英伟达(NVIDIA)的GPU架构
英伟达GPU架构经历了从通用计算到专用AI计算的演进。早期Tesla、Fermi奠定并行计算基础;Kepler、Maxwell提升能效;Pascal开始支持深度学习。Volta首次引入Tensor Core,Turing加入RT Core,实现AI训练和光追突破。Ampere和Hopper专注AI计算,支持大规模Transformer训练。最新Blackwell采用双芯片设计,面向万亿参数模型。未
·
英伟达(NVIDIA)的GPU架构是其技术和产品创新的核心,不同架构的GPU针对性地提升了计算性能、能效以及特定任务(如AI训练、推理、图形渲染等)的处理能力。下面我将为你梳理英伟达GPU架构的发展历程、各代特点以及一些最新动态。
为了让你能快速了解英伟达GPU架构的演进,我用一个表格来汇总它们的主要特性:
| 架构名称 | 推出年份 | 制程工艺 | 核心创新 | 关键特性 | 代表产品 | 主要应用场景 |
|---|---|---|---|---|---|---|
| Tesla | 2006 | - | 统一计算架构思想 | 早期CUDA支持 | Tesla C870, GeForce 8800 GTX | 通用并行计算起步 |
| Fermi | 2010 | - | 引入ECC内存、C++并行支持,统一缓存 | 更强的双精度性能,更好的并行计算能力 | Tesla C2050, GeForce GTX 480 | 高性能计算早期探索 |
| Kepler | 2012 | - | GPU Boost动态提速技术 | 能效大幅提升,支持动态并行计算 | Tesla K40, GeForce GTX 680 | 高性能计算,早期深度学习 |
| Maxwell | 2014 | - | 能效优化,动态超分辨率(DSR) | 能耗控制优秀,支持VR优化 | Tesla M40, GeForce GTX 980 | 图形处理,VR |
| Pascal | 2016 | 16nm FinFET | NVLink 1.0, HBM2显存 | 高性能计算和深度学习早期阶段重要架构,支持FP16运算 | Tesla P100, GeForce GTX 1080 | HPC,深度学习早期阶段 |
| Volta | 2017 | 12nm FinFET | 首次引入Tensor Core,NVLink 2.0, HBM2 | 专为AI和科学计算设计,深度学习训练支持大幅提升 | Tesla V100, Titan V | AI训练,科学计算 |
| Turing | 2018 | 12nm FinFET | 首次引入RT Core,第二代Tensor Core,GDDR6 | 实时光线追踪,AI渲染(DLSS) | Tesla T4, GeForce RTX 2080 Ti | AI推理,实时光追渲染 |
