大模型原理的解析
简单理解一下大模型的推理过程。
说实话,用了这么久的AI大模型,对于它的底层原理,并不是很了解。只是粗略看过Transformer,知道核心是自注意力机制,但为什么大模型有如此能力,背后的原理,始终是一知半解,心存疑惑。
今天看了一些资料,用自已的理解,来从头到尾梳理一下,加深理解。
对于大模型的应用,最基础的就是问答了,但比问答更基础的就是文字补全了。我们今天就讲基础的文字补全。并且,不讲模型的训练,只解析推理的过程。
首先,我们把大模型推理的的Transformer架构图拿出来:
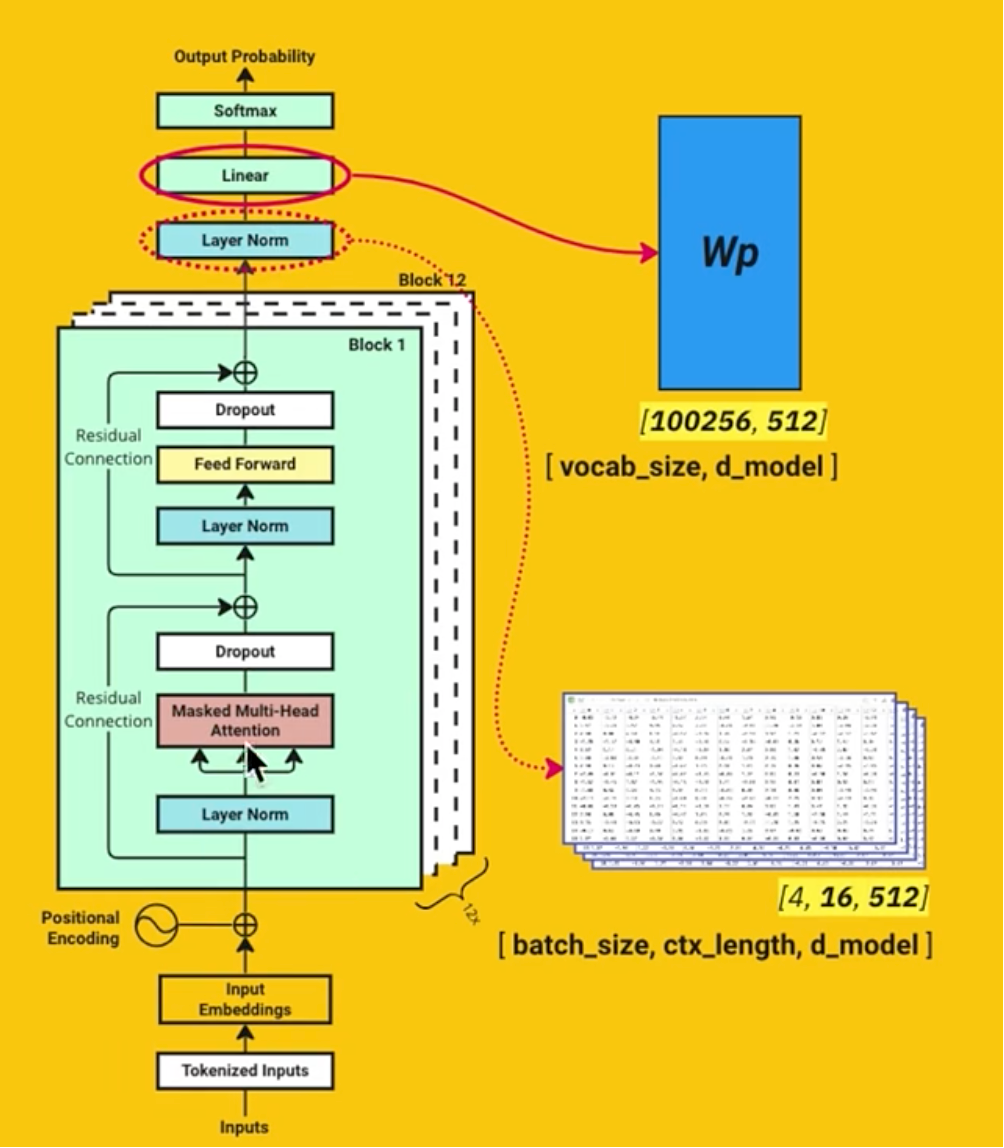
从输入语句开始,到最后补全一个字符,分为N个步骤,我们来解释 每个步骤,并且说明其中用到哪些模型权重。
比如,我们输入:我爱中华人民共和 ,希望大模型给我们推测下一个词。
第一步:Tokenized inputs & Embeddings
对输入字串进行编码,转换,得到一个矩阵。在上图中表达了两个节点。一个是查表,一个是取值嵌入。
这里出现我们用到的第一张参数表:
第一张参数表:嵌入向量表,一个矩阵(词向量总数 X 模型使用维度)
以DeepSeek为例,我们用的词库量是 100256,模型使用的维度是 3584 。 词库量很好理解,就是一共有多少个词,维度如何理解?你可以认为每个词我们都给他 3584 种场景,每个场景,词的含义都不同。那这个矩阵代表了啥?代表的就是在 3584 种场景的情况,每个词与其它词之间的关联关系。这个表非常重要,也是训练中输出的一个重要的权重。
好了,我们根据输入的字串,找到每个字符对应在矩阵中的行,然后把该行的 3584个不同的数取出来,假设我们输入的字符串的token数量是 M ,那我们就得到了一个 M * 3584 的矩阵。
你可以理解,我们取出了这些输入词在3584个场景下的关联度。也可以理解我们为每个字符找到一个多维的表示,在3584维空间中的表示。
第二步:Position Encoding
为输入字符,添加位置信息,因为这些字符是有相互的位置关系的,这个信息你一定要表达清楚。这样在后续过程中,模型能知道每个字符的位置。
