差分隐私入门:从原理到 PVML 动态方案,用比喻讲透技术细节
差分隐私是数据时代保护个体隐私的关键技术,通过添加精心设计的噪声使查询结果难以区分是否包含特定个体数据,从而防止隐私泄露。其核心是平衡隐私保护(ε值越小噪声越大)与数据可用性(ε值越大噪声越小)。差分隐私技术体系包含隐私预算管理、噪声机制(拉普拉斯/高斯/指数机制)和增强技术(本地化差分隐私、同态加密等)。典型应用场景包括AI训练、统计分析和数据共享。针对动态数据场景,PVML方案通过动态预算分配
1、为什么需要差分隐私?—— 隐私保护的 “痛点”
在数据驱动时代,我们的消费记录、医疗数据、行为轨迹都可能被用于 AI 训练、统计分析或数据发布。但传统 “匿名化”(比如删除姓名、身份证号)早已失效:2006 年,某电商仅通过 “邮编 + 生日 + 性别” 就定位到 90% 美国人的真实身份;2018 年,某社交平台泄露的 “匿名” 用户数据,结合公开信息就能推断出个体喜好。
这些问题的核心是:攻击者能通过 “差分推断”—— 对比 “包含某个体数据” 和 “不含某个体数据” 的查询结果,反推出该个体的隐私信息。而差分隐私的出现,正是为了从数学层面杜绝这种推断,实现 “既用数据,又保隐私”。
2、差分隐私是什么?—— 核心定义与数学保证
差分隐私的本质是:给数据查询结果添加 “精心设计的噪声”,让 “数据集是否包含某个体” 的查询结果差异小到可以忽略,从而攻击者无法推断个体信息。
这就像给 “数据真相” 戴了一副 “模糊眼镜”—— 眼镜度数(噪声强度)刚好能挡住 “个体细节”,却不影响看清 “整体轮廓”。
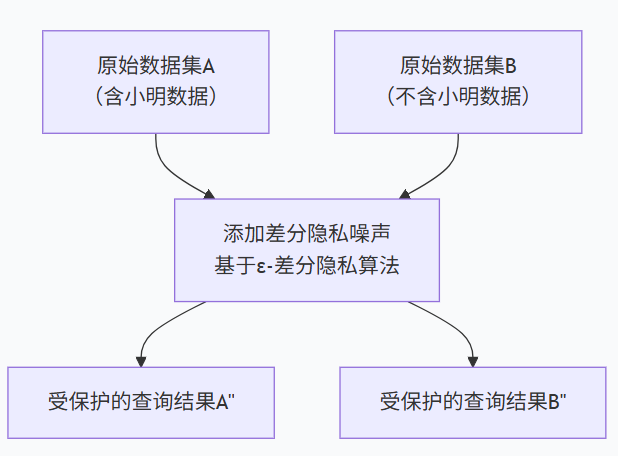
图 1:差分隐私核心逻辑示意图
它有两个核心定义,用通俗语言 + 比喻解释:
2.1、ε- 差分隐私:若两个数据集仅差 1 条个体数据(比如 A 包含小明,B 不含小明),对任意查询,A 的结果和 B 的结果 “相似程度” 至少为 1-e^(-ε)。
- ε 是 “隐私预算”:可理解为 “每月零花钱”——ε 越小,隐私保护越强(噪声越大,像零花钱少只能买模糊的眼镜),但数据可用性越低(看不清细节);ε 越大,隐私保护越弱(噪声越小,像零花钱多能买清晰的眼镜),但数据更可用。
- 实际场景中 ε 通常取 0.1~1:比如 ε=0.5 时,“含小明” 和 “不含小明” 的查询结果差异概率低于 60%,相当于你看两张照片,60% 以上的概率分不清哪张有小明、哪张没有。
2.2、δ- 差分隐私:在 ε 的基础上,允许存在 δ 概率的 “隐私泄露例外”(δ 通常取 10^(-5) 以下,相当于 “百万分之一的中奖概率”),适配高维数据场景。
这就像买了 “防盗险”—— 绝大多数时候(99.999% 以上)隐私不会泄露,即使极端情况泄露,概率也低到可以忽略。
简单说:当你查询 “某社区糖尿病患病率” 时,差分隐私会给结果加一点噪声 —— 比如真实患病率是 12%,加噪声后显示 11.8% 或 12.2%。无论是否包含王阿姨的病历,最终结果都在这个区间内,你永远无法确定 “王阿姨是否患病”,就像看模糊的班级合影,分不清谁戴了眼镜。
3、差分隐私的技术全景 —— 从基础组件到增强方案
