的思路是迭代优化数据集前向传播值与真实值之间的损失函数。
对于 decoder-only 大语言模型,预训练阶段的损失函数是什么呢?我们以概率论的视角来给出解答。
机器学习中,分类问题的损失函数是模型预测值与真实标签之间的交叉熵。因为以概率论角度,交叉熵衡量了两个随机变量分布的差异,看这张图。

对于 decoder-only 大语言模型,预训练思路都是期望一个 token 输入进 decoder model 后,输出后一个 token,其本质是分类问题,损失函数自然也是交叉熵。
不同的是,预训练阶段对于一个句子中的每个 token 都要计算交叉熵损失。
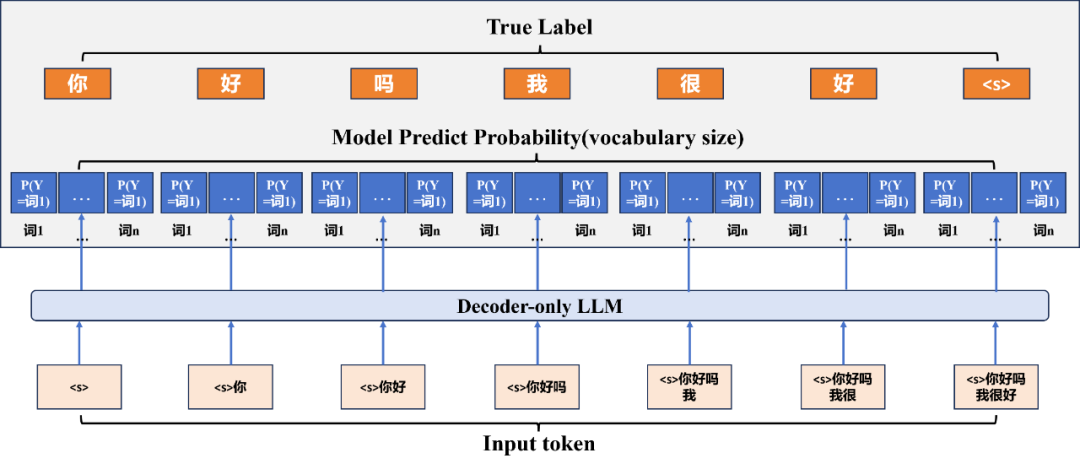
举个例子,看这张图。对于“你好吗我很好”这个句子,tokenizer 切分后的 token,作为 decoder-only 大语言模型的输入,input token 期望预测出的下一个 token 为真实 token 的平均交叉熵最小,也就是这个式子:

由于数据集中每个句子的 sequence length 不一定相同,所以每个句子的损失函数将所有 input token 的交叉熵求和后,需要取平均值。
二、为什么经常选择使用交叉熵,而不是KL散度作为损失函数?
要回答这个问题,其实需要按照下面这个问题链条来思考。
首先,交叉熵一看就是个信息论的概念,为什么变成了大模型最常用的损失函数呢?交叉熵的值到底有什么含义?为什么不用 KL 散度作为损失函数?
所以要讲清楚交叉熵,需要从信息墒说起。
大家先思考一下,信息是如何度量的?如果某件事情大概率发生,当这件事情发生的时候,所带的信息量是很少的。
举个例子:国足输球的概率是 95%。那么当国足又输了的时候,其实并没有什么信息量。
但是如果国足赢球了,并且赢了一个强队,那这个信息量就大的惊人,要是国足得了世界杯冠军,那信息量可以说趋近于无穷大。
而信息熵就是衡量某个随机事件信息的期望值,我们看公式,p 是某个事件发生的概率分布。
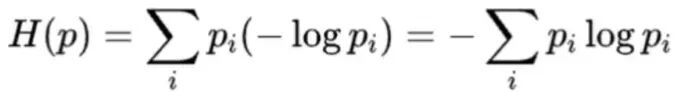
任何理论的产生都是为了解决某一个具体的问题。信息熵的提出是在香农的业务场景中,被用来解决通信的最优前缀编码问题。
具体点就是数据应该如何编码,才能使编码后的长度最短。因为相同的信息,越短的编码就意味着传输效率越高。
比如有这样一个分布 P:“A,A,B,A,C,A,B,D”。
最简单的编码方法就是按二进制编码,比如:
- 00 表示 A
- 01 表示 B
- 10 表示 C
- 11 表示 D
这样这段文本可以编码为这个样子,0000010010000111,长度为 16,每个事件的平均编码长度为 2。
如果我们采用 Huffman 编码:
- 0 表示 A
- 10 表示 B
- 110 表示 C
- 111 表示 D
利用这个编码,上面文本可以表示为这样:00100110010111,长度为 14, 每个事件的平均编码长度为 1.75。
那么问题来了,如果知道一个事件的概率分布,其最优编码是多少?
这个可以证明,信息熵就是某个随机事件的信息的期望值,同时也是最优编码的期望长度。
好,我们再回到交叉熵,交叉熵又是什么?
