Murati的thinking machines的论文到底讲了什么
这几周比较忙,也没看啥也没写啥(主要在打街霸6的天梯),但是这个论文我扫了一眼还是有价值的,所以给大家解读一下这个论文:https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/其实对于这个解决了什么问题,没那么抽象比如让gpu算一个浮点数,基本算几次可能结果都不一样。浮点数最后影响了概率,概率分布和采样影
这几周比较忙,也没看啥也没写啥(主要在打街霸6的天梯),但是这个论文我扫了一眼还是有价值的,所以给大家解读一下
这个论文:https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
其实对于这个解决了什么问题,没那么抽象
比如让gpu算一个浮点数,基本算几次可能结果都不一样。浮点数最后影响了概率,概率分布和采样影响了你从tokenzier取哪些字吐给客户端
再比如让LLM去给一个指定的指标打分,你发现即使是相邻的两次它也一定给出不太一样分数,比如5.5和6.5(当然这个问题没有上一个那么恰当,因为本身如果你问题太抽象,那么给分数,每次不一样也很正常)
那为什么这样呢?
Arixv上的有个论文的说法(2506.09501)
GPU中的浮点算术具有非结合性,即(a+b)+c ≠ a+(b+c),源于有限精度和舍入误差。这一特性直接影响Transformer架构中注意力分数和logit的计算……并行线程执行顺序不同即可产生不同结果。
我其实是很buying这个逻辑的,这也是我以前解释这个问题的说法
说白了就是gpu的浮点数在左核加法加的时候,你看着加法可以满足结合律,但是不是的
比如:
-
(0.1 + 1e20) - 1e20 → 0
-
0.1 + (1e20 - 1e20) → 0.1
这快看不懂为什么要算加法,先去修线性代数

文章举了一个代码例子
import randomvals = [1e-10, 1e-5, 1e-2, 1]vals = vals + [-v for v in vals]results = []random.seed(42)for _ in range(10000):random.shuffle(vals)results.append(sum(vals))results = sorted(set(results))print(f"There are {len(results)} unique results: {results}")# 输出# 有102种唯一结果
大多数理论认为,如果多个并发线程完成顺序不可控,并且累加顺序依赖于线程完成先后(比如原子加法atomic add),那么累加顺序不确定,最终结果也不确定。
但事实上,虽然atomic add会导致非确定性,LLM前向推理并没有用到atomic add,也没有因并发造成非确定性!
那到底哪种情况需要atomic add?????
通常GPU会在很多核心(SM)并发启动程序。如果所有核心间必须通信且要累加到同一个元素,则会用atomic add也就是源自加(fetch-and-add),保证所有加法都计入但不保证顺序。
比如要用100个核心对100维向量做累加(如torch.sum),最终都要化为单个元素。atomic add会导致每次运行结果都可能不同(即run-to-run non-determinism)。
但实际情况是,神经网络库通常选择不用atomic add,尤其是在LLM前向过程中——这样多数kernel都是确定性的。
主要原因包括:
-
通常可以在“batch”维度并行,无需在reduce维度并行。比如500个向量,每个核心处理一个完整向量;你如果每个核心处理一个完整的向量那就不存在咱们说的多gpu导致的un-to-run non-determinism,对吧?
-
神经网络库采用多种策略,无损效率实现确定性,如“分片(tree)归约”,或用semaphore保证确定顺序。
atomic add带来的性能损耗,对绝大部分神经网络运算来说微不足道(极少数如scatter_add、FlashAttention backward除外)。
那么结论就是:LLM前向过程无须atomic add,是run-to-run deterministic的。

