(论文速读)X2-VLM:突破视觉语言理解边界的全能预训练模型
X2-VLM提出了一种创新的多粒度视觉语言预训练框架,通过统一架构同时学习对象级、区域级和图像级的视觉语言对齐。该模型采用模块化设计,使用双重预训练目标(多粒度对齐和定位),实现了图像-文本和视频-文本任务的高效统一处理。实验表明,X2-VLM在多项基准测试中表现优异,其模块化特性还支持零成本的跨语言适应。该工作为多模态AI提供了统一处理多粒度视觉语言任务的新范式,在性能和模型规模间取得了良好平衡
论文题目:X2-VLM: All-in-One Pre-Trained Model for Vision-Language Tasks(视觉语言任务的一体化预训练模型)
期刊:IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE(TPAMI)
摘要:视觉语言预训练旨在从大量数据中学习视觉和语言之间的一致性。大多数现有方法只学习图像-文本对齐。其他一些使用预训练的对象检测器来利用对象级别的视觉语言对齐。在本文中,我们提出了一个统一的预训练框架来学习多粒度视觉语言对齐,该框架同时学习多粒度对齐和多粒度定位。在此基础上,提出了灵活模块化架构的一体化模型X2-VLM,进一步将图像-文本预训练和视频-文本预训练统一在一个模型中。X2-VLM能够学习与不同文本描述相关的无限视觉概念。实验结果表明,X2-VLM在基础和大规模的图像文本和视频文本任务中都表现最好,在性能和模型规模之间取得了很好的平衡。此外,我们还证明了x2 - VLM的模块化设计使其具有很高的可移植性,可用于任何语言或领域。例如,通过简单地用XLM-R替换文本编码器,X2-VLM在没有任何多语言预训练的情况下优于最先进的多语言多模态预训练模型。
源码链接:https://github.com/zengyan97/X2-VLM.
引言
