LLM大模型-大模型微调(常见微调方法、LoRA原理与实战、LLaMA-Factory工具部署与训练、模型量化QLoRA)
**摘要:**微调(Fine-tuning)**是在预训练模型基础上,使用特定任务或领域的数据进一步训练,使模型适应特定场景。主要方法包括: 全量微调:调整所有参数,性能最优但成本高; 参数高效微调(PEFT):如LoRA(低秩矩阵更新)、Prefix Tuning(前缀参数调整),仅微调少量参数,成本低且效果接近全量微调; 强化学习微调(RLHF):通过人类反馈优化模型行为,适用于价值观对齐和复
一、 微调(Fine-tuning)
定义:在预训练模型的基础上,使用特定领域或任务的数据集进一步训练,调整模型参数,使模型更适应特定场景。
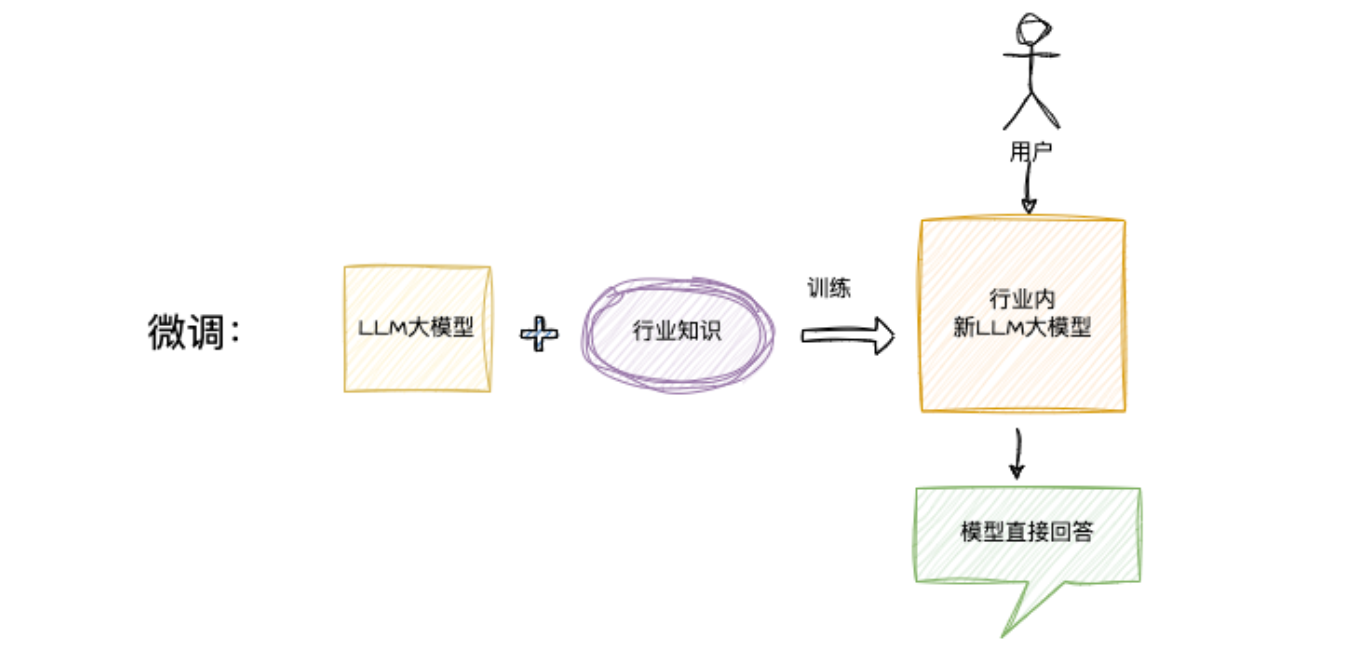
微调:是对定制化模型的问答,是模型学习到的内容,生成一个新的模型
核心原理:预训练大模型已经通过海量数据学习了通用知识和语言规律,但在具体任务(如客服问答、代码生成)或专业领域(如医疗、法律)中表现可能不够精准。
其本质是:
- 冻结预训练模型的大部分参数(或只调整少量参数)
- 用特定任务数据重新训练,让模型参数在保留通用能力的基础上,适应特定场景的语言模式和知识
- 相比从零训练,微调能以极低的成本(数据量、计算资源)获得显著的性能提升】
微调的基本流程:

常见的微调方法
根据参数调整范围,主要分为以下几类:
1. 全量微调(Full Fine-tuning)
全量微调(Full Fine-tuning)是大模型微调中最 “彻底” 的一种方式,指对预训练大模型的所有参数(从底层嵌入层到顶层输出层)进行重新训练和更新,而非只调整部分参数。它的核心目标是让模型在保留通用知识的同时,完全适配特定任务或领域的细节,是实现 “极致任务对齐” 的重要手段。
全量微调的逻辑是:
- 以预训练模型的所有参数为 “初始起点”,不冻结任何层;
- 用特定任务 / 领域的高质量数据集(如医疗病历标注数据、金融研报生成数据)重新迭代训练;
- 让模型的每一个参数(包括负责基础语义理解的底层参数、负责逻辑推理的中层参数、负责输出生成的顶层参数)都根据目标场景的数据进行调整,最终形成 “专属定制” 的模型。
优点:
- 适配度最高:所有参数都为目标任务优化,能最大程度挖掘模型在特定场景的潜力,通常是性能上限最高的微调方式。
- 对数据 “容错性” 稍高:即使数据量中等(如数万条),也能通过全参数更新实现较好的拟合(前提是数据质量高)。
缺点:
- 成本极高:需支持完整模型参数的训练,对 GPU 显存、算力和训练时间要求远高于其他微调方式(如 LoRA)。
- 灵活性低:微调后的模型高度绑定单一任务,若要切换任务,需重新全量训练,无法像 PEFT 方法那样快速切换。
- 对数据质量要求极高:若数据存在噪声、偏见或分布不均,全参数更新会放大这些问题,导致模型 “学歪”。
典型使用场景包括:
- 核心业务场景追求极致性能(如医疗诊断辅助、金融风险精准预测)
- 拥有大规模高质量标注数据(数万至百万级以上)的企业级应用
- 任务与预训练数据差异极大(如古汉语处理、专业加密协议解析)
- 有充足计算资源(多 GPU 集群)支撑的大型团队或机构
- 需要模型深度适配特定领域知识体系(如法律条文生成、芯片设计辅助)
- 对模型输出精度要求极高且性能直接关联核心业务价值的场景
2. 参数高效微调(PEFT, Parameter-Efficient Fine-Tuning)
参数高效微调(PEFT)是针对大模型全量微调成本过高问题提出的优化方案,核心是只调整模型中极少部分参数(通常 < 1%),同时保持预训练模型的大部分参数冻结,在大幅降低计算成本的同时,仍能实现较好的任务适配效果。