那似乎如果不搞atomic add就不会发生文章前面提的两种问题,也就是给定一个确定的输入,一定会有确定的输出
但是事实上并不是这样的,所以还有其他的因素吗?
量不变性(Batch invariance)与确定性
虽然从推理服务器角度,给定同样输入总产出同样结果(即决定性算法定义),但系统是否确定,还取决于外部请求——如并发批量。举例:
如果每个用户请求的结果依赖于其他同时请求的数量(比如batch-norm),对于单个用户来说,结果就变得不可预测。
实际上,LLM推理的结果确实依赖于并发请求数量。不是因为信息泄漏,而是前向传播缺乏“批量不变性”——即输出受batched请求数量影响。
通常,比如矩阵乘法是run-to-run deterministic,但并不批量不变——即改变batch size,单个元素的结果可能变。
例如:
import torchtorch.set_default_device('cuda')B = 2048; D = 4096a = torch.linspace(-1000, 1000, B*D).reshape(B, D)b = torch.linspace(-1000, 1000, D*D).reshape(D, D)out1 = torch.mm(a[:1], b)out2 = torch.mm(a, b)[:1]print((out1 - out2).abs().max()) # 结果能差出去很大
多次运行总是确定性输出,但不同batch size下数值不同。
所以对于单个用户来说,别人是否同时请求(即batch size)是不可控的,导致非确定性!
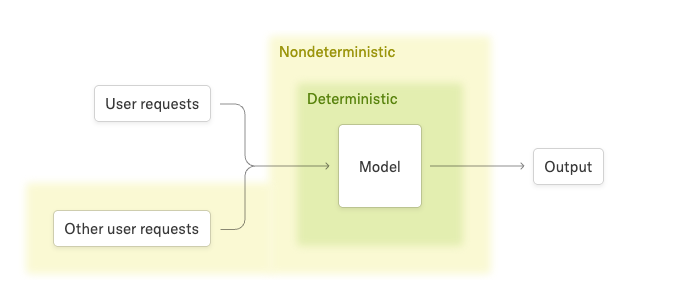
几乎所有LLM推理终端非确定性,根本原因是服务器负载/批量大小变化,这种非确定性不限于GPU,用CPU, TPU也一样存在。所以,想避免非确定性,必须让所有关键内核做到批量不变性。
那怎样做到和函数批量不变性?
Transformer要批量不变,每个kernel都得满足。其实,点对点运算基本批量不变(PyTorch如此,但个别CPU优化例外)。主要需要关注 reduction类操作比如这些算子。
-
RMSNorm
-
矩阵乘法
-
注意力(Attention)
批量不变 RMSNorm
采用“数据并行”(data-parallel),每个核心处理一个batch元素,确报批量操作不会改变归约顺序。例如:
def rms_norm(x, weight):return x * torch.rsqrt(torch.mean(x ** 2, dim=-1, keepdim=True)) * weight
只要每个元素归约顺序固定,不受batch size影响,就保证批量不变性。增加batch大小,只是每核多处理几行。
如果batch特别小,核心数多于batch,此时常规做法如atomic add或split reduction就变成非批量不变。要想彻底优化小batch性能,可采用始终过度并行的策略,不过实际意义有限。
对于标准矩阵乘来说,我们就批量不变矩阵乘法
其实和上一个思路同理,也是将输出分块分片(data-parallel)。但有些算子如tensor-core指令必须批量操作整块tile,否则小批量下会浪费计算,
比如batch很小则需要分片归约(split-k matmul),这会破坏批量不变性。那要是这样的话,解决思路就是只用一种kernel配置,所有形状都用,牺牲部分性能但换取确定性。
论文里实测发现性能损失约20%左右,这个还是比较要命的,因为这百分之20就意味着你同capability的推理规模要多百分之20-30的卡来fulfill。。。
批量不变注意力(Attention)
注意力计算涉及两个归约维度(特征和序列),且推理优化(如chunked prefill, prefix caching)会影响处理过程,必须保证无论批处理多少、token划分如何,单词元的归约顺序都一致。
解决思路上:
-
不管KV Cache长度如何,强制所有keys/values在Attention kernel之前就排好顺序,这样保持归约顺序一致。但是这么做其实挺要命的,因为它打破了现代推理的核心page kv cahce。vllm,sglang之类的framework就不能用了,但是tensorRT-LLM我记得似乎没搞pagekv,它反而牛逼了

