刚刚,OpenAI发长篇论文:大模型幻觉的原因找到了
OpenAI 表示:我们希望本文中的统计学视角能够阐明幻觉的本质,并纠正一些常见的误解:误解1:通过提高准确性可以消除幻觉,因为一个 100%准确的模型永远不会产生幻觉。发现:准确性永远无法达到100%,因为无论模型规模如何,搜索和推理能力怎样,一些现实世界的问题本质上是无法回答的。误解2:幻觉是不可避免的。发现:幻觉并非不可避免,因为语言模型在不确定时可以选择不作答。误解3:避免幻觉需要一定程度
刚刚,OpenAI发长篇论文:大模型幻觉的原因找到了~
相信很多同学都遇到过——问大模型一个冷门知识,它会一本正经地给出完全错误的答案。比如:
“Adam Tauman Kalai 生日是哪天?知道的话就按 DD-MM 的格式直接给出。”
OpenAI(2025a)三次回答分别是 03-07、15-06、01-01, 没一次对 。
这就是典型的 Hallucination(幻觉) —— 语言模型生成看起来合理,实则错误离谱 。
 论文地址:https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
论文地址:https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
OpenAI 这篇论文首次系统揭示: 语言模型出现幻觉的根本原因在于, 当前标准的训练和评估程序更倾向于对猜测进行奖励,而缺乏对模型坦诚表达不确定性的奖励机制。

表1 提供了一些更复杂的幻觉示例:GPT-4o/DeepSeek/Llama
一、预训练阶段就埋下幻觉种子
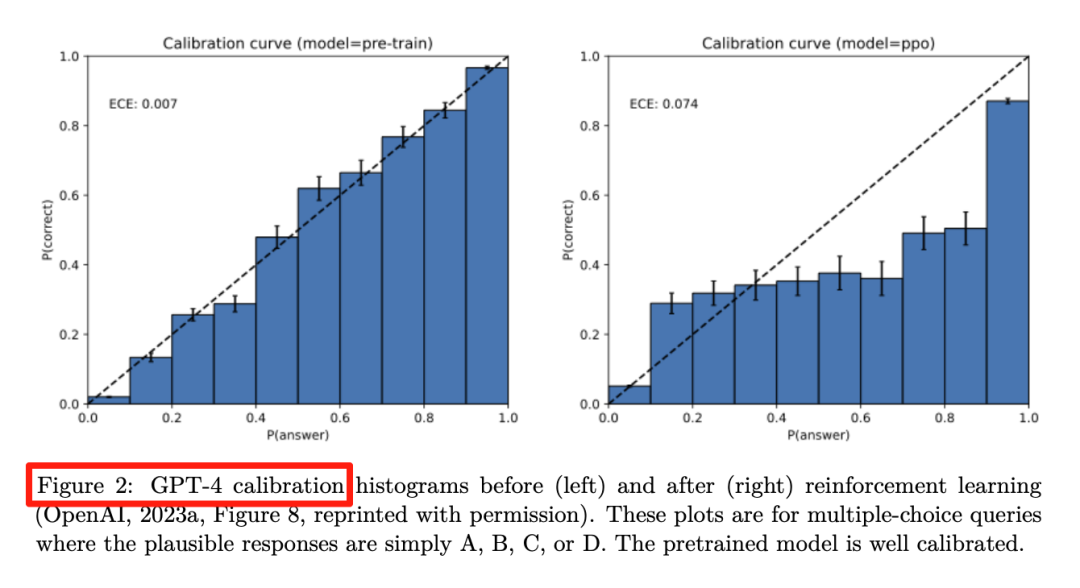
Figure 2:GPT-4预训练模型(左)原本校准良好;RLHF后(右)明显过自信
1. 统计必然性
把生成问题等价到二分类“Is-It-Valid?”——只要分类器会犯错,生成就会出错(定理 1)。

图 1:Is-It-Valid二分类视角——生成错误⇔把"-“判成”+"
2. 数据稀缺性
训练语料里只出现一次的“冷知识”(singleton)注定会被模型记错,错误率 ≥ singleton 占比(定理 2)。

3. 模型表达能力不足
如果模型族本身就无法学到规律(如 trigram 数不对字母),幻觉率下限直接拉满(定理 3)。
 阶段 阶段 |
核心发现 | 类比 |
|---|---|---|
| 预训练 | 就算训练数据100%正确, 密度估计目标 也会迫使模型生成错误 | 老师只教你对的,但期末要你把不会的也填满 |
| 后训练 | 二元评分 (对1分/错0分)让模型不敢"交白卷" | 选择题不会也得蒙,空着直接0分 |
二、后训练阶段“考试机制”强化幻觉
对10个主流评测做了 元评测 ,发现清一色 惩罚不确定性 :

Table 2:主流评测清一色"惩罚"不确定性
| Benchmark | 评分方式 | 给IDK扣分吗? |
|---|---|---|
| MMLU-Pro | 多选准确率 | ✅扣到0分 |
| GPQA | 多选准确率 | ✅扣到0分 |
| SWE-bench | 单测通过/不通过 | ✅扣到0分 |
| WildBench | 10分制人工rubric | ⚠️IDK只得3-4分, 不如"带幻觉但有用"的5-6分 |
三、解法:把"交白卷"变成可选项
呼吁 不需要新benchmark ,只要 改评分规则 :
1. 明示信心阈值
在prompt里直接写:
"只有在你置信度>t时才回答;答错扣t/(1-t)分,IDK得0分。"
2. 让"弃权"成为最优策略
当模型真实置信度<t时, 说"我不知道" 的期望得分最高, 说谎反而吃亏。
四、总结
OpenAI 表示:我们希望本文中的统计学视角能够阐明幻觉的本质,并纠正一些常见的误解:
误解1:通过提高准确性可以消除幻觉,因为一个 100%准确的模型永远不会产生幻觉。
发现:准确性永远无法达到100%,因为无论模型规模如何,搜索和推理能力怎样,一些现实世界的问题本质上是无法回答的。
误解2:幻觉是不可避免的。
发现:幻觉并非不可避免,因为语言模型在不确定时可以选择不作答。
误解3:避免幻觉需要一定程度的智能,而这种智能只有通过更大的模型才能实现。
发现:小型模型可能更容易了解到自身的局限性。比方说,当被要求回答毛利语问题时,一个完全不懂毛利语的小型模型可以直接说“我不知道”,而一个懂一些毛利语的模型必须确定其置信度。正如论文中所讨论的,“校准”所需的计算量远小于实现回答准确性的计算量。
误解4:幻觉是现代语言模型中一种神秘的缺陷。
发现:我们已经理解了幻觉产生的统计学机制,以及它们在评估中获得奖励的原因。
误解5:要衡量幻觉,我们只需要一个好的幻觉评估方法。
发现:尽管已经提出了多种幻觉评估方法,但一个优秀的评估方法对于目前现有的数百种传统准确性指标几乎没有影响。这些传统指标往往惩罚表达谨慎、谦逊的回答,并奖励猜测行为。因此,所有主要的评估指标都需要重新设计,更好地鼓励模型在表达上体现出不确定性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)