语音篇之音乐生成模型
(1)不知道大家发现没有:自从LLM取得历史性的效果提升后,其他模态的AI比如语音和图像等等都也在最近几年突飞猛进,当然不排除扩散模型这种创作性的工作,但是很多都是借鉴甚至直接利用了LLM进行了加持,而LLM最关键也是最牛逼的地方就是能推理,而且能天然用到几乎各个领域。作为技术,如果仅从技术角度看这个事的话,我们的收获是我们可以尝试想办法把LLM这个backbone用进自己的领域(比如VQ-VAE
前言
今天咱们继续介绍语音垂类这个系列,之前笔者介绍过一篇音效生成的技术,感兴趣的小伙伴可以穿梭
《语音篇之音效生成模型》https://zhuanlan.zhihu.com/p/1945492140043015222
今天咱们介绍音乐生成这个方向,相信大家在网上已经刷到过类似的一些demo了,可以说现在的效果基本都很好了,笔者就不放具体效果了,感兴趣的同学可以去官网体验,咱们这里主要重点看看技术是怎么实现的?
截至目前,目前该行业比较做的好的有Suno,国内做的好的有昆仑万维的Mureka V7、MiniMax刚刚放出的Music 1.5。
MiniMax体验官网:https://www.minimaxi.com/audio/music
Mureka体验官网:https://www.mureka.cn/
其中昆仑万维放出来了一篇比较新的技术报告如下:https://arxiv.org/pdf/2503.19611,MiniMax笔者没有找到,所以今天咱们就看看昆仑万维的这篇技术~
技术
其最核心的idea就是参考LLM领域的一个常用手段:引入COT,即在生成音频token之前先规划整体要生成的音乐结构,这样能增强最终音乐的连贯性和创造性。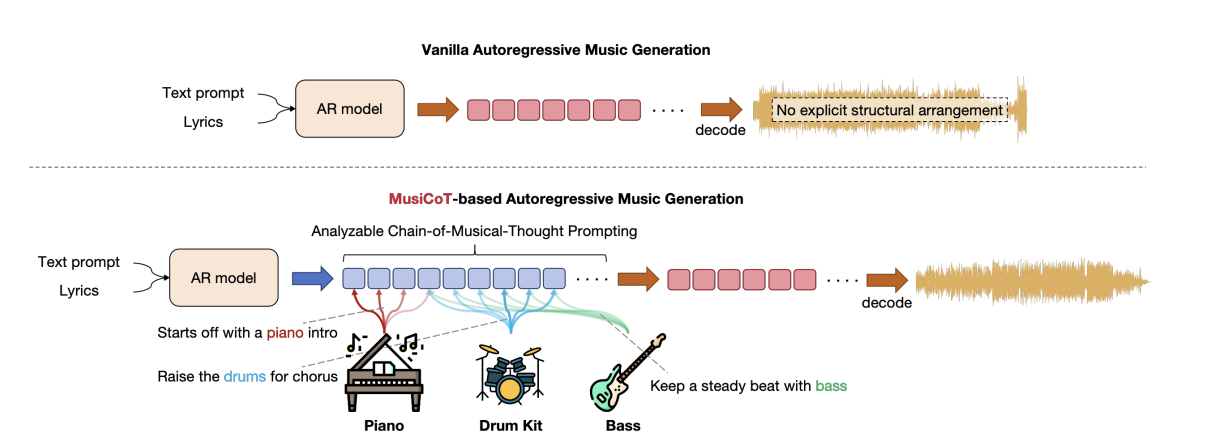
(1)背景
在音乐生成领域通常有三类模型,一个是AR模型即自回归模型,第二类是diffusion models即扩散模型,第三类就是把大语言模型LM和扩散模型相结合比如MeLoDy模型。
这三种模型各有优劣,首先第一种主要受启发于大获成功的LLM,其通过VQ-VAE方式来生成音乐,关于什么是VQ-VAE大家可以随便看网上几篇博客便知比如
https://blog.csdn.net/weixin_43693967/article/details/143115155
https://blog.csdn.net/weixin_43135178/article/details/130592568