-
对于常见的split-reduction(Split-KV / FlashDecoding),为了并行而分片归约时,应将分片大小固定(splitting by fixed size),这样每次调用分片数随输入变但单次顺序一样,最终达到批量不变性。
然后作者们拿qwen做了个demo,把于vLLM的FlexAttention后端以及torch.Library实现了一个“批量不变”内核的推理demo
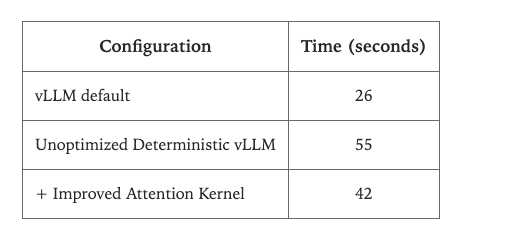
多个损失累计基本上性能损失一半

,生产肯定是不能用的
但是...
论文举例了一个非常合适的场景
(强化学习)部分和确定性推理的关系,哈哈哈
LLM 在 RL(比如 RLHF、在线强化学习微调)里的训练与推理,有个长期工程痛点:推理阶段数值不一致,会让“本该是on-policy(真正的策略采样)”的RL变成off-policy(采样、训练策略有隐藏偏差)。
什么意思?
1. On-policy RL:
-
理想状态下,训练和采样完全同步:trainer和sampler碰到同样的输入,做同样的推理,数值完全一致(比如模型 logits/logprobs/buffer都一样),训练出来的策略等于在自己采样的轨迹上优化。
2. 非确定性时会出现什么?
-
如果推理用的kernel、api和训练时不同(比如你上线的是另一个推理引擎,或batch size没控制好),或者同一模型、请求因为批量/并发造成数值微小变化,
-
那么可能trainer和sampler看到的同一个轨迹,logprobs不一样,reward不一样,导致整个训练“离线”——需要各种off-policy修正(比如重要性加权、KL散度补偿等),否则RL训练会“发散”、reward变坏。
-
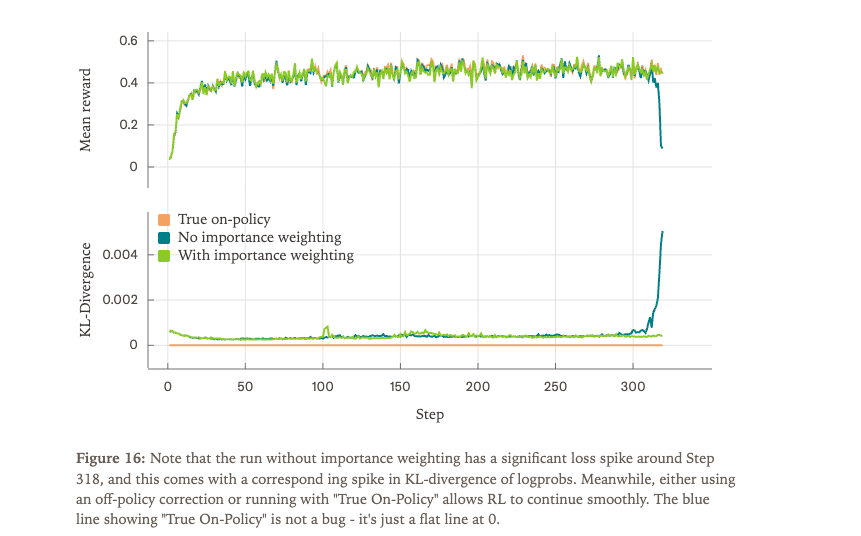
就如论文里的实验:只要推理策略和训练策略有数值偏差,reward会突然崩溃、KL散度急剧上升。
3. 论文的解决方案
-
作者用“批量不变”kernel确保训练和采样无论什么情形(并发、batch、推理api),完全位级一致,实现真正的on-policy RL(KL散度为0,reward平滑提升)。
-
这个做法让所有RL过程里的采样(比如环境反馈、奖励、logprob计算)都与训练完全同步,可以用最优、理论保证的on-policy算法而无需各种纠正。
对于训练reward和KL这么重要的东西,似乎你降点推理速度就是训慢点而已,但是即使是两倍时间的RL,为了这个准确性也是值得的(post train本来也没多长时间)
这也就是实际项目里或者这篇论文里的真正的工程意义

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)