pretrain-Alignment范式的强大与极限——李宏毅大模型2025第五讲笔记
当前大语言模型(LLM)训练的三阶段范式已经成熟:1. 预训练(Pre-training)2. 有监督微调 / 指令微调(SFT, Supervised Fine-tuning)3. 人类反馈强化学习(RLHF)其中,第2、3阶段合称为 对齐(Alignment),目标是让模型行为符合人类偏好。
当前大语言模型(LLM)训练的三阶段范式已经成熟:
1. 预训练(Pre-training)
2. 有监督微调 / 指令微调(SFT, Supervised Fine-tuning)
3. 人类反馈强化学习(RLHF)
其中,第2、3阶段合称为 对齐(Alignment),目标是让模型行为符合人类偏好。
课程详细内容
1、对齐 ≠ 模型能力的“源泉”,而是“激活器”
* 对齐数据极少: Llama 2 只用了约 2.7 万条高质量数据;LIMA 甚至只用 1000 条就能让模型表现良好。
* 对齐更像“画龙点睛:模型能力早已在预训练中形成,对齐只是“激活”这些能力,而非“灌输”新知识。
* 数据质量 >> 数量: 第三方百万级数据不如自制几千条高质量数据有效。
2、对齐只是行为调整,而非知识灌输
* 知识蒸馏盛行: 很多“低成本训练”其实是用 GPT-4 等强模型生成对齐数据,训练自己的小模型。
* 数据选择策略奇特但有效:如“选最长的回答”、“用弱智吧问题”、“非问答式续写”都能提升模型表现。
* 对齐难以教授新知识:如果预训练模型完全不会某类问题,对齐阶段强行训练反而会导致性能下降。
3、预训练:模型能力的“根基”
* 数据多样性是关键:同一内容需要以多种方式描述,预训练后的模型才具备泛化能力。
* 部分多样性即可泛化:只要部分实体有多样描述,模型就能学会泛化,应用到其他实体上。
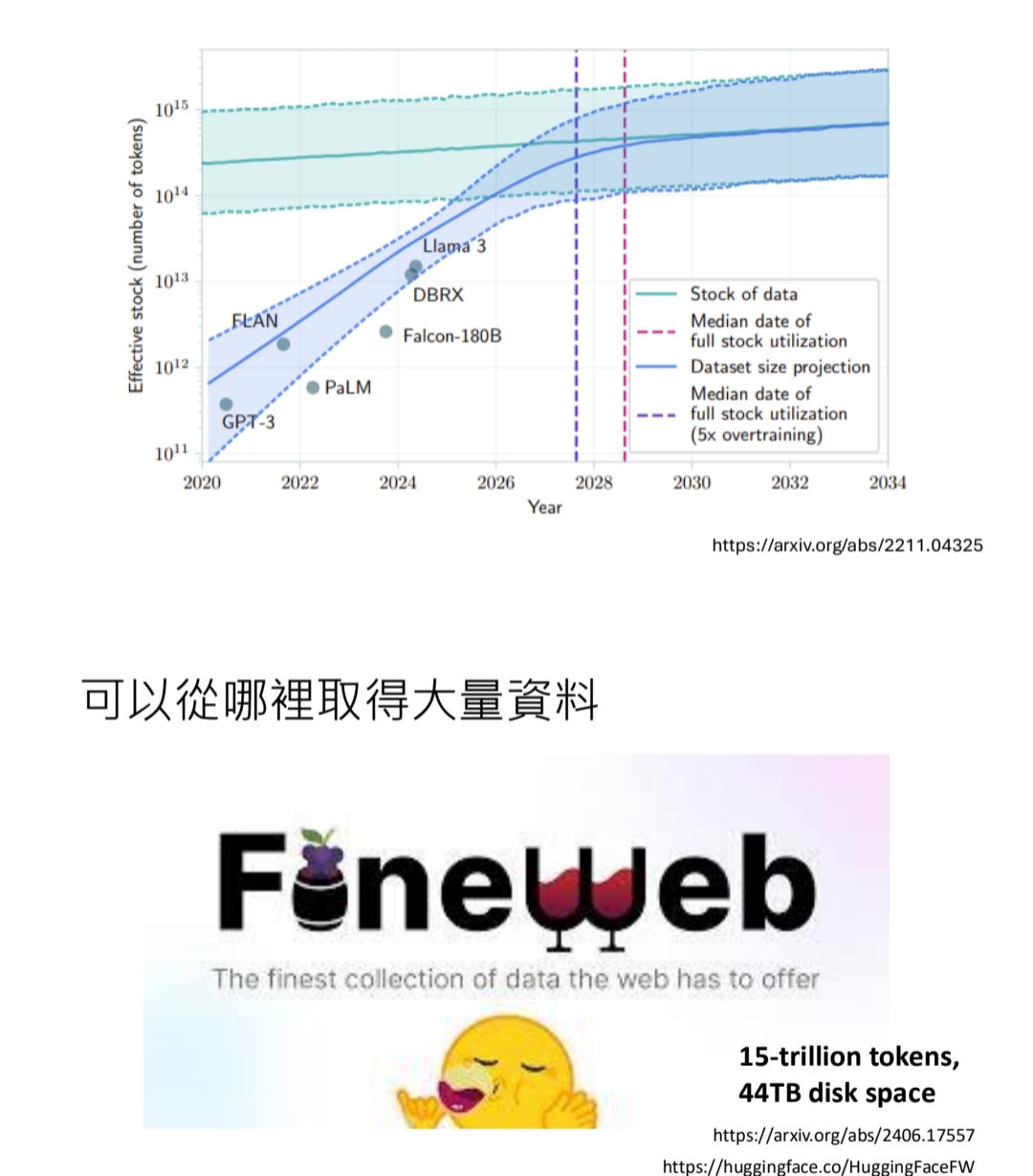
* 数据量巨大: Llama 3 预训练用了 1.5T tokens,DeepSeek-V3 用了 14.8T tokens。(下文截图是一个预测,在2028年前后,模型训练会用尽人类的所有知识)
* 数据不是越多越好:在算力固定下,重复数据收益递减,应优先保证“多样性”而非“规模”。
4、对齐的极限与预训练的“烙印”
* 对齐只是“压抑”了模型不当行为,并未删除其内部知识。
* 预训练只是“记住”而非“学会”。 预训练塑造了一个“混乱但博学”的怪物,对齐只是给它戴上了“问答”的面具。
5、结论:
1)预训练模型本身已具备“指令遵循”能力
- 研究发现,仅通过“控制解码”或“轻量规则”,未对齐的 base 模型也能完成指令任务。
- 模型早已学会“如何回答”,对齐只是让它“愿意回答”并“格式化输出”。
6、课程延伸思考
- 如何设计更有效的“对齐”方法,真正影响模型内部知识?
- 未来研究方向之一:是否可以不依赖 RLHF,仅通过预训练+规则控制实现对齐?
- 近期研究热点 如何在预训练阶段就“预防”偏见生成?
- 数据治理与模型安全

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)