【AI论文】驾驭不确定性:面向长周期大语言模型(LLM)智能体的熵调制策略梯度法
【摘要】本研究针对长周期任务中基于大语言模型的智能体面临的信用分配难题,提出熵调制策略梯度(EMPG)框架。该框架通过分析策略梯度与熵的内在关联,创新性地利用步骤级不确定性动态调整学习信号:放大自信正确动作的更新,惩罚自信错误,并减弱不确定步骤的干扰。实验表明,EMPG在WebShop等三项挑战性任务中显著提升性能(如ALFWorld任务成功率提高8.1%),同时增强训练稳定性。研究揭示了LLM策
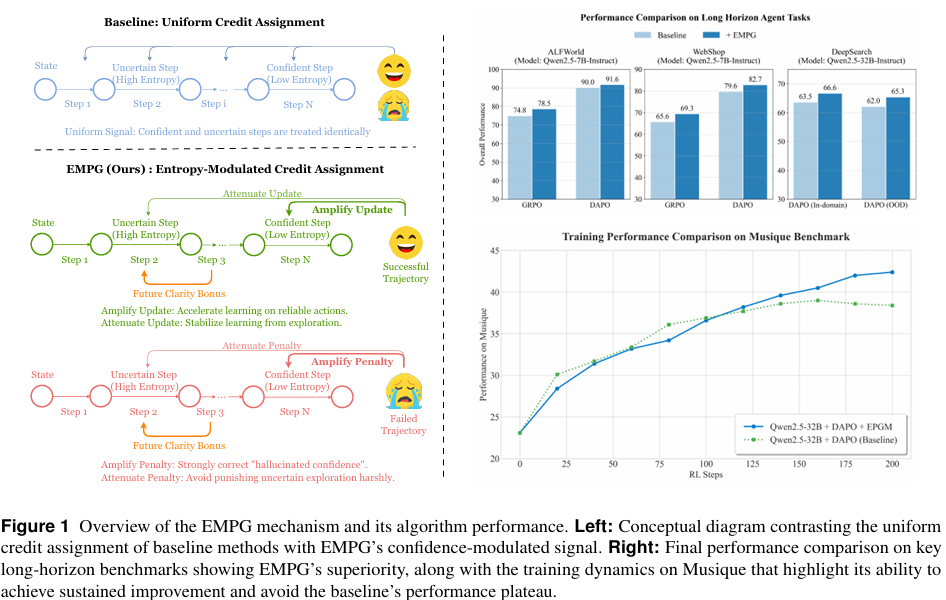
摘要:在长周期任务中,近期基于大语言模型(Large Language Models, LLMs)的智能体面临着一个重大挑战:基于稀疏结果的奖励机制使得为中间步骤分配功劳(归因)变得十分困难。此前的方法主要聚焦于创建密集奖励信号以指导学习,要么通过逆强化学习等传统强化学习技术实现,要么借助过程奖励模型提供分步反馈。在本文中,我们发现了大语言模型学习动态中的一个根本性问题:策略梯度的大小本质上与熵相关联,这导致对于自信的正确动作,更新幅度小且效率低下,而对于不确定的动作,大幅更新则可能使系统不稳定。为解决这一问题,我们提出了熵调制策略梯度(Entropy-Modulated Policy Gradients, EMPG)框架,该框架根据分步不确定性及最终任务结果重新校准学习信号。EMPG放大了对自信正确动作的更新,惩罚了自信的错误,并减弱了来自不确定步骤的更新,从而稳定了探索过程。此外,我们还引入了一个面向未来清晰度的奖励项,鼓励智能体寻找更具可预测性的解决方案路径。通过在WebShop、ALFWorld和Deep Search这三项极具挑战性的智能体任务上开展全面实验,我们证明EMPG实现了显著的性能提升,且大幅优于强大的策略梯度基线方法。项目主页位于https://empgseed-seed.github.io/。Huggingface链接:Paper page,论文链接:2509.09265
研究背景和目的
研究背景:
近年来,随着大型语言模型(LLMs)的发展,自主智能体在处理复杂、多步骤任务方面取得了显著进展。然而,在长程任务中,基于LLMs的智能体面临一个核心挑战:稀疏的、基于结果的奖励机制使得为中间步骤分配信用变得困难。在许多现实场景中,如网页导航、软件工程和深度搜索,反馈仅在完整任务生成完成后才可用,这导致标准强化学习(RL)算法难以辨别关键的中间步骤。传统的解决方法主要集中在通过逆向强化学习或过程奖励模型(PRMs)提供逐步反馈来创建密集奖励信号,但这些方法往往存在计算成本高、依赖人类先验知识或泛化能力差等问题。
研究目的:
本研究旨在解决长程任务中LLMs智能体训练的信用分配问题,提出一种新的框架——熵调制策略梯度(Entropy-Modulated Policy Gradients, EMPG),通过利用智能体在“推理-行动”步骤中的内在不确定性,动态重新校准策略梯度,从而在不依赖外部密集奖励信号的情况下,提高学习效率和稳定性。具体而言,EMPG框架旨在放大对自信且正确动作的更新,惩罚自信但错误的动作,并减弱对不确定步骤的更新,以稳定探索过程。
研究方法
1. 理论基础分析:
研究首先从理论上分析了策略梯度方法中的基本动态问题,即策略梯度的幅度与策略熵之间的固有耦合。通过数学推导,证明了对于标准softmax策略,分数函数的期望范数与策略的Rényi-2熵是单调相关的。这一发现揭示了高熵(不确定)动作自然会产生大梯度,而低熵(自信)动作则产生小梯度的双重挑战,导致学习效率低下和不稳定。
2. EMPG框架设计:
基于上述理论分析,研究提出了EMPG框架,该框架包含两个主要组件:
- 自校准梯度缩放:通过动态调制基于步骤不确定性的策略梯度,放大对自信且正确动作的更新,减弱对不确定步骤的更新。具体实现中,使用基于熵的缩放因子来重新加权优势函数,确保学习信号的幅度适当。