其主流方法及特点如下:
- LoRA(Low-Rank Adaptation)
- 原理:在模型关键层(如注意力层)插入低秩矩阵,通过优化低秩矩阵参数间接更新模型,避免全量参数调整
- 优势:性能接近全量微调,显存占用仅为全量微调的 1/10~1/20,训练速度快
- 适用:几乎所有场景,尤其是资源有限的中小团队
- Prefix Tuning
- 原理:仅在输入序列前添加可训练的 “前缀参数”,模型主体参数冻结,通过前缀引导模型生成符合任务的输出
- 优势:适合生成类任务(如文本摘要、翻译),多任务切换灵活
- 局限:性能略逊于 LoRA,对长文本任务适配性一般
- IA³(Infused Adapter by Inhibiting and Amplifying Inner Activations)
- 原理:通过学习缩放因子调整模型内部激活值,不新增参数,仅修改原有参数的缩放系数
- 优势:参数效率极高(几乎不增加额外参数),适合超大规模模型(如 100B + 参数)
- 局限:调优难度稍高,对部分任务效果不如 LoRA
PEFT 的核心优势:
- 成本极低:单 GPU 即可训练 7B/13B 参数模型,无需昂贵集群
- 泛化性好:不易过拟合,小数据集(数千条)即可见效
- 灵活部署:微调后可只保存少量适配器参数(通常 < 1GB),方便迁移和多任务切换
典型适用场景:
- 中小团队或个人开发者的模型定制需求
- 数据量有限(数千至数万条)的领域适配任务
- 需快速迭代、多任务并行开发的场景
- 资源受限但需要利用大模型能力的应用(如边缘设备部署)
3. 强化学习微调(RLHF)
强化学习微调(RL Fine-tuning,常结合人类反馈强化学习 RLHF)是一种通过强化学习机制优化大模型行为的微调方法,核心是让模型在与环境(或人类反馈)的交互中学习 “如何更好地满足人类需求”,而非单纯通过监督数据拟合输出。
强化学习微调不直接用 “输入 - 输出” 数据训练模型,而是通过三步闭环实现优化:
- 监督微调(SFT):先用高质量标注数据让模型学会基础任务能力(如回答问题、生成文本),作为初始模型。
- 奖励模型训练(RM):让人类对模型的多个输出打分(如 “回答是否准确”“是否符合伦理”),用这些打分数据训练一个 “奖励模型”,使其能自动评估模型输出的优劣。
- 强化学习优化(RL):用奖励模型作为 “裁判”,让模型通过试错生成输出,根据奖励模型的打分调整参数,最终学会生成更高分的结果(即更符合人类偏好的输出)。
关键特点
- 目标不同:传统微调追求 “模仿数据”,强化学习微调追求 “优化行为以获得更高奖励”。
- 依赖反馈:核心是奖励信号(人类反馈或自动评价指标),而非固定的 “正确答案”。
- 动态优化:模型会通过迭代试错调整策略,逐步逼近人类期望的输出风格(如更安全、更有用、更诚实)。
典型应用场景
- 对齐人类价值观:让模型输出符合伦理规范(如避免偏见、拒绝有害请求),例如 ChatGPT 通过 RLHF 减少不当回答。
- 优化输出风格:调整模型语气(如更礼貌、更简洁)、格式(如结构化报告)或专业度(如学术写作风格)。
- 复杂决策任务:在需要多步推理或权衡的场景(如规划路线、资源分配)中,让模型学会更优的决策逻辑。
- 弥补监督数据缺陷:当缺乏高质量标注数据时,可用少量人类反馈通过强化学习引导模型优化。
优势与挑战
- 优势:能让模型超越训练数据的局限,生成更符合人类实际需求的输出,尤其在价值观对齐和复杂决策上表现突出。
- 挑战:流程复杂(需多阶段训练)、成本高(依赖人类反馈)、奖励模型可能存在偏差(如打分不一致导致模型学歪)。
二、LoRA(Low-Rank Adaptation)