| Ampere | 2020 | 8nm | 第三代Tensor Core,第三代RT Core,MIG技术,GDDR6X | AI训练和推理性能大幅提升,支持TF32和稀疏计算 | A100, RTX 3080, RTX A6000 | AI训练/推理,高性能计算 |
| Ada Lovelace | 2022 | 4nm | 第四代Tensor Core,第四代RT Core,DLSS 3 | 极致光线追踪能力,高效AI加速 | RTX 4090, L20 | 高端游戏,专业图形,AI推理 |
| Hopper | 2022 | - | Transformer Engine,第四代NVLink,HBM3 | 专为大规模Transformer模型训练设计 | H100, H800 | 大规模AI训练(尤其是大语言模型) |
| Blackwell | 2024-2025 | - | 第五代Tensor Core,双芯片设计(MCM),第五代NVLink | 支持FP4,AI计算性能相较Hopper提升2-4倍,专为万亿参数模型和生成式AI设计 | B100, B200, GB200 NVL72 | 下一代AI训练与推理,生成式AI |
| Rubin (未来) | 预计2026 | - | 解耦推理(CPX单元处理长上下文,Rubin GPU负责生成),GDDR7显存,与Vera CPU协同 | 专为长上下文AI推理和视频生成优化,单芯片128GB GDDR7显存 | Rubin CPX, Rubin GPU, Vera CPU (预计) | 百万Token推理、长视频生成、复杂软件开发(预计) |
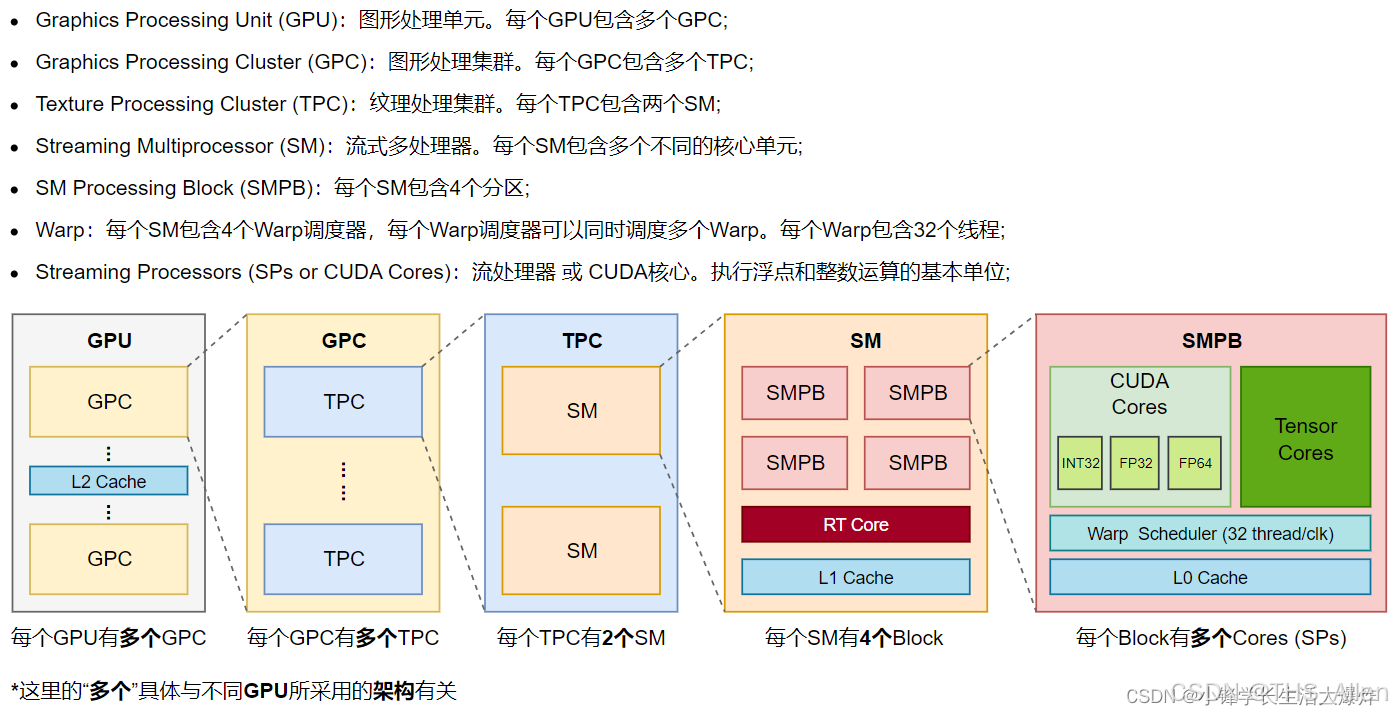
各架构简要说明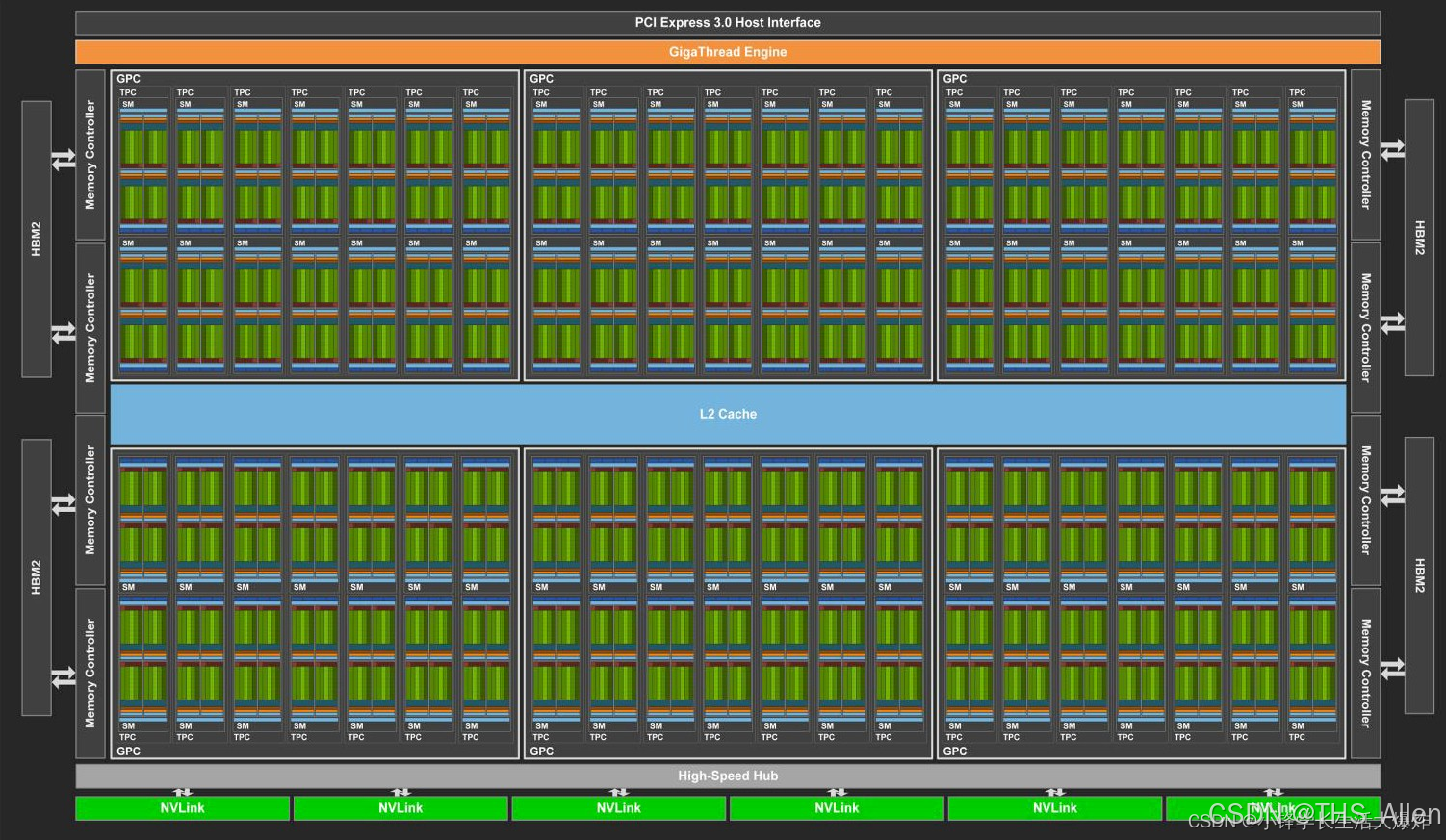
英伟达GPU架构的迭代,清晰地展现了其从通用图形处理到通用并行计算(GPGPU),再到专用AI计算的演进路径:
- Pascal及以前:聚焦于图形渲染和通用计算能力的提升,为GPGPU和深度学习奠定了基础。
- Volta & Turing:专用计算单元的引入是革命性的。
- Volta的Tensor Core极大加速了AI训练。
- Turing的RT Core实现了实时光线追踪,其Tensor Core也优化了AI推理。
- Ampere & Hopper:AI计算架构的成熟和爆发。
- Ampere:第三代Tensor Core和支持MIG(多实例GPU) 技术,使其成为数据中心AI训练的绝对主力。
- Hopper:其Transformer Engine和HBM3显存,专为大规模Transformer模型训练设计,成为了训练大语言模型的标配。
- Blackwell & Rubin (未来):面向下一代AI的架构创新。
- Blackwell:采用双芯片设计(MCM),支持FP4精度,旨在处理万亿参数规模的模型和生成式AI应用。
