又爱又恨浮点数:谈谈使用浮点运算遇到的几个问题
本文探讨了浮点数运算在计算机中的特点与应用问题。文章首先说明浮点数在AI、金融等领域的广泛应用,并指出其存储方式决定了存在不可避免的计算误差。接着分析了单精度与双精度浮点的指令差异和有效位数区别,强调单精度在精度上的损失。重点讨论了浮点溢出问题,包括INF和NAN的产生条件及连锁反应,通过实际案例展示了除零、负数开方、取模等导致的异常情况。最后建议使用系统宏进行防御性编程,并适当引入AI辅助解决问
一 前言
提到浮点运算,这几年大火的人工智能可谓是其主战场。神经网络训练要计算权重、系数,这些转化到底层,都是大量矩阵的乘加运算,运算的数据基本也都是浮点类型。除了人工智能,传统的金融、控制等领域,面对的也大都是浮点运算。
不同于整形数据,计算机中对浮点数大都是采用指数和小数分开存储的形式。这里说的分开,不是说分开到不同内存区域,而是说同一个32比特或64比特的浮点数,部分比特位表示指数,部分比特位表示小数。这是有国际标准的,感兴趣的小伙伴可以查阅相关资料。
计算机存储整形数据不存在误差,1就是1,2就是2,1和2之间本来就是空的。但是对于浮点数就不一样了,1.1和2.2之间还有无穷个数,计算机要做到没有误差,是办不到的。特定的存储形式就决定了其天然存在一个最小台阶,台阶之间的数是无法保存和使用的。不过在我们日常领域,这些误差并不会带来严重问题,或者说不影响我们的正常使用和功能的正确表达。
下面博主就分享一些自己使用浮点数过程中遇到的问题,部分问题还比较有代表性,希望能够帮助到入门的小伙伴。
二 单精度和双精度指令差异问题
以C语言为例,浮点数有float 和 double两种类型。一般将前一种称为单精度,后一种称为双精度。对于32位平台,单精度占用32bit,双精度占用64bit。很显然,双精度类型能够表示更大范围更小误差的浮点数。既然双精度如此好,单精度还有存在的必要吗?存在就是合理。双精度虽然好,但是占用内存更多,早期的资料也都说双精度速度要慢一些,不仅读写要慢,计算也慢。当然,这是对32位平台而言。对于64位平台,一次读取64bit数据,不应该存在字节对齐带来的性能损失。对于指令,有资料说float和double在运算时都是按double类型计算的,对此,博主在一款早期的ARM处理器上进行了汇编分析,证明不是这样的。
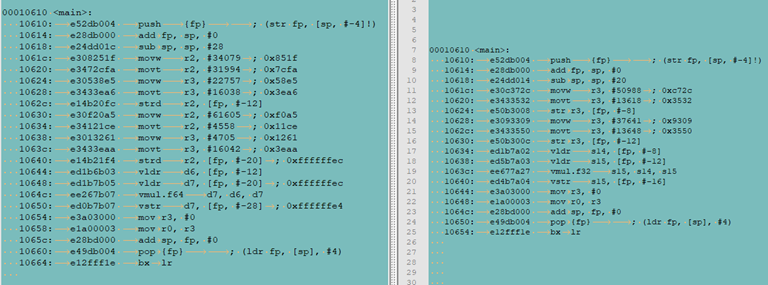
上图左边为double,右边为float,可以看到,double在内部占用8个字节,float占用4个字节。加载和存储指令,double为strd,float为str。乘法指令,double为vmul.f64,float为vmul.f32,总的来说,指令并不一样。也说明,double和float运算时并不都是按double进行的。
三 关于数据的有效位数
单精度浮点数是总共7位有效位,包含了小数点前后的非零开始的数字。双精度浮点数可以保证小数点后有6位有效数字。实测发现,如果两个单精度浮点数较大,则结果小数点部分位数可能就会被截断的比较多,而双精度浮点数则能够保留的会比较完整,比如能够保留到小数点后6位。所以,使用单精度浮点数,结果出现截断的情况要比双精度严重一些,在精度上损失大一些。但反过来想,如果一个数特别大,则小数点部分的影响就会特别小,数越大,影响越小,所以损失一些精度,对整体的影响应该是有限的。而且从结果来看,只要在运算范围内,单精度浮点数的运算结果也都是正确的。为什么强调这一点呢,因为我们经常使用printf %f类的输出进行程序调试,单纯查看这类日志输出,你可能得到运算不正确或误差特别大的结论,原因是这类输出语句在显示时可能对数据进行了截断。
举个例子,以下面代码为例:
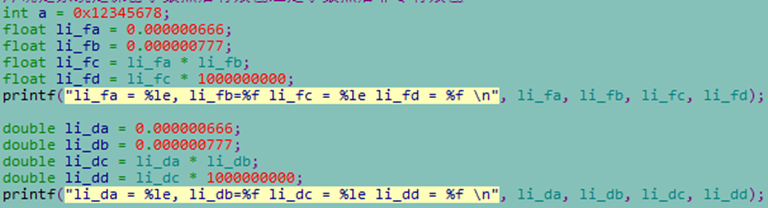
两个相对较小的数字分别按浮点和双精度浮点运算,都得了正确的结果:
li_fa = 6.660000e-07, li_fb=0.000001 li_fc = 5.174820e-13 li_fd = 0.000517
li_da = 6.660000e-07, li_db=0.000001 li_dc = 5.174820e-13 li_dd = 0.000517
四 关于浮点溢出问题
这是本博文要重点强调的一个点。浮点运算可能出现浮点溢出错误,在Linux系统下,终端会输出Floating point exception信息,进程会崩溃。而且这类问题存在随机出现,难以定位的困难。博主就遇到了几次,这里汇总记录。