LoRA(Low-Rank Adaptation,低秩适应)是目前最流行的参数高效微调(PEFT)方法之一,核心思想是通过低秩矩阵分解来减少可训练参数,在大幅降低计算成本的同时,保持接近全量微调的性能。
在 LoRA 出现之前,微调大型预训练模型(如 GPT-3, LLaMA)的主要方式是 全量微调(Full Fine-Tuning)。这种方法需要更新模型的所有参数,存在几个显著问题:
- 计算成本高:模型动辄数十亿甚至上千亿参数,训练需要大量的 GPU 显存和算力。
- 存储成本高:每个下游任务都需要保存一份完整的模型副本,非常占用存储空间。例如,一个 7B 的模型,微调 100 个任务就需要 700B 的存储空间。
- 容易过拟合:如果目标任务的数据集很小,全量微调庞大的参数很容易导致模型遗忘预训练时学到的通用知识,只在微调数据上过拟合。

LoRA 的核心思想:假设模型在适配下游任务时,权重更新(ΔW) 其实是一个低秩矩阵(Low-Rank Matrix)。这意味着我们不需要更新所有参数,只需要用一个更小的、由两个低秩矩阵相乘得到的矩阵来模拟这个更新过程即可。
- 低秩矩阵: LoRA方法在原始网络参数更新过程中,通过引入低秩矩阵近似原始权重的更新
- 将网络的某些权重矩阵分解为两个较小的矩阵乘积,也就是低秩矩阵
- 这些小矩阵是需要微调的参数,而原始的预训练权重则保持不变。
- 减少计算和存储需求: 只需要调整相对较少的参数,同时又能实现与完全微调大模型类似的性能效果。
- 适应性:通过低秩矩阵的引入,使得微调过程可以更高效地适应特定任务,提升任务的表现,而不需大规模参数更新。

1. LoRA 的工作原理
我们以 Transformer 模型中的自注意力层(Self-Attention) 的权重矩阵为例(如 Wq, Wk, Wv, Wo)。
-
冻结预训练权重:在微调过程中,预训练模型的原始参数 W 被冻结( freeze),完全不参与梯度更新。
-
注入旁路矩阵:对于原始模型中的某一个权重矩阵 W (维度为
d × k),我们引入一个低秩分解的旁路。具体操作是:- 定义一个降维矩阵 A (维度为
d × r),初始化为随机高斯分布。 - 定义一个升维矩阵 B (维度为
r × k),初始化为零。 - 将这两个矩阵的乘积 BA 作为原始权重更新 ΔW 的近似。这里的 r 就是秩(Rank),且 r << min(d, k)。
- 定义一个降维矩阵 A (维度为
-
前向传播:前向传播时的计算变成了:
h = Wx + BAx
其中:Wx是原始模型的计算结果。BAx是 LoRA 引入的适配器计算结果。
-
只训练新参数:在训练过程中,只有 A 和 B 这两个小矩阵的参数会被更新,原始参数 W 保持不变。


2. LoRA 的优势
- 大幅降低显存需求:由于绝大部分参数被冻结,只需要计算和存储小矩阵 A 和 B 的梯度,大大减少了训练所需的 GPU 显存。通常可以将显存需求降低至全量微调的 1/3 甚至更少。
- 训练效率高:参数少了,训练速度自然更快。
- 存储高效:训练完成后,只需要保存 A 和 B 这两个小矩阵(通常只有几兆到几十兆),而不是整个模型(通常是几GB到几十GB)。在推理时,可以先合并权重:
W_new = W + BA,也可以单独加载小矩阵并与原模型进行计算,几乎不引入额外的推理延迟。 - 便于任务切换:可以为不同任务训练不同的 LoRA 权重。在推理时,通过加载不同的 LoRA 权重,可以快速在同一个基础模型上切换不同任务的能力,实现“一个模型,多种用途”。
- 可以多个一起用:可以同时使用多个 LoRA 适配器(例如,一个用于数学能力,一个用于日语能力),通过加权求和等方式组合它们的效果。
3. 微调实战-LLaMA-Factory