简单来说就是VAE通过将中间隐变量规范到一个分布进而实现了可生成训练集中没有出现过的图片,而VQ-VAE就是将中间隐变量在VAE的思想基础上进一步进行了量化,进而能生成更好的图片,不过在笔者看来量化这里一个更大的好处就是最近LLM大火,通过量化(类似token)就可以直接嫁接利用LLM这个强大的backbone了。不过这样利用自回归生成音乐有一个比较大缺陷就是低比特率的限制。比较代码本过少,当然还有一些针对性的改进比如RVQ,但建模的复杂度也随着增加了。
第二种就是以diffusion为代表的模型,其虽然有连续空间,且没有量化损失的缺点,但由于连续潜在向量存在高计算成本,且面临支持长上下文窗口的挑战,进而导致生成样本的音乐性和结构一致性都有不足。
第三种就是结合二者,代表作是MeLoDy,先利用语言模型从单个码本中预测语义标记token(条件生成里的条件),然后这些标记引导扩散模型生成细粒度的波形,这样不仅可以生成与基于扩散的方法相当的高质量音乐音频,还可以像AR模型一样支持长上下文窗口。
本篇论文最终采用的就是类似第三种结构。
然后再来说说COT,其实这个在文本模型里面已经被证明很多次了,比如openai的O1,年初大火的deepseek R1等等都是用了cot来辅助思考的,同样音乐创作这个领域也是需要cot的,因为人类在创作音乐的时候都是会先全局思考,比如用什么乐器,整体结构等等。所以这里也需要,而且cot可以不是文本那样的形式(这种当然很好,很天然适合人类阅读,但是其占用空间很大),其可以是隐变量方式。
(2)框架
介绍完一些基本背景后,我们来看看最终的框架
- (a)用LLM进行语义建模
作者把生成的所需的条件C定义如下:
C : = { C l y r i c s , C t e x t } C:=\left \{ C_{lyrics}, C_{text}\right \} C:={Clyrics,Ctext}
其中
{ C l y r i c s } \left \{ C_{lyrics}\right \} {Clyrics}
代表人声的部分。
{ C l y r i c s } \left \{ C_{lyrics}\right \} {Clyrics}
代表文本提示,描述音乐的期望特征。
所以可以看到其是支持生成带有人声音乐的,而原始的MeLoDy是不支持的。
基于这个条件就可以用AR模型生成一些列token如下:
s 1 : N = [ s N ∣ s 1 : N − 1 , C ] s_{1:N} = \left [ s_{N} |s_{1:N-1,C} \right ] s1:N=[sN∣s1:N−1,C]
其中
s 1 : N s_{1:N} s1:N
就是通过用K-Means或者VQ-VAE量化得到的语义token,而这些方法通常都可以自监督训练,具体来说本篇用的是BEST-RQ来作为encoder的。
- (b)用扩散模型进行声学建模
