自动驾驶---神经网络为什么会记忆?
作者结合自身研究经历,从RBF神经网络到现代AI应用,阐释了神经网络的学习与记忆机制。神经网络通过权重调整(长期记忆)、激活状态(短期记忆)及特殊结构(如RNN、Transformer)实现信息处理。以GPT为例,其长期记忆存储于预训练权重中,工作记忆依托上下文窗口,短期记忆则通过激活值传递信息。这种记忆机制本质上是统计性、关联性的模式存储,不同于计算机的精确存储,更接近生物记忆特性。
1 渊源
笔者在上大学的时候,曾跟随导师做过RBF(径向基函数)神经网络(很多朋友估计没听说过)的科研,主要用于非线性函数的逼近,后续用于控制,那时还是懵懵懂懂的看论文,所谓的“照葫芦画瓢”,现在回过头来看,当时并没有真正搞懂什么是神经网络。
在AI发展蓬勃的今天,神经网络还是那个神经网络,但性能已经不可同日而语了。也许到现在为止,还有很多读者朋友比较好奇,为什么神经网络会“学习”(之前的博客已经介绍过),甚至拥有很好的“记忆”。
近些年,笔者接触比较多的应用神经网络的领域就是自动驾驶,所以会更加熟悉,其它领域同理,后面的举例主要也以自动驾驶相关关键词为主,并尽量用通俗的文字把这个概念(神经网络会“学习”,神经网络会“记忆”)解释清楚,不足之处,欢迎共同交流。
2 神经网络
神经网络能够记忆,是如何实现的,且往下看。首先温习一下神经网络的基本结构,如下图所示。
2.1 结构
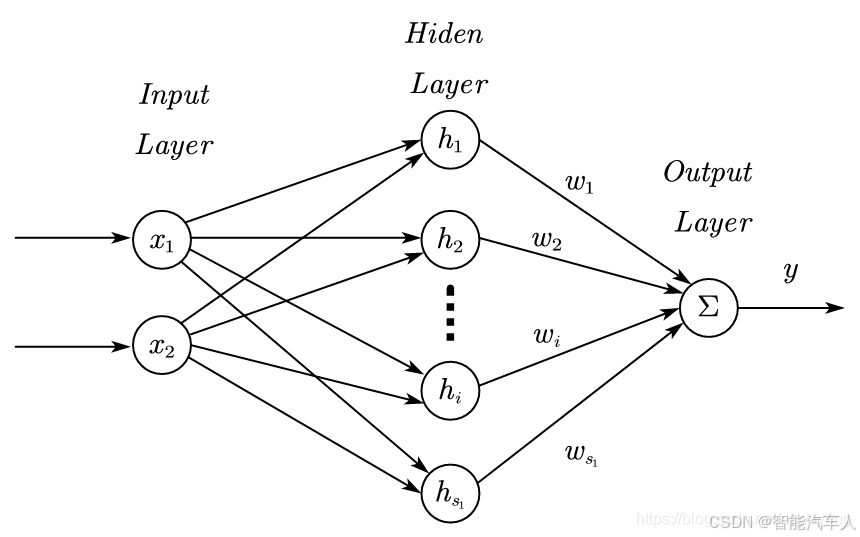
我们先一起看看神经网络的结构(结合上图):
- 神经元(上图中的圆圈): 神经网络的基本单元是神经元。每个神经元接收来自其他神经元的输入,对这些输入进行加权求和,然后通过一个激活函数进行非线性变换,最后将结果输出给其他神经元。
- 权重 (上图中的
): 权重是神经元之间连接的强度。通过调整权重,神经网络可以学习不同的模式和关系。
- 激活函数 (两层神经元之间的连线上): 激活函数引入了非线性因素,使得神经网络能够学习非线性函数。常见的激活函数包括 sigmoid、ReLU、tanh 等。
- 层 (上图中的Layer): 神经网络由多个层组成,包括输入层、隐藏层和输出层。每一层都包含多个神经元。
- 输入层(Input): 接收输入数据。
- 隐藏层(Hiden): 对输入数据进行特征提取和转换。
- 输出层(Output): 输出最终结果。
后续发展,很多网络层出不穷,如FN,RNN,CNN以及Transformer等,都是由上述基本的网络结构发展而来。
2.2 核心
概念: 在神经科学和人工智能中,“记忆”并非指像计算机硬盘那样精确存储数据块。它指的是系统根据过去的经验(数据)改变其内部状态(参数/连接强度/激活模式),从而在未来遇到相似或相关信息时做出适应性反应(预测/决策/生成) 的能力。这是一种统计性、关联性、模式化的记忆。
神经网络概念来源于生物的神经结构,因此先从生物学解释其原理。
(1) 生物学基础:神经元与突触可塑性
生物神经元是神经系统的基本单元。它们通过突触相互连接,传递电化学信号。记忆的关键在于突触可塑性:
-