不同的大模型进行LoRA微调时,需要的数据不同,且 Python 代码的编写也不同。为了能统一微调市面上所有流行的大模型,有一个团队做了一个开源工具,允许使用命令行或者 WebUI 操作的方式来微调模型,叫做 L L a M A − F a c t o r y LLaMA-Factory LLaMA−Factory。

LLaMA-Factory 工具地址: https://github.com/hiyouga/LLaMA-Factory
3.1 工具部署
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation
3.2 安装测试
llamafactory-cli version

3.3 准备数据集

-
按照示例准备数据集,将数据集复制到 L L a M a − F a c t o r y LLaMa-Factory LLaMa−Factory 的 d a t a data data 目录下。
-
数据格式:问题为训练数据,回复为标签。工具会自动处理并划分输入和输出。
-
将 JSON 数据集复制到指定路径下,并修改配置文件,进行数据集登记,确保工具能够检测到新添加的数据集。

3.4 启动工具
输入命令行启动 WebUI
llamafactory-cli webui

3.5 开始训练
提供的各种数据集:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
-
保持参数默认值,更改模型路径和数据集路径。


-
后台命令行出现以下信息,说明正在训练,重点关注损失值(Loss)是否降低

-
页面也会显示训练进度和损失变化曲线。

训练完毕会弹窗提示:

训练完的适配器保存在save文件夹中,可以直接导出为新模型(旧模型+新参数),也可以用代码自己选择适配器(下面第9节知识点)
导出:(各种有问题的话,把transformer更新到合适的版本,或者重启电脑或许就好了)

4. LoRA模型使用
直接合并模型
# 合并步骤(只需执行一次) pip install peft
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-llm-1.5b")
lora_model = PeftModel.from_pretrained(base_model, "./your_lora_dir")
merged_model = lora_model.merge_and_unload() # 合并权重
merged_model.save_pretrained("./merged_model", safe_serialization=True)
# 修改您的初始化代码
class DeepSeek:
def __init__(self, model_path="./merged_model", device="cuda", torch_dtype=torch.float16):
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch_dtype,
device_map="auto" # 自动分配设备
) # 无需手动.to(device)
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
三、 量化
1 Byte(字节) = 8 bit(比特)
1 KB(千字节) = 1024 Byte
1 MB(兆字节) = 1024 KB = 1024×1024 Byte ≈ 10⁶ Byte
1 GB(吉字节) = 1024 MB = 1024³ Byte ≈ 10⁹ Byte
1 TB(太字节) = 1024 GB = 1024⁴ Byte ≈ 10¹² Byte
1. 为什么需要量化?