这里在声学建模的时候,不同于AR(其用两个不同的LLM通过多码本来预测),其解码这里用的是一个扩散模型,而且是用上面的作为条件来进行条件生成,公式很标准如下: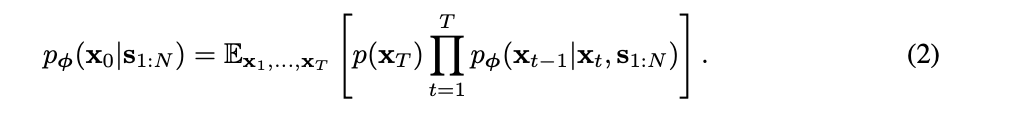
- (c)用人声歌词和文本控制进行条件生成
那具体是怎么把人声歌词和文本控制来作为条件的呢?如下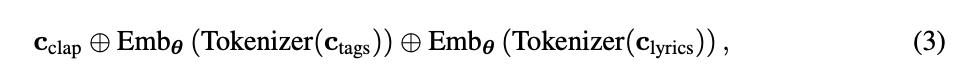

首先是文本的编码 C c l a p C_{clap} Cclap就是借助clip模型,训练的时候直接用原始语音进行encoder,推理的时候可以无缝替换成用文本进行encode(哈哈,这就是clip模型的好处,其本来就是做语音和文本对齐的)。
C t a g s C_{tags} Ctags是说一些音乐检索模型(MIR),其能将音乐分类为流派、性别、情绪和乐器等标签。而这些标签能进一步助于音乐的生成,所以在训练的时候也是直接对英语进行编码然后输入给MIR模型让其输出其tags,推理的时候还是老套路即用对应的clip去计算和各个tag的相似度,得到高就召回,有了这些tag后就可以Tokenizer离散然后Emb,同理 C l y r i c s C_{lyrics} Clyrics也是先kenizer离散然后Emb。
可以看到这里是非常巧妙的用了clip模型,训练的时候直接对语音编码,推理的时候这里又无缝替换成对文本的编码转化。(clip训练的时候就是为了让语音编码后向量和文本编码后的向量一致)
通过把上面三部分进行concatenation给语义 LM进行语义token即上面(1)讲的,这样就实现了文本和最终语义token的对齐,进而用这个去最终控制音乐的生成。
这里比较受启发一点的就是不需要有显示的文本-音频pair数据就可以无监督的训练即训练的时候用原始音频,推理的时候无缝用text即可。本质就是因为有Clip这个模型(其本质就是天然帮我们做了这个对齐,当然了clip训练的时候是需要有这个pair数据的,这是另外一回事了)
(3)COT
当目前为止,还没有进入到本篇的核心idea即cot,下面我们来看看。
其思路其实特别简单,首先其用隐变量来作为cot,那用什么隐变量呢?那就是参考RVQ所用的量化技术也即码本,详细大家看完VQ-VAE的博客后对这里的码本就很好理解,其实就是把音频先10s分割一下,然后过clip得到连续的表征,然后预先准备一个离散化的码本,每次找表征与码本中最相近的向量最为离散化后的向量,最后将所有量化后的token一字排开,这就是所谓的cot如下: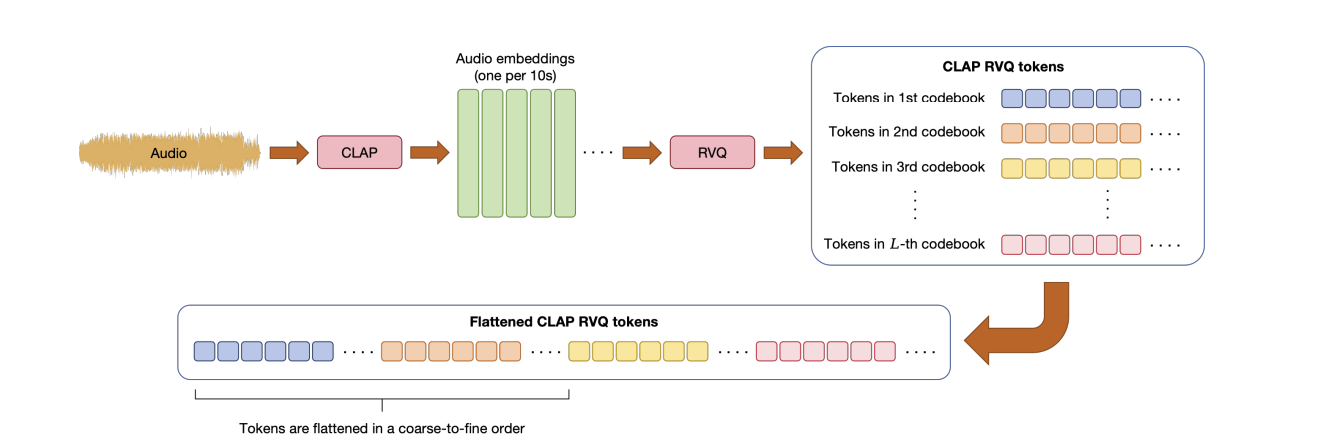