在人工智能快速发展的今天,让机器同时理解图像和文本内容已成为多模态AI的核心挑战。近期发表在IEEE TPAMI上的论文"X2-VLM: All-in-One Pre-Trained Model for Vision-Language Tasks"提出了一个革命性的解决方案,通过创新的多粒度学习框架,显著提升了视觉语言模型的理解能力。
现有方法的局限性
传统的视觉语言预训练方法主要分为两类:粗粒度方法使用CNN或Vision Transformer编码整体图像特征,细粒度方法依赖预训练的目标检测器提取对象特征。然而,这两种方法都存在明显局限:
- 粗粒度方法难以捕捉图像中的细节信息和对象间关系
- 细粒度方法受限于检测器的类别范围,无法识别"百事可乐"vs"可口可乐"这样的细粒度概念
- 现有模型大多只能处理图像-文本任务,缺乏视频理解能力
- 跨语言适应能力有限,需要重新训练整个模型
X2-VLM的核心创新
1. 多粒度视觉语言预训练框架
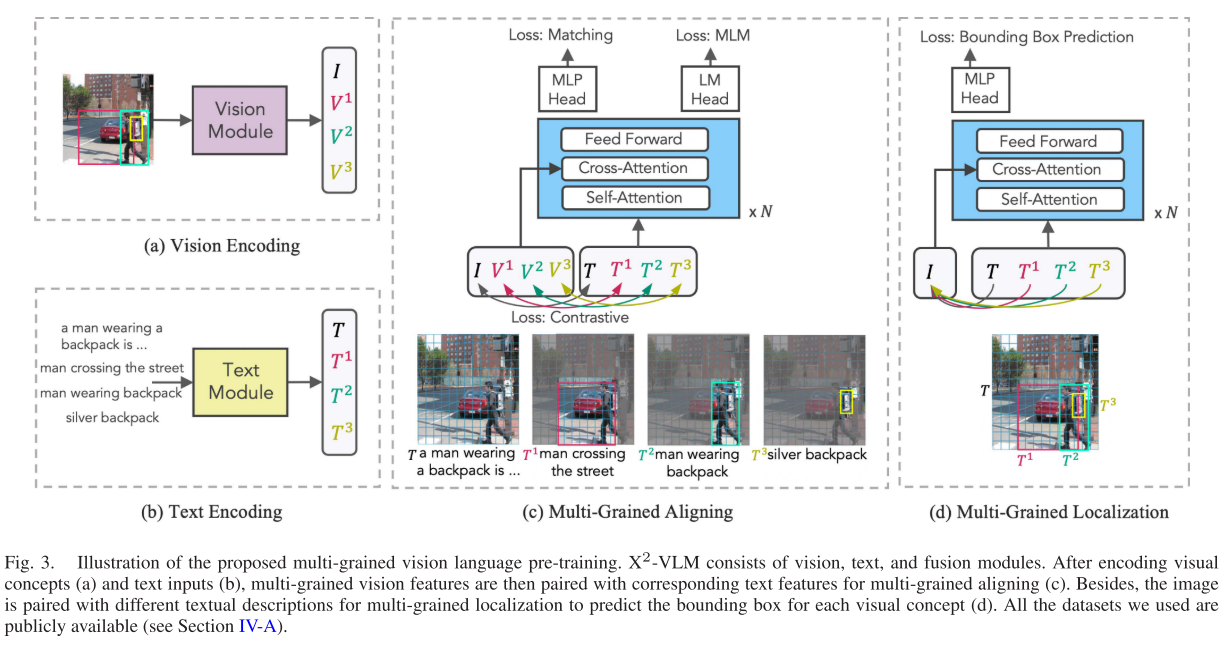
X2-VLM的最大创新在于提出了统一的多粒度预训练框架,能够同时学习对象级、区域级和图像级的视觉语言对齐。该框架的核心思想是将所有视觉概念(无论是对象、区域还是整个图像)都与相应的文本描述进行关联,而不是传统的类别标签。
2. 统一视觉编码策略
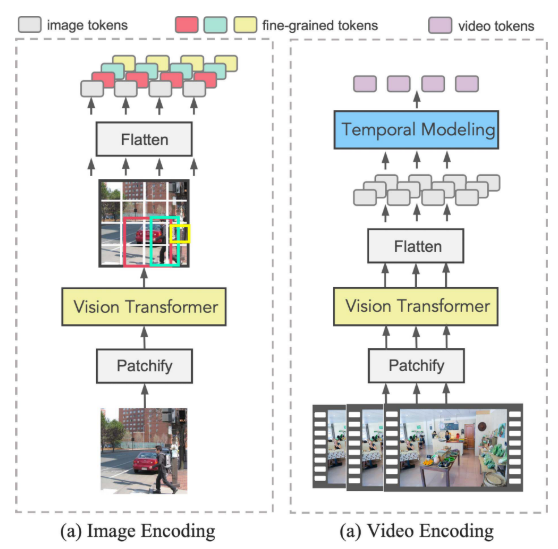
X2-VLM的另一个关键创新是统一视觉编码方法。传统方法需要不同的编码器处理不同类型的输入,而X2-VLM通过巧妙的patch特征聚合实现了统一处理:
- 对象/区域表示:对于边界框内的视觉概念,将对应的patch特征展平并保持原始位置信息,然后计算平均值作为[CLS] token
- 图像表示:聚合所有patch特征来表示整个图像
- 视频表示:每秒采样一帧,分别编码后在时间维度上聚合
这种设计的优势在于:只需一次前向传播就能获得多种粒度的视觉表示,大大提高了计算效率。
3. 双重预训练目标
X2-VLM采用两个互补的预训练目标:
多粒度对齐(Multi-Grained Aligning)
- 对比损失:学习正确的视觉-文本匹配
- 匹配损失:判断视觉概念与文本是否匹配