添加位置信息,最简单的做法就是按序号,在原值上添加,但这样不行。因为序号的值太大了。我们的做法是 取位置的 正弦Sin 或者 余弦Cos 值,这样就保证取值都在-1,1之间了,这里非常妙。但是,对于后面的模型神经网络是如何学习到这一点的,真的是很神奇了。
这一步没有引入参数表,没有模型的权重,因为位置是固定的值。
好了,我们认为我们保留了输入字符的位置信息。
第三步:自注意力的学习
这显然是最烧脑的步骤。啥叫自注意力?
看下面这幅图,我们关注 Attension 是如何生成的。
Attension 由 Q,K,V 计算得到。
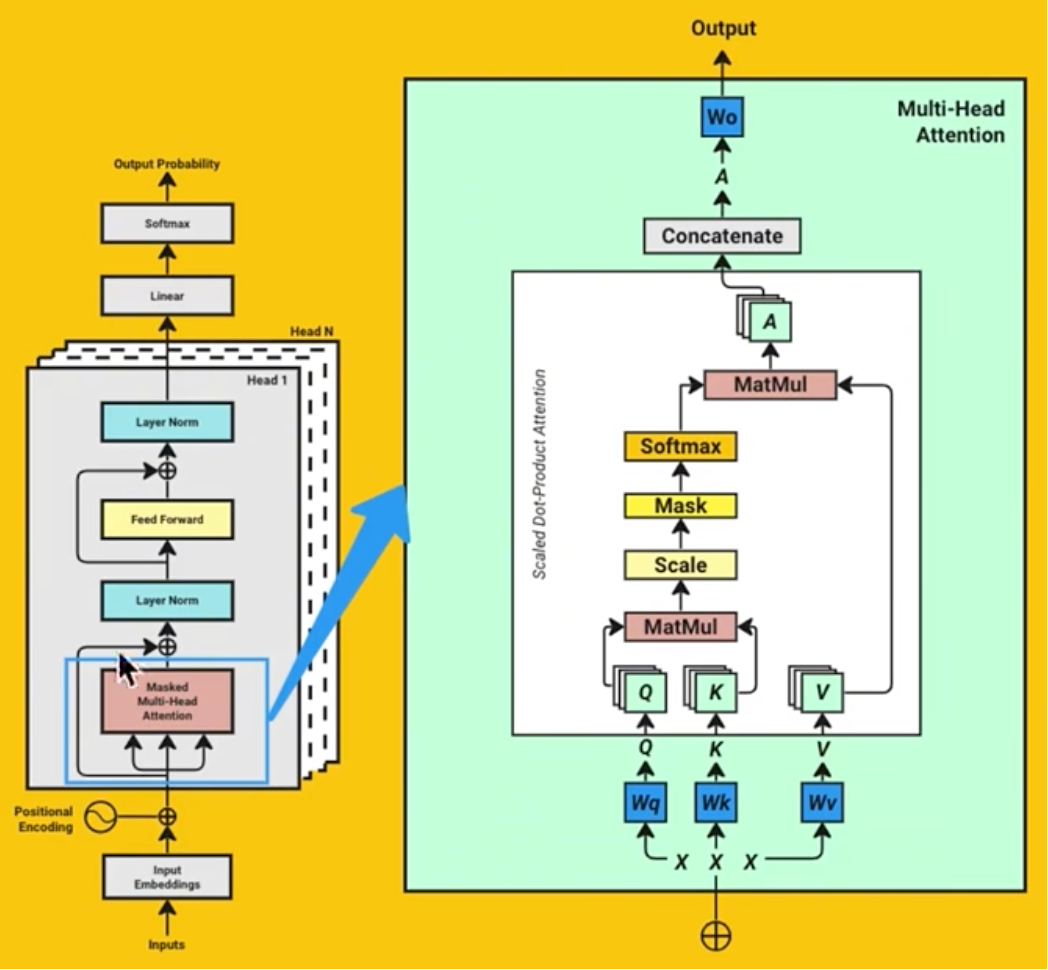
3.1 :准备 Q,K,V 矩阵
Q矩阵如何获得?这里我们见到 第二张重要的参数表:Wq,它也是一个矩阵 总维度 X 总维度。比如:DeepSeek中是 3584 * 3584 的矩阵。
如何理解这个矩阵,为什么叫Query?
Query 就是查询的意思,就是我们提出问题的角度,假如我们有 3584 种问问题的角度。
我们使用上一步的 M * 3584 的矩阵,我们先做拆分,把注意力分成 128个,那就是
M * 28 * 128 的矩阵。
我们把它和 Wq 进行相乘,得到 M * 28 的 128 个矩阵 Q,这里为啥是 128?因为我们希望有多个场景(多个头)。
同样。我们拿到 第三张重要的参数表:Wk,它也是一个和Wq相似的矩阵。
同样,我们使用第 四张重要的参数表:Wv,它和上面相同,但值不同。
同样的计算,我们得到 矩阵 K,矩阵 V。
我们如何理解这个 Q,K,V呢?
我是这么理解,它代表了在 Q和K一问 和 一答场景的关联度。
3.2: 计算 Q * K的转置
就是把K转一下方向,和Q 相乘,这样,得到了 128 个 M * M 的矩阵。
也就是得到128种情况下,输入token之间的关联度矩阵。
并且对输出值进行了缩小,除了一个数值。
然后做了softmax,转成了概率。
注意:这里的mask是针对训练场景的使用,这里可以先不管它。
也就是说得到了128个场景下,输入token间的关联概率。