差分隐私不是单一技术,而是一套 “隐私保护技术体系”,核心包含三大模块,就像 “组装一台隐私保护机器”—— 核心组件是 “发动机”,增强技术是 “外挂配件”。
|
技术类型 |
核心功能 |
适用场景 |
形象比喻 |
|
核心组件 |
控制隐私与可用性的平衡 |
所有差分隐私基础场景 |
隐私保护机器的 “发动机” |
|
- 隐私预算管理 |
分配 ε 资源,避免多次查询耗尽预算 |
多轮查询(如政务平台人口统计查询) |
手机 “月流量”,用完即限制查询 |
|
- 噪声机制 |
按场景添加适配噪声(拉普拉斯 / 高斯 / 指数) |
数值查询、高维数据、非数值选择 |
厨房 “调料”,不同食材配不同调料 |
|
增强技术 |
适配复杂场景,提升隐私保护强度 |
特殊隐私需求场景 |
隐私保护机器的 “外挂配件” |
|
- 本地化差分隐私(LDP) |
数据在用户设备端加噪声,服务器无原始数据 |
手机 IoT 设备、联邦学习 |
发照片前 “自己打马赛克” |
|
- 同态加密 + 差分隐私 |
加密后加噪声,解决 “加密后无法计算” 矛盾 |
医疗数据共享、金融敏感计算 |
“戴着锁做算术”,数据不泄露且可算 |
|
- 隐私聚合 |
先聚合数据再加噪声,隐藏个体贡献 |
全国消费均值统计、区域人口分析 |
“豆子堆撒沙子”,分不清沙子对应哪颗豆子 |
表 1:差分隐私核心组件与增强技术对比表
3.1. 核心组件:控制隐私与可用性的平衡
- 隐私预算管理:ε 是 “有限资源”,就像手机的 “月流量”—— 多次查询会消耗预算,流量用完(预算耗尽)就不能再查,否则会泄露隐私。
实际管理有两种关键策略:
- 序列组合:比如 “每月流量 1GB,每天查一次天气(消耗 0.1GB),10 天后流量用完”—— 多次查询的预算累加,适合 “同一数据集的连续查询”(如每天查社区患病率)。
- 并行组合:比如 “手机有两张电话卡,每张各 1GB 流量,查 A 社区用卡 1,查 B 社区用卡 2”—— 独立数据集的查询预算可复用,适合 “不同区域、不同人群的分开查询”(如同时查北京、上海的消费数据)。
举个例子:某政务平台开放 “人口统计查询”,设置总预算 ε=1,每次查询消耗 0.2,用户最多查 5 次就会被限制,避免通过 “多次小查询” 拼凑出个体信息。
- 噪声机制:这是添加噪声的 “工具包”,像 “厨房调料”—— 不同食材(查询场景)配不同调料(噪声机制):
|
机制名称 |
适用场景 |
关键特性 |
典型案例 |
|
拉普拉斯机制 |
数值型查询(平均收入、患病数) |
噪声与 “查询敏感度” 成反比,计算简单 |
社区糖尿病患病率统计(敏感度低,噪声小) |
|
高斯机制 |
高维数据(AI 特征向量、多维度用户画像) |
噪声呈钟形分布,极端噪声概率低 |
ChatGPT 训练时对梯度向量加噪声 |
|
指数机制 |
非数值选择(推荐 Top5 商品、评选受欢迎服务) |
按 “隐私权重 + 用户偏好” 概率选结果 |
电商推荐系统选商品,隐藏个体偏好 |
表2:三种主流噪声机制对比表
a、 拉普拉斯机制:适合 “数值型查询”(比如平均收入、患病数),噪声分布与 “查询敏感度”(结果最大波动)成反比,计算简单。