简单来说,量化是将模型中的浮点数参数,如 32 位浮点数,转换为低位宽的数值表示,如 8 位整数,从而在不显著降低模型精度的前提下,大幅减少模型的存储空间和计算资源消耗。
具体原因可以归结为以下几点:
1. 减小模型体积(Storage)
- 问题:像GPT-3、Llama 2这样的模型,参数动辄达到1750亿(175B)或700亿(70B)个。如果每个参数都用32位浮点数(FP32)存储,一个70B的模型就需要
70 * 10^9 * 4字节 ≈ 280 GB的存储空间。这对于任何个人设备甚至许多服务器来说都太大了。 - 解决:量化将FP32(32位)转换为INT8(8位)或甚至INT4(4位),模型体积可以急剧缩小。INT8量化后,体积减小为原来的1/4;INT4量化后,体积减小为原来的1/8。这使得我们可以在手机、嵌入式设备等资源受限的环境中存储和运行大模型。
2. 降低内存占用(Memory)
- 问题:运行模型时,不仅参数需要加载到内存(RAM或VRAM)中,前向传播过程中的中间激活值(activations)也需要占用大量内存。巨大的内存占用是阻碍大模型普及的主要瓶颈。
- 解决:量化后,模型参数和激活值都使用低精度表示,显著降低了内存带宽和容量需求。这意味着我们可以在消费级GPU(例如,只有8GB或12GB VRAM的卡)上运行更大的模型。
3. 加速计算(Speed/Latency)
- 问题:现代硬件(CPU、GPU、NPU)针对整数运算进行了大量优化,执行INT8运算的速度远快于FP32运算。此外,从内存中读取8位数据比读取32位数据更快,减少了内存带宽瓶颈。
- 解决:通过利用硬件提供的专用整数指令集(如Intel的AVX-512 VNNI、NVIDIA的Tensor Cores),量化模型可以大幅提升推理速度,降低延迟,提高吞吐量(Throughput)。这对于高并发、实时的应用场景(如聊天机器人、实时翻译)至关重要。
4. 降低功耗(Power Consumption)
- 问题:内存访问是深度学习计算中最耗电的操作之一。高精度的数据移动和计算需要更多的能量。
- 解决:低精度计算和减少的数据传输量直接转化为更低的能耗。这使得大模型可以应用于对电量敏感的移动设备和边缘计算设备(如智能手机、无人机、IoT设备)上
2. 量化技术
2.1 均值量化
Uniform Quantization
-
方法一:全局最值
-
做法:直接取权重矩阵的最大值和最小值
x m i n = min ( W ) x m a x = max ( W ) x_{min} = \min(W) \\ x_{max} = \max(W) xmin=min(W)xmax=max(W) -
优点:简单,计算成本低
-
缺点:如果有少数极端值,会拉宽量化范围 → 大部分权重精度下降
-
-
方法二:按分布统计
-
做法:取某个分位数(比如 0.01% 到 99.99%)的值作为 m i n / m a x min/max min/max
-
优点:减轻极端值影响 → 大多数权重映射更精确
-
2.2 NF4量化
NormalFloat4
NF4 的核心是假设权重近似正态分布(μ≈0)。
-
统计权重的标准差 σ
- 假设权重服从 N(0, σ²)
-
设置范围
- 通常取 −kσ,+kσ 作为量化范围
- 论文里 QLoRA 选择 k ≈ 3 → 覆盖大约 99% 权重
- 极端值之外的权重会被截断(clipping)
-
构建 NF4 离散表
- 根据正态分布密度设计 16 个离散值
- 0 附近密集,尾部稀疏
3. 量化实现
量化的核心思想是:将一个范围的浮点数值映射到一个更小、更离散的整数集合上。
3.1 均匀量化映射
对于一个浮点数向量 r (FP32),其量化值 q (INT4) 可以通过以下公式计算:
-
计算 步长scale
scale = m a x − m i n 2 b − 1 \text{scale} = \frac{max - min}{2^b - 1} scale=2b−1max−min-
这里 b = 4 b = 4 b=4
-
m a x = 2 , m i n = − 2 max = 2, min = -2 max=2,min=−2
scale = 2 − ( − 2 ) 16 − 1 = 4 15 ≈ 0.2667 \text{scale} = \frac{2 - (-2)}{16 - 1} = \frac{4}{15} \approx 0.2667 scale=16−12−(−2)=154≈0.2667
-
-
将 F P 32 FP32 FP32 值映射到 bin 序号(0–15)
bin = round ( x − m i n s c a l e ) \text{bin} = \text{round}\left(\frac{x - min}{scale}\right) bin=round(scalex−min) -
例子: x = − 1.8 x = -1.8 x=−1.8