赫布理论 (Hebbian Theory): “一起激活的神经元会连接在一起”。当两个神经元(A和B)频繁地、几乎同时地被激活时,它们之间的突触连接强度会增加。这意味着A激活时,未来更容易激活B。这是学习和记忆形成的基础机制。
-
长时程增强 (Long-Term Potentiation, LTP): 高频刺激后,突触传递效率的持久性增强。这被认为是学习和长时记忆形成的细胞水平机制。重要的信息会留下更强的连接。
-
长时程抑制 (Long-Term Depression, LTD): 低频或不同步刺激后,突触传递效率的持久性减弱。这被认为是遗忘不相关信息的机制,或用于精细化记忆。
-
短期记忆 (Short-Term Memory): 神经元本身通过持续的放电模式或短暂的生化变化(如钙离子浓度变化) 来暂时维持信息(几秒到几分钟),这类似于工作记忆。
-
长期记忆 (Long-Term Memory): 通过基因表达和合成新的蛋白质,改变神经元的结构(如生长新的树突棘、形成新的突触),将短期记忆转化为更稳定的长期存储。这体现在突触连接强度的持久性改变上。
总结生物神经元的“记忆”:
-
机制: 突触连接强度的变化(增强或减弱),以及神经元活动模式。
-
形式: 不是精确复制,而是关联性模式(“当遇到X,联想到Y”)。
-
存储: 信息分布式存储在庞大网络的连接权重中。
-
提取: 当部分模式(线索)被激活时,整个关联模式有被重新激活的倾向。
(2)人工神经网络中的“记忆”功能
人工神经网络(ANN)从生物神经网络中汲取灵感。它们的“记忆”功能体现在以下几个方面:
-
权重作为长期记忆
-
核心机制: 神经网络学习的过程就是通过训练数据(过去的经验)不断调整神经元之间连接的权重。这些权重决定了信号在网络中传递的强度和方向。(很多模型都有权重文件,这个比较容易理解)
-
类比: 这类似于生物突触强度的改变。训练完成后,这些权重值就固定下来,它们编码了网络从训练数据中学到的所有模式、规律和知识。
-
记忆形式: 这是一种隐式的、分布式的、统计性的长期记忆。网络不是存储具体的训练样本,而是存储了数据的内在结构和关联关系(例如,“猫”的图像通常具有某些像素组合模式,“巴黎”这个词与“法国”、“埃菲尔铁塔”等词有强关联)。
-
-
激活状态作为短期/工作记忆
-
核心机制: 当输入数据(如一个词、一张图片)进入网络时,它会在网络中逐层传播,激活不同的神经元。这些神经元的激活值代表了网络在处理当前特定输入时的内部状态。
-
类比: 这类似于生物神经元当前的放电活动。
-
记忆形式: 这是短暂的、上下文相关的短期记忆或工作记忆。它保存的是网络处理当前任务所需的即时信息。一旦输入结束或处理下一个输入,这些激活值通常会被重置或覆盖(在非循环网络中)。
-
-
专门架构实现更复杂的记忆
-
循环神经网络 (RNN):
-
核心机制: RNN 神经元不仅接收当前输入,还接收自身在上一时间步的激活状态(称为
hidden state)。这个隐藏状态就像一个“记忆单元”,随着时间步推移在网络内部循环传递。 -
记忆功能:
hidden state理论上可以无限期地携带之前所有时间步的信息(尽管实践中存在梯度消失/爆炸问题)。它允许网络具有时序记忆,处理序列数据(如句子、语音、视频帧),让当前的输出依赖于之前的历史输入。
-
-