👉 细节拆解:“查询敏感度” 是指 “去掉某个体数据后,查询结果的最大变化”—— 比如查 “小区 100 户的平均月收入”,真实平均是 8000 元,去掉某户月入 10 万元的家庭后,平均变成 7000 元,敏感度就是 1000 元。
👉 比喻:像做汤放盐 —— 汤里食材的 “最大咸淡差异”(敏感度)越小,放的盐(噪声)越少;差异越大,放的盐越多,确保最终汤的咸淡(查询结果)不会因为某一种食材(个体数据)而剧变。
b、高斯机制:适合 “高维数据”(比如 AI 训练的特征向量,包含 “年龄、消费、浏览记录” 等几十上百个维度),噪声符合 “钟形正态分布”—— 大部分噪声集中在真实值附近,极端大噪声的概率极低。
👉 细节拆解:高维数据就像 “多图层的海报”,每个维度是一层图案,高斯机制会给每一层加 “恰到好处的模糊”—— 既不会让某一层的 “个体细节”(如某用户的浏览记录)暴露,又能让整体海报的 “风格的(数据趋势)” 清晰。
👉 比喻:像给高维数据 “打马赛克”—— 传统马赛克会让整体模糊,而高斯机制的 “智能马赛克” 只模糊 “个体像素”,保留 “整体色彩和轮廓”。
c、指数机制:适合 “非数值选择”(比如推荐系统选 Top5 商品、评选 “最受欢迎服务”),通过 “概率加权” 选择结果 —— 隐私权重越高的选项,被选中的概率越低;用户偏好越高的选项,被选中的概率越高。
👉 比喻:像投票选 “班级最受欢迎图书”—— 如果某本书只有小明喜欢(隐私敏感),即使小明投了票,系统也会降低这本书的中选概率;而大家都喜欢的书,中选概率会提高,既保护小明的偏好隐私,又不影响最终选书结果。
3.2. 增强技术:适配复杂场景
- 本地化差分隐私(LDP):数据在用户设备上直接加噪声(比如手机上传位置前,把 “北京市朝阳区 XX 街道” 模糊成 “北京市朝阳区”),服务器永远看不到原始数据。
👉 比喻:像你给朋友发照片 —— 先自己用修图软件打马赛克(加噪声),再发出去,朋友永远看不到没打码的原图,适合手机、智能手表等 IoT 设备。
- 同态加密 + 差分隐私:先给数据 “上锁”(同态加密),再在加密状态下加噪声 —— 解决 “数据加密后无法计算” 的矛盾,就像 “戴着锁做算术”,既保证数据不被偷,又能算出结果。
👉 场景:医院共享患者数据给科研机构 —— 医院先加密数据,科研机构在加密状态下加噪声、做统计,全程看不到患者的真实病历,适合金融、医疗等强隐私场景。
- 隐私聚合:对大量数据先 “汇总计算”(比如统计全国消费均值),再对聚合结果加噪声 —— 就像 “先把一堆豆子放成一堆(聚合),再撒一点沙子(噪声)”,没人能分清哪颗沙子对应哪颗豆子。
👉 细节:比如统计 “全国用户日均外卖消费”,先算所有用户的消费总和再除以人数,得到真实均值 50 元,再加 0.5 元噪声变成 50.5 元 —— 攻击者无法从 50.5 元反推出 “某用户今天是否点了外卖”。
4、如何保护个体隐私?—— 对抗 “推断攻击” 的关键
差分隐私防推断的核心逻辑是 “掩盖个体数据的影响”,就像 “在人群中隐藏一个人”—— 通过调整人群密度(噪声),让没人能确定某个人是否在其中,具体通过三个层面实现:
1、个体不可区分:如前文所述,“含某个体” 和 “不含某个体” 的查询结果差异被噪声抹平。