- Rubin:创新性地采用解耦推理设计,即将推出的Rubin CPX GPU专攻长上下文处理(如百万Token推理、长视频生成),而Rubin GPU则负责Token生成,通过分工提升大规模推理任务的效率和经济性。
显存技术对比
不同的GPU架构和应用场景会采用不同的显存技术,这对带宽和容量影响很大:
| 显存类型 | 定位 | 特点 | 常见应用架构 |
|---|---|---|---|
| HBM3 | 高端服务器 | 超高带宽,容量大,功耗较低 | Hopper, Blackwell |
| HBM2e | 数据中心 | 高带宽,性能优秀 | Ampere (如A100) |
| GDDR6X | 消费级高端显卡 | 高带宽,但功耗较高 | Ampere (如RTX 30系列) |
| GDDR6 | 主流消费显卡 | 平衡带宽、容量和成本 | Turing, Ampere, Ada Lovelace |
| GDDR7 (新兴) | 未来应用 | 预期比GDDR6更高带宽,用于特定推理场景 | Rubin CPX (预计) |
如何选择GPU架构?
选择哪款GPU或架构,主要取决于你的具体需求、预算和工作负载类型:
-
AI训练(尤其是大模型):
- 大规模训练:Hopper (H100/H800) 和 Blackwell (B100/B200) 是当前和未来的旗舰选择,具备极高的计算效率和互联带宽。
- 中等规模或入门训练:Ampere (A100, A800) 甚至 Volta (V100) 仍有价值,性价比可能更高。
-
AI推理:
- 高吞吐量、多租户:Ampere (A10, A30) 和 Ada Lovelace (L20) 支持MIG技术,适合虚拟化和多实例场景。Turing (T4) 则以极高的能效比和性价比著称,是常见的主流推理卡。
- 长上下文、大模型推理:未来可关注 Rubin CPX,其设计针对此类场景进行了优化。
-
科学计算与HPC:
- 需要强大的双精度浮点性能(FP64) 和高速互联,Ampere (A100)、Hopper (H100) 以及 Volta (V100) 都是传统强项。
-
图形渲染与工作站:
- 实时光线追踪:Ada Lovelace (RTX 4090, RTX 6000 Ada) 和 Ampere (RTX A6000) 提供卓越的实时渲染性能。
- 专业设计:RTX 专业系列(基于Ampere或Ada架构)提供认证驱动和优化。
-
游戏与消费级:
- GeForce RTX系列(基于Ampere、Ada Lovelace等架构)提供从主流到顶级的游戏体验。
总结
英伟达通过其GPU架构的快速迭代,持续推动着计算能力的边界。从通用计算到专用加速,从单芯片到异构系统,其技术演进始终围绕着提升性能、降低功耗、优化总体拥有成本(TCO) 展开。
希望以上信息能帮助你更好地了解英伟达的GPU技术架构。如果你有特定的应用场景或预算,我可以提供更具体的建议。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)