vLLM—— 用于加速大模型推理
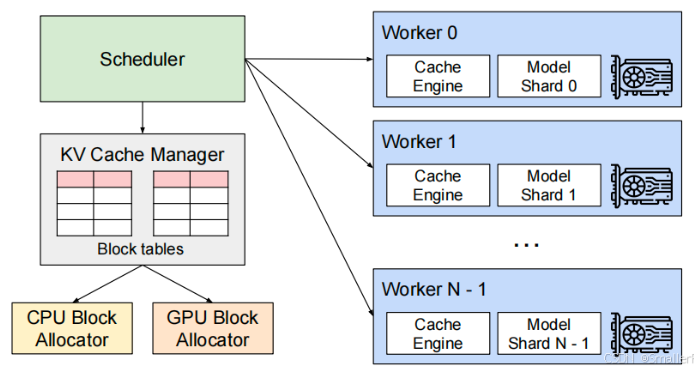
vLLM是一个用于快速LLM推理和服务的开源库,利用分页注意力(PagedAttention)有效的管理注意力key和value,增加模型的吞吐量。vLLM整体架构。
·
-
简介
- vLLM是一个用于快速LLM推理和服务的开源库,利用分页注意力(PagedAttention)有效的管理注意力key和value,增加模型的吞吐量。
- vLLM整体架构
-
原理
- 现状
- 现在的大模型在进行推理的时候,GPU的内存分配如下。可以看出KV Cache是影响模型吞吐量的主要因素,KV Cache的管理如果不好,就会导致推理速度变慢。

- Parameters:模型的权重参数,这部分是静态的,没办法进行优化。
- KV Cache:Transformer的Attention机制引入的中间缓存。
- Other:临时激活函数占用,比例小,优化空间不大。
- 现在的大模型在进行推理的时候,GPU的内存分配如下。可以看出KV Cache是影响模型吞吐量的主要因素,KV Cache的管理如果不好,就会导致推理速度变慢。
-
技术前提
-
自回归生成
- 现在的大模型一般都是基于语言模型,即根据前面的语句来预测下一个字的概率。

- 也就是在注意力机制中,计算K和V的值,然后将K、V的结果缓存后,再预测下一个字。一直重复这个步骤,直到输出最大长度。
- 现在的大模型一般都是基于语言模型,即根据前面的语句来预测下一个字的概率。
-
-
存在的问题
- KV Cache太大
- LLM需要对每个请求维护一个KV缓存(键值对缓存),用于存储模型在生成文本时候的上下文信息,随着请求数量的增加,KV Cache也会增长,占用大量的GPU内存。
- 复杂的解码算法
- LLM会提供多种解码算法,这些算法会对内存管理的复杂性产生不同的影响。
- 未知的输入和输出长度
- LLM 服务的输入和输出长度是变化的,这要求内存管理系统能够适应不同长度的提示。随着请求的输出长度在解码过程中增长,所需的 KV 缓存内存也会增加,可能会耗尽用于新请求或现有的内存。
- KV Cache太大
-
分块注意力(Paged Attention)