- 掩码语言建模:基于视觉信息预测被掩码的文本
多粒度定位(Multi-Grained Localization)
- 边界框预测:给定文本描述,预测对应视觉概念的位置
- 使用L1损失和IoU损失的线性组合,解决不同尺度边界框的优化问题
卓越的实验表现
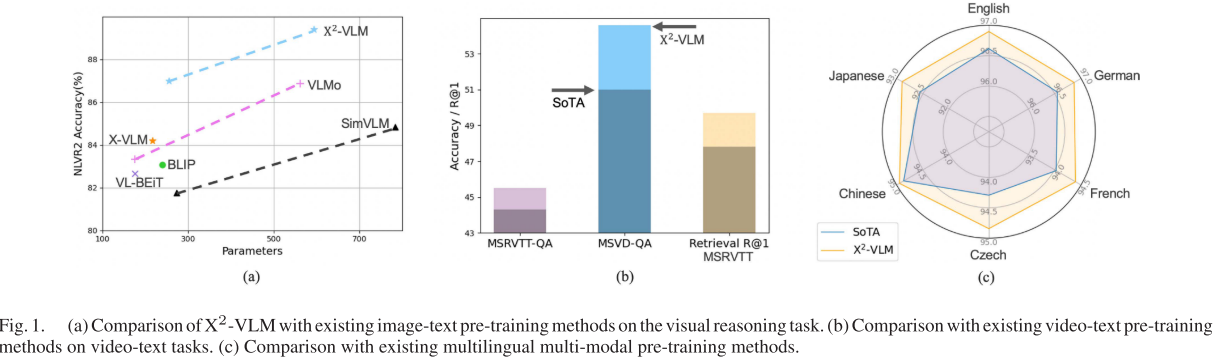
图像-文本任务全面领先
X2-VLM在多个主流基准测试中都取得了最佳性能:
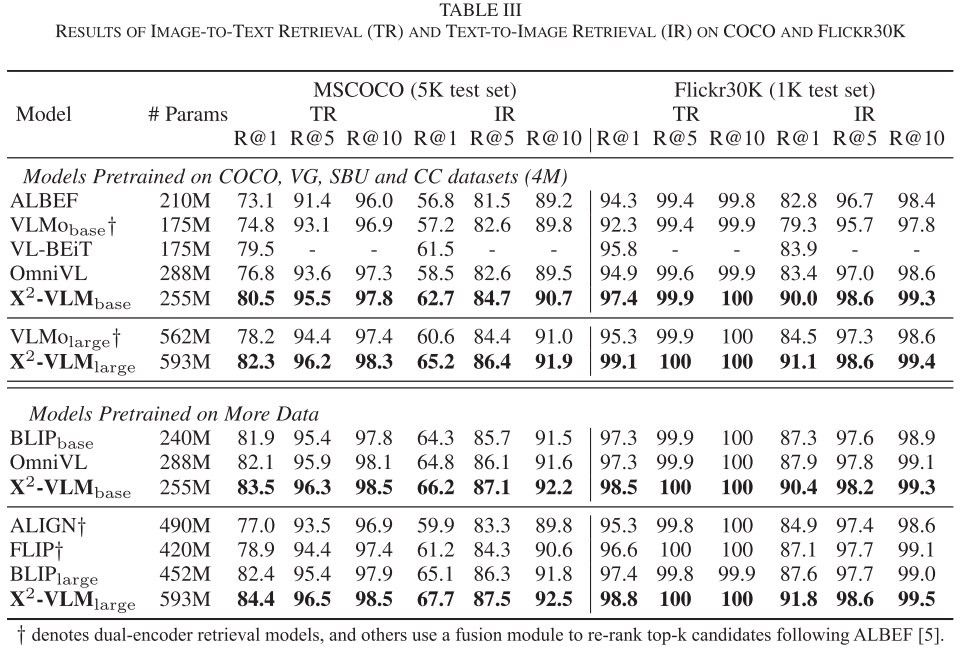
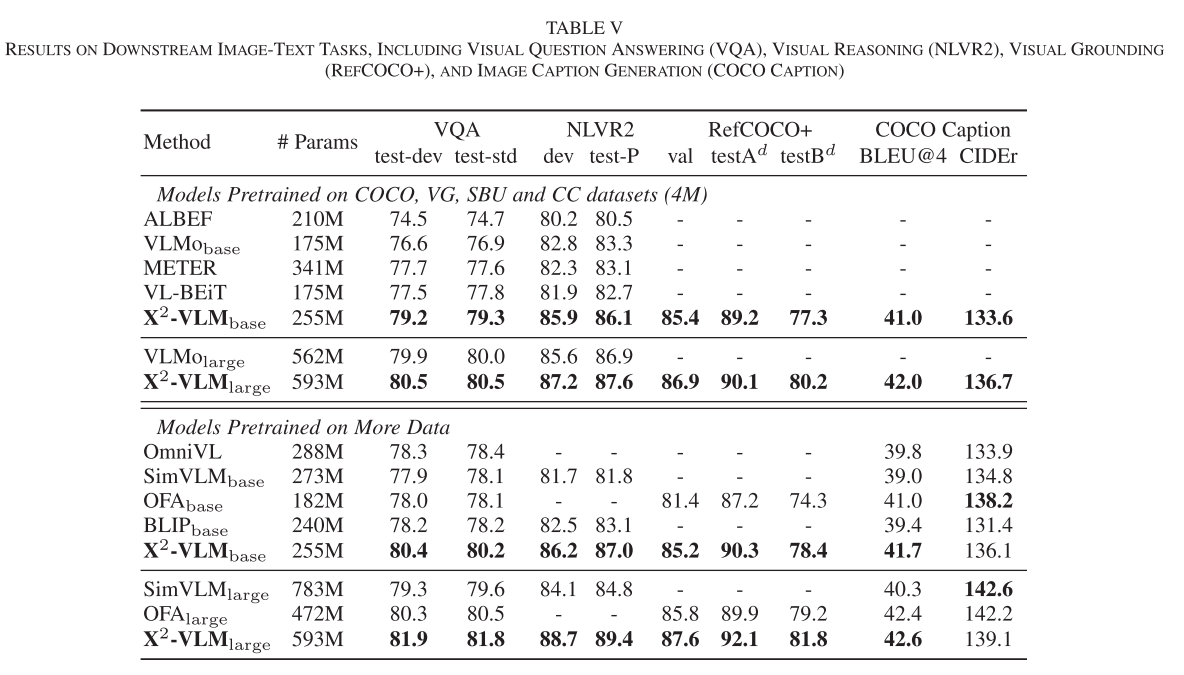

- COCO检索:Text-to-Image R@1达到82.2%,Image-to-Text R@1达到96.2%
- VQA v2.0:准确率达到87.0%,显著超越同规模模型
- NLVR2视觉推理:准确率达到87.6%,展现出强大的视觉推理能力
- RefCOCO+定位:在多个split上都获得最佳结果
视频理解能力突破
更令人印象深刻的是,X2-VLM在视频-文本任务上也取得了突破性进展:
- MSRVTT检索:R@1达到52.8%,创造新的记录
- 视频问答:在MSRVTT-QA、MSVD-QA等多个数据集上都超越了专门的视频理解模型
这证明了统一框架的有效性——通过共享的视觉表示学习,图像理解能力可以很好地迁移到视频理解任务。
跨语言适应性验证
X2-VLM的模块化设计在跨语言任务中展现了巨大潜力。研究人员仅仅将英文BERT替换为多语言的XLM-R,就在6种语言的多模态任务中超越了需要多语言数据预训练的专门模型:
- Multi30K:在德语、法语、捷克语等语言上都取得最佳结果
- 多语言COCO:平均性能超越UC2、MURAL等多语言多模态模型
这种"零成本"的跨语言适应能力对实际应用具有重要意义,大大降低了多语言部署的门槛。
深入的消融实验分析
论文进行了全面的消融实验,揭示了框架各组件的重要性:
1. 预训练目标的贡献