bin = round ( − 1.8 − ( − 2 ) 0.2667 ) = round ( 0.2 0.2667 ) ≈ round ( 0.75 ) = 1 \text{bin} = \text{round}\left(\frac{-1.8 - (-2)}{0.2667}\right) = \text{round}\left(\frac{0.2}{0.2667}\right) \approx \text{round}(0.75) = 1 bin=round(0.2667−1.8−(−2))=round(0.26670.2)≈round(0.75)=1
3.2 NF4量化(Normal Float 4-bit Quantization)
NF4量化是由QLoRA论文引入的一种针对4比特权重存储的创新型量化数据类型。它解决了低比特量化中最棘手的问题:信息密度。
NF4的核心思想:
NF4不是将数值范围均匀地分成16份,而是根据理论上的正态分布来非均匀地分配这16个码点(codepoints),使得每个量化区间所包含的概率质量(Probability Mass)大致相等。靠近 0 密集,尾部稀疏
具体实现步骤:
-
假设先验分布:假设神经网络权重服从一个均值为0,标准差为σ的标准正态分布
N(0, 1)。 -
将 F P 32 FP32 FP32 值映射到 bin 序号(0–15)
bin = arg min i ∣ x − t a b l e [ i ] ∣ \text{bin} = \arg\min_i |x - table[i]| bin=argimin∣x−table[i]∣ -
找到最接近 F P 32 FP32 FP32 权重的离散值下标
-
例子: x = 0.12 x = 0.12 x=0.12
-
查表找到最接近的值:
0.12 最接近 0.1 0.12\text{ 最接近 } 0.1 0.12 最接近 0.1 -
对应下标:
bin = 10 \text{bin} = 10 bin=10- NF4 量化查表找最接近值 - bin = 下标,表示该FP32权重在NF4表中对应的离散浮点值 - 训练时NF4表固定,只训练LoRA插入的小矩阵参数
-
4. 反量化
-
假设某个权重矩阵的一行参数是:
W = [ 0.12 , − 0.95 , 0.33 , 1.24 , − 0.44 ] W = [0.12, -0.95, 0.33, 1.24, -0.44] W=[0.12,−0.95,0.33,1.24,−0.44]- 这些都是 32 位浮点数 (FP32) 存储。
- 每个数占 4 个字节(32 bit) 。
-
把每个 F P 32 FP32 FP32 参数映射到最接近的 i n t 4 int4 int4 值:
- 0.12 → 9 - -0.95 → 0 - 0.33 → 11 - 1.24 → (截断到范围上限 1.0) → 15 - -0.44 → 6如此,量化后的向量为:
W i n t 4 = [ 9 , 0 , 11 , 15 , 6 ] W_{int4} = [9, 0, 11, 15, 6] Wint4=[9,0,11,15,6] -
在计算时,这些 i n t 4 int4 int4 值会根据 b i n bin bin 映射回浮点数,得到的近似权重:
W ~ = [ 0.12 , − 1.0 , 0.33 , 1.0 , − 0.44 ] \tilde{W} = [0.12, -1.0, 0.33, 1.0, -0.44] W~=[0.12,−1.0,0.33,1.0,−0.44]
和原始 F P 32 FP32 FP32 版本相比,有少量误差,但总体形状保持一致。
四、QLoRA
QLoRA 的全称是 Quantized Low-Rank Adaptation(量化低秩适应)。
它是一个革命性的微调方法,核心思想是:将预训练的大模型以极低的精度(4比特)量化到内存中,从而大幅减少内存占用,在此期间再通过一组少量的、可训练的“低秩适配器”(LoRA)来对模型进行微调。
简单来说,它让你可以用一块消费级GPU(如RTX 3090/4090) 来微调原本需要数张A100才能运行的超大模型。
1. QLoRA三大核心技术
1. 1比特 NormalFloat (NF4) 量化
这是QLoRA的内存压缩核心。
- 是什么:一种信息理论最优的4比特量化数据类型,专门为神经网络权重通常服从正态分布的特性而设计。
- 怎么做:它不是将数值范围均匀分割,而是根据正态分布的分位数来分配那16个(2^4)可能的值。使得在数值密集的区域(靠近0)量化更精细,在数值稀疏的区域(尾部)量化更粗糙。
- 好处:相比普通的4比特量化,NF4能最大限度地保留原始模型的信息,将量化损失降到最低。
1.2 双量化(Double Quantization)
对量化常数进行二次量化,进一步节省内存。
- 是什么:第一次量化模型权重时,会产生一批量化常数(
scale和zero_point)。这些常数本身也是浮点数,会占用额外空间。 - 怎么做:QLoRA将这些常数再次进行量化(通常是8比特)。虽然这会引入极小的额外误差,但能节省大量内存。论文中指出,这能为每个参数平均节省0.37比特。