可以这么理解,q 记录了所有问题的角度,k记录了第个角度的关键词。相乘后,得到输入token在我训练的所有场景下的总的相似度。
Q * K 得到 M*M 的矩阵,表达第N个文字对应其它文字的关注度(关联度)的高低。
3.3 :计算 Q * K * V
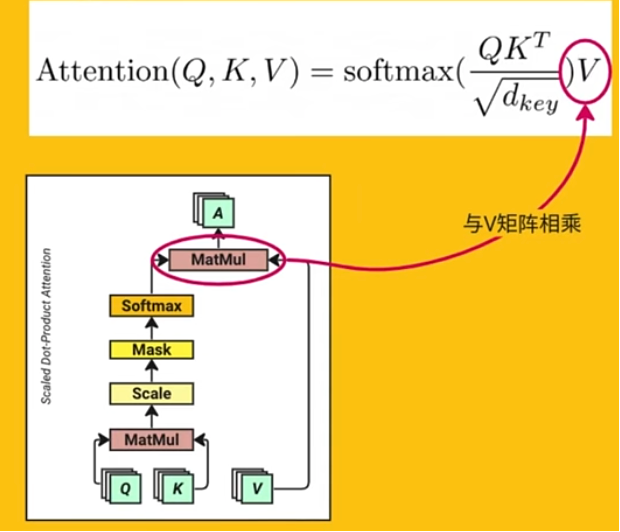
其实,完整的公式如上,我们已经讲了 Q 和 K的转置的乘,也讲了如何将值缩小,然后还进行了softmax的转换,变成了概率,然后,这一步就是 乘上V了。
乘上V之后,得到的就是一个 128 个 M * 3584 的矩阵。
如何理解我们得到的 Attention值:
Attention:单个 token 对应其它所有文字,在所有维度下的关注度权重的总和(其实,还是很抽象,并不好理解)。对原始token对应的权重调整得更准确,更新向量表。
可以这样理解,把当前输入的文字放到了所有的场景里进行了一次理解,得到了当前词与所有场景的隐含关系。
3.4:多头连接,输出Output
将 128 个场景的多头做一下连接。合成为一份矩阵。
变回了 M * 3584 的矩阵。
这里用到 第五张表:Wo,它类似上面的Wk,Wq,Wv
这个Wo是什么意思呢?
第四步:Feed Forward 处理
这一步主要是做神经网络的处理。在处理时有一些小的步骤。
4.1: Drop out
随机去掉一些结果(比如:0.1),属于神经网络的一种标准用法。为了避免过拟合。
4.2: 残差连接(Residual Connection)
主要是减少逼近的方式,使得速度更快。为了避免梯度消失。
4.3: LayerNorm
做一定的数值缩放。
4.4: Feed Forward
这是前馈神经网络的它主要是做非线性的变换,与自注意力的线性处理相配合。
整个过程的公式可综合为:
FFN(x)=GELU(xW1+b1)W2+b2
解读如下:
1: 最外层是线性变换(压缩维度):
计算公式:y= aW2 + b2
此步将向量从高维空间 d_ff投影回原始的模型维度 d_model,以便与残差连接相加,并输入到下一个层。