- 多粒度对齐对所有任务都至关重要,是性能提升的主要来源
- 边界框预测对视觉定位任务特别重要,同时能提升整体性能
2. 数据类型的影响
- 对象数据主要提升图像-文本检索性能
- 区域数据对视觉定位和开放词汇属性检测更为关键
- 同时使用两种数据类型能获得最佳性能
3. 模块化设计的验证
对比实验证明,相比于将cross-attention层嵌入BERT或仅替换tokenizer的方案,X2-VLM的完全模块化设计在跨语言适应中表现最佳。
定性分析:
模型学会了什么?研究人员对X2-VLM进行了详细的定性分析,结果令人印象深刻。模型展现出了超越预训练数据类别限制的细粒度理解能力。例如,虽然训练时只看到"汽车"这样的通用标签,但X2-VLM能够准确区分奥迪和宝马、百事可乐和可口可乐,甚至能识别路飞和索隆这样的动漫角色。
这种"涌现"能力表明,大规模多粒度预训练确实帮助模型学到了从通用概念到具体实例的映射规律,这对实际应用具有重要价值。
技术意义与影响
1. 架构设计的启发
X2-VLM的模块化设计为多模态模型开发提供了新的思路。不同于将所有功能集成在单一Transformer中的做法,分离式设计带来了更好的灵活性和可维护性。这种设计思想值得在其他多模态任务中借鉴。
2. 数据利用效率的提升
通过统一框架同时利用图像-文本对、视频-文本对、对象标注、区域标注等多种数据类型,X2-VLM显著提升了数据利用效率。这种"一石多鸟"的预训练策略为数据稀缺场景提供了解决思路。
3. 跨语言部署的新范式
X2-VLM证明了通过模块化设计可以实现"零成本"的跨语言适应,这对多语言AI产品的开发具有重要意义。传统方法需要收集多语言多模态数据并重新预训练,而X2-VLM只需替换文本编码器即可。
局限性与挑战
尽管X2-VLM取得了显著进展,但仍存在一些局限性需要关注:
1. 计算复杂度
多粒度预训练需要处理更复杂的数据和损失函数,相比传统方法计算开销更大。虽然统一视觉编码提高了效率,但整体训练成本仍然较高。
2. 数据质量依赖