为了便于后面场景中内容的理解,这里补充点相关内容。浮点数与整形数不同的一点是引入了INF和NAN,前一个表示到边界,也就是无穷大小,后一个表示无效浮点数。这些内容比较繁琐,感兴趣的小伙伴可以查找相关资料,这里仅引入一些基本内容。
前面讲了,INF是指无穷,NAN是指无效。INF可能会导致NAN,NAN进一步导致浮点异常。所以,在进行浮点数运算处理时,我们要避免产生INF和NAN。
为了调试方便,可以利用浮点数存储原理,人为产生INF,然后快速验证一些想法。比如,可以通过下面的代码人为产生INF。
float f = 0;
*(unsigned int*)&f = 0x7F800000L;//正无穷(二进制 [0111 1111] [1000 0000] [0000 0000] [0000 0000])
//*(unsigned int*)&f = 0xFF800000L;//负无穷(二进制 [1111 1111] [1000 0000] [0000 0000] [0000 0000])
一旦产生INF,再进一步运算,就很可能出现NAN。比如,将INF送给sin、cos等三角函数或者fmod,就会输出NAN。NAN与任何数进行运算,几乎都输出NAN。也就是说,在整个计算链路上,一旦产生一个NAN,那后续涉及该变量的相关运算,结果都会是NAN。这一连锁反应,将导致程序崩溃。除了INF的转换运算,INF和-INF相加,也会产生NAN。这些都是博主在实际产品中遇到的。
当然,更常见的可能是除0。不过,有一定经验的开发人员在进行除法运算时,可能会刻意注意分母是否为零,特别是算法类的一些场景,开发人员容易形成条件反射,问题反倒会比较好的避免。反而是那些看似正常的运算,可能潜藏着导致浮点溢出的隐患。博主在实际产品中遇到过这样一个例子。在闭环自动控制过程中,采样数据需要进行分解运算,正常情况下,分解运算结果会作用到控制对象从而影响采集数据,整个过程数据会自然的处于一个合理区间。当闭环控制被打断,运算结果无法影响新的采样数据时,分解过程中的积分累加运算会导致中间变量变大,因为控制周期很短,运算频率很高,很快就会出现INF情况,紧接着数据进入sin、cos后输出NAN,导致浮点溢出。还有一种情况是前面提到的INF和-INF相加产生NAN。比如中间数据结果为-INF,通过低通滤波器时,进行了平方运算,出现INF,再之后INF和-INF相加,产生NAN。
除了上面提到的两种情况, 博主遇到过出现NAN的情况还包括:
接口内部使用静态变量导致的NAN。这类变量虽然方便了接口的逻辑实现,但是其潜藏在代码中,在程序复位时,并不能正确归位,仅在第一次运行遇到时进行了初始化。这就导致随着程序运算过程的变动,特别是流程复位后,新的过程中使用了旧的历史的内部静态变量值。这类历史值数据参与新的过程计算,导致算法结果出错,进而累计错误导致INF的出现。不过这种情况大部分在调试阶段都可以发现。因为正式运行时,算法本身基本得到了验证,错误的算法结果就提前触发了错误保护,此时浮点运算还没有到出现INF的程度。
负数开根号。虽然问题比较常见,但是博主遇到这个问题的引子却比较特殊,并不是真的给了负数,而是求和运算得到了负数。为了优化性能,博主在计算一串数据的和时,采用了窗口移动的方法。也就是每次加一个新的数,同时减一个最老的数,这样就不用重新计算整个窗口中数据的和了。但是,实际运行发现,当窗口中数据比较分散时,比如同时存在特别大的数和特别小的数,此时就存在明显的计算误差,且误差会累积。这导致求得的和减去最旧的那个数据时,可能出现负数。拿这个新的和进行开根号就会出问题。
取模运算。一个数%0时会出现浮点异常情况。博主遇到这个情况主要是取模的分母部分是个变量,不是固定值。因为外部情况不同,需要取模的基准也不同,是个变化过程,当外部没有符合条件的输入时,基准会变成0,也就是出现%0情况,此时即导致浮点异常。
五 总结
上面介绍了浮点数运算的一些情况,特别是介绍了几个博主遇到的浮点异常案例,希望对小伙伴们的日常工作有所帮助。
c/c++中提供了一些宏用于判断一个浮点数是否是INF或NAN,在开发中引入这些宏,可以做针对性的防御工作,以便在问题出现时,能够快速定位问题代码。另外,在一些容易诱发问题点对数据做一些限幅处理,也算是一种防御措施。
最后,小伙伴们也可以求助AI以便提供一些有用的规避措施。不可否认,AI在编程方面的进化速度是超乎想象的,将其作为自己的强力助手再好不过。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)