将激活后的高维向量 a与第二个权重矩阵 W2(形状为 [d_ff, d_model])相乘,并加上偏置 b2。
2:非线性激活(引入非线性):
对高维向量 z应用一个非线性激活函数,如 ReLU 或 GELU。这是引入非线性的关键,使模型能够学习更复杂的函数。
计算公式:a=GELU(z)
3: 最里层线性变换(扩展维度):
输入向量 x(维度为 d_model,例如 512)与权重矩阵 W1(形状为 [d_model, d_ff])相乘,并加上偏置 b1。
此步将向量从低维空间(d_model)映射到一个更高维的空间(d_ff,例如 2048)。d_ff通常是 d_model的 4 倍。
计算公式:z=Activation(xW1+b1)
为什么FFN是这样,为什么它有作用,其实说不太清楚,反正就是有用就对了。
-
提供非线性变换:自注意力机制本质上是线性操作(加权求和)。FFN 通过激活函数(如 GELU)引入了非线性,极大地增强了模型的表达能力,使其能够拟合更复杂的函数。
-
空间变换:FFN 充当一个“专家网络”,它在高维空间(
d_ff)中对自注意力机制提取的特征信息进行深度处理和转换,学习到更抽象、更有用的特征表示。 -
独立处理:FFN 对序列中每个位置的向量进行独立处理,这与自注意力机制(考虑所有位置之间的关系)形成互补
W1,W2:重要权重参数表:3584 * 3584 作为重要的参数。
第一个权重矩阵 (W1)
-
形状:
[d_model, d_ff] -
作用:负责第一次线性变换(升维)。
第二个权重矩阵 (W2)
-
形状:
[d_ff, d_model] -
作用:负责第二次线性变换(降维)。
第五步:重复 N 层的运算
多次运算,早期是 12 层,对于DeepSeek R1 应该是有 61 层之多。
运算时,不断重复更新 权重数据,每一层的权重数据都是不同的。
第六步:输出结果
6.1: LayerNorm
执行一次 LayerNorm,将值进行缩放。
6.2: linear 线性变换
乘以一个矩阵 Wp 100256 * 3584 ,就是词汇量 * 维度的权重矩阵。
上一步的输出是 M * 3584.