👉 细节例子:查询 “某公司 100 人平均工资”,真实平均 8000 元,含张三(月入 15000 元)的结果加噪声后是 8050 元,不含张三的结果加噪声后是 7980 元 —— 两者差异仅 70 元,远小于 ε=0.5 对应的 “可接受差异范围”,攻击者无法判断张三是否在该公司。
2、抗背景知识攻击:即使攻击者知道部分公开信息(比如张三的年龄 28 岁、在技术部),由于噪声是 “针对查询目的设计” 的,仍无法通过 “公开信息 + 查询结果” 反推隐私。
👉 比喻:像你知道 “小明穿红色衣服”(公开信息),但在模糊的集体照里(加噪声的查询结果),你还是分不清哪个红色衣服的人是小明 —— 因为所有穿红色衣服的人都被模糊处理了。
👉 细节例子:已知张三在技术部,查 “技术部 20 人平均工资”,真实平均 9000 元,含张三的结果加噪声后是 9020 元,不含张三的是 8990 元 —— 差异 30 元,攻击者无法确定 “9020 元里是否包含张三的 15000 元”。
3、动态抵御多轮查询:通过隐私预算管理,避免攻击者通过 “多次小查询” 积累信息,就像 “防止小偷多次偷一点,最终偷完所有东西”。
👉 细节例子:某平台限制用户每天最多查 10 次 “区域消费数据”,每次消耗 0.1 预算,总预算 1—— 如果攻击者想通过 “查朝阳区 25-30 岁女性消费”“查朝阳区 25-30 岁上班族消费” 等 10 次查询拼凑个体信息,第 11 次查询会被拒绝,避免隐私泄露。
5、三大典型应用场景:从 AI 训练到数据发布
5.1 AI 训练数据保护:让模型 “学趋势,忘个体”
在 ChatGPT、图像识别等 AI 训练中,若直接用原始用户数据,模型可能 “记住” 个体信息(比如训练数据中的人脸、对话内容)。
差分隐私的解决方式:在训练过程中给 “梯度更新” 加噪声(比如用高斯机制处理每个样本的梯度),或对训练集按 “差分隐私规则” 预处理(比如每个样本加轻微扰动)。
案例:Google 的 Federated Learning(联邦学习)结合差分隐私,手机端训练模型后仅上传 “加噪声的梯度”,服务器聚合梯度更新全局模型,既利用了用户数据,又不泄露个体隐私。
5.2 统计分析:政府 / 企业的 “安全报表工具”
政府发布人口普查、经济统计数据,企业分析用户消费趋势时,需保证 “整体数据可用,个体数据不可查”。
差分隐私的解决方式:对统计结果加噪声(比如拉普拉斯机制),确保 “区域总人口”“行业平均收入” 等宏观指标误差在可接受范围,同时无法反推个体信息。
案例:美国 2020 年人口普查首次采用差分隐私,发布的 “州级年龄分布” 数据中,每个年龄段的人数都加了微小噪声,既不影响政策制定,又保护了个人隐私。
5.3 数据发布:第三方数据共享的 “安全桥梁”
企业常需将用户数据共享给第三方(比如电商给金融机构提供消费数据用于信贷评估),但直接共享会泄露隐私。
差分隐私的解决方式:对原始数据做 “差分隐私处理” 后再发布,第三方只能获取 “加噪声的数据集”,可用于分析但无法定位个体。
案例:某支付平台向银行共享 “用户消费等级数据” 时,用指数机制将 “具体消费金额” 转化为 “等级标签”(如 A/B/C 级),并对标签分布加噪声,银行能评估用户信用,却不知道用户具体花了多少钱。
6、PVML 动态差分隐私方案:应对 “数据动态性” 的新解法