Transformer 架构 (自注意力机制):
-
核心机制: Transformer 摒弃了循环结构,完全依赖自注意力机制。在处理序列时(如一个句子),它对序列中的所有元素(词)同时计算注意力权重。
-
记忆功能: 自注意力机制允许模型在处理序列中的某个元素(如第5个词)时,直接关注并加权整合序列中任何位置(如第1、2、3、4个词)的信息,无论距离多远。
-
优势:
-
全局记忆访问: 克服了RNN顺序处理的瓶颈,能直接获取序列中任何位置的历史信息(只要在上下文窗口内)。
-
关联性记忆: 注意力权重动态计算当前元素与历史元素的相关性,只提取最相关的信息用于当前计算,效率更高。
-
并行化: 所有位置的计算可同时进行,极大提高训练速度。
-
-
-
(3)以大模型为例说明(以GPT为代表)
以当前主流的大语言模型GPT(Generative Pre-trained Transformer) 为例,其强大的语言生成和理解能力正是基于多层次记忆功能的协同作用。
1)长期记忆:预训练权重中的知识存储
GPT 通过海量文本数据(如书籍、网页、论文)预训练,其数十亿甚至数万亿的权重参数存储了人类语言规律、常识知识和世界事实,这是长期记忆的核心:
- 语法知识:权重编码了 “主谓一致”“时态变化” 等语法规则,使生成的句子符合语言规范。
- 语义关联:存储了 “同义词替换”(如 “高兴” 与 “开心”)、“概念层级”(如 “狗→哺乳动物→动物”)等语义知识。
- 世界事实:记住了 “地球是行星”“巴黎是法国首都” 等客观事实,能在问答中准确输出。
- 举例: 当你问GPT“法国的首都是哪里?”时,它不需要去查数据库,而是利用其权重中编码的强关联(“法国”->“首都”->“巴黎”)来生成答案。这种知识是模型“记住”的(通过权重固化)。
2)工作记忆:上下文窗口中的动态信息处理
GPT 的上下文窗口(Context Window) 是工作记忆的载体。用户输入的 prompt(提示词)和模型生成的前文会被纳入上下文窗口,模型通过注意力机制动态关注窗口中的关键信息,实现对当前任务的记忆:
- 例如,用户问:“小明有 3 个苹果,小红有 5 个,两人一共有几个?”GPT 的上下文窗口会 “记住” 数字 3 和 5,通过权重中存储的 “加法规则” 计算出 8。
- 长文本生成中,上下文窗口会记住前文的剧情、人物关系,确保后文逻辑连贯(如小说创作中角色性格的一致性)。
3) 短期记忆:激活值的实时特征传递
在生成每个 token(如单词、字)的过程中,GPT 通过前向传播产生的激活值实时处理上下文信息。例如,生成句子 “人工智能的发展离不开____” 时,输入的 “人工智能” 会通过网络层计算产生激活值,这些短期记忆引导后续层调用权重中 “人工智能与技术 / 算法相关” 的长期知识,最终输出 “算法创新”。
3 总结
通过两篇博客的神经网络介绍:《神经网络为什么会学习》和《神经网络为什么会记忆》,相信读者朋友们对神经网络有了更深的认识,对于后续模型的掌握,理解相应的也会更深刻。
人工神经网络确实是一个伟大的发明,使得计算机技术取得飞跃式的发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)