- 比喻:就像压缩一个文件夹,你不仅压缩了里面的文件(第一次量化),还把压缩包本身也压缩了(第二次量化)。
1.3 分页优化器(Paged Optimizers)
利用CPU内存来分担GPU显存的压力。
- 是什么:一种内存管理技术。
- 怎么做:在训练过程中,当GPU内存使用达到峰值时,自动将优化器状态临时移动到CPU的RAM中,然后在优化器更新步骤需要时再将其取回GPU。这个过程对训练流程是透明的。
- 好处:有效地防止了由于突然的内存波动而造成的训练中断(内存溢出错误),让在有限GPU上训练超大模型成为可能。
2. 核心原理
-
将参数范围压缩到一个有限范围,比 − 127 -127 −127 到 127 127 127(INT8 Qlora 8)或 − 7 -7 −7 到 7 7 7(INT4 Qlora4)。
-
存储参数的量化值,同时存储一个全局或局部的缩放因子,用于反量化时恢复精度。
公式:
X Int8 = round ( 127 absmax ( X FP32 ) ⋅ X FP32 ) = round ( c FP32 ⋅ X FP32 ) \mathbf{X}^{\text{Int8}} = \text{round}\Big(\frac{127}{\text{absmax}(\mathbf{X}^{\text{FP32}})} \cdot \mathbf{X}^{\text{FP32}}\Big) = \text{round}\big(c^{\text{FP32}} \cdot \mathbf{X}^{\text{FP32}}\big) XInt8=round(absmax(XFP32)127⋅XFP32)=round(cFP32⋅XFP32)
解释:
-
absmax:取整个权重矩阵的绝对值最大值
absmax ( X ) = max ( ∣ X i j ∣ ) \text{absmax}(\mathbf{X}) = \max(|X_{ij}|) absmax(X)=max(∣Xij∣)
这个值起到 缩放因子 的作用 -
缩放到 [-127,127]
- 把 FP32 权重按比例压缩到 Int8 可表示的整数范围 [-127,127]
- 然后 round 成整数
-
回浮点值时
X FP32 ≈ X Int8 / c FP32 \mathbf{X}^{\text{FP32}} \approx \mathbf{X}^{\text{Int8}} / c^{\text{FP32}} XFP32≈XInt8/cFP32
相当于查表,表是线性的、等间隔的。
【例子】
假设原始 FP32 数据是 [2.5, -4.0, 3.2]
- 先算 absmax:这些数的绝对值是 2.5、4.0、3.2,最大的是 4.0。
- 算系数c:127 ÷ 4.0 = 31.75。
- 缩放每个数:
- 2.5 × 31.75 = 79.375
- -4.0 × 31.75 = -127
- 3.2 × 31.75 = 101.6
- 四舍五入取整,得到 Int8 结果:
[79, -127, 102]
3. Normal Distribution
- 权重的特性:大模型的权重服从 “正态分布”(像钟形曲线)—— 绝大多数权重都挤在0 附近(比如 - 0.5~0.5),只有极少数权重会跑到 “尾部”(比如 2.0、4.0)。
就像一个班级里,90% 的学生身高都在 150~160cm(对应 0 附近的权重),只有 10% 的学生身高在 120cm 或 190cm(对应尾部权重)。 - 普通 4bit 量化的特性:4bit 整数(int4)能表示的范围是 [-7, 7],共 15 个离散值(-7,-6,…0,…6,7),这些值是 “等间距均匀分布” 的 —— 每个值之间的 “间隔” 一样大。
3.1 分布失配问题
普通 4bit 量化会先算一个 “统一缩放系数(scale)”,把所有权重 “拉到 [-7,7] 范围内” 再映射到整数。用你给的例子:
-
假设有权重分布(接近正态):
w = [-0.05, 0.01, 0.02, 0.03, 0.07, 0.5, 2.5, 4.0] -
第一步算 scale:int4 的最大绝对值是 7,原始权重的最大绝对值是 4.0(尾部的 4.0),所以 scale = 原始最大值 /int4 最大值 = 4.0 / 7 ≈ 0.57。
(意思是:1 个 int4 单位 = 0.57 个原始权重单位,比如 int4 的 7 对应 4.0,int4 的 1 对应 0.57) -
第二步映射:每个权重 ÷ scale,再四舍五入到最近的 int4 值。
比如:0.01 ÷ 0.57 ≈ 0.017 → 四舍五入成 0;0.07 ÷ 0.57 ≈ 0.12 → 也成 0;甚至 0.5 ÷ 0.57 ≈ 0.88 → 还是 0! -
映射结果:
w_int4 = [0, 0, 0, 0, 0, 1, 4, 7]
3.2QLoRA 的Normal Distribution
核心思路很简单:既然权重是 “中间密、两边疏” 的正态分布,那 int4 的 15 个 “站位” 也应该跟着调整 —— 中间 0 附近的站位设得密集点,两边尾部的站位设得稀疏点。