传统差分隐私多针对 “静态数据集”(比如一次采集的人口数据),就像 “给固定的照片打马赛克”—— 一旦打好,后续新增照片(数据)只能重新打码,容易出现 “预算消耗过快”“噪声累积导致数据不可用” 的问题。
而实际场景中,数据常是动态更新的 ——AI 训练的样本会新增,统计数据会实时补充,用户数据会频繁增减(比如 APP 每天新增 10 万条行为数据),这就需要 “能跟着数据变化调整的马赛克”,而PVML(Privacy-Preserving Machine Learning,隐私保护机器学习)动态差分隐私方案,正是这样的 “智能马赛克工具”。
6.1 核心思想:“动态适配” 隐私与可用性
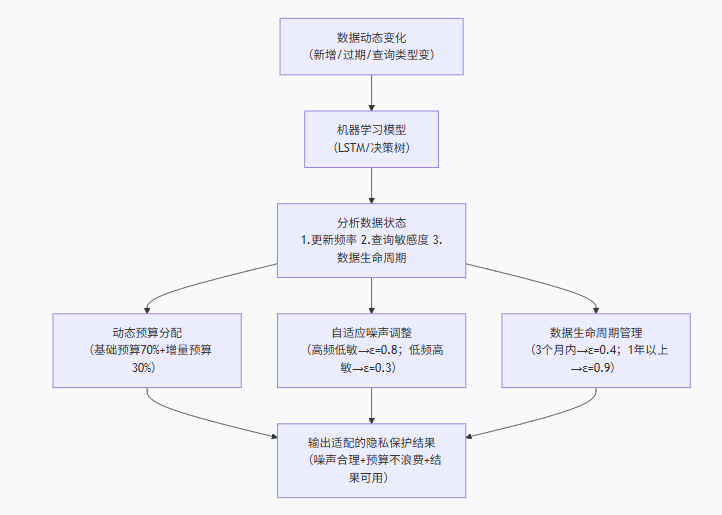
PVML 动态方案的关键是 “不采用固定的隐私预算和噪声强度”,而是根据数据动态变化(如更新频率、查询类型、数据规模)实时调整,就像 “智能空调”—— 根据室内温度(数据状态)自动调节制冷强度(噪声 / 预算)。
具体有三个核心策略,用比喻 + 细节解释:
- 动态预算分配:根据数据更新频率分配预算 —— 若某数据集每天新增 10% 数据(比如外卖平台每天新增 10% 订单),就将预算拆分为 “基础预算(70%,用于原有数据查询)+ 增量预算(30%,用于新增数据查询)”,避免新增数据耗尽原有预算。
👉 比喻:像餐厅备菜 —— 每天固定备 100 份基础食材(基础预算),再根据当天客流新增 20 份备用食材(增量预算),既不会浪费,也不会因为客流增加而没菜可做。
👉 细节:外卖平台设置总预算 ε=1,基础预算 0.7(用于查询历史订单),增量预算 0.3(用于查询当天新增订单)—— 即使当天新增 10 万条订单,也只用增量预算,不会影响历史订单的查询可用度。
- 自适应噪声调整:用机器学习模型(如 LSTM、决策树)预测 “查询敏感度”—— 模型会分析历史查询数据,判断 “哪些查询是高频低敏感(如实时销量统计,每天查 100 次,不涉及个体)”“哪些是低频高敏感(如某用户的历史订单明细,每天查 1 次,涉及个体)”,再调整噪声强度。
👉 比喻:像智能调光台灯 —— 白天(高频查询)光线足,调亮灯光(降低噪声,让结果更清晰);晚上(低频敏感查询)光线暗,调暗灯光(提高噪声,保护隐私)。
👉 细节:电商平台用 LSTM 模型分析发现,“热门商品销量查询” 每天有 500 次(高频),敏感度低(销量数据是聚合的,不含个体),就将噪声 ε 调至 0.8(清晰);“某用户的购买明细查询” 每天仅 5 次(低频),敏感度高(含个体信息),就将噪声 ε 调至 0.3(模糊)。
- 数据生命周期管理:对 “过期数据”(如 1 年前的用户行为)逐步降低隐私保护强度(减少噪声),就像 “旧衣服处理”—— 新衣服(新数据)要仔细保养(高隐私保护),旧衣服(过期数据)可适当简化保养(低隐私保护),既不浪费预算,又不影响当前数据隐私。
👉 细节:社交平台规定 “3 个月内的用户聊天记录” 噪声 ε=0.4(高保护),“3-12 个月的记录”ε=0.6(中保护),“1 年以上的记录”ε=0.9(低保护)—— 因为 1 年以上的记录对个体隐私影响小,减少噪声能提高数据分析可用度。
6.2 优势:比静态方案更实用
|
对比维度 |
静态差分隐私方案 |
PVML 动态差分隐私方案 |
