AI学习日记——逻辑回归
目录
特征缩放
目的:将所有特征数值(n
xn)映射到大致相同的数值范围内,从而加速梯度下降的过程
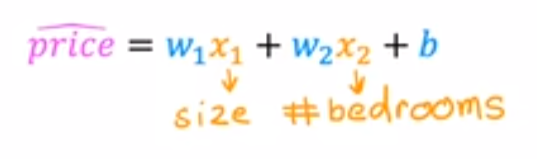
当x1(size)=2000, x2(bedrooms)=50,则1的数值要小,
2的数值要大,保证特征散点图分布均匀。
归一化处理
目的:将数据变换到[0, 1]区间内。
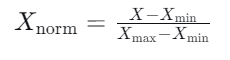
-
适用:适用于数据分布范围边界有限且不易受异常值影响的场景(如图像处理中像素强度归一化到[0,1])。
均值归一化处理
目的:将数据变换为均值为0,标准差为1的正态分布。( [-1,1] / [-3,3] )
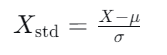
-
适用:适用于数据分布没有明显边界或存在异常值的场景,这是最常用的方法。特别是当数据近似服从正态分布时,效果更好。
逻辑回归
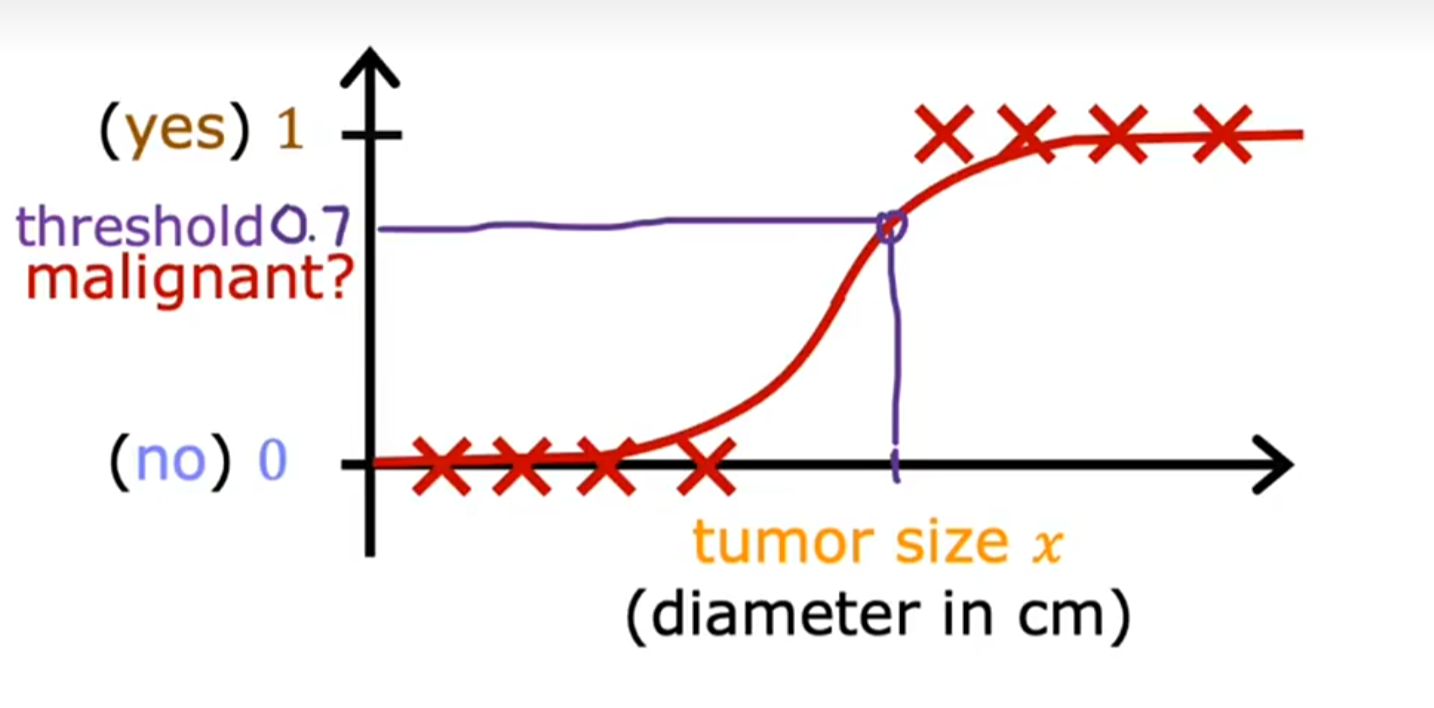
定义:是一种用于解决分类问题的统计学习方法,尤其适用于二分类任务(如预测事件发生与否)。
为什么不能用线性回归解决分类问题?