- 分块注意力是一种受操作系统中的虚拟内存和分页技术启发的算法。它允许将连续的K和V向量存储在非连续的内存空间中。这点于传统的注意力算法不同,后者通常要求K和V向量在内存中连续存储。
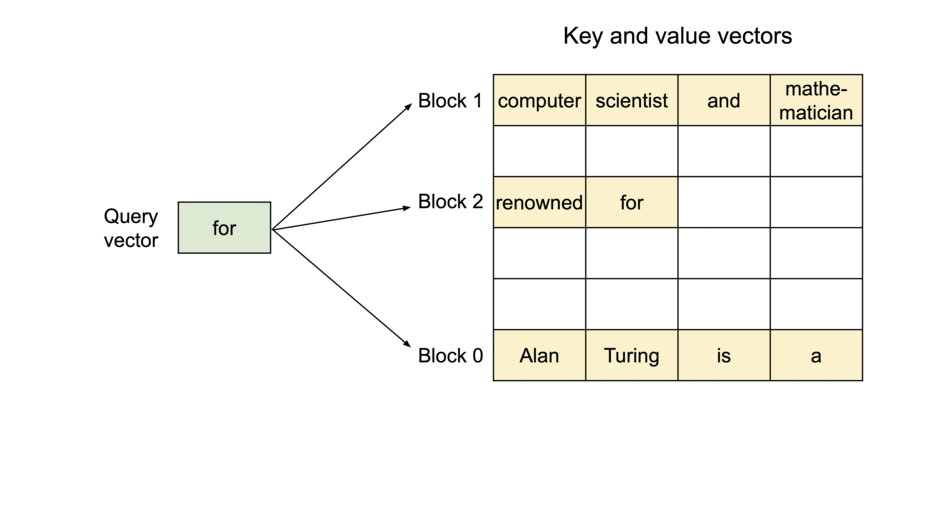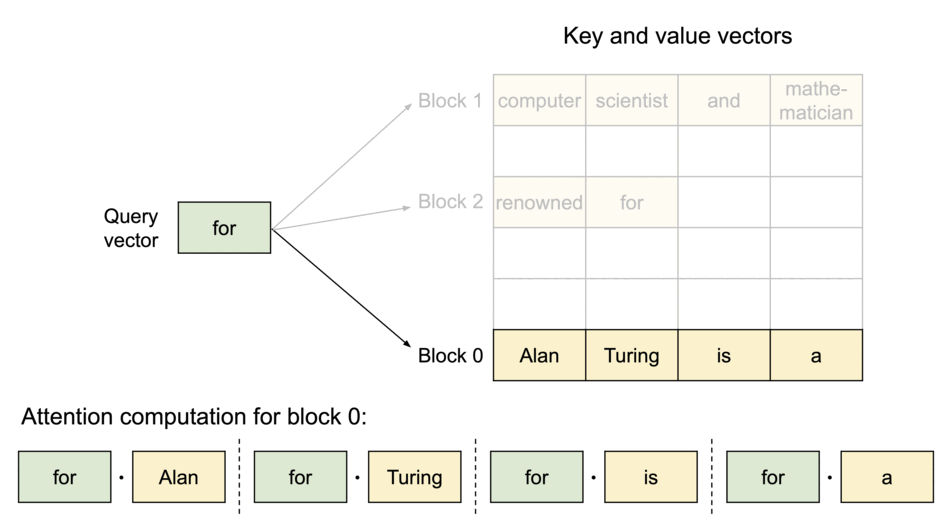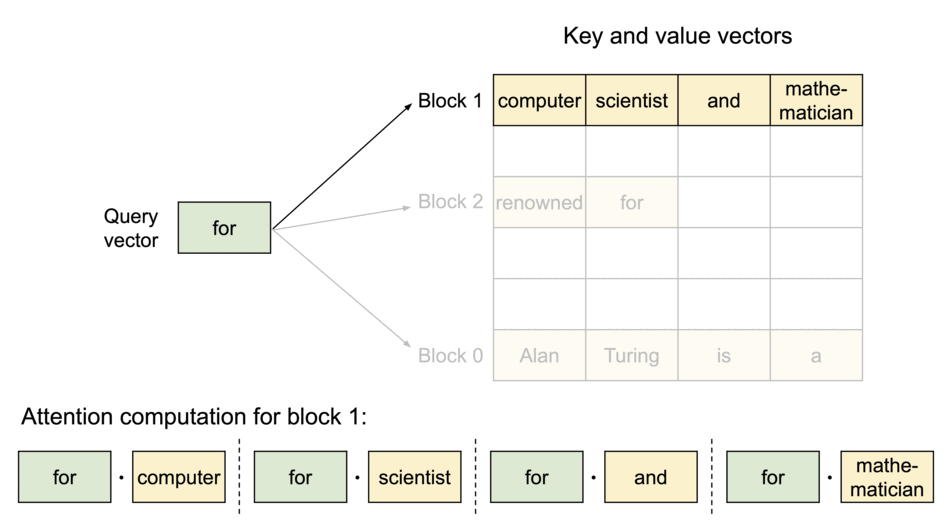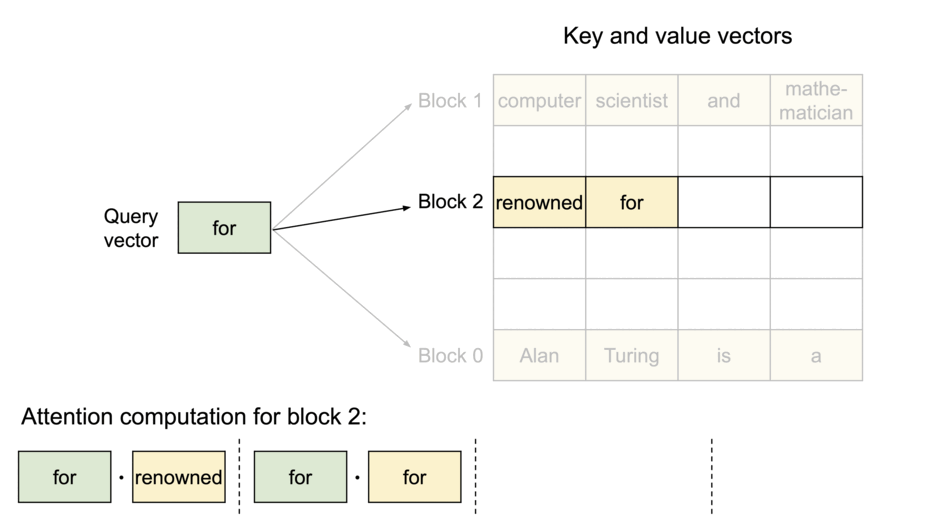
- KV缓存分块
- 分块注意力将每个序列的KV Cache划分成多个KV块(KV blocks),每个KV块中都包含了固定数量Token的K和V向量。
- 非连续存储
- 同时分块注意力可以根据需求来分配KV块,减少了内存碎片,并允许跨请求或同一请求不同序列之间的内存共享。
- 按需分配
- 与传统的方法不同,分块注意力允许这些KV块可以在物理内存中非连续的存储,使内存管理更为灵活。
- 分块注意力是一种受操作系统中的虚拟内存和分页技术启发的算法。它允许将连续的K和V向量存储在非连续的内存空间中。这点于传统的注意力算法不同,后者通常要求K和V向量在内存中连续存储。
- KV Cache Manager
- KV Cache Manager是vLLM系统中的核心组件,负责以分页的方式高效管理KV Cache。
- 逻辑与物理块映射
- KV Cache Manager维护这一个块表(block table),负责记录逻辑KV块与物理KV块之间的映射关系。这种分离允许动态的增长KV Cache内存,从而无需预先为其所有位置分配内存。
- 动态内存分配
- KV Cache Manager根据需要动态分配物理KV块,这消除了现有系统中的大部分内存浪费。
- 内存共享
- 通过页级内存共享,KV Cache Manager支持在不用请求之间共享KV Cache,进一步减少内存使用。
- 举例
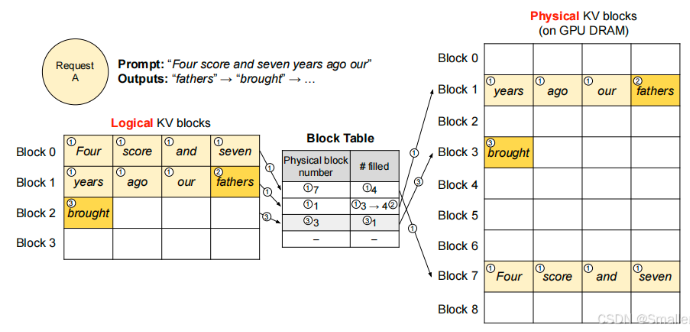
- 一个 Block 最大存储 4 个 token。开始输入Four score and seven years ago our 一共7个token,因此逻辑 KV 块 Block 0 填充前4个,对应于物理 KV 块的 Block 7;剩下3个 token 填充逻辑 KV 块 Block1,对应于物理 KV 块的 Block 1,但是并没有填满,对应的 Block Table 的 #filled 写入3。 ( filed 表示有多少个token)