就像班级排队:把 150~160cm(0 附近权重)的区间拆成 3 个站位(比如 150~153cm 站 - 1、153~157cm 站 0、157~160cm 站 1),而 120~150cm(左边尾部)和 160~190cm(右边尾部)的大区间各拆成少数几个站位 —— 这样中间的学生能分开站,差异不丢失,尾部的学生也有位置。
根据正态分布的特性,把 [ − 7 , 7 ] [-7,7] [−7,7] 的 整数区间非均匀划分,例如在 0 附近划分得更密集,远离 0 的区域划分得更稀疏。
区间 1:权重非常接近中心([-0.5, 0.5])
区间 2:权重稍远([-1.5, -0.5] 和 [0.5, 1.5])
区间 3:极端权重([-3, -1.5] 和 [1.5, 3])
每个值映射到小的范围区间内,后做向量化与反向量化,转成整数。每个区间会对应自己的scaling
量化后:
w_int4 ≈ [-1, 0, 0, 1, 2, 3, 6, 7]
优点:
- 接近 0 的数也能分布到多个整数区间,不会全挤到 0。
- 大值仍然有较好的表达能力。
4. 双量化
权重要从 F P 32 FP32 FP32 压缩到 I n t 4 Int4 Int4:
-
普通 int4 量化公式:
w i n t 4 = round ( w f p 32 / scale ) w_{int4} = \text{round}(w_{fp32} / \text{scale}) wint4=round(wfp32/scale) -
问题:
scale本身是 F P 16 FP16 FP16 或 F P 32 FP32 FP32 浮点数,每个通道/组都要存储。- 对数百亿参数大模型来说,存储 scale 的开销很大,回答道几百 MB。
- 虽然权重被压缩到 4bit,但额外关联的 scale 张量 还占据不少空间。
QLoRA 提出:缩放因子 (scale) 也做量化
- 第1层量化:把 FP32 权重量化到 int4,得到
w_int4和scale1。 - 第2层量化:再把这些
scale1用 更低精度(如 int8)存储,而不是 FP16/FP32。
【示例】
假设我们有一组 FP32 权重:
w = [-2.1, -0.5, 0.0, 1.2, 3.5]
-
普通单量化
-
最大绝对值 = 3.5 → scale1 = 3.5/7 ≈ 0.5
-
量化后:
w_int4 = [-4, -1, 0, 2, 7] 存储 = int4 权重 + FP16(0.5)
-
-
Double Quantization
-
第1步:和上面一样,得到
scale1=0.5。 -
第2步:把所有
scale1再统一存储在一个较小范围内,比如:- 所有 scale1 的值大约在
[0.01, 1.0]。 - 对 scale1 做 int8 量化(比如 [-127,127])。
- 存储的时候不是 FP16,而是 int8。
- 所有 scale1 的值大约在
-
于是存储:
权重 w_int4 = [-4, -1, 0, 2, 7]
scale1 被量化为 int8(比如 64 表示 0.5)
反量化时:
真实权重 ≈ (w_int4 × dequant(scale1_int8))
优点:
- 大幅省空间:对量化所需的辅助参数(如 scale)再做低精度量化(如 FP32 转 Int8),进一步压缩存储开销,且不增加核心权重的存储负担;
- 几乎不丢精度:辅助参数(如 scale)本身取值集中、对误差不敏感,二次量化的微小偏差几乎不影响模型最终推理 / 训练性能,性价比极高。
5. QLoRA的工作流程
- 准备预训练模型:加载一个庞大的预训练语言模型(如LLaMA)。
- 量化冻结:将模型的所有参数用NF4格式+双量化进行4比特量化。量化后的模型被冻结,在微调过程中其权重不可训练。
- 注入LoRA适配器:在模型的Transformer层(通常是Attention的Q, K, V, O和FFN层)中插入低秩适配器(LoRA Adapters)。这些适配器是非常小的、可训练的矩阵(通常秩
r很小,如64或128)。 - 微调:
- 前向传播:输入数据通过4比特的主模型进行计算。
- 反向传播:只计算LoRA适配器的梯度。主模型的4比特权重因为被冻结,没有梯度。
- 优化器更新:只更新LoRA适配器的参数。使用分页优化器来管理这些优化器状态。
- 保存与部署:
- 训练完成后,你可以将训练好的LoRA适配器单独保存为一个文件(通常只有几MB到几百MB)。
- 在推理时,你可以将预训练的基模型(FP16或NF4)和微调后的LoRA适配器动态组合起来使用,获得微调后的模型能力。
6.QLoRA的意义与影响
- 民主化AI:它极大地降低了微调最先进大模型的门槛,使得研究人员、学生和小公司也能在自己的领域数据上定制大模型。
- 高效实验:研究人员可以快速在多个数据集上尝试微调不同的模型,加速实验迭代。
- 成本极低:避免了租赁昂贵的多卡A100服务器,节省了大量成本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)