如果有一个分布Q,“B,B,A,B,C,B,D,C”,Q 的最优分布是用上面信息熵的公式可以求出为 1.75。
对于分布 Q,如果用分布 P 的最优编码来编码的话,长度是多少呢?
这里直接给答案:101001011010111110,最终编码出来长度为 18, 平均长度为 2.25。
这可比分布 P 自己的最优编码长了不少。所以这个非最优的平均长度其实就是交叉熵了。
用公式表示如下:
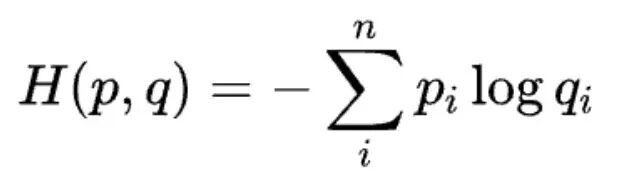
所以我们总结一下:交叉熵就是在 P 分布下,使用基于 Q 的最优编码方案的期望编码长度。
说得更通俗一点,就是如果你用模型的预测分布来表示实际标签分布,你需要付出多少“代价”。这个代价越小,说明模型的预测越接近实际情况。
如果两个分布在每个类别上都完全一致,那么交叉熵就是零,表示你不需要付出代价。
但如果两个分布有差异,那么交叉熵就会增加,代表你需要付出的“代价”也就增加了。
到这里,交叉熵作为损失函数的物理含义也就不言而喻了。
那 KL 散度呢,它又是什么,为什么不用它?
上面也说了,交叉熵是在 P 分布下,使用基于 Q 的最优编码方案的期望编码长度。当 P 和 Q 不相等时,这个期望长度是有冗余的,那到底冗余了多少?
其实冗余的数量就是 KL 散度。表示为这个公式:
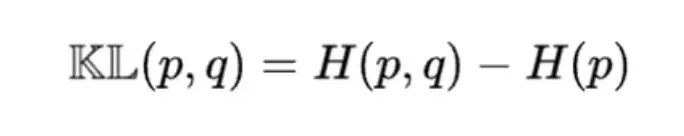
所以我们总结一下:KL 散度就是使用分布 Q来 表示 P的时候,丢失的信息量。
所以为什么不用 KL 做损失度量,而要用交叉熵,自然也就理解了。
KL 散度可以作为差异性的度量方式,但是这个差异并不是距离,因为 KL 散度并不对称,KL(P,Q)和 KL(Q,P)并不总是相等的。
也就是它用分布 Q 来表示 P,和用分布 P 来表示 Q,这二者带来的编码差异是不一样的。
所以 KL 散度不满足距离三要素,在训练神经网络时,不利于稳定和有效的训练。
另外,从 KL 的公式可以看出,如果 P 和 Q 的样本分布差异很大(比如网络刚开始训练时)。
如果 P,Q 其中一个在某个区域为 0,另一个在此区域刚好不为 0,那 KL 散度值会趋于无穷大,此时 KL 散度的对应的梯度接近于 0,这不利于网络做反向传播。
三、为什么Softmax和交叉熵(Cross-Entropy)经常结合使用?
通常在 softmax 层后使用交叉熵损失。为什么这种组合特别有效?请从数学角度解释。
要回答这个问题,得需要对 softmax 和交叉墒损失的公式在深度学习中的推导特别熟悉才行。
在深度学习中,Softmax 和**交叉熵(Cross-Entropy)**经常结合使用,尤其是在分类任务中,我们可以从数学和实际应用两个层面进行解释。