- 当自回归生成下一个 token fathers 后,物理 KV 块的 Block 1 同时写入,并且对应的 Block Table 的 #filled 由 3 改写成 4。
- 自回归生成下一个 token brought 后,流程类似。
- 现状
-
vLLM与Ollama对比
-
对比维度 Ollama vLLM 核心定位 轻量级本地大模型运行工具(适合个人开发/实验) 生产级大模型推理框架(适合企业/高并发场景) 部署难度 简单:一键安装,支持 Mac/Linux/Windows(WSL) 较复杂:依赖 Python 环境,需手动配置 GPU 驱动和 CUDA,仅支持linux或WSL 硬件要求 低:CPU 可用(推荐 16GB+ 内存),可选 GPU 加速 高:必须 NVIDIA GPU(显存越大越好),依赖 CUDA 计算 模型支持 内置主流开源模型(Llama2、Mistral、DeepSeek 等),自动下载预训练模型 支持 HuggingFace 格式模型,需手动下载和转换模型文件 运行性能 中等:适合单次问答、小规模交互 极高:优化了显存管理和批处理,支持千级别并发请求 使用场景 个人学习、本地测试、快速原型开发 企业级 API 服务、高并发推理、云端部署 交互方式 命令行直接对话,支持类似 ChatGPT 的交互界面 需通过 API 调用(OpenAI 兼容接口),无内置对话界面 资源占用 灵活:可调整 CPU/内存占用,适合低配电脑 固定:显存占用量大,需预留资源应对峰值负载 扩展性 有限:专注于单机本地化运行 强:支持分布式部署、动态批处理、多 GPU 并行 新手友好度 极高:开箱即用,无需代码基础 中等:需了解 Python 和 API 开发基础 社区支持 活跃的开发者社区,文档清晰 学术团队维护,更新频繁但偏向技术文档 典型用途 写代码、翻译、文案生成等个人任务 构建智能客服、批量文档处理、AI 赋能业务系统
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)