这里将 Wp 做一下转置,变成 3584 * 100256
和上一步进行相乘,得到 M * 100256的矩阵。
好了,这就得到了每个输入字符与所有token的关联度。
6.3: SoftMax
为了方便计算,把值变成百分比。更容易得到关联度。
最后一步:得到预测值
通过最后一个输入参数的所有权重值,查到最大的权重,就是推荐的下一个字符。
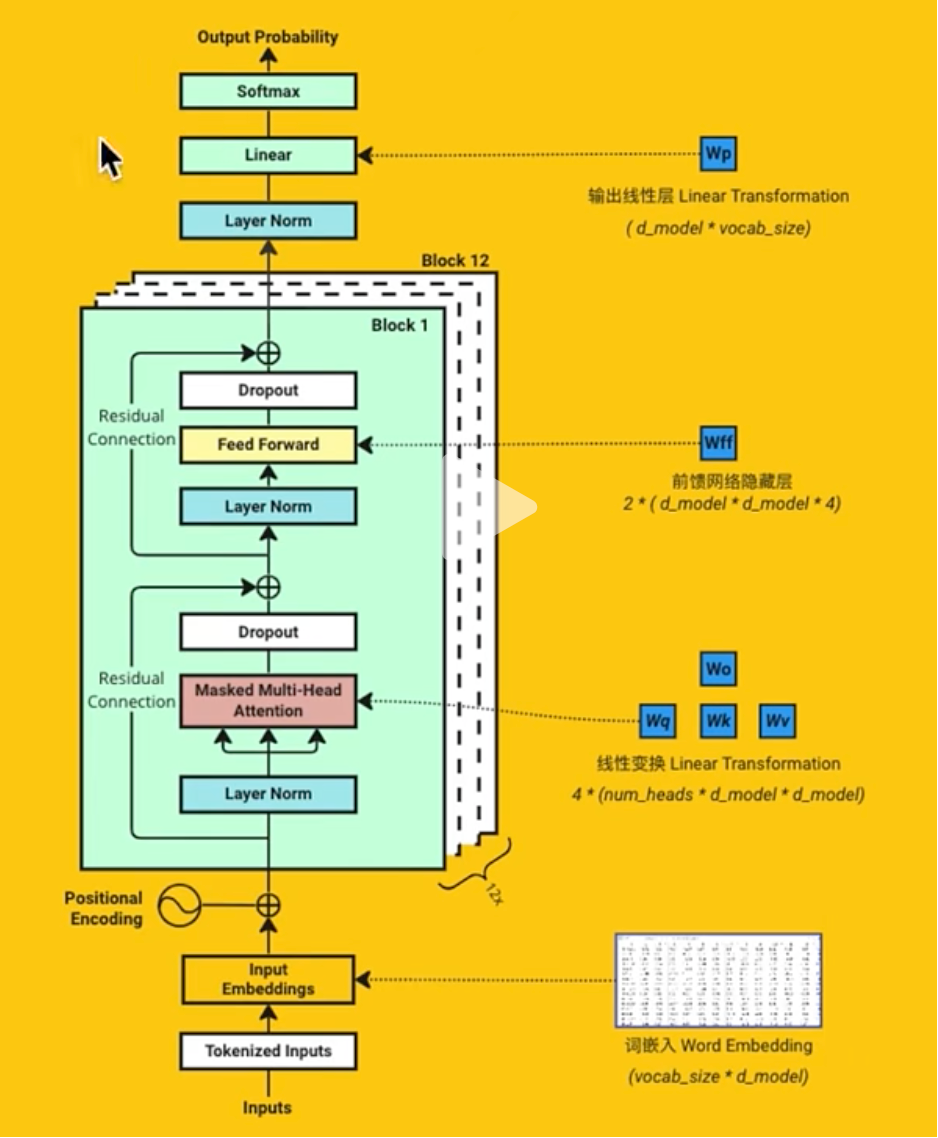
回顾和总结:
看看下图,总结一下,我们有如下的蓝色的权重部分。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)