- 未来清晰度奖励:引入一个额外的奖励项,鼓励智能体选择导致更可预测后续状态的动作。该奖励项与下一步状态的策略清晰度(即低熵)成正比,通过提供内在信号引导智能体进行有目的的探索。
3. 算法实现:
EMPG算法的实现包括以下步骤:
- 步骤级熵计算:在每个训练批次中,计算所有动作步骤的熵。
- 归一化处理:使用批次最小-最大归一化对步骤级熵进行归一化。
- 调制优势计算:根据归一化后的熵值计算自校准梯度缩放因子和未来清晰度奖励,并调制原始优势函数。
- 最终优势归一化:对整个批次的调制优势进行零均值归一化,以减少方差并确保稳定训练。
4. 实验设计:
研究在三个具有挑战性的长程智能体任务上进行了实验:WebShop、ALFWorld和Deep Search。实验中使用了不同规模的Qwen2.5模型,并比较了EMPG与强基线方法(如GRPO和DAPO)的性能。
研究结果
1. 性能提升:
实验结果表明,EMPG在所有任务和模型规模上均显著优于基线方法。例如,在ALFWorld任务上,使用Qwen2.5-1.5B模型的EMPG将GRPO的平均成功率提高了8.1个百分点,将DAPO的平均成功率提高了7.3个百分点。在更复杂的Deep Search任务上,EMPG将DAPO的整体平均分数从62.0提高到65.3,实现了3.3个百分点的显著提升。
2. 泛化能力:
EMPG不仅在域内(ID)任务上表现优异,在域外(OOD)任务上也展现出强大的泛化能力。例如,在Deep Search的OOD任务上,EMPG实现了3.9个百分点的性能提升,表明EMPG通过学习处理不确定性的基本技能,获得了更具韧性的问题解决方法。
3. 训练稳定性:
EMPG显著增强了训练过程的稳定性和鲁棒性。通过可视化KL损失动态,发现基线方法在训练后期经常出现“策略崩溃”现象,而EMPG增强的智能体在整个训练过程中保持低且稳定的KL损失,有效防止了过于激进的策略更新导致的发散问题。
研究局限
尽管EMPG框架在多个长程任务上取得了显著的性能提升和稳定性增强,但仍存在一些局限性:
- 模型依赖性:EMPG的性能提升在一定程度上依赖于底层LLM模型的能力。对于非常小的模型,EMPG可能无法充分发挥其优势。
- 超参数调优:EMPG引入了额外的超参数(如k和ζ),这些超参数需要针对具体任务进行调优,增加了实现的复杂性。
- 计算开销:虽然EMPG不依赖价值模型,但步骤级熵的计算和归一化处理仍带来一定的计算开销,尤其是在大规模模型和复杂任务上。
未来研究方向
1. 多任务与跨领域应用:
未来研究可以探索EMPG在更多样化的长程任务和跨领域场景中的应用,验证其普适性和鲁棒性。例如,在 embodied AI(具身AI)和 multi-agent collaboration(多智能体协作)等领域应用EMPG框架。
2. 更高效的熵估计方法:
研究可以探索更高效的熵估计方法,以减少计算开销。例如,使用蒙特卡洛 dropout 或模型头集成的方法来估计不确定性,可能提供更直接的链接到梯度动态分析。
3. 自适应超参数调整:
开发自适应超参数调整机制,使EMPG能够在训练过程中动态调整超参数(如k和ζ),以进一步减少人工调优的需求,提高框架的易用性和性能。
4. 结合其他强化学习技术:
探索将EMPG与其他先进的强化学习技术(如模型基强化学习、分层强化学习等)相结合,以进一步提升长程任务中智能体的性能和效率。
5. 理论分析与扩展:
进一步深化EMPG框架的理论分析,探索其在更广泛政策梯度方法中的适用性和潜在扩展。例如,分析EMPG在不同类型策略(如确定性策略、随机策略)中的表现,并探索其在连续控制任务中的应用可能性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献130条内容
已为社区贡献130条内容

所有评论(0)