因为当单一样本点距离其他点较远的时候(即离群点),决策边界将偏移,导致直线模型预测不准
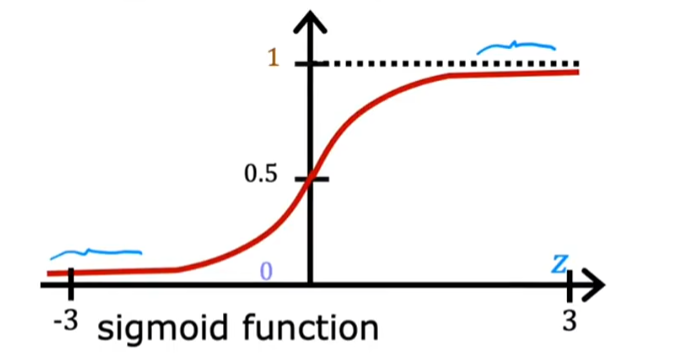
Sigmoid函数
定义:是一种非线性激活函数,常用于二分类问题,其输出范围为0到1,适合处理概率预测。
其数学表达式为: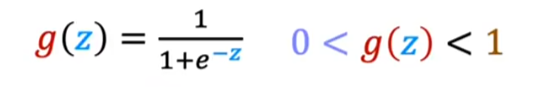
函数图像:
决策边界
定义:在特征空间中,决策边界将不同类别的数据点分开,使得边界一侧的数据点属于一个类别,另一侧的数据点属于另一个类别。
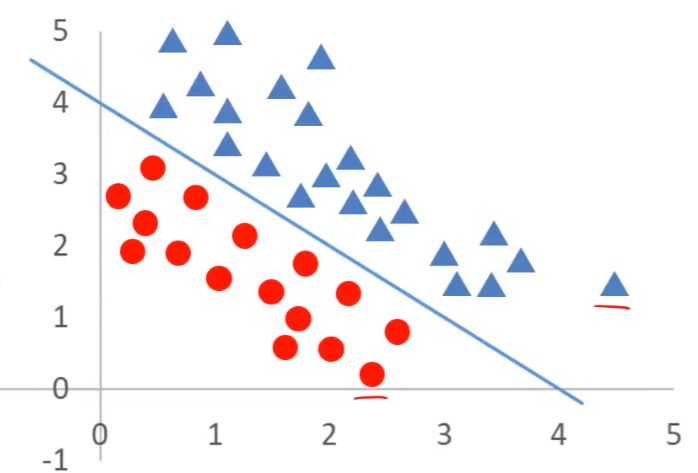
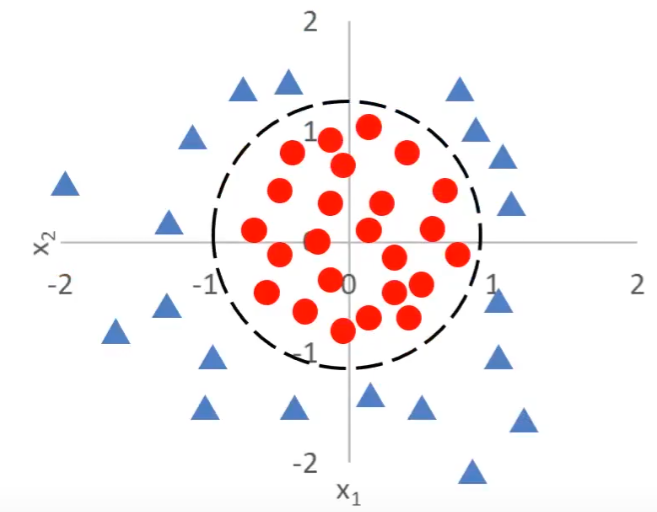
如以上两张图片所示,三角形为类别1,圆形为类别2,函数线是他们的决策边界,将两种类别区分开。
图1的中的直线公式是x+y-4=0,当x+y-4>0,对应着三角形;当x+y-4<0,对应着圆形。
图2的曲线公式是,当
,对应着三角形,
对应着圆形。
由此可见,决策边界的公式的正负对应两种类别,完美符合刚刚的sigmoid函数,我们将决策边界的公式代入到sigmoid公式的因变量z中,即可准确预测复杂分类问题下的样本类别。
损失函数
可不可以直接沿用线性回归的损失函数公式J?
不可以。如下图所示,线性回归的损失函数值先减后增,便于找到最小值;然而逻辑回归的损失函数起伏不断,多个极小值点,不利于找到最小值。
因此我们新设计了一个逻辑回归的损失函数,公式如下:
其中P(xi)为即为刚刚代入后的sigmoid公式(预测值0~1),yi为实际的类别标签(实际值0/1)。
其中-log(x)图像如下,x越接近0越大,越接近1越小。
损失函数J中的设定是当实际值yi是1时,x越接近0越大,越接近1越小;当实际值yi是0时,x越接近1越大,越接近0越小,符合损失函数定义。
总结的损失函数公式: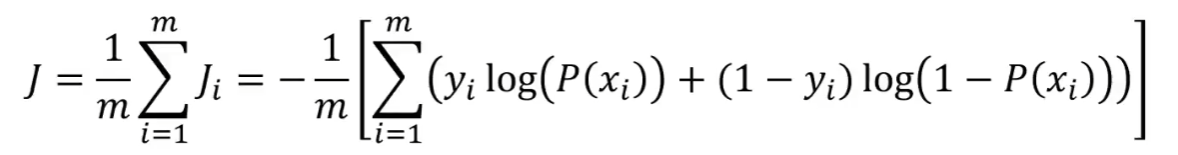
最终通过梯度下降法求得min(J)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)