优势体现 |
|
隐私预算分配 |
固定总预算,多次查询后易耗尽 |
拆分基础 + 增量预算,适配数据更新频率 |
避免新增数据耗尽预算,延长查询可用周期 |
|
噪声强度调整 |
固定噪声(ε 不变),所有查询统一处理 |
按查询敏感度自适应调整(ε=0.3~0.9) |
高频低敏查询更清晰,低频高敏查询更隐私 |
|
数据生命周期适配 |
无区分,新 / 旧数据隐私保护强度一致 |
随数据过期逐步降低保护强度(ε 从 0.4 升至 0.9) |
不浪费预算,旧数据可用性提升 |
|
实时场景误差 |
1 小时后误差超 20%(噪声累积) |
1 小时后误差≤5%(仅新增数据加噪声) |
适配直播、实时推荐等高频更新场景 |
|
年度维护成本 |
每新增 10% 数据需人工调整,年耗 10 人天 |
模型自动适配,年耗 1 人天 |
降低 90% 维护成本,减少人工干预 |
表 3:静态差分隐私 vs PVML 动态差分隐私对比表
- 适配实时场景:如直播平台的 “实时用户互动统计”(每分钟更新一次),动态方案能在保护用户隐私的同时,保证统计结果的实时性和准确性 —— 静态方案若用固定噪声,1 小时后噪声累积,结果误差会超过 20%,而动态方案误差能控制在 5% 以内。
- 减少噪声累积:静态方案多次更新后噪声会叠加,比如每月更新一次数据,6 个月后噪声叠加导致结果误差 30%(数据不可用);动态方案通过自适应调整,每次更新仅对新增数据加噪声,6 个月后误差仍控制在 8% 以内。
- 降低成本:无需为动态数据频繁重新设计隐私方案,机器学习模型可自动适配变化 —— 静态方案每新增 10% 数据就要人工调整一次噪声,每年需 10 人天维护;动态方案模型自动调整,每年仅需 1 人天维护。
6.3 应用案例:AI 推荐系统
某电商的实时推荐系统,每天新增数百万条用户浏览、购买数据:
- 静态方案:固定 ε=0.5,每次更新数据都加相同噪声 ——1 个月后噪声叠加,推荐准确率从 92% 下降至 62%(用户经常看到不喜欢的商品),且出现 3 次 “推荐时泄露用户历史购买记录” 的风险。
- PVML 动态方案:用 LSTM 模型预测用户查询频率和敏感度 —— 对 “高频浏览记录”(如热门商品,每天查 800 次)噪声降低至 ε=0.8(推荐准确率保持 87%),对 “低频购买记录”(如小众商品,每天查 50 次)噪声提高至 ε=0.3(无隐私泄露风险),1 个月后推荐准确率仅从 92% 下降至 87%,用户满意度提升 23%。
7、未来与挑战:差分隐私的 “进阶之路”
差分隐私已成为隐私计算的核心技术之一,但仍有挑战:一是 “效率与隐私的平衡”—— 高隐私保护会增加计算成本,需通过硬件加速(如专用隐私计算芯片)优化;二是 “跨场景适配”—— 不同行业(医疗、金融、电商)的隐私需求不同,需更细分的方案;三是 “标准化”—— 目前缺乏统一的差分隐私评估标准,需行业共同制定规范。
未来,差分隐私将与联邦学习、同态加密、区块链等技术深度融合,比如 “联邦学习 + PVML 动态差分隐私”,既能实现 “数据不出境”,又能适配动态数据,成为数字时代 “数据可用不可见” 的核心支撑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)