那最终是怎么拼接给AR模型呢?我们知道AR模型就是一个一字排开的序列,其实也很简单,和正常的AR没啥区别如下: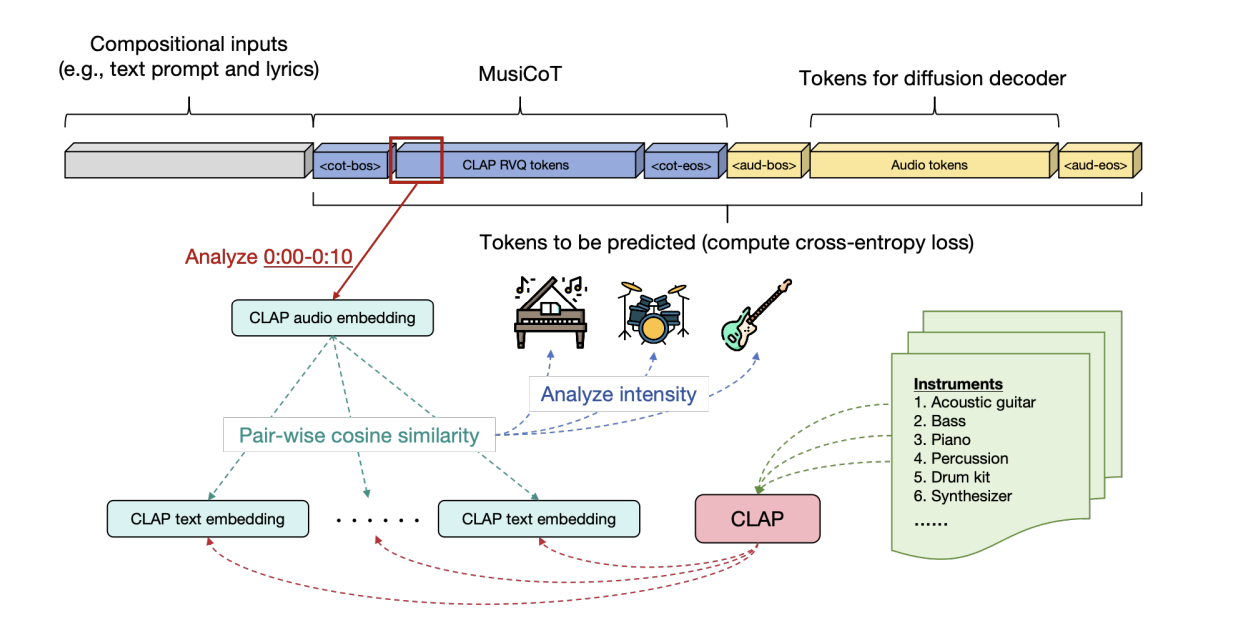
可以看到灰色的就是输入条件也即咱们上面“用人声歌词和文本控制进行条件生成”一节讲的内容。浅蓝色这里就是cot,其中红框就是代表其中的一个10s片段RVQ后的离散token,这些token也是一个表征,其可以拿来被各种可视化分析比如和各种乐器文本进行相似度计算。
黄色的就是正常语音文本用来给扩散模型去解码生成最终音乐的。
返回头再来看为啥这里使用RVQ来量化作为cot,因为这样其可被计算CE loss。同时由于直接用clip来表征,就实现了可以直接进行监督训练,因为一切都ready,只有有音频就行。
通过上节和本节我们看到了,作者就是把clip用到了极致,实现了很多音频自监督训练,一个是条件那里通过clip无缝切换了训练音频->文本推理的转化。另一个是cot这里直接用音频过clip后的表征作为了监督信号。
总结
(1)不知道大家发现没有:自从LLM取得历史性的效果提升后,其他模态的AI比如语音和图像等等都也在最近几年突飞猛进,当然不排除扩散模型这种创作性的工作,但是很多都是借鉴甚至直接利用了LLM进行了加持,而LLM最关键也是最牛逼的地方就是能推理,而且能天然用到几乎各个领域。作为技术,如果仅从技术角度看这个事的话,我们的收获是我们可以尝试想办法把LLM这个backbone用进自己的领域(比如VQ-VAE、RVQ这些方法),而且其往往是用在需要推理的环节,这也是具备所谓智能的关键地方。
(2)其实除了扩散模型,最近还有flow流模型等等,这些模型本质要解决的问题就是从一个分布恢复到最终要的图片或者音频(也就是去噪过程),之所以是一个分布是因为只有这样才能泛化,才能生产训练集没有见过的图片或者音频,即推理的时候就是从分布中随机采样点进行去噪生成。还有一点就是条件生成,我们最终还是希望生成是受控制的,而不是随机的,所以又引出了另外一个技术方向就是在去噪的过程中再输入中再额外引入一个条件y(这个可以是文本指令等等),这样就能生成我们想要的图片了。其次就是离散化,如果想要利用现在的LLM,这些连续的图片或者音频必须要经过离散token化才有机会进行结合。
(3)正如文章所说cot是一个很大的概念,并不一定非要局限到文本这样样式(当然这是人类最容易交互看懂的一种的方式),其可以是各种隐变量的方式,各种适合其他任务的方式。
(4)当没有pair数据的时候,可以借助clip这种实现无监督(训练和推理的时候可以不一样,实现无缝衔接)
关注

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)