模型的细粒度理解能力很大程度上依赖于预训练数据的质量和多样性。对于某些特定领域或小众概念,模型的表现可能受限于训练数据覆盖度。
3. 边界框标注的需求
虽然X2-VLM在推理时不需要边界框标注,但预训练过程仍需要大量的标注数据。这在一定程度上限制了模型在标注稀缺领域的应用。
4. 模型规模的权衡
虽然X2-VLM在参数效率上表现出色,但要达到最佳性能仍需要相当的模型规模。如何在保持性能的同时进一步减小模型大小,仍是一个待解决的问题。
未来发展方向
基于X2-VLM的成功经验,我们可以预见多模态AI的几个发展方向:
1. 更细粒度的视觉理解
未来的研究可能会探索像素级或部件级的视觉语言对齐,进一步提升模型的细节理解能力。
2. 多模态统一架构
X2-VLM展示了统一处理图像和视频的可能性,未来可能出现处理更多模态(如音频、3D)的统一架构。
3. 少样本适应能力
如何让预训练模型快速适应新领域、新任务,仍是重要的研究方向。X2-VLM的模块化设计为此提供了基础。
4. 效率优化
在保持性能的前提下,如何进一步降低计算成本、存储需求,将是工程实践中的重要考虑。
结语
X2-VLM代表了视觉语言预训练的一个重要里程碑。通过创新的多粒度学习框架和模块化架构设计,它不仅在多个任务上取得了最先进的性能,更重要的是为多模态AI的发展提供了新的思路和方法。
该工作的价值不仅在于具体的技术创新,更在于展示了统一多粒度学习的可行性和有效性。随着大规模预训练模型的发展,如何更好地利用多源数据、实现跨任务泛化、降低部署成本等问题将变得越来越重要,而X2-VLM在这些方面的探索为后续研究指明了方向。
对于从事多模态AI研究和开发的人员来说,X2-VLM提供了宝贵的经验和启发。其模块化设计理念、多粒度学习策略、统一编码方法等都值得深入研究和借鉴。
当然,任何技术都有其适用场景和局限性。在实际应用中,需要根据具体需求、资源限制等因素来选择合适的方法。X2-VLM为我们提供了一个强有力的工具,但如何用好这个工具,还需要持续的探索和实践。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)