首先是数学上的兼容,Softmax 将 logits 转换为概率分布,而交叉熵需要输入概率分布。因此 Softmax 的输出可以直接作为交叉熵的输入。
另外是梯度计算的高效性,在反向传播时,Softmax 和交叉熵的结合可以简化梯度计算,避免数值不稳定。单独使用 Softmax 和交叉熵时,梯度计算可能涉及复杂的中间步骤。
当两者结合时,梯度计算可以简化,像这样:
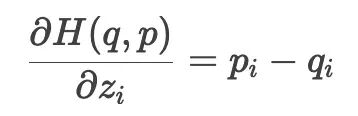
这种形式非常简单,计算效率高,且数值稳定。
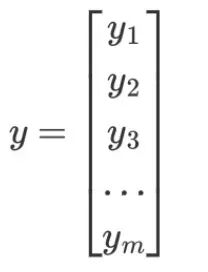
我们看一下怎么得出这个结论的:目标向量 y 维度为 m,表示 m 类别,y 为 one-hot 编码,只有一个值为 1,其他的值为 0。
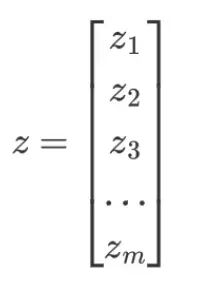
预测向量 z 为 softmax 函数的输入,和标签向量 y 的维度一样,为 m:
向量 s 为 softmax 函数的输出,和标签向量 y 的维度一样,为 m:
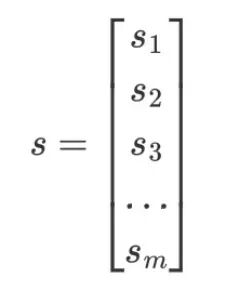
交叉熵损失函数具体计算公式如图,其中 y 代表真实值,s 代表 softmax 求出的值,j 代表输出结点的标号:
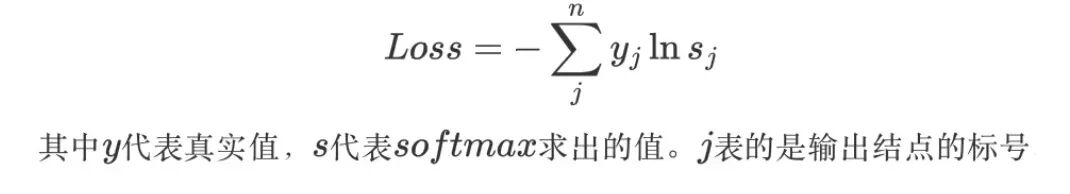
接下来我们对向量 z 中每个 zi 求偏导:
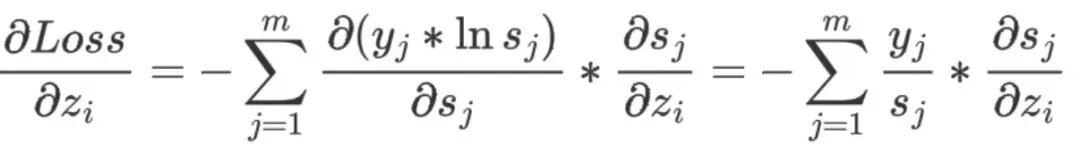
看这张图,向前传播时,由于 s 是多个 z 共同决定的,所以需要求出 s 对所有 z 的导数,以 s1 为例,前向传播求梯度的时候,需要求出 s1 对 z1,z2,z3…zi 的导数。
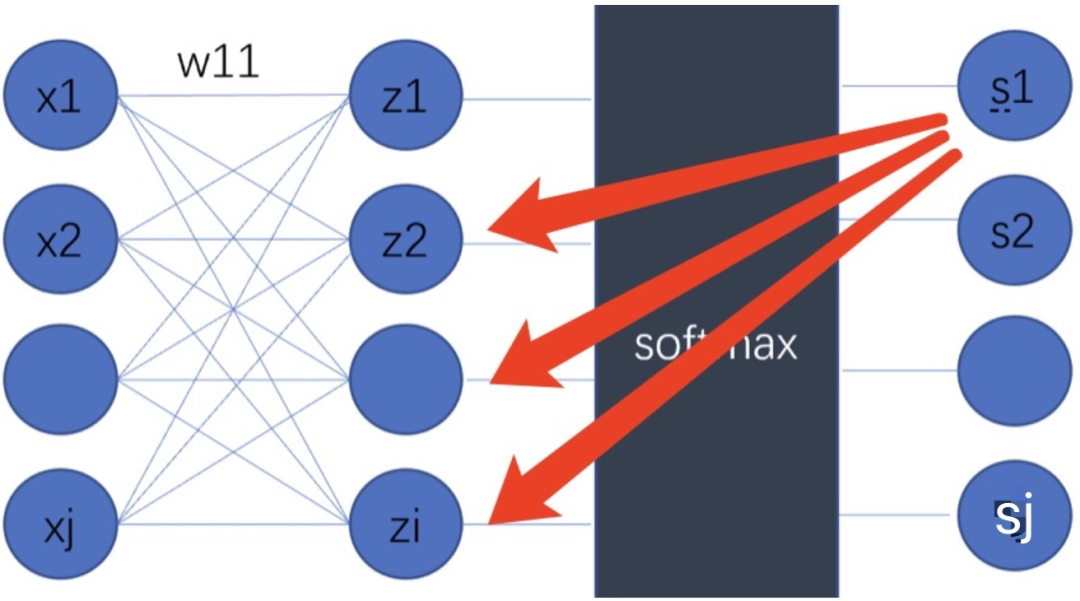
所以我们最后求偏导的时候,需要计算 i=j 和 i≠j 两种情况,也就得到了我们前面的结论,最后的梯度等于预测标签分布和真实标签分布的差,结论非常漂亮。
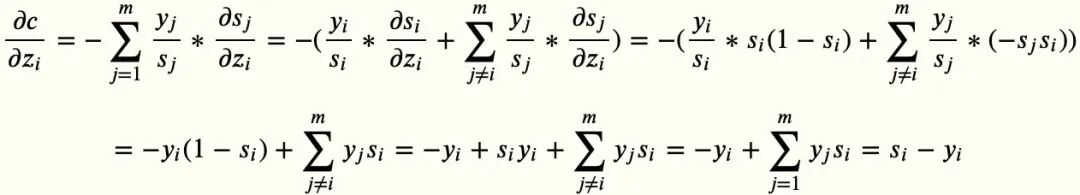
好,以上就是对大模型面试中关于损失函数的经典面试题的分析拆解,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇



一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
四、 AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👆
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献398条内容
已为社区贡献398条内容

所有评论(0)